Text=岡元 朋子、江口 陽子、細野 友基 (日本アイ・ビー・エム・システムズ・エンジニアリング)
AI運用担当者とAIオーナー、それぞれの悩み (→★小見出し)
AIアプリ運用担当者(例:鈴木花子氏)は、日々Google NotebookLMを使ってAIのパフォーマンスを評価し、Excelでグラフ化するなど、属人的かつ工数のかかる作業に追われている。
一方、AIオーナー(例:佐藤太郎氏)は、ユーザーからの問い合わせやクレームに対するAIの応答品質を把握したいが、評価指標が担当者によって異なるため、横並びでの比較が困難という課題を抱えている。
この問題を解決するために評価用ツールを使用することで、評価指標の統一や、簡単な可視化を実現できる。

watsonx.governance
RAG評価を標準化するツール
IBMが提供する「watsonx.governance」は、AIモデルの評価を標準化・可視化できるツールである。RAG評価では、図表2のような指標を用いてAIの回答品質と検索品質を定量的に評価できる。

これらの指標により、AIの応答がどれだけ適切か、検索結果がどれだけ有効かを客観的に判断できる。また、Part2で紹介した3つの評価指標(回答の関連性、忠実性、コンテキストの関連性)も含まれている。
RAG評価を実施するためのステップ
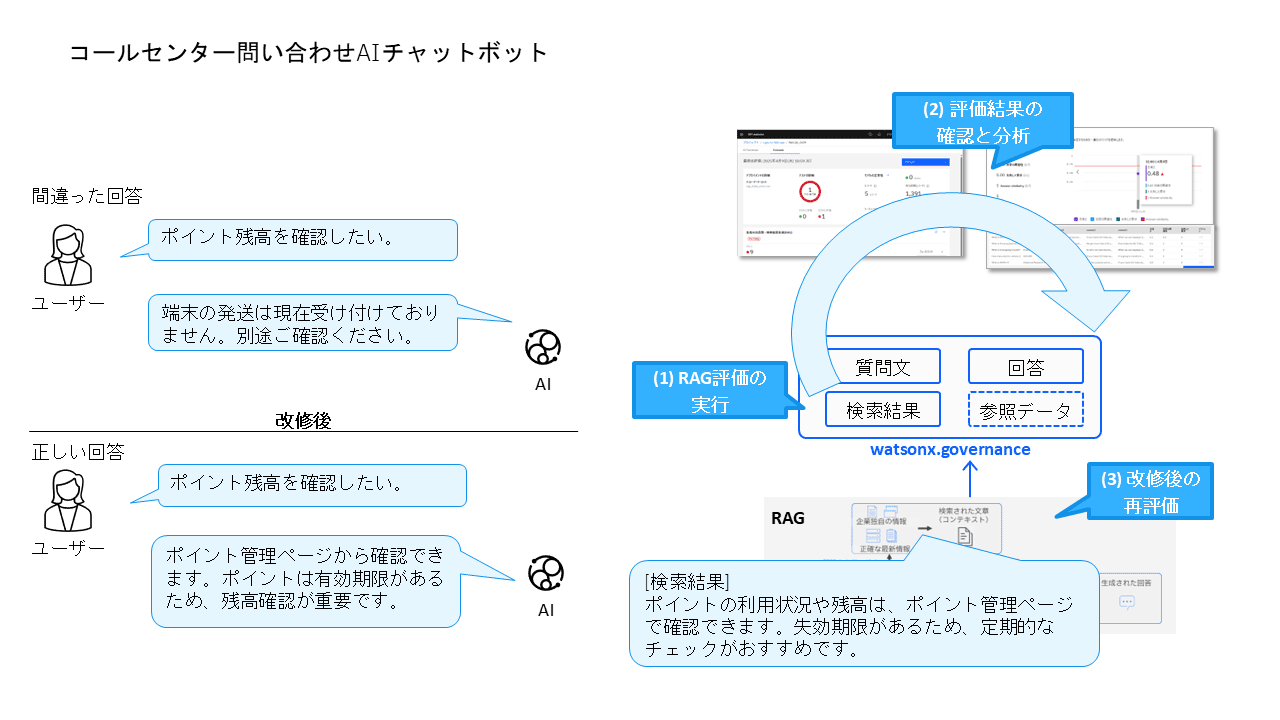
ここでは、コールセンター向けAIチャットボットを題材に、以下のようなRAG評価プロセスの例を紹介する。
(1)RAG評価の実行:入出力のCSVを用意して評価を実施。
(2)評価結果の確認と分析:スコアが低い箇所を特定し、詳細を確認。
(3)改修後の再評価:修正後に再度RAG評価を行い、改善を確認。
この一連の流れにより、評価の標準化と可視化が可能となり、運用効率が大幅に向上する。
(1) RAG評価の実行
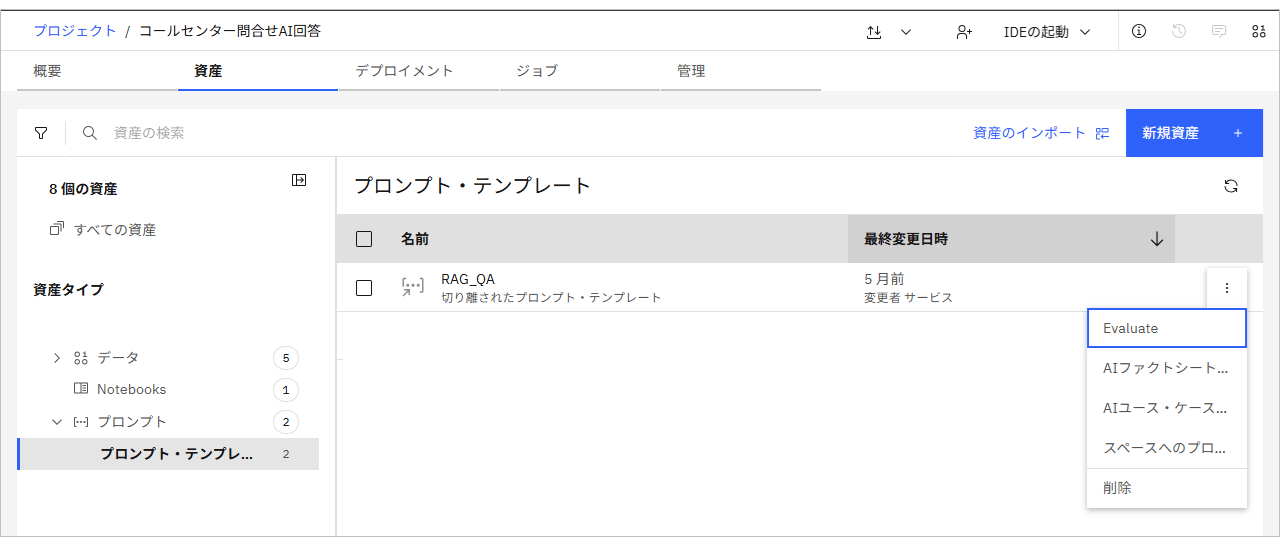
watsonx.governanceでは、プロンプト・テンプレート(*1)を選択し、「Evaluate」をクリックすることで評価設定ウィザードが起動する。
*1 プロンプト・テンプレートとは、AIに指示(プロンプト)を出すための、事前に定義された「定型文(ひな形)」のこと
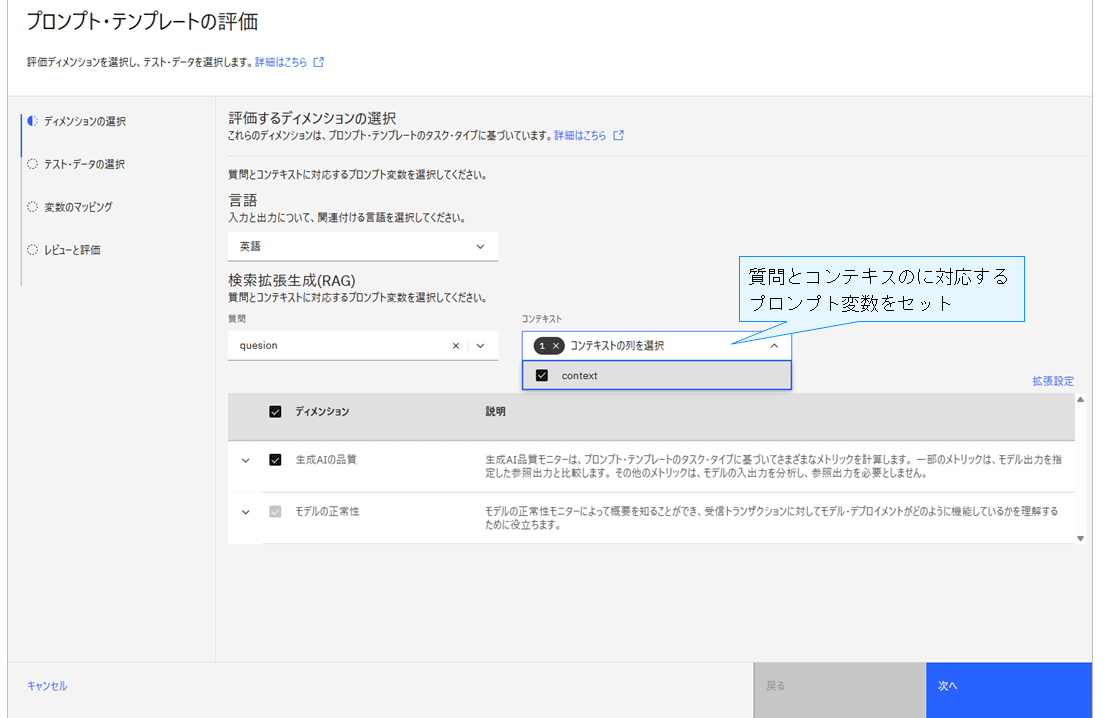
