Text=岡元 朋子、江口 陽子、細野 友基 (日本アイ・ビー・エム・システムズ・エンジニアリング)
大規模言語モデル(LLM)は、自然言語生成の分野で目覚ましい進歩を遂げているが、そのまま運用すると、「古い知識に依存する」「根拠のない回答を生成する」などのリスクがある。こうした問題を緩和するための主要アプローチとして、Retrieval-Augmented Generation(RAG:検索拡張生成)が実用化されている。
一方で、「RAGを導入すれば自動的に高品質な応答が得られる」とは限らない。RAGには、検索精度や生成された出力の信頼性、評価メトリクスの設計等の技術的な壁が存在する。そのため評価・改善サイクルを体系的に回す仕組みが非常に重要になる。
本稿ではそうした観点を踏まえ、開発・運用段階で実践可能なRAGシステムの品質評価手法を紹介し、技術的な信頼性を高める道筋を示していく。
RAGとは
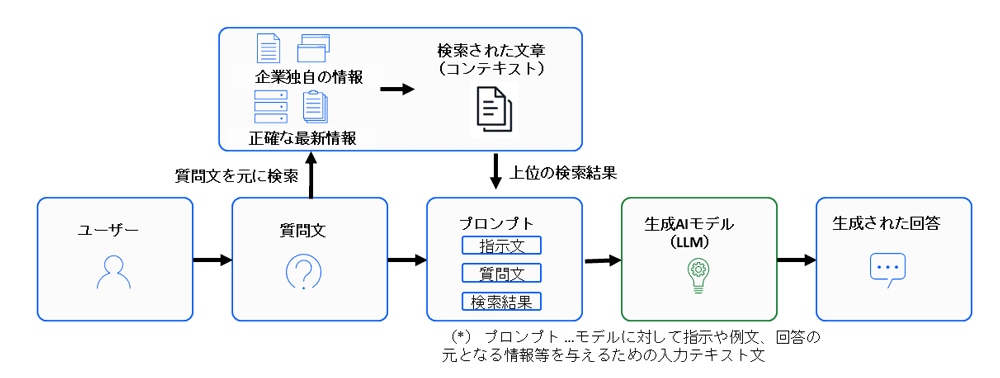
RAGでは、まずユーザーのクエリーに対して必要な情報を外部データソース(企業のドキュメント、ナレッジベースなど)から検索し、その取得した情報をLLMに入力して応答を生成する。
そうすると、LLMは事前学習済みの知識だけで応答を作るのではなく、都度根拠となる情報を補強された状態で生成するため、企業固有のナレッジや最新かつ正確な情報を反映した応答を生成できるようになる。
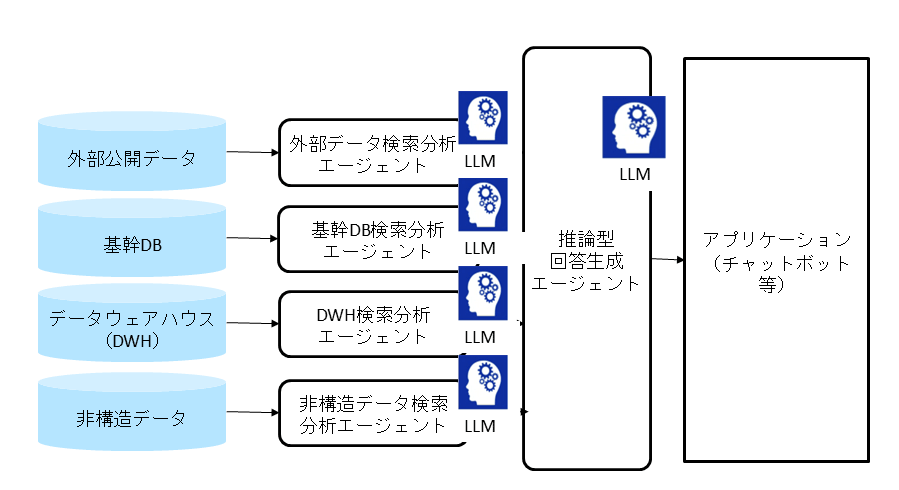
近年では、RAGはAIエージェントの中核技術として活用されるようになっている。AIエージェントとは、環境を観察し、自律的に意思決定をしてタスクを実行できるAIシステムである。
AIがツール利用や計画、記憶へのアクセスを通じて行動しながら、RAGによって根拠ある情報を取得・活用することで、より信頼性の高い自律タスク処理が実現される。
代表的なRAGの手法
基本となるNaïve RAGとその限界、および発展形のAdvanced RAG、さらにそこから派生する主要アーキテクチャを簡単に整理する。
Naïve RAGとは、クエリー→検索→取得した文書をそのままLLMに渡して応答生成する、という最もシンプルなRAGパイプラインである。
シンプルがゆえに容易に実装可能だが、検索品質や文脈整合性がよくない、また複雑な問いや多段推論に弱い、といった限界がある。
