日本総研は10月10日、「大規模言語モデルのビジネス活用の新展開 ~ChatGPTのプロンプトエンジニアリングを超えた活用法と今後の展望」と題する調査レポートを発表した。
現在、ChatGPTを筆頭に生成AIのビジネス適用が進んでいるが、現状の生成AIにはハルシネーション(誤りを含む情報を回答する事象)や秘密情報・個人情報の漏えいを惹起する懸念があり、また企業固有の知識・情報を取り込めないなどの制約もある。
今回のレポートは、現状の制約を解決する取り組みについて解説したもので、A4判10ページにコンパクトにまとめられている。
最初に、大規模言語モデル(LLM)のビジネス活用の「新展開」として、次の2つの手法を解説している。
(1)LLMに組織固有の知識(業務知識、業務マニュアルなど)を反映させて利用する、「RAG」(Retrieval-Augmented Generation)に代表される手法
(2)ChatGPT以外のオープンなLLMをチューニングして用いる手法
(1)のRAGについては、「外部の情報源として組織内の文書を用いることで、組織の固有知識を反映させてLLMを活用することができる」と述べ、図を示して概要を解説している。RAGのフローは次のとおり。
①利用者がチャットシステムにテキストで質問する → ②その質問の回答に関連しそうな文書を文書DBから検索し、結果を得る → ③検索結果と質問文をLLMに渡す。このとき、LLMは単に自身が持っている知識だけでなく、関連する組織内の文書(知識を踏まえて回答を生成できるようになる。また、組織内の文書に基づいて回答するため、誤った回答を生成する可能性も低減できる → ④LLMが生成した回答文をユーザーに返答する
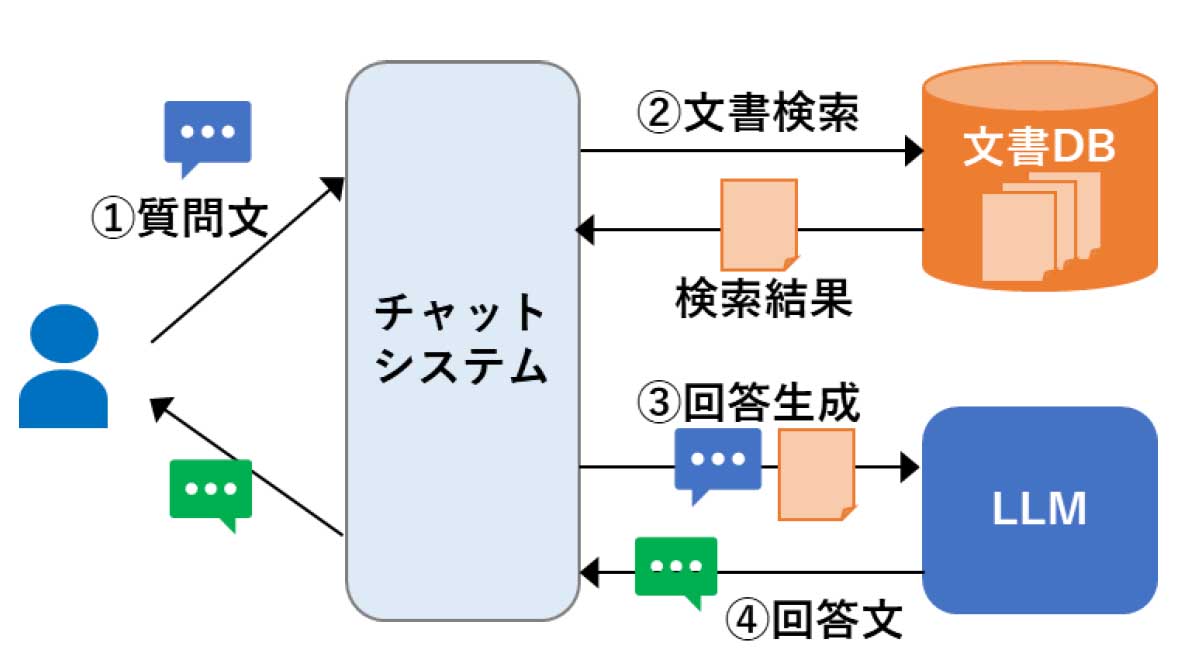
RAGは現在、多くの組織がPoC(実証実験)や社内環境の整備を進めており、RAGの仕組みをサービスとして提供する事例もある(IBMが先ごろ発表したwatson Code AssistantもRAGを採用)。調査レポートは「RAGの仕組みを実現するハードルは今後低くなっていくと考えられる」と述べる。
(2)の「ChatGPT以外のオープンなLLMをチューニングして用いる手法」については、以下の4つのチューニング手法を整理している。
①言語モデルの追加学習
②特定タスクに特化した学習
③指示に対応するための学習
④人間のフィードバックによる強化学習
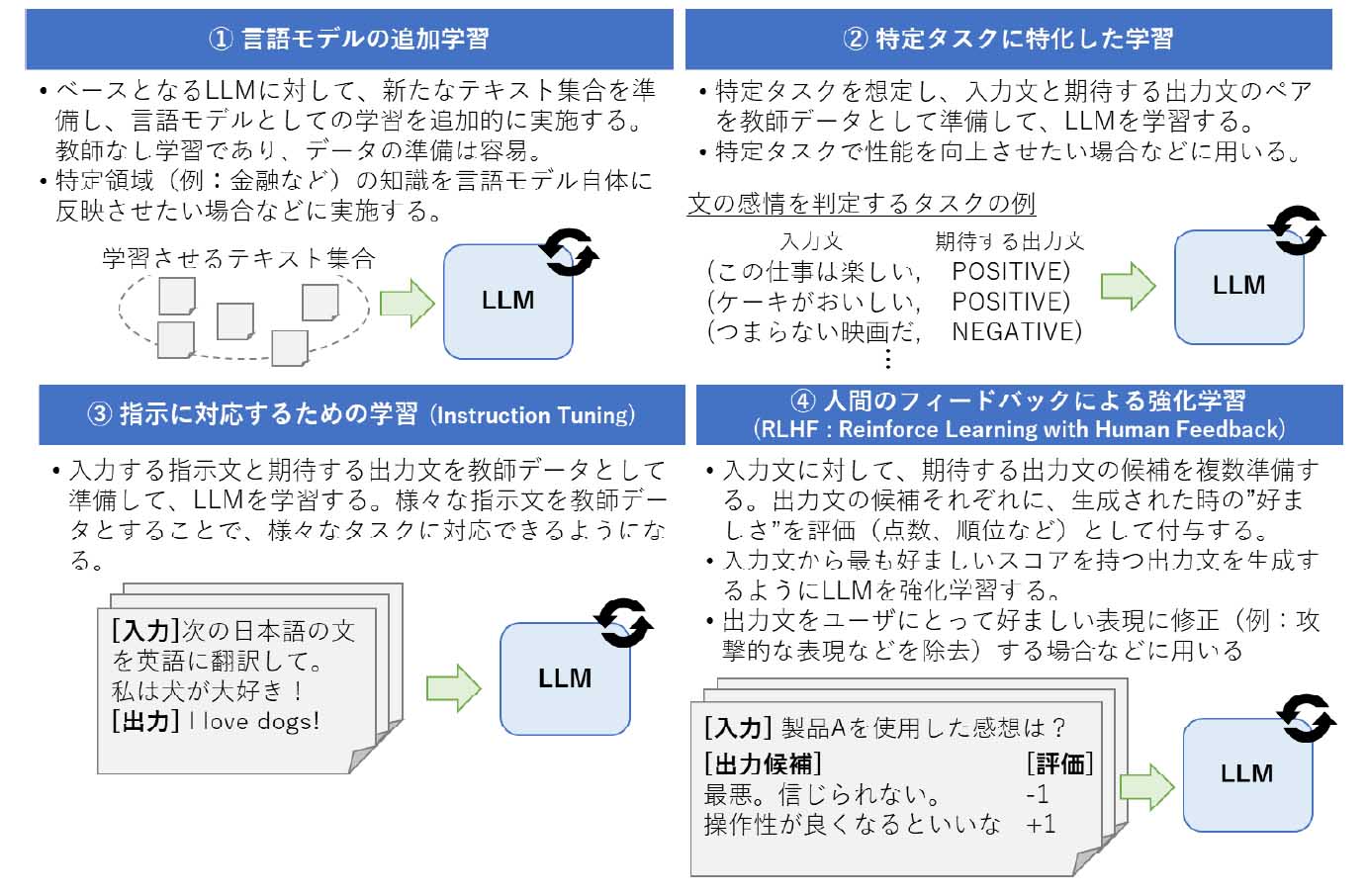
このうち、③「指示に対応するための学習」の適用が進んでいるが、「LLMに望ましい挙動をさせるためのデータセットの整備方法は研究途上」にあり、現状は人手作業に頼っていること、それを克服するための方法として、データセットをLLM自身に作成させる研究も行われており、「今後はデータセットの作成を省力化するための研究が活発になるであろう」と予想している。
