近年、企業内外に散在もしくは蓄積しているさまざまな大量の非構造化データを有効活用したいという要望が多く、検索・分析を通じて大量のテキスト情報から洞察(気づき)や発見を得て、意思決定に役立てる仕組みが必要不可欠となっている。
そうした中、まさにテキスト情報の活用に必要となる機能をオールインワンで提供する知識探索ソリューション「Watson Discovery for Cloud Pak for Data」 (以下、WD for CP4D)が登場した。
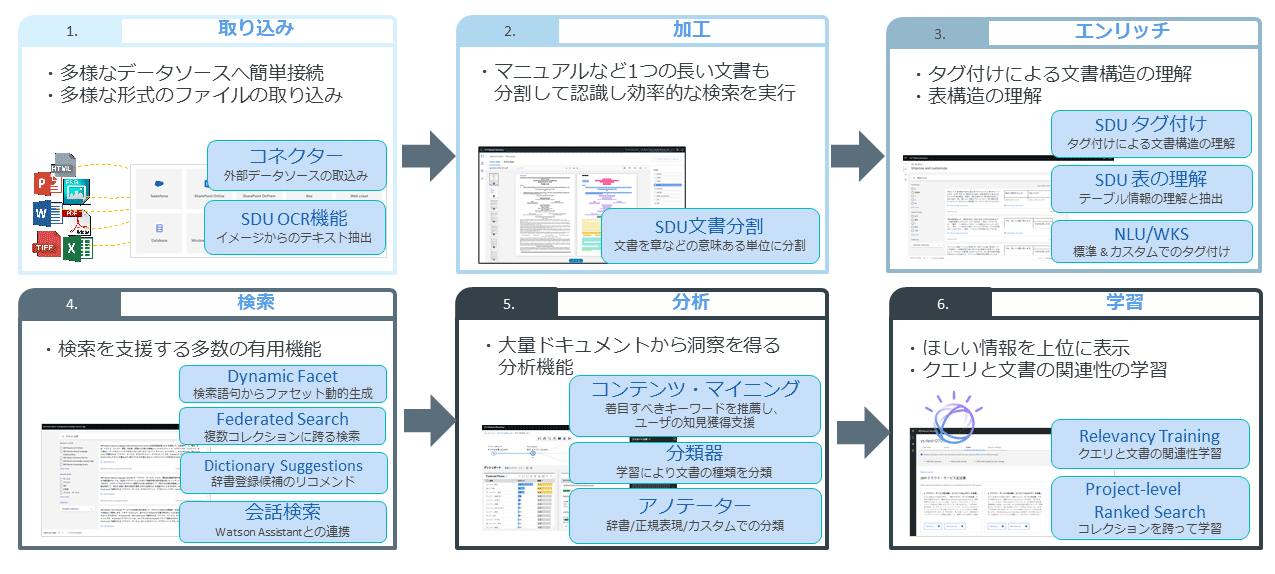
テキスト活用の中核となる検索や分析はもちろん、その前処理のテキストの「取り込み」や「加工」「エンリッチ」(タグ付け)、また「学習」といったAI要素も含んでおり、テキスト活用に必要となる一連の機能を包含したソリューションである(図表1)。
WD for CP4Dは既存のWatsonサービスおよび製品を統合し、新たに誕生したソリューションである。
具体的には図表2のとおり、大量のデータを検索するとともに、適切な意思決定を支援する知的探索機能(Watson Discovery Service)に加え、コグニティブな探索機能、強力なテキスト分析機能、および機械学習機能を使用することですべての非構造化データを探索しマイニングするツール(oneWEX)を統合している。
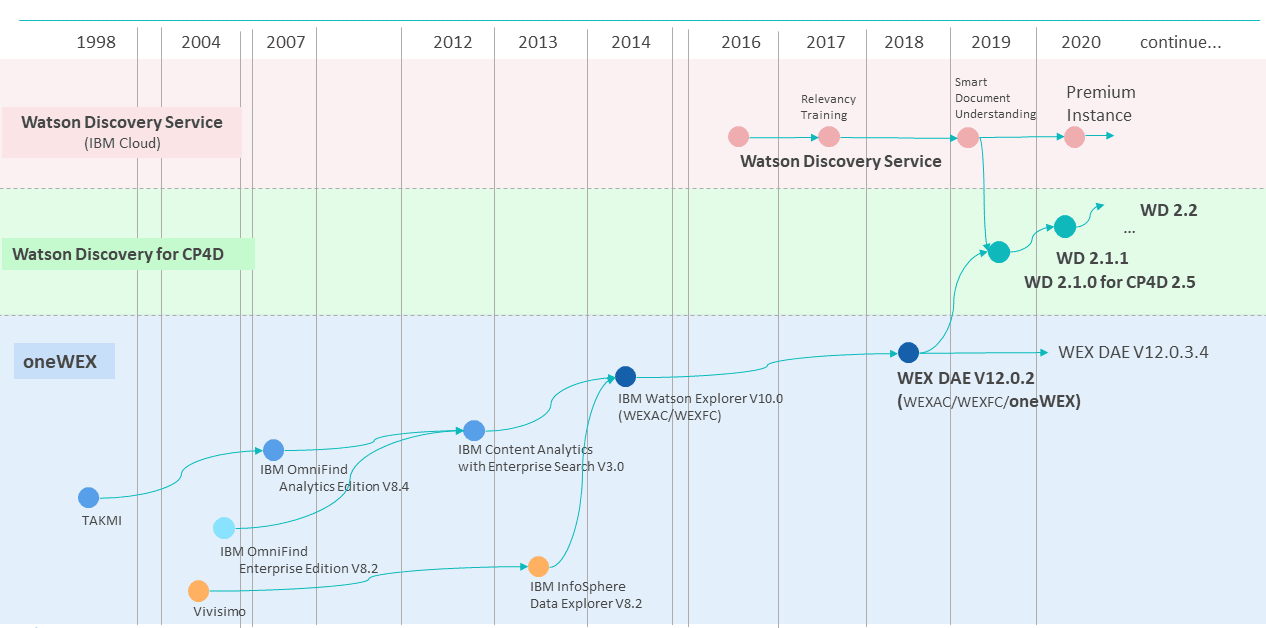
さらに2020年には、IBM CloudのDiscovery Premiumインスタンスとして同様の機能が活用できるようになり、IBM CloudのSaaSとして利用可能になった。