そこで、Naïve RAGの限界を克服するため、さまざまな工夫が凝らされている。こうしたさまざまな工夫を表す総称としてAdvanced RAG、という呼び名が存在する。
そのためAdvanced RAGには特定の手法やアーキテクチャ、RAGパイプラインは存在せず、RAGに関するあらゆる創意工夫を内包する言葉となっている。図表2に、代表的な手法をまとめた。

図表2で、特に最近注目されているのはGraph RAG、Agentic RAG、Cache RAGである。
Graph RAGはナレッジグラフ(エンティティと関係性を持つグラフ構造)から部分サブグラフを取得し、それをLLMに与えて構造的な文脈として使う方式である。テキスト同士の関係性を明示的に活用することで、より豊かな推論が可能になっている。
Agentic RAGはAIがエージェントとして振る舞い、RAG検索を計画・判断・実行する。RAGシステムはAgentの中の一ツールとして存在するアーキテクチャである。
Cache RAGはその名のとおり、キャッシュ機構を導入し、頻繁に使われる情報や過去取得したデータを再取得せずに再利用することで、検索ステップを省いたり、レイテンシーと計算コストを大幅に削減できたりする。
以上は、最近注目されているAdvanced RAG手法の簡単な紹介だが、それぞれ、図を用いてもう少し詳しく解説する。
RAG手法詳説 ①
Graph RAG
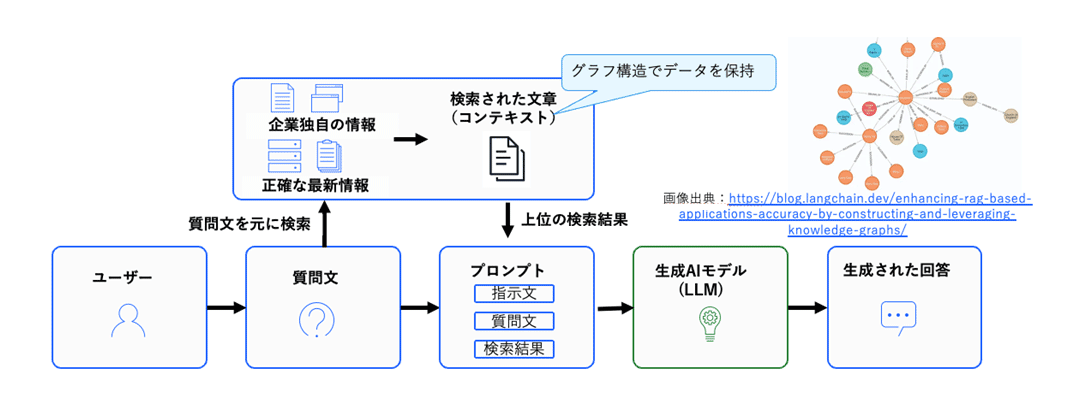
Graph RAGはナレッジグラフから関連するチャンクを取得し、回答に利用する方式である。
ナレッジグラフは通常、Graph DB(グラフデータベース)上に構築する。従来のベクトルDBを用いたTop-N検索ではなく、Top-N+グラフ構造上の関連性をもとにしたチャンクを回答生成に利用できるため、クエリーに直接関係するチャンクだけでなく、背景情報なども併せて取得できるので、より納得度の高い回答を出力することが可能となる。
RAG手法詳説 ②
Agentic RAG
Agentic RAGは、AIエージェントによる自律的なワークフローにRAGを統合したアプローチである。
RAGにより、外部知識ベースやドキュメントを動的に検索し、生成モデルの推論精度を強化する。これにより、単なる情報生成に留まらず、タスク遂行に必要な知識をリアルタイムで補完できる。
