テキストアノテーションにより
非定型データから洞察を得る
ここでは、テキストマイニングを支える重要な要素である「テキストアノテーション」と呼ばれる手法、およびテキストアノテーションを実行する「IBM Watson Knowledge Studio」(以下、WKS)の概要と使用方法について解説する。
一般名詞としての「アノテーション(Annotation)」という言葉には、「注釈」「注記」などの意味がある。しかしIT用語としては「情報に注釈としてメタデータを付与する」、もしくは「そのように付与されたメタデータ」という意味で使われる。
すなわちテキストアノテーションとは、文章に注釈としてメタデータを付与する作業であり、自然言語で記述された非定型情報を、取り扱いが容易な定型情報に変換する。これは大量の文書データを効果的に活用するための有効な下準備となる。
WKSでは、いくつかのテキストアノテーション手法を提供している。それぞれの手法の特徴や長所・短所を理解し、これらを使い分け、あるいは組み合わせて使用することで、効率的なテキストアノテーションが可能になる。またWKSはほかのWatson製品と連携することで、テキストマイニングのパフォーマンスをさらに高められることも大きな特徴である。
企業には、さまざまな業務で蓄積された多種多様な文書データ 、そしてその文書データをビジネスに活用する事例が多く存在する。以下に、その一例を挙げよう。
・製造/サービス業で、製品やサービスを利用する顧客と企業の間でやり取りされたメール、電話、チャット、アンケート回答、顧客がWeb上に書き込んだブログや口コミサイトの内容を分析し、 製品・サービスの品質改善につなげる。
・医療業界で、カルテに記載された症状、所見、治療、投薬履歴などの記録を分析し、今後の診断や治療に役立てる。
・ニュースや新聞記事などの情報を分析し、経済動向や株式市場の変動を予測する。
ところが、これらの文書データは自然言語で記述された非定型情報なので、そのままでは効果的な活用が難しい。大量に蓄積したものの、利用されずに埋没しているケースが少なくない。テキストアノテーションは、このような非定型情報を活用しやすい定型情報に変換するのに役立つ。