本稿ではテキスト情報の活用に必要な機能が豊富に備わったDiscoveryについて、テキストの活用場面に応じた代表的な機能を紹介する。
前処理を支援する機能
テキスト情報を活用するためには、テキストの「取り込み」や「加工」「タグ付け」といった前処理が必要であり、Discoveryはそのための機能を備えている。
まず「取り込み」については、DiscoveryのGUIに直接ファイルをアップロードするだけでなく、2つの有用な機能を備えている。
1つは「コネクター」と呼ばれる機能で、 Microsoft SharePointやSalesforce、BOX、IBM Cloud Object Storageなど多彩な外部サービスと連携してデータを取り込める。
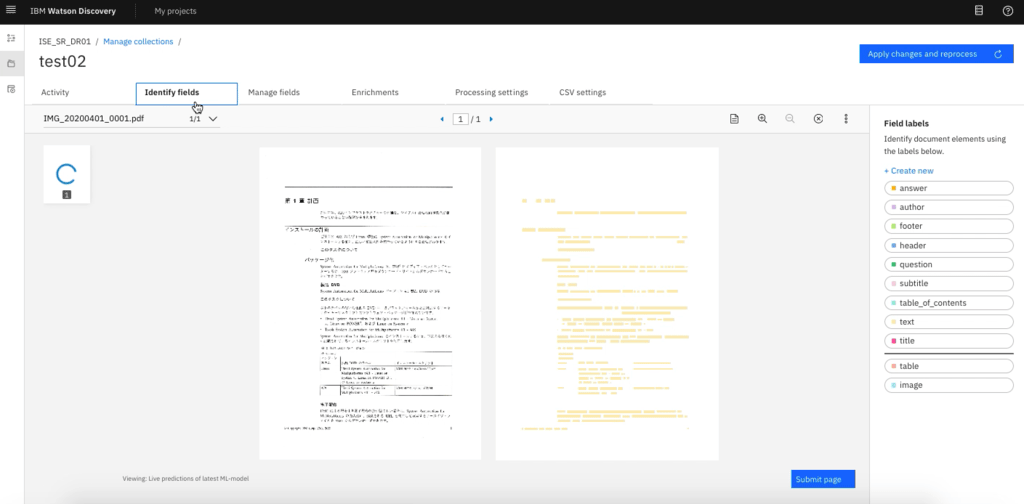
もう1つはOCR機能で、たとえば文書のハードコピーをスキャナで取り込んだイメージファイルをDiscoveryにアップロードすると、イメージ上の文字をテキストとして認識する。
図表3では、左側が取り込んだイメージで、右側の薄く反転した部分がテキストと認識された箇所である。テキストとして認識されると検索対象になり、またタグ付けも行える。
次に「加工」については、マニュアルなどページ数の多い文書はそのままDiscoveryにアップロードしても検索結果の粒度がファイル単位になる。そのため従来、前処理として章単位あるいはページ単位でテキストを切り出しJSON化してDiscoveryに取り込む必要があり、そのためのプログラムを開発する必要があった。
現在は、Smart Document Understanding(SDU)の文書分割機能により、GUIでファイルを分割できる。機械学習を利用して文書構造を学習させ、文書中のどこで分割させるかを学習させられるので、長い文書でも比較的容易に分割して取り込める。これにより検索結果はファイル単位ではなく、分割した粒度の単位で表示できる。