評価には、プロンプト変数(*2)として質問文(question)と検索結果(context)を指定し、CSV形式の評価対象データをアップロードする。
*2 AIへの指示(プロンプト)内で、実行時に動的に置き換えるためのプレースホルダーのこと
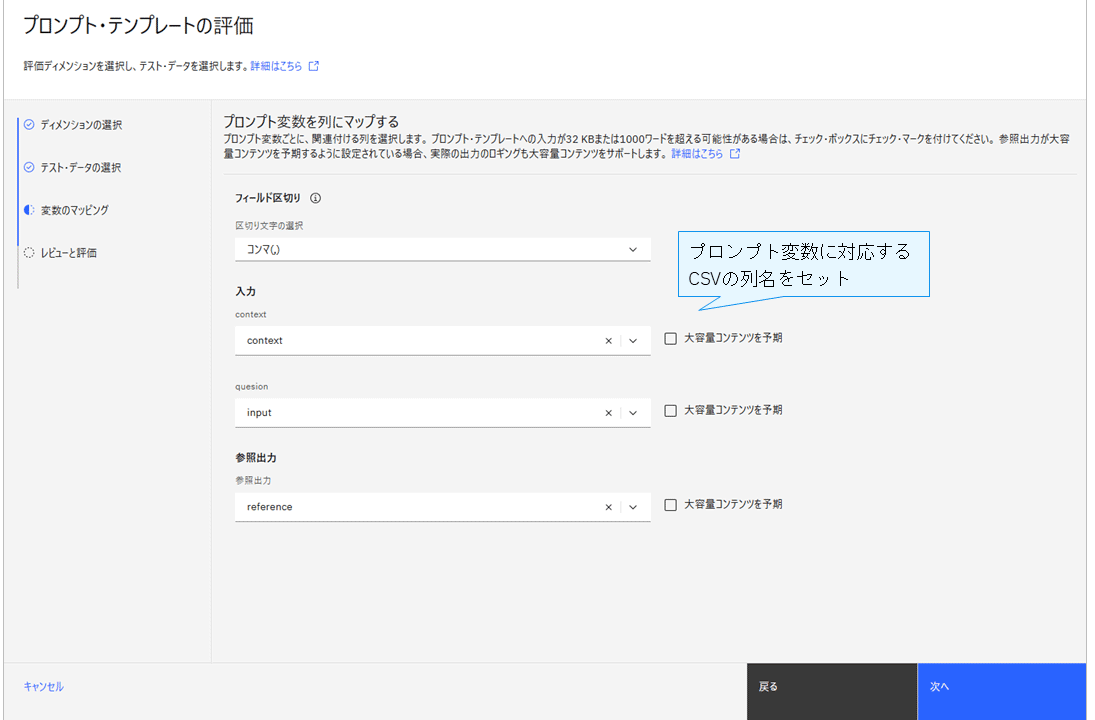
CSVには、以下の列を含む。
・input:ユーザーの質問
・context:検索結果
・generated_text:AIの生成回答
・reference:正解データ
watsonx.governanceの評価用データは日本語にも対応しているが、2026年1月時点では回答品質や検索品質などの一部評価指標が日本語未対応のため、評価は英語データで実施している。

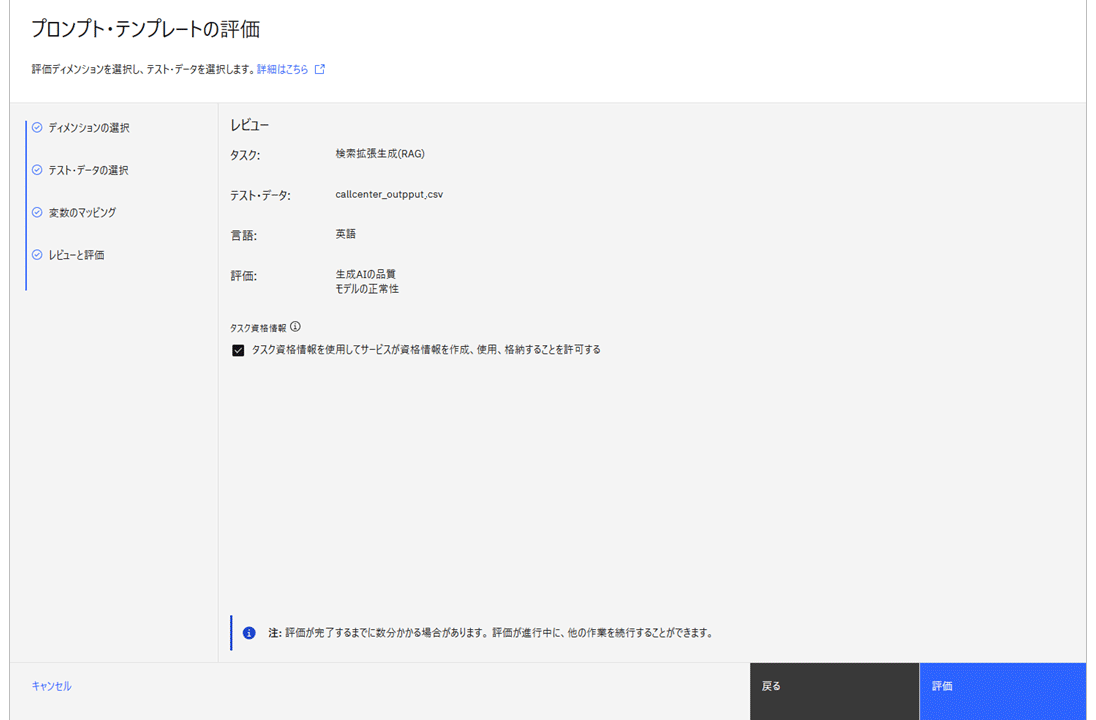
プロンプト変数とCSVの列名をマッピングし、内容を確認後「評価」をクリックすると、RAG評価が開始される。
(2)評価結果の確認と分析
評価結果は最初にサマリー画面に表示され、設定した閾値を下回る項目には赤い丸が付き、「テスト失格」となる。「生成AIの品質」欄には、RAG評価の各指標が一覧で表示され、詳細を展開することでスコアと違反度合い(閾値との差)を確認できる。
