多くの企業でデータ分析やAIモデル開発が一般的になりつつある。昨今は、IBM AutoAIなどの自動AI製品やSaaSが多く登場しており、プロのデータサイエンティストではない市民データサイエンティストでも、AIモデル開発を容易にスタートできる時代になっている。
AIモデルのよし悪しが、予測精度や汎用性を大きく決定する。その重要な要素として、データから有用な特徴量を作成する技術「特徴量エンジニアリング」が挙げられる。
自動AI製品にはプロデータサイエンティストが培ってきた特徴量エンジニアリングの手法が組み込まれており、初心者でも扱える。
また一方で、Kaggle等のデータ分析コンペティションでは、有用な特徴量エンジニアリング手法が多くのユーザーからコミュニティの中で提案されている。
本稿では、初級~中級のデータサイエンティストを対象に、自動AI製品に組み込まれた手法やKaggleなどで提案されているなかで筆者が実際に使ってみてとくに有用だった手法を紹介する。
特徴量エンジニアリングとは
データ分析やAIモデル開発の特徴量エンジニアリングとは、オリジナルデータから機械学習モデル(AIモデル)に有用な説明変数=特徴量を作成する作業を指す(図表1)。
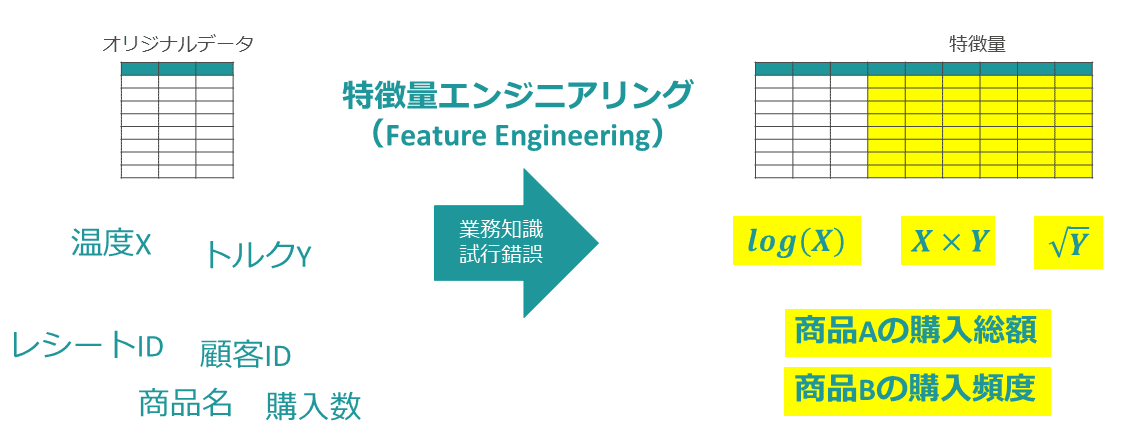
オリジナルデータとはデータが生成されたときの状態を表し、たとえば工場の生産ラインで生み出される時系列の温度データや、店舗のレジから生み出される商品の購買履歴データである。
特徴量エンジニアリングでは、そのオリジナルデータから目的のAIモデルの予測に役立つ集計データを生成する。店舗の顧客ごとの購買行動のAIモデルを作る例では、「顧客ごとの商品の購入総額」などが特徴量となる。
