今年6月、IBMはエンタープライズ・データ・スタックを根本的に簡素化し、AIエージェントやその他の高度なAIアプリケーションに必要な非構造化エンタープライズ・データを統合、管理、活性化するソフトウェアを発表する。
この2つの新製品には、「IBM watsonx.data integration」と「IBM watsonx.data intelligence」が含まれる。これらの製品から選択した機能は、watsonx.dataを通じて利用できる。watsonx.dataはIBMのハイブリッドでオープンなデータレイクハウスで、データとAIライフサイクル全体を単一のエクスペリエンスで管理できる。
新しいソフトウェアはハイブリッドかつオープンであり、サードパーティのデータスタックと接続することで、柔軟性、相互運用性を提供し、エコシステム全体からのイノベーションを促進する。watsonx.dataとのテストによると、新製品は従来のRAGよりも40%精度の高いAIを実現する。
IBMのユーザーであるロッキード社は、最近このwatsonx.dataを活用し、7万人のエンジニア、科学者、技術者が自然言語を使用して、何百万ものドキュメントから回答や情報を取得できるようになった。
ロッキード社の技術・戦略革新担当上級副社長であるジョン・クラーク氏は、次のように述べている。
「私たちは、研究室から現場にソリューションを送り出し、より安全でセキュアな世界の実現を支援するために、イノベーションと効率化を急速に加速させています」
非構造化データをうまく活用できない
企業はイノベーションを推進し、生産性を向上させ、競争力を維持するために、生成AIとエージェント型AIを必要としている。そして生成AIが正確で高いパフォーマンスを発揮するには、企業固有のデータが必要となる。IBMの新しいCEO調査によると、ビジネスリーダーの72%が、生成AIの価値を引き出す鍵として、自社独自のデータを重要視している。
しかしこれらのデータは、しばしば非構造化データであり、電子メール、PDF、プレゼンテーション、ビデオの中に存在するため、活用が困難である。従来のRAGでは、非構造化データの規模と複雑さを扱えず、構造化データと適切に組み合わせることもできない。一方、断片化されたさまざまなツールが、データ・スタックを複雑で面倒なものにしている。
その結果、企業の非構造化データ(IDCによれば、データ全体の最大90%を占める可能性がある)はほとんど活用されておらず、AIエージェントやその他の生成AIアプリケーションに反映されていない。
watsonx.data integrationとwatsonx.data intelligence
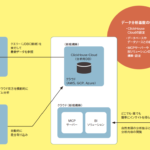
watsonx.data integrationは、AI対応データの配信を拡張するために設計された、新しい統一されたデータ統合コントロールプレーンを採用している。
データ・エンジニアは、ローコード、コード・ファースト、エージェント・ツール間を橋渡しでき、異なるオーサリング・エントリー・ポイントを可能にする。
このソフトウェアは、多様な統合スタイルにおけるデータ移動をオーケストレーションし、構造化データまたは非構造化データのバルクおよびバッチETL/ELT、リアルタイムストリーミング、データ複製、データ観測機能を備えている。
柔軟性と適応性があるため、データチームは断片化されたツールを操作したり、新しいデータ・ストレージのパラダイムシフトごとに、新たな技術を学ぶ必要はない。
watsonx.data integrationは、6月11日からスタンドアロンで利用できる。その非構造化データ統合と観測可能性の機能は、watsonx.dataを通じて活用できる。
一方のwatsonx.data intelligenceは、ハイブリッド・エコシステムにおけるデータ配信を簡素化するためにAIのパワーを活用し、組織がデータをキュレーション、管理、活用する方法を変革する。このソフトウェアは、データガバナンス、品質、データリネージ、共有を統合し、組織が有意義なデータを発見し、信頼し、アクセスできるようにする。
watsonx.data intelligenceは、6月11日からスタンドアロンで利用できる。その機能は、watsonx.dataを通じて、レイクハウスで管理されているデータにも活用できる。
6 月にwatsonx BIをリリース
IBMはDataStaxを買収し、そのツールやテクノロジーをwatsonx.dataに統合していく。これにはAstra DBとHyper-Converged Databaseが含まれ、オープンソースのApache Cassandraを利用したNoSQLとベクトル・データベースの機能を提供し、6月11日から利用可能となる。
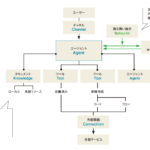
またIBMは6月、チームのデータ活用方法を見直し、自然言語を使って卓越したビジネス・インテリジェンスを提供するAI分析エージェント、watsonx BIを発表する。
このエージェントは、マーケティング、営業、業務、財務、その他の分野の質問に数秒で回答し、その理由を段階的に説明する。watsonx BIはスタンドアロンで提供されるほか、watsonx.dataでも利用できる。
さらにIBMは、Gluten Accelerated Sparkをwatsonx.dataに統合し、計算負荷の高いSpark SQLワークロードのパフォーマンスを強化する。このテクノロジーは、企業のデータ量が急速に増加している現在、大規模データ分析におけるクエリー処理の高速化とリソース効率の向上を支援する。
IBMはまた、MetaのLlama StackのAPIプロバイダーとして、watsonxを追加すると、最近発表した。watsonx.dataのMilvusデータベースはすでにLlama Stackフレームワークの一部であり、今回の統合により、さらに非構造化・構造化データ管理とエージェント検索が可能になる。
IBMは最近、あらかじめ構築されたドメイン固有のエージェント、watsonx Orchestrate Agent Builder、エージェント型AIガバナンス機能など、企業向けの新しいエージェント型AIツールを発表した。
今日の強固なデータ提供と組み合わせることで、企業はエージェント型AIの大規模展開を成功させるために必要なデータとツールを手に入れることができる。
[i Magazine・IS magazine]