次に「エンリッチ」については、文書中の文字列にタグ付けできるだけでなく、「表の理解」の機能を利用することにより、文書中の表をタグ付けして表構造を理解させられる。
たとえば、図表4の左側が取り込まれた文書で表が記載されている。
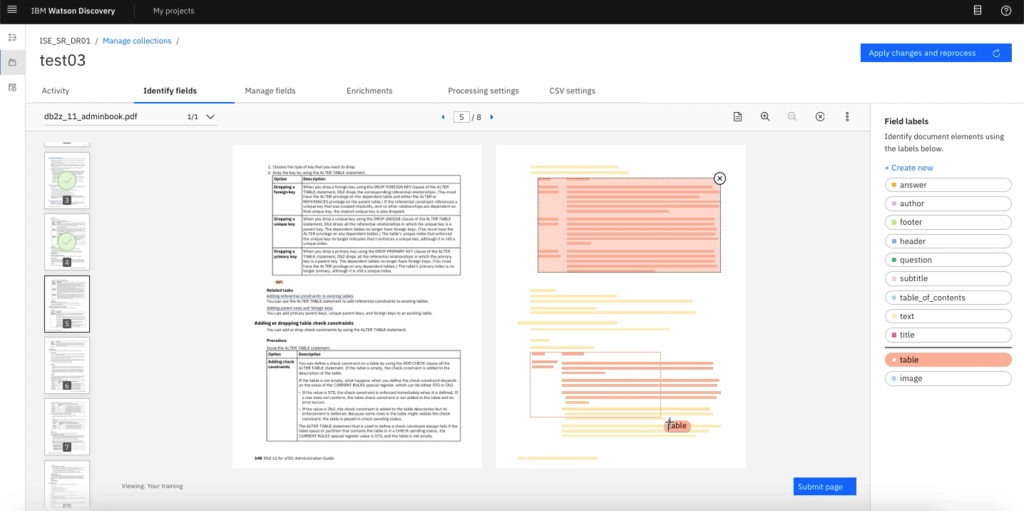
右側のDiscovery が認識した部分はテキストとして認識されているが、「Table」タグでタグ付けすることにより、この部分はテーブルであるとDiscovery に認識させられる。これにより表も検索対象となり、検索結果に表を表示することもできる(図表5)。
その他のタグ付けに関する機能では、Discoveryに標準搭載されているポジネガ表現や重要キーワードの抽出があり、また別途Watson Knowledge Studioで作成したカスタムのテキスト抽出器を組み込むことにより、業界固有の用語や表現の抽出も可能である。
検索の概要と検索支援機能
テキストの前処理が済み、Discoveryに文書が格納されると、実際に検索や分析といった活用が可能になる。ここでは、検索の概要と検索を支援する多数の機能の中から代表的なDynamic Facetsと呼ばれる機能を紹介する。
まず図表6に、Discoveryが提供する検索画面を示す。
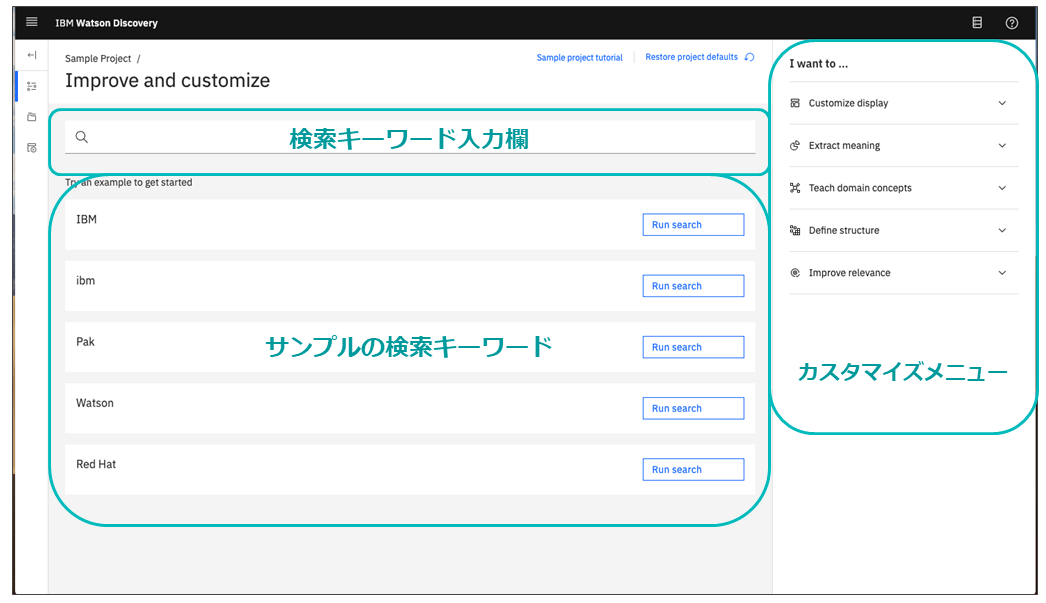
検索画面には、検索キーワード入力欄やサンプルの検索キーワードなどがリストされる。当該キーワードは実際に取り込まれている文書から抽出され表示される。
