
Text=岡元 朋子、江口 陽子、細野 友基 (日本アイ・ビー・エム・システムズ・エンジニアリング)
RAG評価の必要性
RAGシステムを運用する際には、継続的な評価が必要になる。その理由として、まず文書が適切に取得できているかを確認する必要があり、次にLLMが誤った回答を生成していないかを監視することが求められる。また、プロンプト設計に問題がないかどうかも重要なチェックポイントとなる。
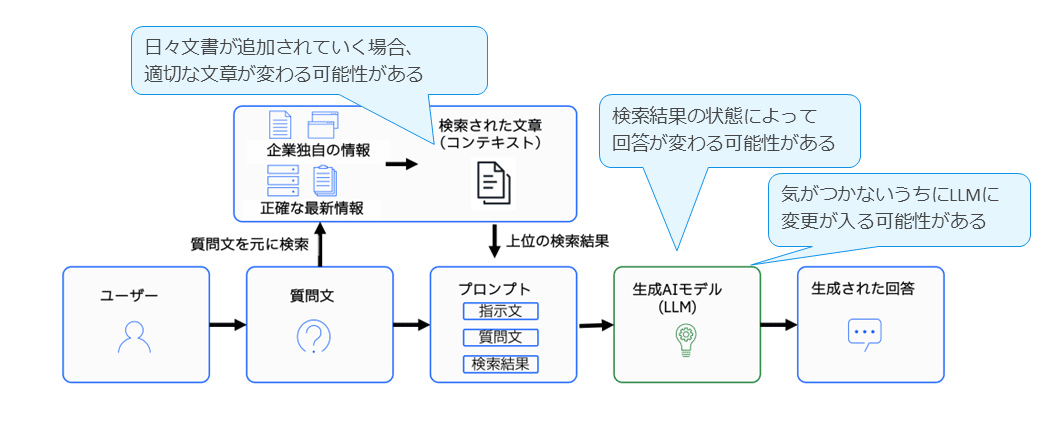
RAG は日々更新される文書を参照する仕組みであるため、検索結果やモデルの更新によって生成される回答が変動する可能性がある。このような性質から、システムが正確に動作しているかを定量的に確認する評価が重要となる。
RAGの評価方法
RAGの評価方法は、大きく機械的(オフライン)評価と人的(オンライン)評価の2つに分類される。
機械的評価は、自動的に算出可能な定量指標を用いて評価を行う方法であり、再現性や客観性が高いという利点がある。しかしその一方で、文脈に基づく妥当性や人間の理解に沿った判断を十分に捉えられない可能性がある。
これに対して、人的評価は実際のユーザーや専門家による主観的な評価を行う方法であり、人間の視点に基づいたより精緻な品質判断が可能である。ただし、実施には時間やコストがかかるという課題がある。
そのため、実運用においては両者を組み合わせて活用し、より信頼性の高い総合的な評価を行うことが推奨される。
機械的に評価可能なオフライン評価には、いくつかの代表的な手法が存在する。
正解データを用意しない評価方法
この方法では、質問、検索によって取得された文書、そしてLLMが生成した回答を入力として、専用の評価ツールなどを用いて性能を測定する。正解データを準備する必要がないため効率的に実施できる一方、生成された回答がユーザーの期待とどの程度一致しているかを直接判断できないため、期待内容との乖離が生じる可能性がある。
正解データを使用しない方法(LLMに判定させる方法)
この方法は、LLMに対して回答の評価を行わせる手法、いわゆるLLM as a Judgeと呼ばれる。生成された回答の品質を別のLLMに判定させることで、人手による主観的評価に近い判定を得られると言われている。ただし、こちらも正解データとの比較ではないため、期待内容との乖離が発生し得る点に加え、LLMが評価者となるため評価結果が毎回一定になるとは限らないという課題がある。
正解データを利用する評価方法
この手法では、あらかじめ用意した正解回答と生成回答を比較し、一致度などを指標として性能を評価する。ユーザーが期待する回答と照らし合わせて適切に評価できる点が大きな利点である。しかし、正解データを作成するための工数が大きく、また回答の自由度が高い質問では単純な一致度指標では評価が難しいという制約もある。
以上のように、オフライン評価にはそれぞれ利点と課題があり、目的や利用環境に応じて適切な方法を選択することが重要となる。

主な評価項目
RAGの評価では、いくつかの主要な要素を基にして総合的な分析を行う。
具体的には、まずユーザーのクエリーとして与えられる質問文、次に検索によって取得された文書(コンテキスト)、そしてシステムが生成した回答が評価対象となる。
