コンピュータに文字入力したり、データとして保存したりするときには、何の文字をどんなバイト列で取り扱うかをあらかじめ取り決めておくことが必要だ。この取り決めは文字コードと呼ばれている。
文字コードはコンピュータの発展とともに、ANSI(米国規格協会)やISO、JISといった標準化団体などさまざまな経路で発展を続けている。逆にさまざまな規格が存在するため、OSとしてWindowsでは日本語をShift-JISで取り扱い、LinuxではEUC-JPで取り扱うといったようにプラットフォームごとに異なる文字コードが使用される。IBM iではメインフレームで使用されているEBCDIC(拡張二進化十進コード: Extended Binary Coded Decimal Interchange Code)と呼ばれる文字コードが採用されている。
プラットフォーム間でデータ連携を行う場合、自身の文字コードから相手の文字コードに正しく変換しなければならない。IBMはプラットフォーム間での正しいデータ連携のために文字コードの設計指針となるCDRA(Character Data Representation rchitecture)を提唱した。
このCDRAに沿って文字コードを一意に識別できるIDが割り振られている。このIDはCCSID(コード化文字セットID: Coded Character Set IDentifiers)と呼ばれている。IBMのプラットフォームやソフトウェアでは連携元と連携先のCCSIDに沿って、データ連携時の正しい文字コード変換が行われるように変換ルールが実装されている。
CCSIDは図表1にある3つの要素の組み合わせで、1つ1つについて図表2のように1つのIDが割り振られている。要素のうち1つでも異なるものがあれば新しいIDが割り振られる形だ。

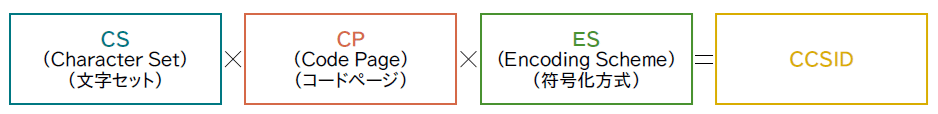
IBM iを日本語OSとして動作させる際に利用できるEBCDICとしてはCCSID 5026、5035、1399といったものがある。CCSID 5026とCCSID 5035は2バイト文字の部分は共通だが、図表3と図表4のように1バイト文字(SBCS: Single Byte Character Set)のコード・ポイントが異なる。
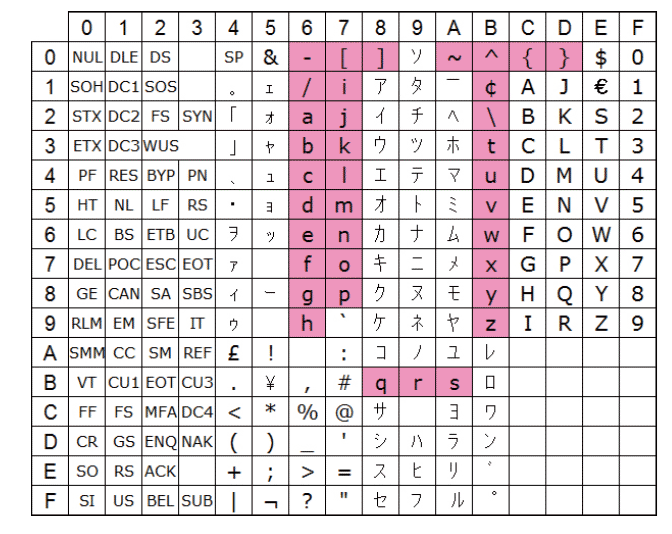
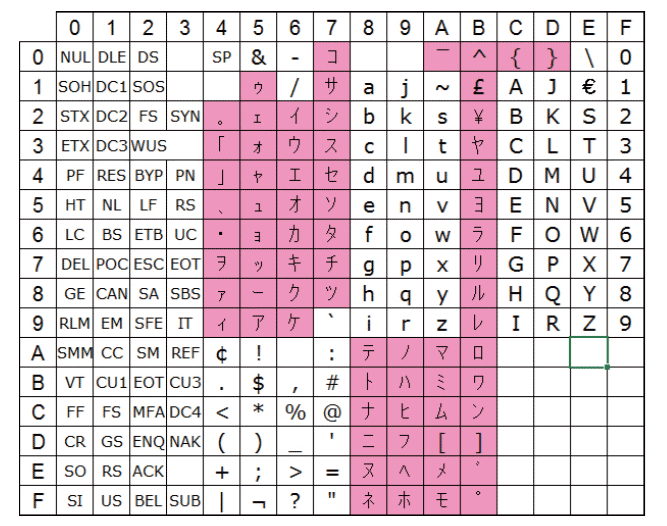
異なる部分は、いわゆる英小文字と半角カタカナのコード・ポイントだ。CCSID 5026のSBCSでは英語のSBCSで英小文字に割り当てていたコード・ポイントを半角カタカナに割り当て、英小文字のコード・ポイントは英語のSBSCとは異なるものとなっている。一方でCCSID 5035は英語のSBCSで割り当てられていないコード・ポイント部分に半角カタカナを割り当てる。CCSID 1399はCCSID 5035のDBCS部分が拡張されたもので、JIS第三・第四水準文字も取り扱うことができる文字コードとなる。CCSID 1399のSBCS部分はCCSID 5035のSBCS部分と同一だ。