とくに画像などを扱うディープラーニングでは、扱う際の特徴量エンジニアリングが学習アルゴリズムに組み込まれている。しかし一般的な表形式のビジネスデータを扱うシーンでは、今でもこの特徴量エンジニアリングの作業ステップが必要である。ここで予測精度に大きく寄与する有用な特徴量を作れるかどうかが、AIモデル開発の成否を大きく左右する。
特徴量エンジニアリングでは、データサイエンティストの業務知識や経験を元に有用な特徴量を作成するが、とくに初級?中級データサイエンティストはその経験が少なく、またある程度の経験があるデータサイエンティストであっても意外な特徴量を着想しにくいという悩みがある。
また、集計・数値変換・コード化などのさまざまな手法を適用してデータを変換するが、このデータの変換方法は無限に存在するため、その作成に要する時間や計算資源というリソース問題、また大量に作成された特徴量から有用なものを絞り込む特徴選択が煩雑になるという悩みもある(図表2)。
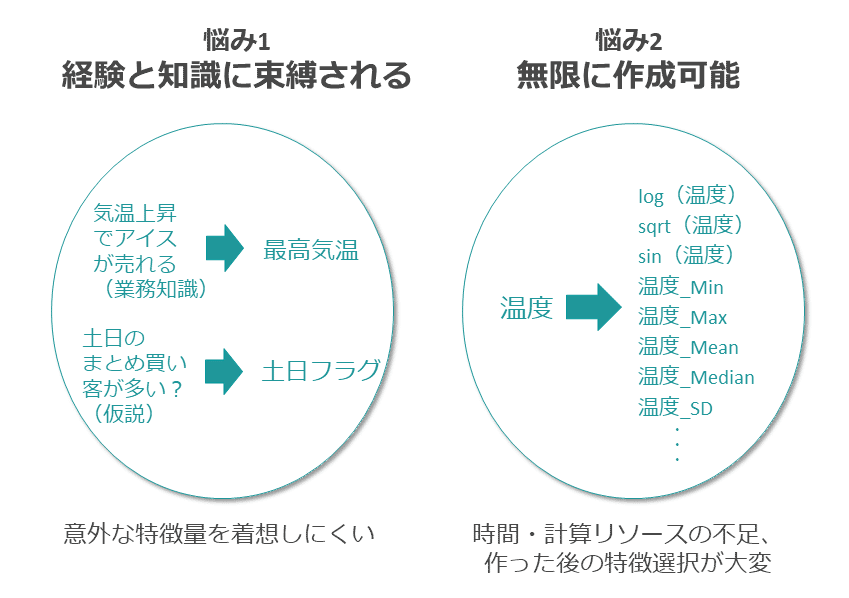
自動AI製品やKaggleコンペなどで培われた手法を学んで新たな着眼点を得ることや、昨今提案されている効率的に特徴量を作成し選択する手法を取り入れることが、これらの悩みを解決する方法の1つと言える。
特徴量エンジニアリングの手法
特徴量エンジニアリングの手法を、データ変換の対象となる表の数や集計対象などで大まかに分類したものを図表3に示す。

単一の表、単一の行、単一の変数(列)を単純に数値的に変換する手法から、複数の変数をかけ合わせた手法、集計と票の結合から生み出す手法など、さまざまなものがある。また、特徴量を作成するだけでなく、有用な特徴量を選択する手法も最近提案されている。
ここでは、最近の自動AI製品などで培われてきた手法のなかから筆者のイチオシを中心に紹介しよう。