さらに正解データが用意されている場合には、期待される回答として比較の基準となる。これら4つの要素を踏まえたうえで、各種の評価指標を用いて検索と生成の両面から性能を測定する。
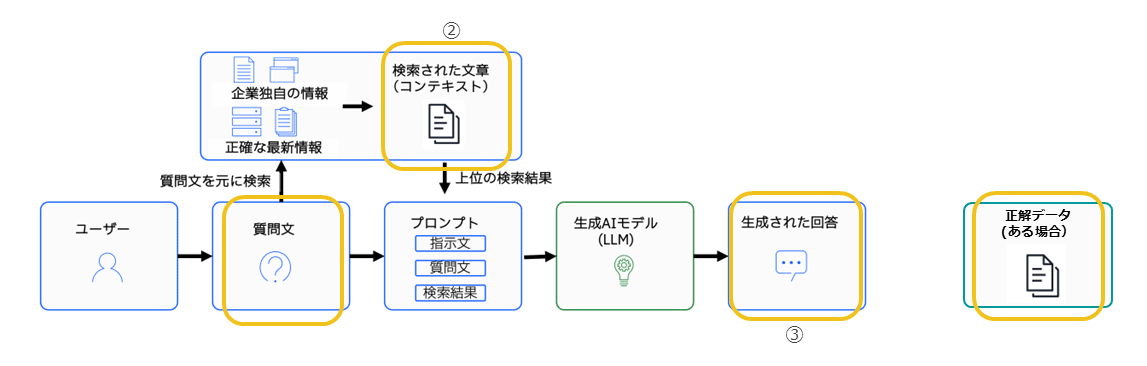
主な評価指標
基本的な指標
RAGの評価で用いられる基本的な指標には、いくつかの重要な項目がある。
Context Relevance(コンテキストの関連性)
検索された文書が、質問内容とどの程度関連しているかを評価する指標である。
Faithfulness(忠実性)
生成された回答が、検索文書の内容に基づいているかどうかを測るものであり、事実誤りやハルシネーションを検出するために重要な役割を果たす。
Answer Relevance(回答の関連性)
生成された回答が、質問に対してどれだけ適切に応答しているかを評価する指標であり、ユーザーの意図に沿った回答になっているかを判断するために用いられる。
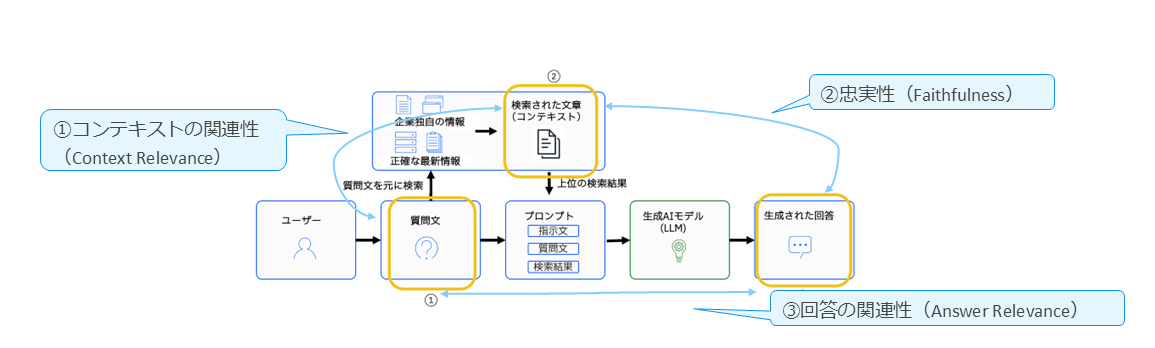
正解データがある場合の追加指標
正解データが存在する場合には、基礎的な指標に加えて、より詳細な評価を行うための追加指標を用いることができる。
Context PrecisionとContext Recall(文脈の精度と文脈の再現率)
検索された文書がどの程度正しい情報を含んでいるかを評価する指標である。Context Precisionとは取得した文書のうち正しいものが占める割合を示し、Context Recallは正しい文書をどれだけ取りこぼさずに取得できたかを表す。
Answer Correctness(回答の正確性)
生成された回答を正解データと照合し、その正確性を測定するものである。
Context Entities Recall(文脈固有表現の再現率)
回答に必要となるキーワードやエンティティが検索文書に適切に含まれているかを評価する指標である。
Noise Sensitivity(ノイズへの敏感性)
回答に不要な情報が紛れ込んでいないかを確認するための指標であり、生成品質をより精緻に評価するために役立つ指標である。
評価ツールの紹介
代表的なRAG評価ツールやフレームワークとしては、いくつか広く利用されているものがある。
Ragas(RAG Assessment)はその代表例であり、GitHub で公開されているほか、arXiv:2309.15217 として論文も発表されている。
Ragas (RAG Assessment)
GitHub: https://github.com/explodinggradients/ragas
論文: arXiv:2309.15217
また、Amazon ScienceによるRAG Checkerも重要なツールとして位置付けられている。こちらもGitHub上で公開されているほか、関連論文がarXiv:2408.08067にて提供されている。
RAG Checker(Amazon Science)
GitHub: https://github.com/amazon-science/RAGChecker
論文: arXiv:2408.08067
これらのツールは、RAG システムの性能を効率的かつ体系的に評価するために活用されている。