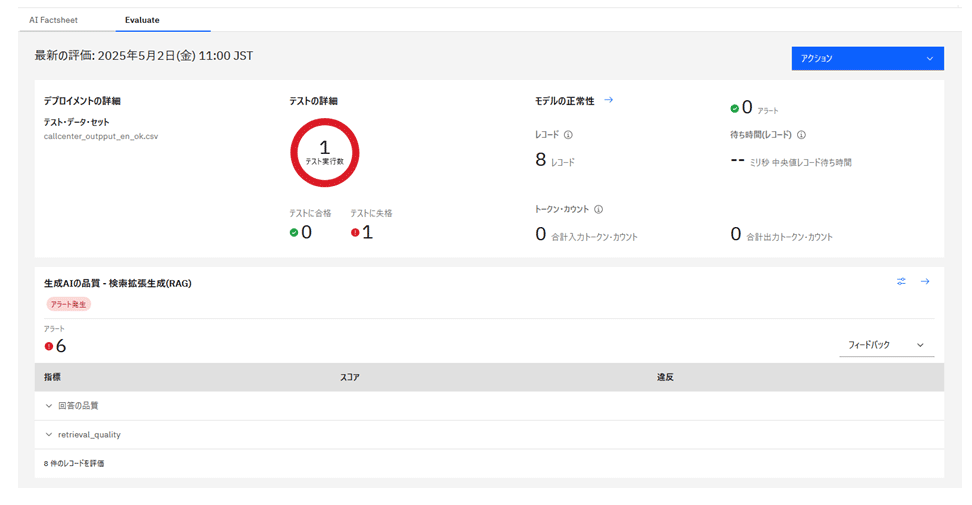
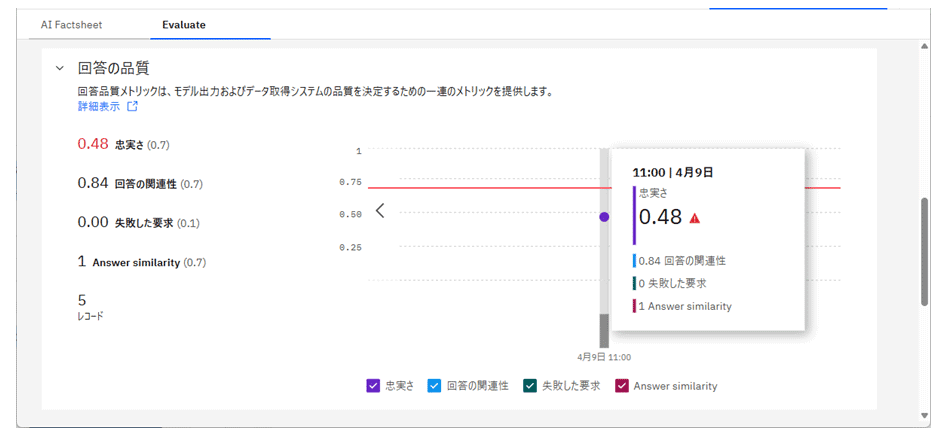
より詳細を確認したい場合、評価対象として投入したCSVファイル内のレコードごとに、質問・回答・コンテキスト・スコアを確認できる。

たとえば、「ポイントを確認したい」という質問に対して、コンテキストは「ポイント管理ページで確認できます」というように正しい検索結果を拾えているのに対して、質問の回答としての生成結果は検索結果に基づかないおかしな回答を出力している。
この例では、コンテキストの関連性スコアは高く問題なかったが、忠実さスコアが低く、閾値を下回っている。
コンテキスト関連性は高く、適切な検索結果が取得できていたにもかかわらず、生成された回答が文脈に基づかない「幻覚(ハルシネーション)」を含んでいたためである。
(3)改修後の再評価
このような評価結果をもとに、Part2で紹介した「RAG評価低下時の対応」に従って改修する。
改修後、初回同様にCSV形式の評価対象データを用意してアップロードし、再評価を実施する。
評価結果画面では、すべての指標が閾値を超えており、閾値違反が発生していないため、緑色の丸で「テスト合格」と表示されている。