たとえば図表1は自動車業界の事例であり、文章で記述された事故報告書に対してテキストアノテーションを実施することで、非定型情報から定型情報へ変換する様子を示している。図表上のように、自然言語による非定型情報の形式で情報を蓄積すると、蓄積される文書の数、それに含まれる文章の量、表現の種類が増加するにつれ、情報の探索・分析・可視化は次第に困難となる。

それよりも図表下にあるように、定型情報の形式で情報を蓄積するほうが、あとで情報を探索・分析・可視化する場合に有利となる。
車の年式:2005
車のメーカー:Ford
事故の内容:two-vehicle crash
(車の衝突)
事故の発生日:July 2014
ここで、図表上のような非定型情報を、図表下のような定型情報に変換するには、次のように、文書に含まれる要素のそれぞれが何を意味するかを示すメタデータを付与する作業、すなわちテキストアノテーションが必要になる。
2005という数字は、車の年式を意味する。
Fordという単語は、車のメーカー名を意味する。
two-vehicle crashという連語は、事故の内容を意味する。
July 2014という英数字は、事故の発生日を意味する。
WKSで業界固有の
用語や表現に対応する
WKSは、文書データを取り込んでテキストアノテーションを実行したり、テキストアノテーションを人間に代わって自動的に実行する「アノテーター」(情報抽出器)を作成するIBM製品である。
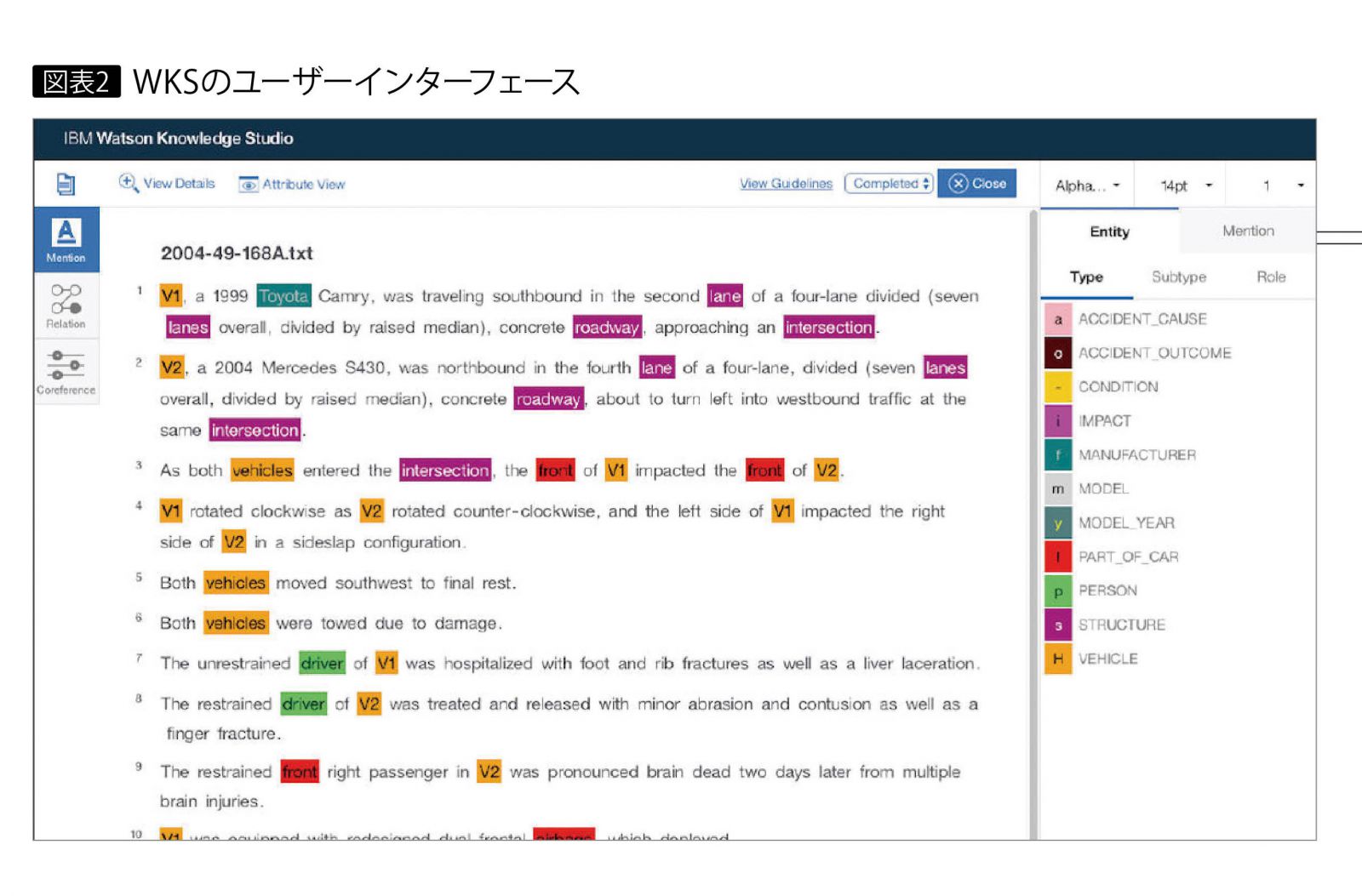
図表2は、WKSを用いてテキストアノテーションを行っている画面の一例である。ITエンジニアはもちろん、ITに関する知識があまりない業務担当者でも、テキストアノテーション作業を直感的に、わかりやすく進められるユーザーインターフェースを備えている。
IBM Watsonの製品群は大きく分けて、IBM Cloud上で提供されるAPIやSaaS製品と、ユーザーが利用するマシンにインストールして使用するオンプレミス製品に大別されるが、WKSは前者のSaaS製品に該当する。
またWKSは他のWatson製品と密接に連携している。Watson Explorer、Natural Language Understanding、Watson Discovery Serviceといった他のWatson製品に、WKSで作成したアノテーターをデプロイして使用できる。