テストデータの自動生成ツール
評価用のQ&Aデータセットを自動的に生成するためのツールも、近年充実してきている。
たとえば、Ragas Testset Generationは、与えた文書から質問と回答の組み合わせを自動生成するツールであり、社内規程の文書から「勤務時間は?」といった質問とその回答を生成するなど、評価データ作成を効率化する用途で活用できる。詳細は公式ドキュメントで公開されている。
Ragas Testset Generation
https://docs.ragas.io/en/stable/getstarted/rag_testset_generation/
また、Expert GenQA は文書のトピックを分類し、各トピックについて専門家が作成したQ&Aを基に、LLMが類似した質問を自動生成する仕組みを備えている。
これにより、専門性の高い領域でも高品質なテストデータを生成することが可能になる。関連する研究は論文として公開されている。
Expert GenQA
論文: https://arxiv.org/abs/2503.02948
評価結果が低い場合の対応案
実際に評価を行った際、主だった以下の項目の数値が極端に下がるような場合には、原因に応じていくつかの対処法を検討する必要がある。
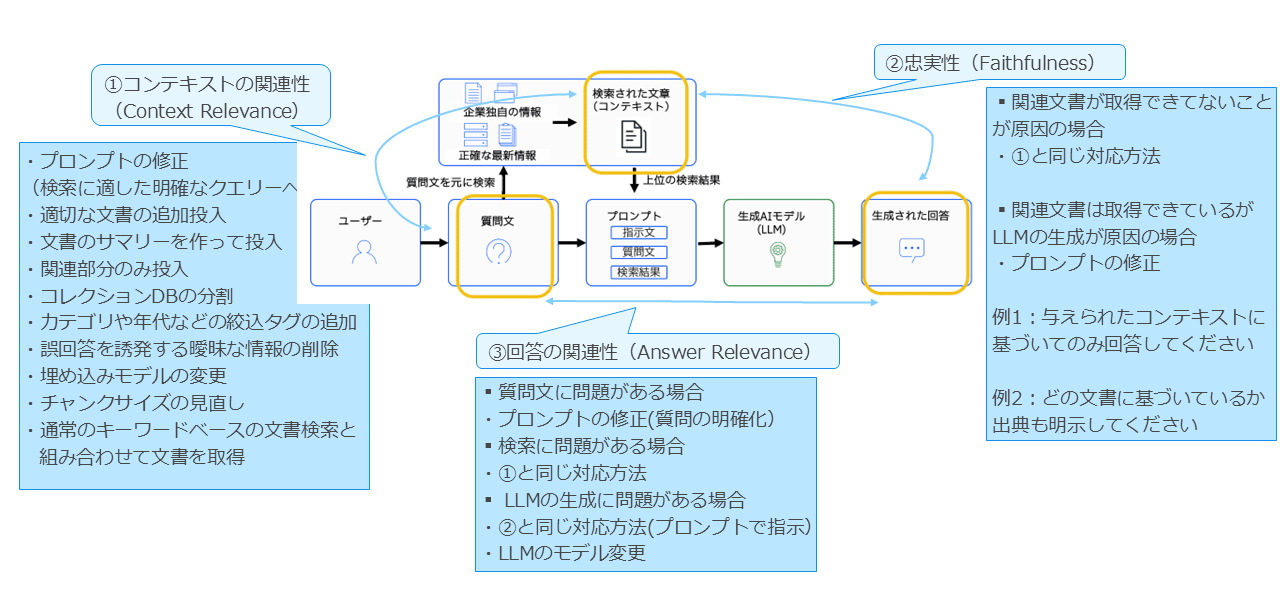
コンテキストの関連性が低い場合
検索精度および生成品質の向上を目的として、複数の対策を講じることが有効である。
まず、検索に適したより明確なクエリーとなるようプロンプトを修正することで、取得される文書の精度向上が期待できる。
また、必要な情報が不足している場合には、適切な文書を追加投入する、あるいは文書の要約を作成して投入することで情報密度を高めることが可能である。
さらに、関連部分のみを抽出して投入する手法は、ノイズを削減し、検索および生成段階の品質を向上させるうえで有効である。
データベース構造に関する改善としては、コレクションを適切に分割し、カテゴリや年代などの絞り込みタグを付与することで、検索対象を明確化できる。
また、誤回答の原因となり得る曖昧な情報を削除することも、ノイズの低減に寄与する。モデル側の調整としては、埋め込みモデルをより適合するものに変更したり、チャンクサイズを見直したりすることで、文書の意味表現精度を改善できる。
さらに、ベクトル検索だけでなく、従来のキーワードベース検索と併用して文書を取得することも、検索網羅性の向上に有効な手法である。
これらの対策を組み合わせることで、コンテキストの関連性を高め、RAGシステム全体の性能を向上させることが可能となる。
忠実性が低い場合
忠実性が低下する要因としては、大きく分けて2つのケースが考えられる。
1つ目は、そもそも回答に必要となる関連文書が十分に取得できていない場合である。この場合は、コンテキストの関連性が低い場合と同様の対策が有効であり、クエリー設計の改善、文書の追加投入、データベース構造やタグの最適化、埋め込みモデルやチャンクサイズの見直しなど、検索精度を向上させるための手法を適用することが求められる。
2つ目は、関連文書が適切に取得されているにもかかわらず、LLMの生成段階で誤りが生じている場合である。この場合には、プロンプトの修正が主な対策となる。