歴史的にはIBM iではCCSID 5026が広く利用されてきたが、CCSID 5026では、JavaやC、C++などプログラム・コードで大文字小文字を区別するプログラムが動作しない。
一方でCCSID 5035であれば、英小文字も英大文字も英語のSBCSと同一のコード・ポイントが割り当てられていることから特に問題なく動作する。WebSphere Application ServerやNode.js、PHPアプリケーションなどをIBM i上で稼働させる場合には、少なくともそれらのソフトウェアの動作環境部分はCCSID 5035もしくはCCSID 1399にしなければならない。
日本語OSとしてのIBM iではこれらのCCSIDが利用されるが、そのOSのDb2 for iではテーブル内のカラム単位で格納するデータのCCSIDを規定することができる。つまり、Db2 for iに格納するデータとしては、OSの言語設定によらず、UCS2、UTF-8、UTF-16といったさまざまな文字コードのデータを入れることができるのだ。
図表5では「あいうえお」をCCSID 1399のカラム1、UTF-16のカラム2、UTF-8のカラム3に格納している様子だ。いずれもSQLで通常にデータを取得した場合には「あいうえお」と表現されているが、バイト列を見ると、各文字コードに沿ったデータとして格納されていることがわかる。
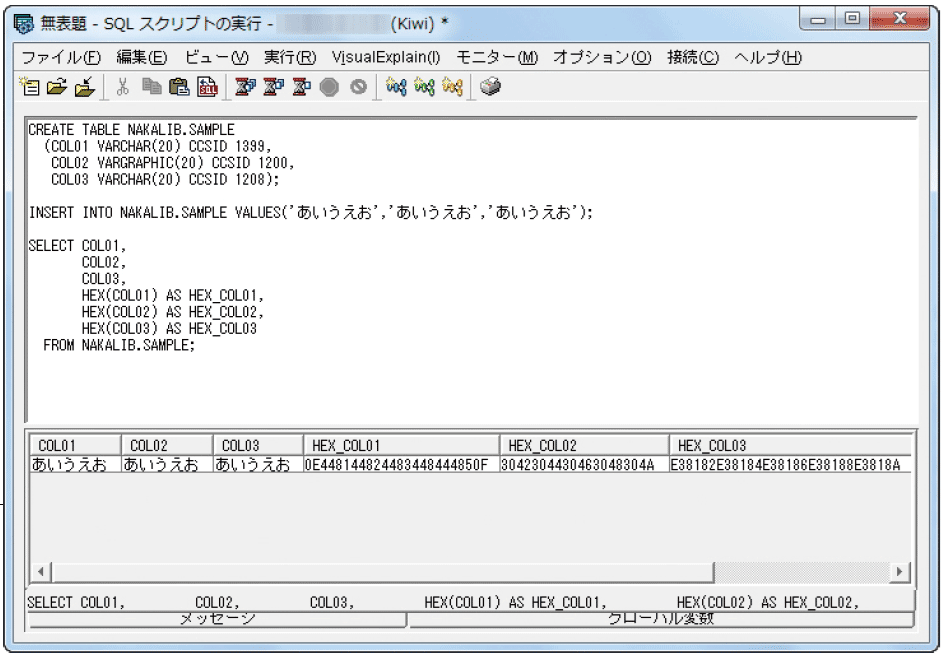
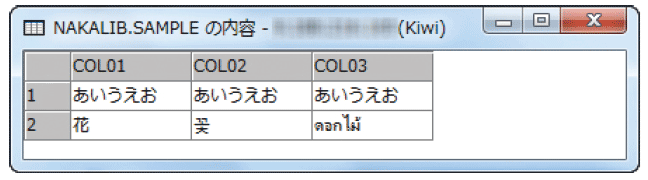
また、図表5のように当然だがUTF-16、UTF-8のカラムには各国語の文字を入れることもできる。このように、IBM iではOSの言語環境、実行環境としてはEBCDICで設定されるが、データベース・サーバーとして利用する場合、さまざまな文字コードのデータを格納、一度に取り扱うことができる(図表6)。
なお、データベー・ファイルと同様に、表示装置ファイルでもUnicodeがサポートされている。表示装置ファイルのレコード・レベルもしくはフィールド・レベルにて、CCSIDキーワードにCCSIDの値を設定する形だ。ただし、表示装置ファイルでサポートされるUnicodeはUCS2もしくはUTF-16となっており、フィールドはG(グラフィック)タイプである必要がある。
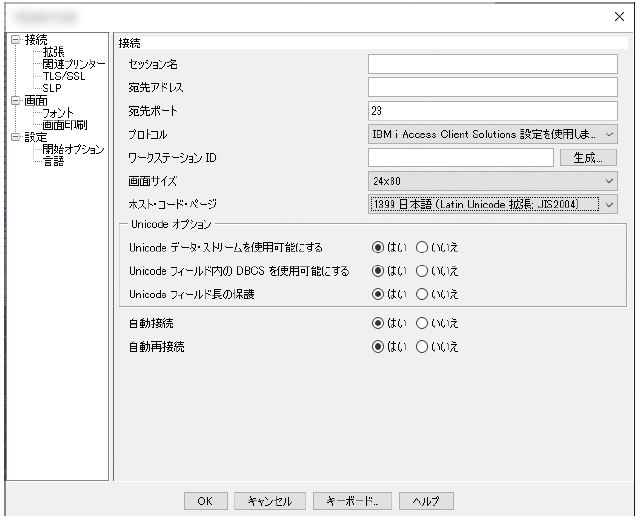
IBM i Access Client Solutions(ACS)の5250エミュレーターではUnicodeをサポートしているため、Unicodeフィールドが定義された表示装置ファイルを適切に表示させることが可能だ(図表7)。