対数変換、Yeo-Johnson変換
正規分布に近づける
単一の数値変数に対して、対数(log)の変換をかける手法である。数学的な変換では、ほかにもexpやsqrtやsinなどがあるが、対数は「ロングテールな分布を正規分布に近づける」という特徴を備える(図表4)。
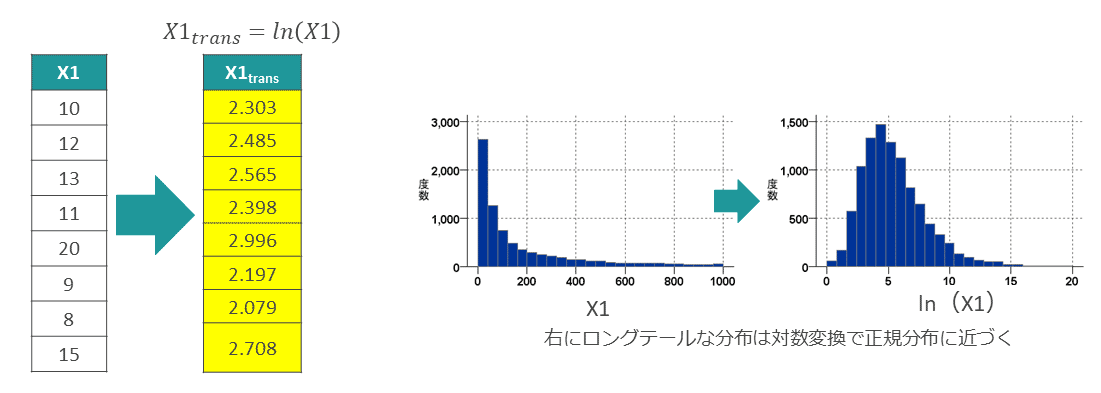
この正規分布に近づける特性は、予測残差の正規分布性を期待する分析アルゴリズム(例:線形回帰)などでとくに有用であり、モデルの精度向上に役立った経験がある。
ただし対数はその数学的性質上、0以下の数値を変換できない。0以下の数位が含まれる場合は、元の数値X1に定数を加算して常に0より大きい値に変換してから対数変換する(最小値がわかっている場合)方法や、対数変換をより一般化したYeo-Johnson変換(Y-J変換)を用いる方法がある(図表5)。

Y-J変換ではパラメータλによって変換後の分布が変化するため、より正規分布に近い変換結果を得るようにλを調整する必要がある。
λの探索は最尤法を用いた手法もあるが、実用上はいくつかλを変えてY-J変換を行った結果を視覚的に確認し、最も正規分布に近いものを採用する簡易的な方法でも問題ない。
Target Encoding
リークに注意
Kaggleのコンペティションで培われてきた手法である。カテゴリ変数を、そのカテゴリ値ごとの目的変数(Target)の平均値に置き換える(図表6)。
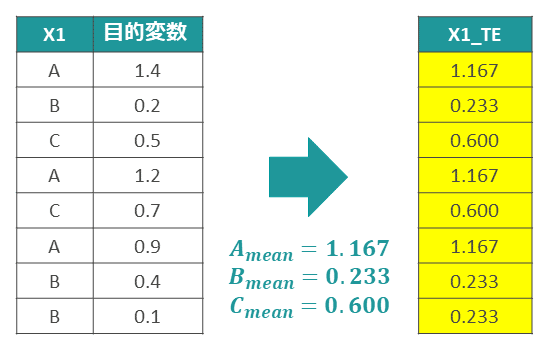
これは、カテゴリ値ごとに別の集計値に置き換えるビンカウンティングと呼ばれる手法の一種である。