具体的には、出典文書に基づいて回答するよう明確に指示を追加する、利用すべき情報範囲を限定する、推測による回答を避けるよう促すなど、生成方針を適切に誘導するプロンプト設計が重要となる。
このように、忠実性の低下は検索段階と生成段階のいずれにも起因し得るため、原因を適切に切り分け、それぞれに応じた対策を講じることが重要である。
回答の関連性が低い場合
回答の関連性が低い場合には、その原因に応じて複数の改善策を検討する必要がある。
まず、質問文自体に問題があり、意図が不明確であることが原因となっている場合には、プロンプトを修正し、質問内容をより明確に記述することで、適切な情報検索および回答生成を促すことができる。
次に、検索段階に起因する問題で回答の関連性が低下している場合には、コンテキストの関連性が低い場合と同様の対策が有効となる。具体的には、クエリー設計の見直し、文書の追加や再構成、データベース構造の最適化、埋め込みモデルやチャンクサイズの調整など、検索精度の向上につながる改善が求められる。
さらに、LLMの生成過程に問題がある場合には、忠実性が低い場合と同様、プロンプトにおいて回答方針を明確に指示することが重要である。
たとえば、参照文書の内容に基づいて回答することを明示する、推測による回答を避けるよう指示するなど、生成の制御を強化することが有効である。
また、利用しているLLM自体の性能に起因する可能性もあるため、必要に応じてより適したモデルに変更することも検討すべきである。
以上のように、回答の関連性が低い場合には、質問文、検索過程、生成過程の3つの観点から原因を分析し、それぞれに応じた適切な対策を講じることが重要となる。
RAGの評価においては、「検索」と「生成」の両方の段階を定量的に測定することが重要である。
特に、生成内容の正確性を示すFaithfulnessと、質問との関連度を示すRelevanceを中心に、複数の指標を組み合わせて評価することが望まれる。
また、Ragasのような自動評価ツールを活用することで、評価作業を効率化することが可能である。
さらに、watsonx.governanceなどのガバナンスツールを用いて評価結果を可視化することも、システムの透明性や改善の方向性を明確にするうえで有効である。
<参考資料>
参考資料としては、RAG 評価や関連ツールに関する公式ドキュメントおよび論文が公開されている。
Ragas に関しては公式ドキュメントが提供されており、評価指標や使用方法について詳細に説明されている。
Ragas公式ドキュメント:https://docs.ragas.io
また、RAG Checker については arXiv に論文が公開されており、評価手法の特徴や実験結果を確認することができる。
RAG Checker論文: https://arxiv.org/pdf/2408.08067
さらに、Expert GenQA についても関連論文が公開されており、テストデータ生成手法の概要や有効性を知ることができる。
Expert GenQA論文: https://arxiv.org/abs/2503.02948
これらの資料は、RAG評価を理解し実施するうえで有用な参考情報となる。