これらのWatson製品は、デフォルトで一般の用語や表現を抽出できるようにチューニングされているが、業界固有の用語や表現を捉えることは苦手である。そこで、そういった固有の用語や表現に対応するためのアノテーターを業務担当者がWKSで作成し、他のWatson製品にデプロイすることで、業界向けのカスタマイズが可能となる。
WKSによる
テキストアノテーション
テキストアノテーションと一口に言っても、文書にアノテーションできる情報や、テキストアノテーションの手法にはさまざまな種類がある。そこでWKSについて、どのような情報を文書にアノテーションできるか、またどのようなアノテーション手法が可能かについて解説する。
アノテーション手法にはそれぞれ特徴や長所・短所があり、その特性を理解したうえで適切な手法を選択し、ときには組み合わせて使用する必要がある。
WKSでアノテーションできる情報
WKSではインポートされた文書に対して、次の3種類の情報をアノテーションできる。
ⓐEntity
特定の性質をもつ単語を表す
ⓑRelation
異なる2つのEntity間の関係を表す
ⓒCoreference
異なる2つのEntityの同一性を表す
それでは「孫正義はソフトバンク1の社長です。彼はソフトバンク2のファンでもあります」という例文で、Entity、Rela
tionを定義してみよう。
ⓐEntity
Person Entity:「人」を表すEntity
Company Entity:「企業」を表すEntity
BaseballTeam Entity:「野球チーム」を表すEntity
ⓑRelation
isPresidentOf Relation: 「『人』が『企業』の社長である」というPerson EntityとCompany Entityの間の関係を表すRelation
isFanOf Relation: 「『人』が『野球チーム』のファンである」というPerson EntityとBaseballTeam Entityの間の関係を表すRelation
すると、定義したEntityが例文中の次の単語に対してアノテーションされ、加えて定義したRelationおよびCoreferen