右側には、検索画面をカスタマイズするためのさまざまな設定を搭載したメニューが提供されており、同義語辞書の作成やメタデータをファセットとして表示させるなどの設定ができる。
また検索画面はそのまま検索アプリのUIとして利用でき、よりカスタマイズしたい場合はサンプルコードとしてReusable Componentが公開されている。
Reusable Component
https://cloud.ibm.com/docs/discovery-data?topic=discovery-data-deploy
https://github.com/watson-developer-cloud/discovery-components
さらに検索画面には標準機能として、たとえば「watson」と入力した際に関連する推奨キーワードが表示され検索を支援する機能(図表7の左)や、検索キーワードの綴りを間違えて、「クラアド」と入力すると、「クラウド」ではないかと指摘し修正を支援する機能も備わっている (図表7の右)。
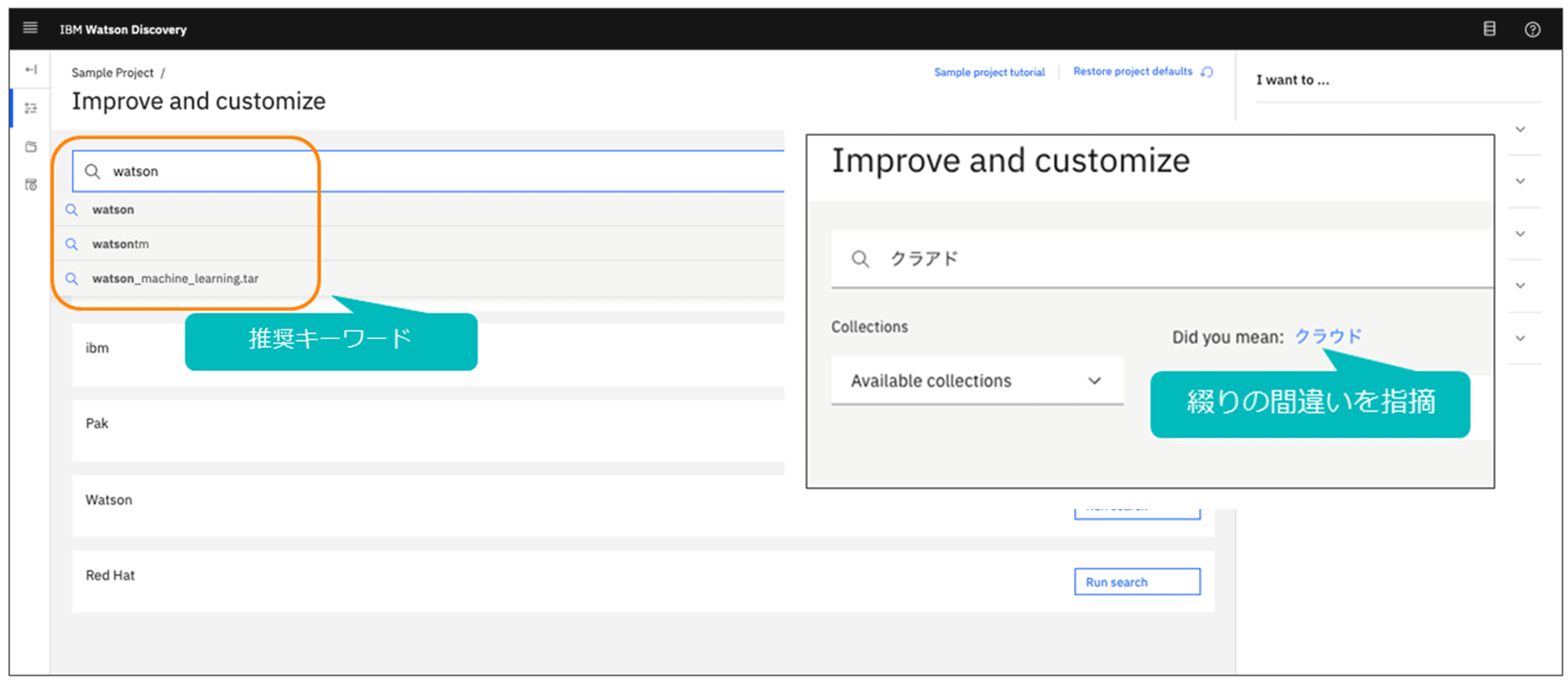
その他、検索結果の文書中で検索キーワードとの関連性が高い文節(パッセージ)をハイライトする機能など、多数の検索支援機能を備えている。
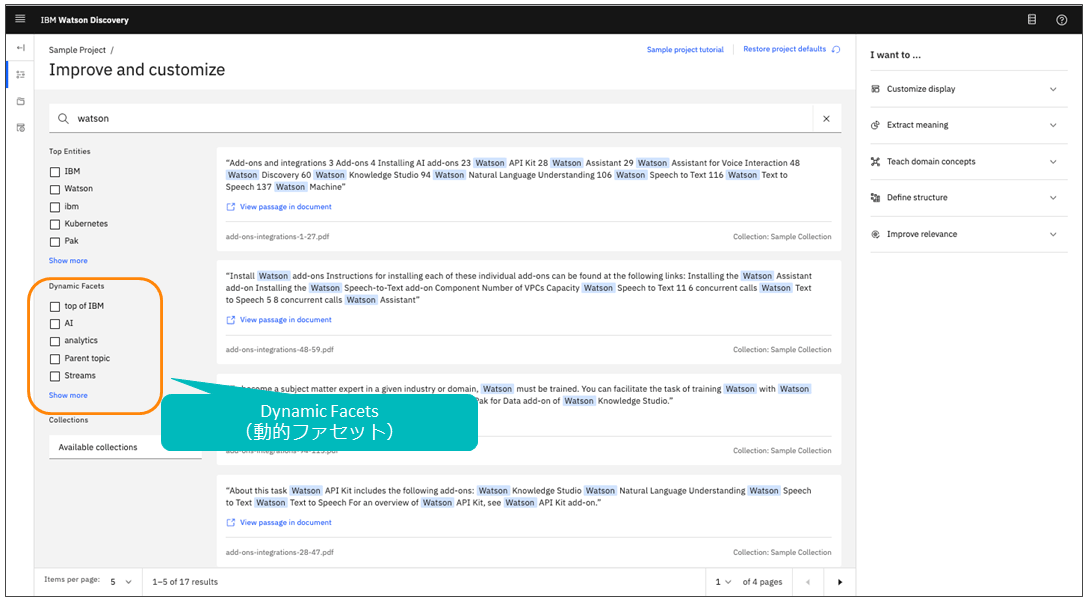
次に、検索を効率的に行うことを支援するDynamic Facetsを紹介する。Dynamic Facetsとは、検索キーワードとDiscoveryに投入されている文書から動的にファセットを生成し、検索結果の絞り込みを効率的に支援する機能である。