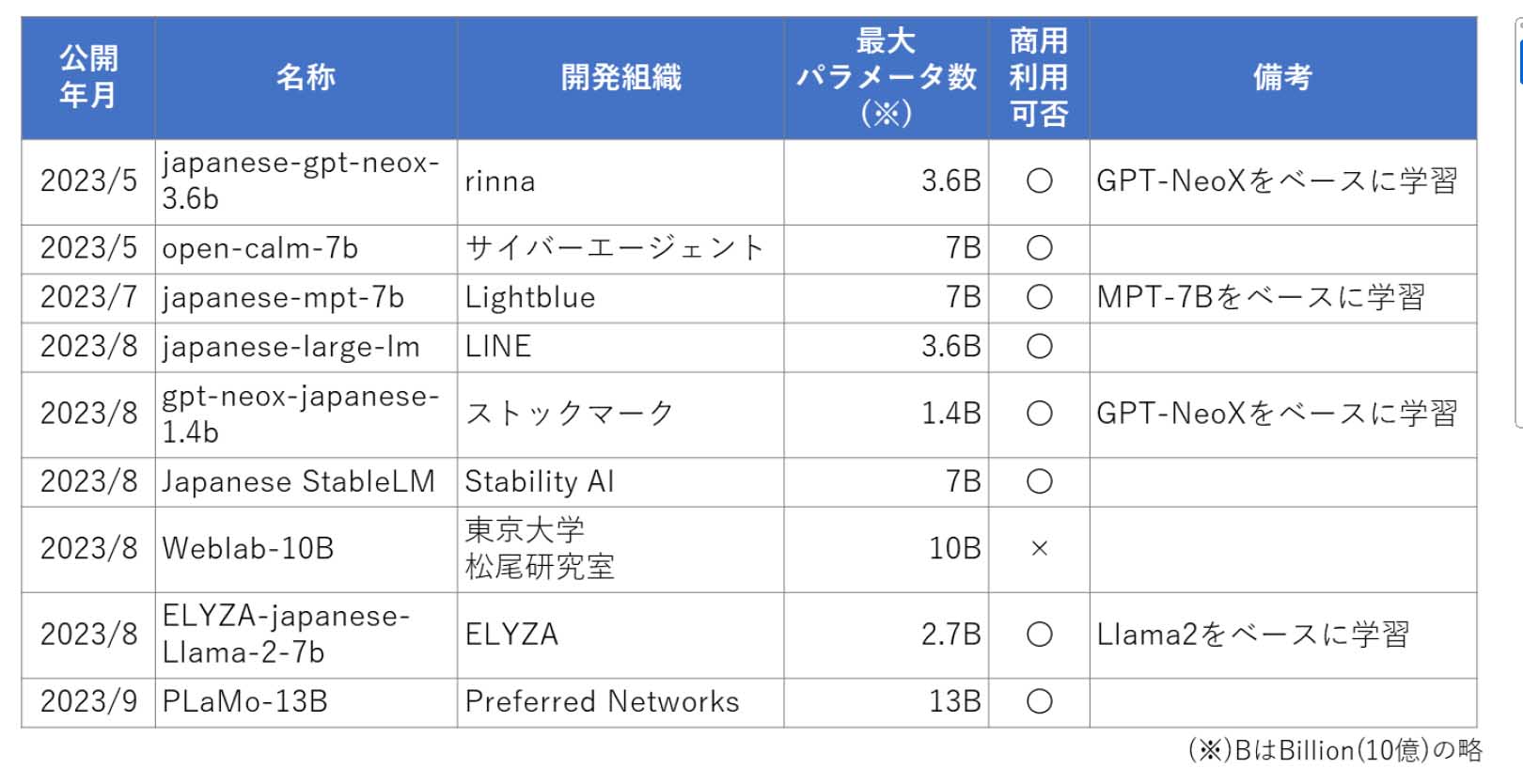
現在、ChatGPT・GPT-4(OpenAI開発)やPaLM2(Google開発)の技術情報(ソースコードやパラメータ数など)は非公開で、詳細は不明である。その一方で、ベンチャー企業、大学、コミュニティなどから独自開発のLLMを公開する動きが進んでいる。その中には商用利用が可能なLLMもあり、ユーザーにとってLLM活用の選択肢が増えつつある。
調査レポートは、日本語に特化したオープンなLLMの代表例を紹介している。また、組織がオープンなLLMを活用する動機についてまとめ、「これらの動機を持つ組織は、オープンなLLMの活用も検討の余地がある」と指摘する。

調査レポートは「今後の展望」として、
・LLMへの過度な期待が落ち着き、慎重に活用先を見極めるフェーズに移行する
・LLM活用の深化として、まずはRAGの活用が進展する
・データセットの整備やモデル開発の共同化の動きが活発化する
を挙げている。
・調査レポート「大規模言語モデルのビジネス活用の新展開 ~ChatGPTのプロンプトエンジニアリングを超えた活用法と今後の展望」
https://www.jri.co.jp/MediaLibrary/file/advanced/advanced-technology/pdf/14543.pdf
[i Magazine・IS magazine]