ceが、例文中の次の単語の対に対してそれぞれアノテーションされる。
ⓐEntity
Person Entity:「孫正義」「彼」
Company Entity:「ソフトバンク1」
BaseballTeam Entity:「ソフトバンク2」
ⓑRelation
isPresidentOf Relation:「孫正義」と「ソフトバンク1」
isFanOf Relation:「彼」と「ソフトバンク2」
ⓒCoreference
「孫正義」と「彼」
WKSによるアノテーション手法
WKSではインポートされた文書に対して、次の4つの手法でアノテーションできる。
①ヒューマンアノテーション
人間の目で文書を確認し、人間の手でアノテーションを行う。図表2は、このヒューマンアノテーションを実行している画面である。
②辞書アノテーション
特定のEntityをアノテーションさせたい単語に対して、人間の手であらかじめ辞書を定義し、その辞書をもとにEntityを自動でアノテーションする。
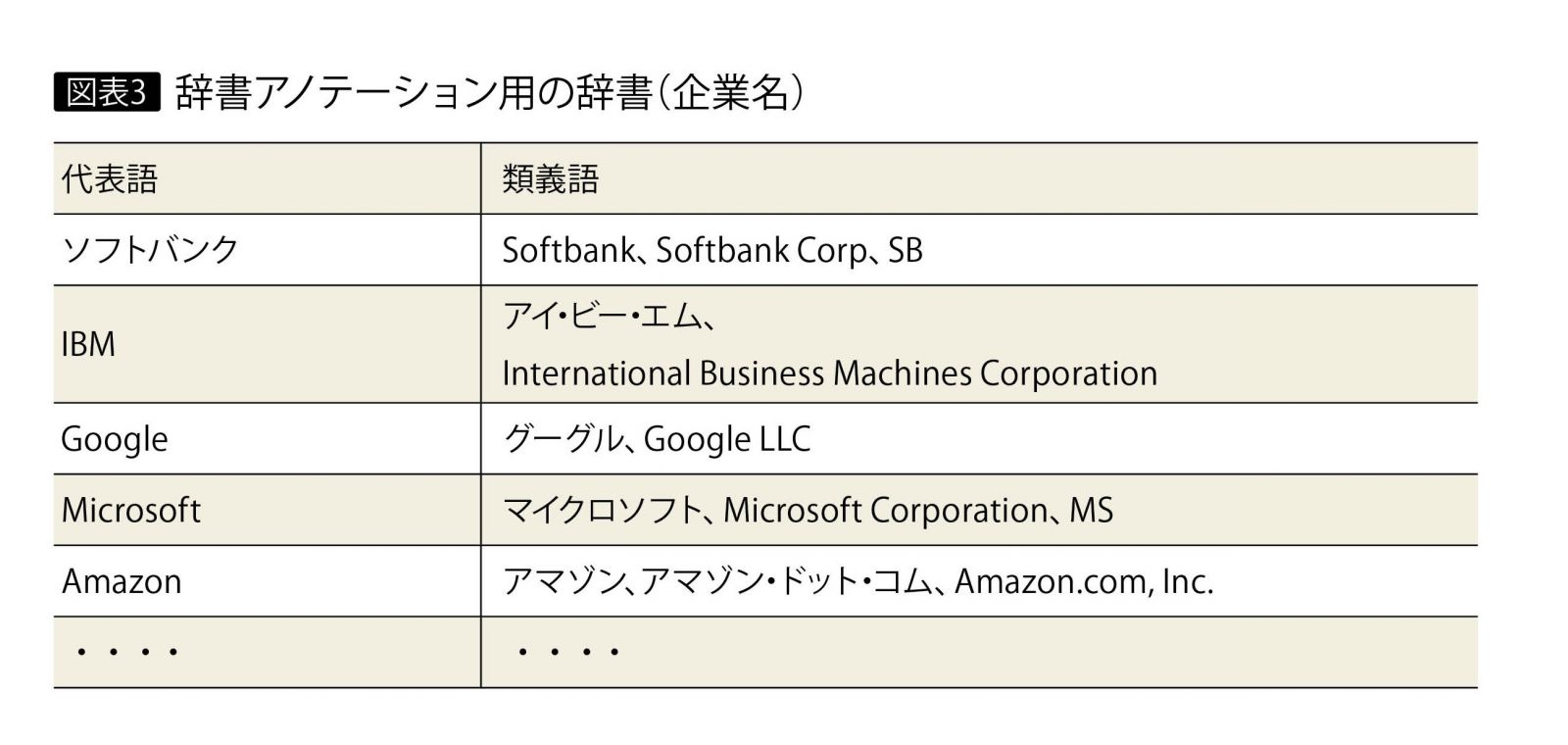
たとえば、Company Entityをアノテーションさせたい単語の辞書として、企業名を集めた辞書を図表3のように定義したうえで辞書アノテーションを実行する。その結果、アノテーション対象の文書内に出現した単語のうち、この辞書に記載されている代表語またはその類義語に一致した単語に対して、Company Entityがアノテーションされる。
③ルールベースアノテーション
辞書アノテーションで使用する辞書に加え、正規表現などを組み合わせたルールを人間の手であらかじめ定義し、そのルールをもとに自動でEntityをアノテーションする。
たとえば、年月日を表すDate Entityをアノテーションさせたい場合、年と日を表す数字に対してアノテーションするための正規表現と、月を表す単語に対してアノテーションするための辞書を組み合わせたルールを作成することで、次のような年月日の表現に対してアノテーションが可能になる。
ルール:
辞書「January、February…」+正規表現「[0-9]{1,2}, [0-9]{4}」
アノテーションされる表現の例:
January 29, 2009
④機械学習アノテーション