利用者は図表8に示す画面左側のファセットを選ぶことによって、検索結果を絞り込み、目的の情報に効率的にたどり着くことができる。
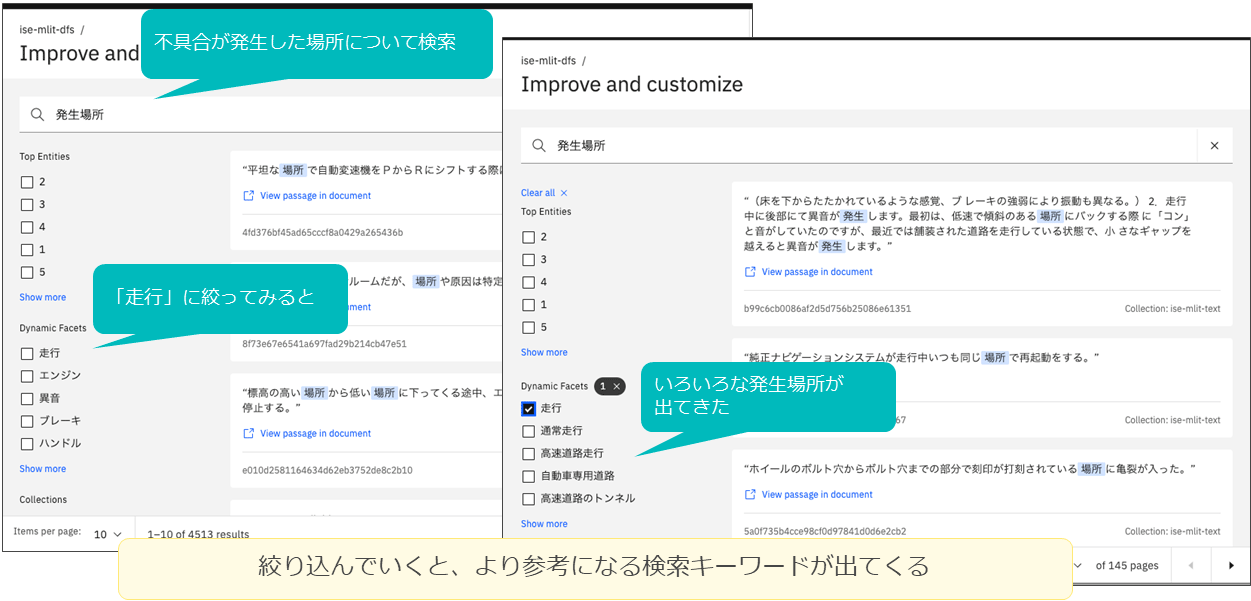
Dynamic Facetsの有効な例としては、知りたい情報に効率的に辿り着けるケースや、動的に生成されるファセットの情報によって、想像していなかった気づきを得て、洞察を深められるケースが考えられる。
前者の具体例としては、自動車の不具合情報が格納されたコレクションの検索で、不具合の発生場所に効率的にたどり着くケースが挙げられる(図表9)。
後者の具体例としては、家電やスポーツ、IT、趣味といったさまざまな情報が格納されたコレクションで、美容について検索したところ、美容に関する多彩で興味深いキーワードが表示され、新しい知見を得られたケースが挙げられる(図表10)。
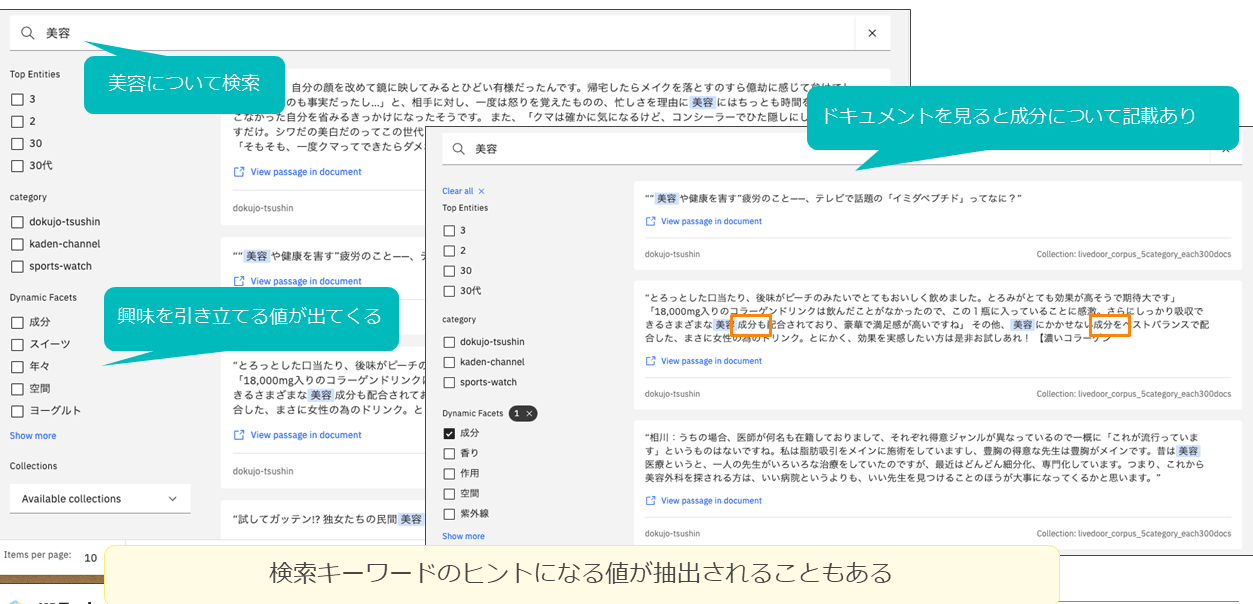
図表10 想像していなかった気づきを得られた例
分析を支援する機能
テキストの前処理が済み、Discoveryに文書が格納されたら、分析に活用できる。
Discoveryの分析では、大量ドキュメントから洞察を迅速に得るための機能が豊富に含まれている。ここでは主に、以下の3つの機能について概要を紹介する。
(1) Dictionary Suggestions
(2) コンテンツ・マイニング
(3) 分類器
(1) Dictionary Suggestions
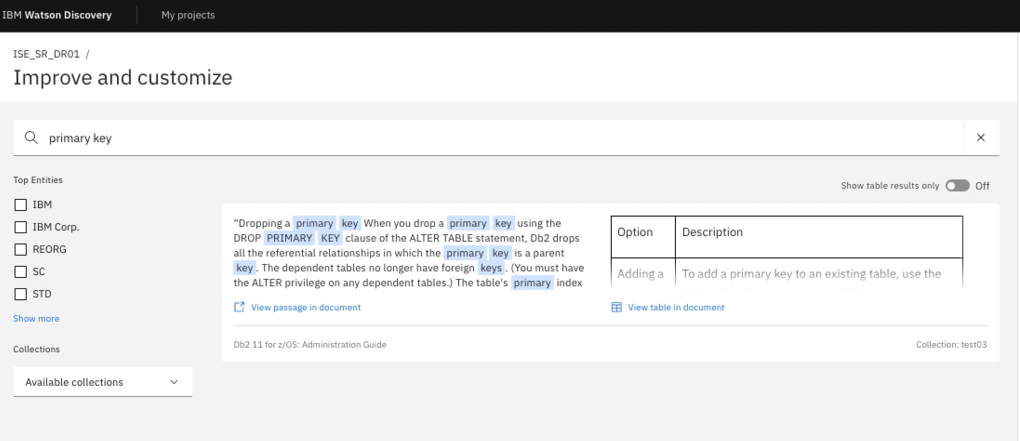
分析で必要不可欠となる辞書作成を強力にサポートする機能である。図表11のように、辞書に登録したい単語を数個入れるだけで(図表内の左)、自動的に文書の中から似た用途で使われている単語が抽出される(図表内の右)。