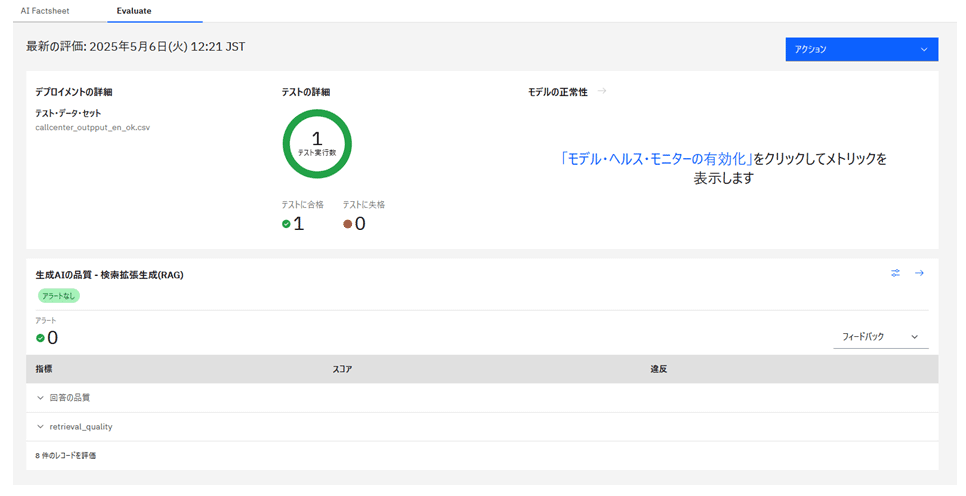
評価の詳細画面を確認すると、忠実さスコアも改善され、違反は解消されている。
たとえば、「ポイント残高を確認したい」という質問に対して、「ポイント管理ページから確認できます」というように、コンテキストに基づいた適切な回答が生成されていた。

実運用に向けた留意点
今回の例では、デモ用に作成したテストデータであり、忠実さスコアが1という極端な結果となっているが、実際の開発では何度も評価を繰り返し、生成結果の許容範囲を見定め、適切な閾値を設定して監視する必要がある。
watsonx.governanceは、こうした品質管理を効率化し、AIの信頼性向上に貢献するツールである。
RAG評価の第一歩は「見える化」から
RAG評価は、AIの信頼性を高めるための鍵である。ツールを活用することで、評価指標の統一と可視化が可能となり、AI運用の効率と品質が飛躍的に向上する。
RAG評価の導入を検討している企業や開発チームにとって、watsonx.governanceは有力な選択肢となる。まずは小規模な評価から始め、評価指標の標準化と可視化による運用改善を体験してみるとよいだろう。