あらかじめ、前述した3つのアノテーション手法(ヒューマンアノテーション、辞書アノテーション、ルールベースアノテーション)を用いてアノテーションした文書群を準備する。
その文書群をトレーニングデータとして機械学習することで、既存の文書群に対するアノテーション結果をもとに、未知の文書群に対して自動でアノテーションする機械学習モデルを作成する。
アノテーション手法の比較
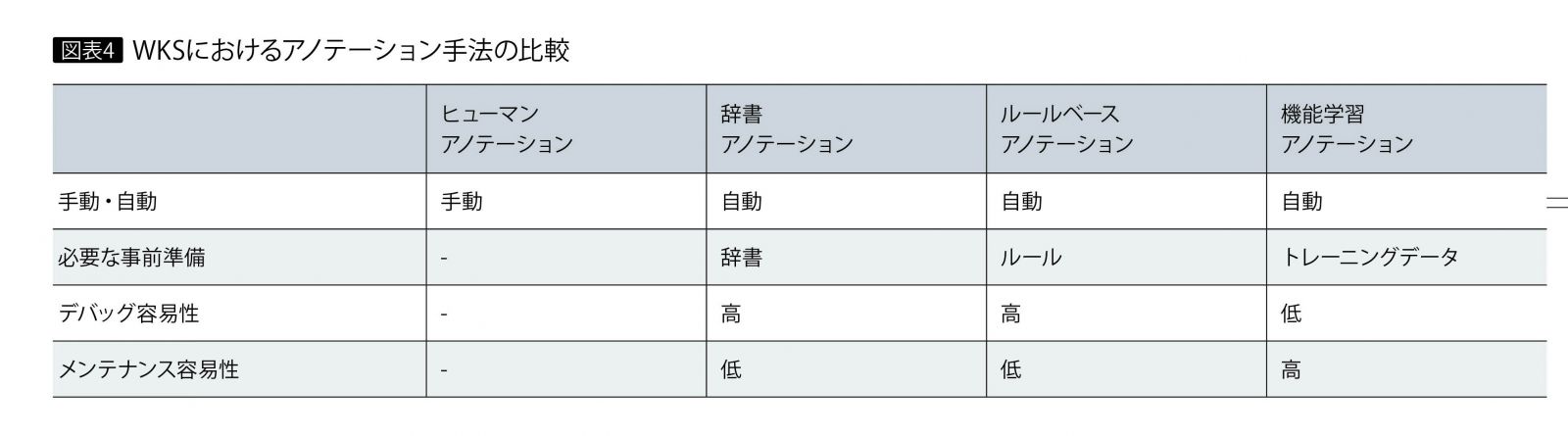
図表4は、前述した4つのアノテーション手法の比較である。比較の観点は「手動・自動」、および自動化の場合に重要とされる「必要な事前準備」「デバッグ容易性」「メンテナンス容易性」の4点。それぞれの手法に、長所・短所がある。
手動・自動
ヒューマンアノテーションは手動でアノテーションを行うため、アノテーション作業自体の負荷が大きい。ただし、人間が意図した結果を得やすい点は長所と言える。
一方、その他の3つの手法である辞書、ルールベース、機械学習の各アノテーションは自動でアノテーションを行うので、アノテーション作業自体の負荷は皆無である。その代わり、アノテーション自動化のための事前準備(後述)が必要となる。また人間が意図した結果を得にくいことがあるので、それが短所となる。
必要な事前準備
ヒューマンアノテーションを除き、自動化のための事前準備が必要となる。それぞれ辞書、ルール、機械学習のためのトレーニングデータを用意する。
デバッグ容易性
自動アノテーションの結果が想定したのと異なる場合、アノテーターの修正が必要になる(ヒューマンアノテーションを除く)。このとき、辞書およびルールベースのアノテーションでは、なぜそのような結果になったかを理解しやすいので、辞書やルールの修正点を比較的容易に導き出せる。これに対して機械学習アノテーションでは、なぜそのような結果になったかを理解しづらく、どのようなトレーニングデータを追加すればよいのか、見当をつけるのが難しい。
メンテナンス容易性
アノテーション対象の文書に出現する表現は、次第に多様化していくので、アノテーションの運用中もアノテーターのメンテナンスが定期的に必要である(ヒューマンアノテーションを除く)。