予測対象である目的変数(Target)の値を使うので、一見すると禁じ手のように見える。事実、図表6に示したやり方では、各データ行で自身の目的変数の値が計算に織り込まれているので、本来は予測時に与えられない情報を特徴量に加えている不適切な状態である。この不適切な状態を、「リーク」と呼ぶ。
リークはTarget Encodingに関わらず、データを不適切に扱った場合に発生し得る。たとえば、気候の時系列のデータで最高気温を予測するモデルを作る際に、そのモデルでの予測実行のタイミングではまだ得られていない「同時刻の最低気温」を特徴量に加えてしまった場合もリークとなる。
リーク防止策として、データを分割(Folding)して平均値の計算対象となるデータを分離する方法がある。各データ行は、自分自身の目的変数の影響がない他のFoldのデータ群の平均値を用いる(図表7)。
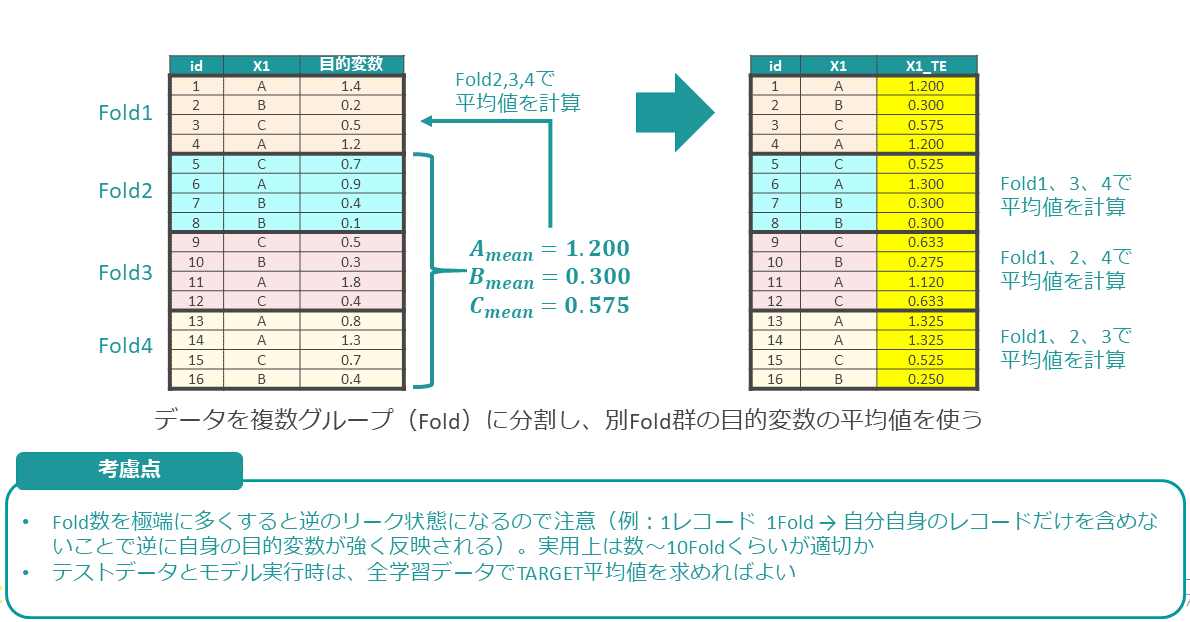
Foldingは、クロスバリデーションでも使われる方法である。Fold数は、細かくしすぎるとまたリーク状態に近づくため、データ件数やカテゴリ数次第であるが、数~十数個くらいがちょうどよいようだ。
Target Encodingはリーク対策をとった上で使用すれば、Kaggleコンペティション以外のビジネスデータでも有用な手法となる可能性がある。適したシーンがあれば、リークに注意しながらぜひ使ってみてほしい。
複数変数の掛け合わせ
意外な特徴量の発見
2つの変数をかけ合わせた新しい変数を作る方法である。掛け算(×)で作成した特徴量のことを、とくに「交互作用項」と呼ぶこともある。カテゴリ変数と数値変数の場合は、カテゴリごとに平均値や標準偏差など何らかの集計値に置き換えるビンカウンティングの方法を取る(図表8)。
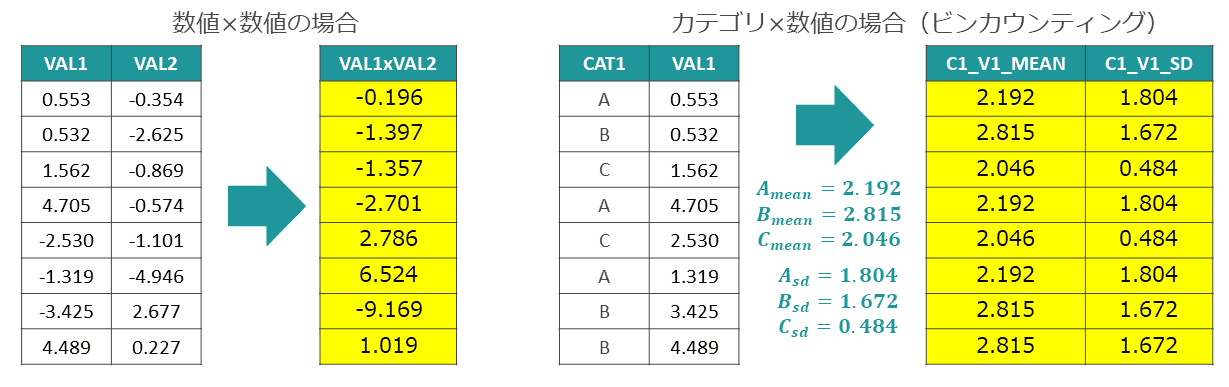