特徴として、①自律的な意思決定、②反復的な推論による精度向上、③複数エージェント間での協調的なワークフロー実行がある。
さらに、エージェントはタスク分解、役割分担、結果検証を自動で行い、複雑な業務プロセスを効率化する。Agentic RAGは、企業のナレッジ活用や高度な意思決定支援において、次世代のAI基盤として注目されている。
RAG手法詳説③
Cache Augmented Generation
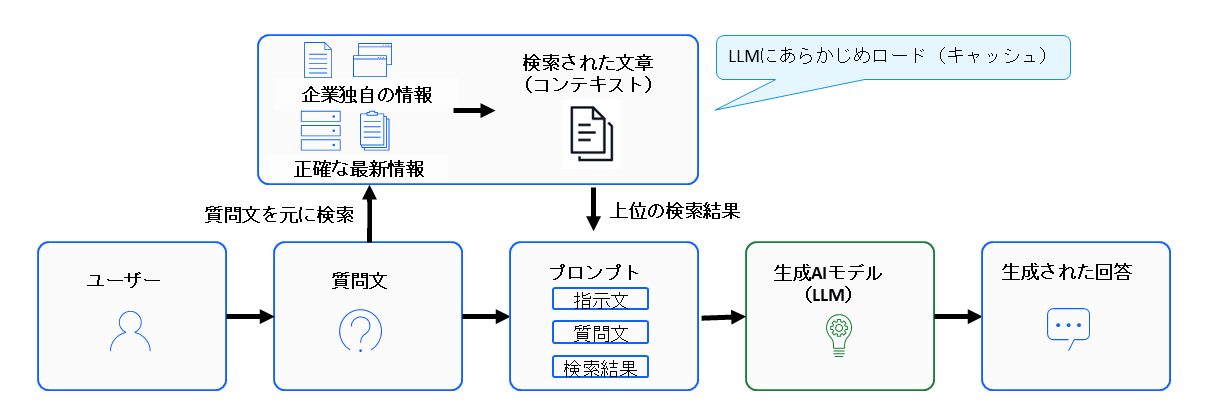
Cache RAGは、回答に必要な文書をリアルタイムで検索することなく、LLMの長大なコンテキストを活用し、あらかじめ関連情報をモデルにロードしておく手法である。これにより、外部検索を伴う従来のRAGと異なり、推論時に検索処理が走らないため、ワークフローがシンプルで高速、という特徴がある。
Cache RAGは、事前にキャッシュされた知識を活用することで、低レイテンシーかつ安定した応答を実現し、大規模なドキュメント群を効率的に扱うことが可能となる。
特に、頻繁に参照される情報や限定されたドメイン知識を扱うシナリオに適しており、検索コストを削減しながら高精度な回答を提供できる。このアプローチは、リアルタイム性が求められる業務や、検索インフラの負荷軽減を目的としたシステム設計において有効である。
RAG本格活用に向けた課題
RAG本格活用に向けた課題として、精度向上のノウハウは急速に発展している一方で、RAGを評価する仕組みが未整備であり、エンタープライズにおける本番運用レベルに達していないケースが多く見られる点が挙げられる。
現状では、評価が人手や感覚に依存することが多く、何をどう評価すべきかについて依然として手探りの状態であることが多い。
実際の案件でも、ドメイン・エキスパートが出力の妥当性を確認し、適宜修正するプロセスで進められており、体系的な評価基準が確立されていない中、進めていることが多々ある。
その結果、精度向上や評価に関する試行錯誤は属人化しやすく、再現性や標準化が困難な状況である。今後は、評価のあり方を整理し、現状の課題や既存ツールを振り返りながら、どのように精度評価を実現できるかを検討する必要がある。
Part2では、こうした評価手法の方向性について具体的に整理していく。