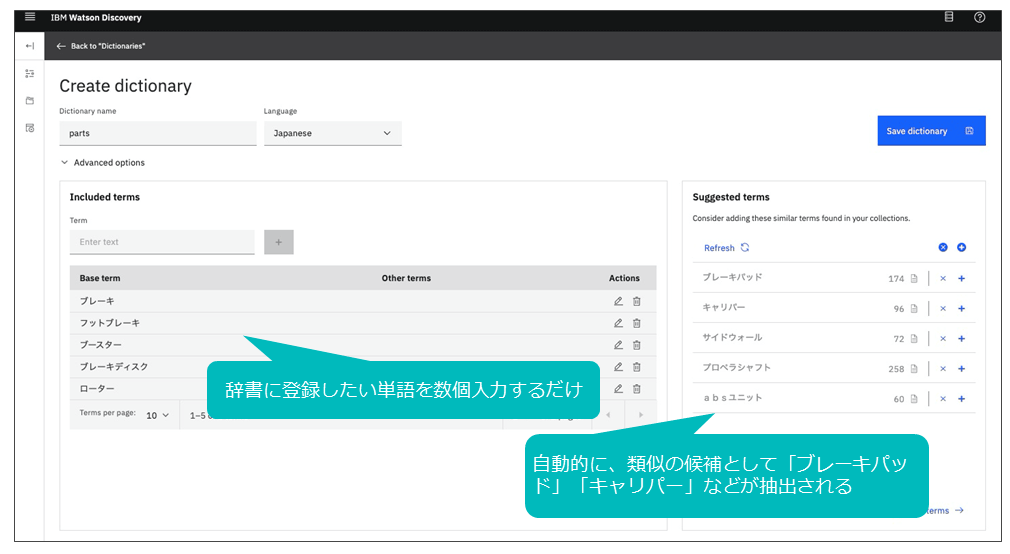
抽出されたリストの中から辞書に追加することはもちろん、適切ではない単語を除外することで新たに学習が進み、抽出される単語が改善されていく。実際にどのように文書中で使われているかを確認したうえで辞書に登録することもできる。
(2) コンテンツ・マイニング
データの絞り込み経緯の可視化や次に実施できる分析を複数提示することで(図表12の上段)、分析を支援する機能である。
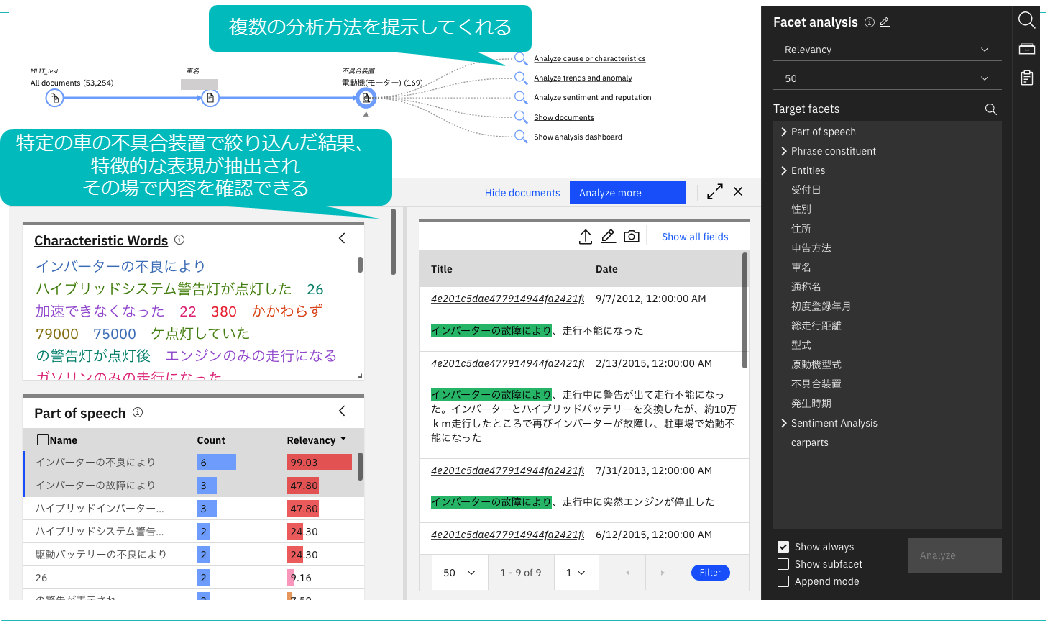
特定の条件に絞り込んだ後、提示された分析方法の中から「Analyze cause or characteristics」をクリックするだけで、「Characteristics Words」で現在絞り込まれている条件に対して特徴的なキーワードを自動的に抽出するとともに、他の構造化データから特徴的なファセット(分析軸)と値が表示される。
この機能により、大量のデータから効率的に文書の特徴を捉え、多様な角度から分析することで新たな洞察を迅速に得られるよう支援している。
(3) 分類器
学習により文書を分類する機能である(図表13)。
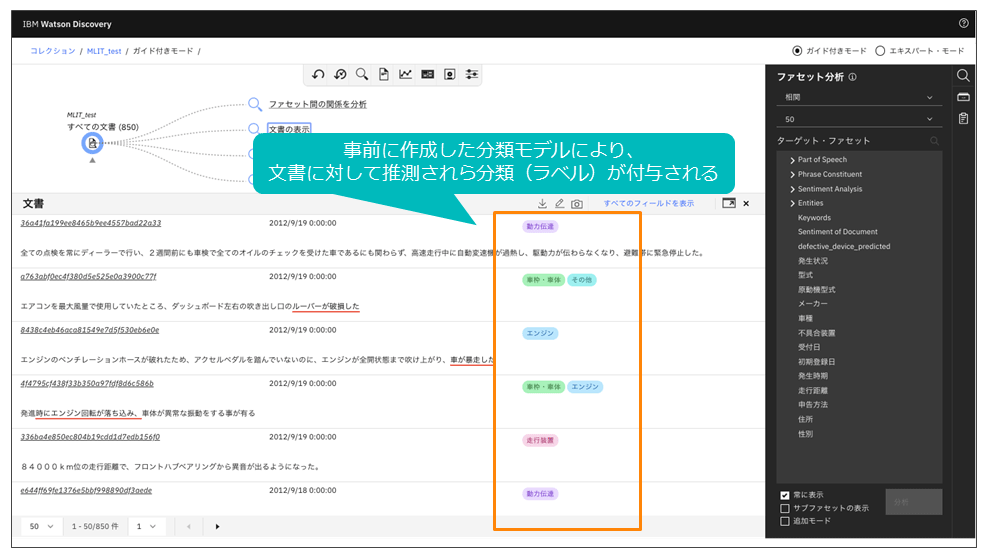
文書とその文書の分類クラスを教師データとして学習させた分類モデルを作成し、新たな文書に対してどの分類クラスに属するかを推測する機能である。
Discoveryの分類器の特徴は、教師データとして自然文だけではなく構造化データも含められ、また必要に応じて1つの文書に対して複数の分類クラスを定義できる。