このとき、辞書およびルールベースのアノテーションでは、新たに出現した表現を正しくアノテーションするために、どのような辞書やルールが必要なのかを人間が考えて一般化し、それを正確に作成する必要がある。その結果、表現が多様化するにつれて辞書やルールが急速に肥大化・複雑化することになり、メンテナンスが煩雑になる。
一方、機械学習アノテーションでは、新たに出現した表現をアノテーションしたトレーニングデータを、いくつか追加するだけで済む。そのトレーニングデータから一般化されたルールを導き出す作業は機械学習が実施するので、メンテナンスが比較的容易である。
アノテーションの運用フロー
前述した4つのアノテーション手法はそれぞれ単独で利用できるが、組み合わせることも可能である。それぞれの手法には一長一短があり、組み合わせることで、それぞれの手法の短所を他の手法の長所で互いに補完し合える。
たとえば実際の運用では、次の手順でアノテーターを作成する(図表5)。
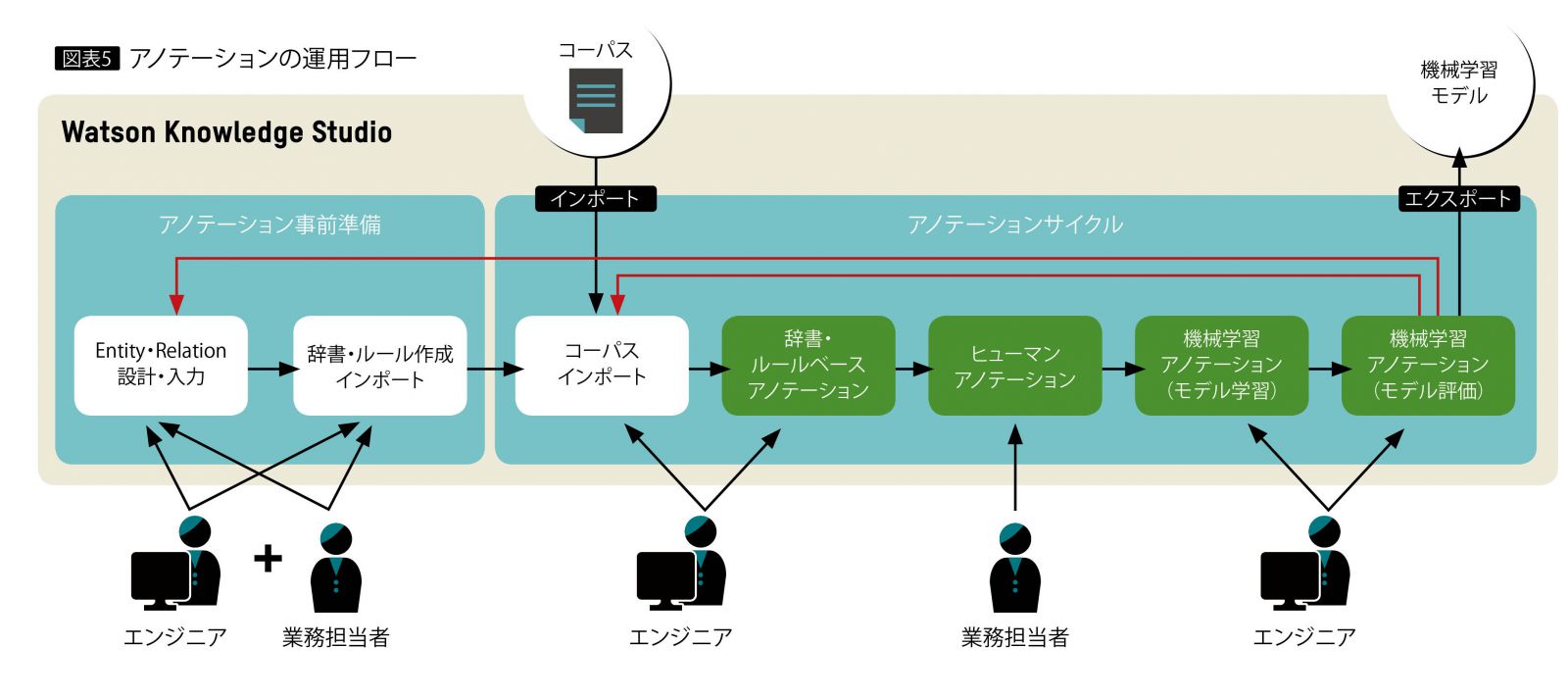
①エンジニアと業務担当者が協業しEntityやRelationの設計、辞書・ルールの作成、文書群のインポートを実施する。
②エンジニアにより、①でインポートした文書群に対して、①で作成した辞書・ルールに基づき、辞書およびルールベースの各アノテーションを実施する。
③業務担当者により、②で辞書およびルールベースの各アノテーションを実施した文書群に対して、さらにヒューマンアノテーションを実施する。これにより、辞書およびルールベースの各アノテーション結果を確認し、必要であれば修正する。
④エンジニアにより、③でヒューマンアノテーションを実施した文章群をトレーニングデータとして、機械学習アノテーションを実施。機械学習アノテーターを作成し、アノテーターの性能を評価する。
⑤④で作成した機械学習アノテーターの性能が十分であれば、アノテーターをエクスポートして運用する。不十分であれば、①に戻って手順を繰り返し、アノテーターの性能を改善する。
こうした組み合わせにより、トレーニングデータ作成に向けたヒューマンアノテーションの作業負荷を辞書およびルールベースのアノテーションにより軽減できる。また辞書およびルールベースのアノテーションで、辞書やルールが正しく作成できていないためにアノテーションに失敗した表現を、ヒューマンアノテーションや機械学習アノテーションでカバーするといった相互補完が可能になる。