さらに、モデル作成からモデル精度の確認、モデル適用まですべてDiscoveryの画面から操作可能である。
最適な検索結果に成長するための学習機能
検索結果の精度改善を図る学習機能は、検索結果に対して利用者が期待した結果であるかどうかをDiscoveryにフィードバックし、検索キーワードと文書の関連性を学習させ、最適な順位になるよう成長させる機能である。
フィードバックとは、利用者もしくは管理者が個々の検索結果に対してRelevant(関連性が高い)、Not Relevant(関連性が低い)と評価することである(図表14)。Discoveryはフィードバックのための画面やAPIを提供している。
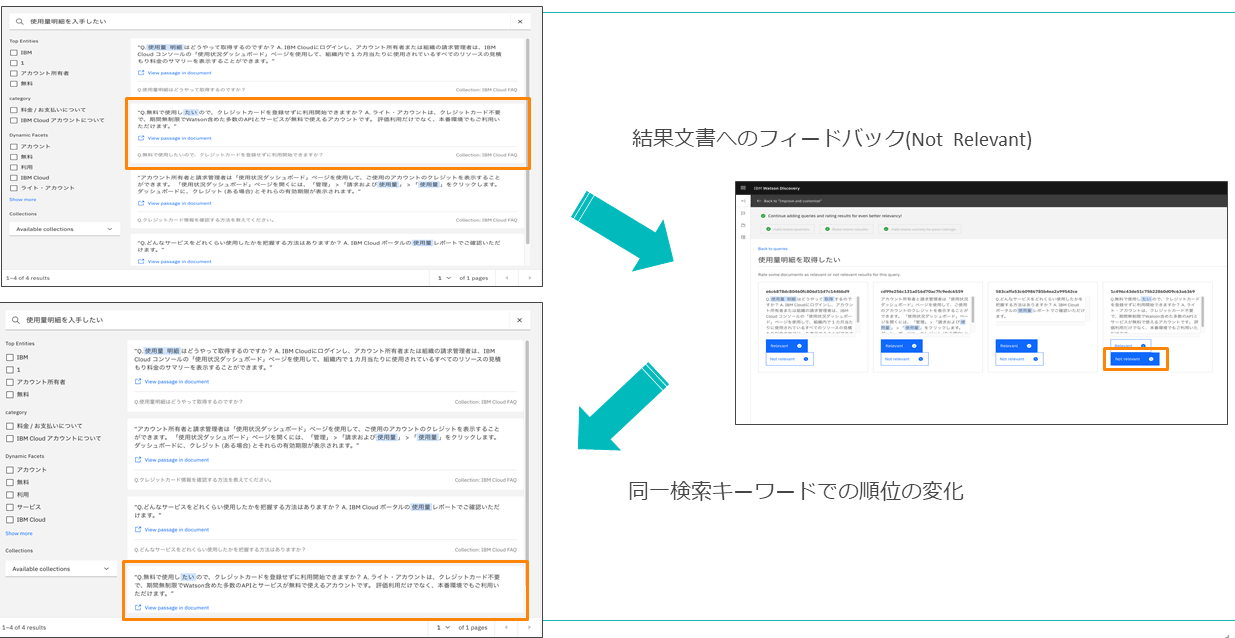
この学習機能はユーザーから高く評価されており、たとえばDiscoveryの事例集では、本田技術研究所様やJR東日本様がその有用性を下記のように述べている。
「一般的な全文検索とは異なり、機械学習を用いた学習モデルに基づき、最適なコンテンツを提示するのが重要なポイントである」
「新しいデータを追加して学習を進めるほどWatsonは“賢く”なり、回答できる範囲が拡大していくことがわかった」
「継続的な学習によって 精度が向上する様子を目の当たりにすると、やはりWatson Discoveryを導入し、AIによる情報探索をベースにしたこと には大きな意義があった」
今回紹介したとおり、Discoveryにはテキスト情報を活用した検索および分析業務で必要となるさまざまな機能が豊富に備わっている。そのため、Discoveryを使った提案活動、PoC、本番案件も徐々に増えつつあり、今後も増加することが期待される。
今回紹介した内容がそれらの案件に役立てば幸いである。なお、紹介しきれなかった機能やより詳細な内容については以下の参考資料を参照いただきたい。
【参考資料】
Watson Discovery
https://www.ibm.com/jp-ja/cloud/watson-discovery
Watson Discovery for CP4D
https://cloud.ibm.com/docs/discovery-data?topic=discovery-data-about
コンテンツ・マイニング
https://cloud.ibm.com/docs/discovery-data?topic=discovery-data-contentminerapp
著者
髙谷 尚子氏
日本アイ・ビー・エム システムズ・エンジニアリング株式会社
Advanced AI
シニアITスペシャリスト
2016年にWatsonを扱う部門に異動。以降、Watson Explorerを中心とした技術支援やデリバリー支援、講師活動に携わる。最近ではWatson Discovery、Watson Knowledge Studio、Watson Assistantなど自然言語処理系のプロジェクトに参画することが多い。

西野 謙吾氏
日本アイ・ビー・エム システムズ・エンジニアリング株式会社
Advanced AI
アドバイザリーITスペシャリスト
2018年に日本IBMから日本アイ・ビー・エム システムズ・エンジニアリングに出向し、Watson APIを中心とした技術支援や講師活動に携わる。主にWatson DiscoveryやKnowledge Studioといった自然言語処理系のAPIを活用したプロジェクに参画することが多い。

[i Magazine・IS magazine]