以上、テキストアノテーションの内容、WKSの概要と使い方について解説した。WKSが提供している複数のテキストアノテーション手法を、その特性を十分に理解したうえで適切に使いこなし、テキストアノテーションをさまざまな角度からサポートするWKSの多彩な機能も併せて活用することで、大量の文書データに対してテキストアノテーションを効率的に実施できる。
テキストマイニングは、大量の文書データをビジネス活用するうえで欠かせない技術である。しかし大量の文書データをただ蓄積するだけで、そこに眠る知見を獲得し活用するに至っていない企業は多く存在する。この状況から脱却するには、文書データを取り扱いやすい形式に変換し、役立つ形に整理することが第一歩であり、テキストアノテーションはその助けとなることが期待される。
・・・・・・・・
著者|小熊 和仁 氏
日本アイ・ビー・エム システムズ・エンジニアリング株式会社
ワトソン・ソリューション
ITスペシャリスト

2014年、日本IBMに入社。製造クライアントIT推進部にて、鉄鋼・電機といった製造業のユーザー向けプロジェクトに参加し、オープン基盤系を中心とした設計・構築・運用に従事。2016年に日本アイ・ビー・エム システムズ・エンジニアリングに出向。2017年1月より現所属。Watson製品を中心としたコグニティブ系ソリューションのプロジェクト支援、解説記事執筆、QAサービスなどのソリューション推進活動を行う。
[IS magazine No.20 (2018年7月)掲載]
●特集|Watson Update
Part 1
Watson API&サービスの進化の方向性を探る ~データプラットフォームとAIの完全一体化に向けたロードマップ
Part 2
Watson Knowledge Studio ~機械学習とルールベースで業界固有の用語や表現をWatsonに教える
Part 3
Watson Discovery Service ~質問と回答の類似性に焦点を当て、回答候補をランキング提示する
Part 4
Watson + RPA ~データの種類と複雑性を軸にWatsonが判断し、後続のRPAを動かす