複数変数の掛け合わせは一見単純な手法に見えるが、どの変数を組み合わせるかに意外性がある。自動AI製品も積極的に取り入れているが、元の変数が多い場合、組み合わせの数は膨大になり、計算量の増大や作成後の特徴選択が大変になる。
また自動的に組み合わせで作った特徴量は、データの意味から考えてナンセンスなものになる可能性がある(例:気温×顧客の年収)。
筆者の経験では、曜日フラグ変数(0 or 1(×気温(数値)の掛け合わせ特徴量が有用だったことがある。事前知識でも曜日や気温との関係が強いことを想定できる目的変数であったが、データ観察の結果、曜日ごとの目的変数の上下動の大きさが季節によって変化しているデータであった。
単純な0 or 1のフラグではなく、そこに気温という別変数をかけ合わせた交互作用項を作ることで、予測精度が大幅に向上した経験であった。
特徴選択を組み合わせた手法
効率的に探索
上記のように特徴量を大量に作成すると、次はそのなかからモデルの精度向上に役立つ有用な特徴量を選択していく必要がある。
この特徴選択は、分析アルゴリズムに組み込まれている手法や、学習後のモデルにおける特徴量の重要度を算出する方法、何度も特徴量を変化させてモデル学習と精度評価を繰り返す方法などがあり、かなり骨の折れる作業と言える。
最近の研究では、特徴量を作成しながらそのよし悪しを評価して、同時に特徴選択も行う手法がいくつか提案されている。
Cognito(*1)は、強化学習の仕組みで、特徴量の作成と選択を繰り返し探索する、2016年にIBM Researchが提案した手法である。図表9に論文の図を引用する。
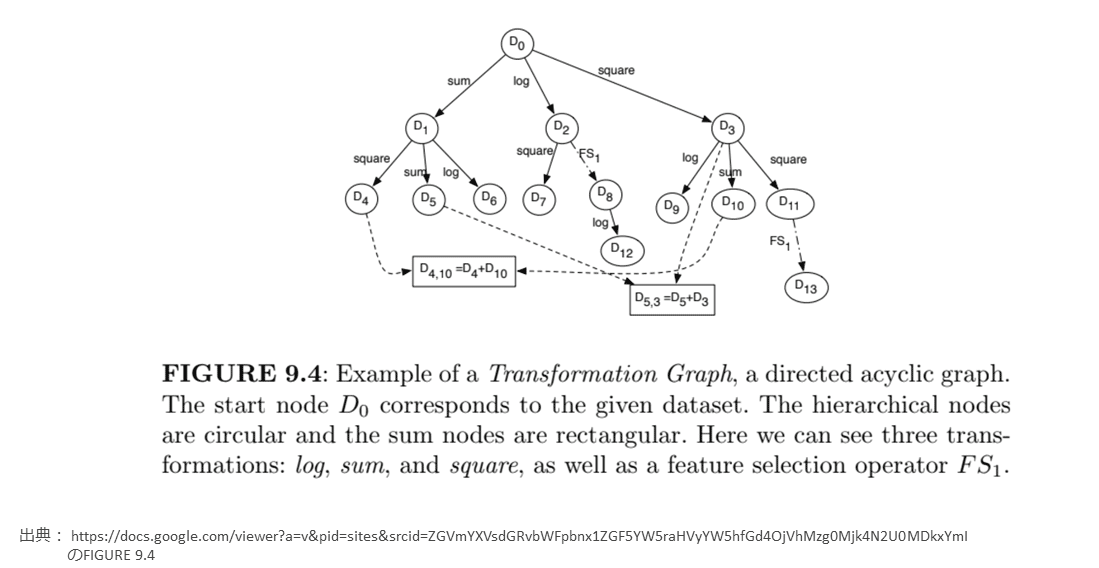
オリジナルデータセットD0に対してsum、log、squareなどの新しい特徴量を加えたデータセットD1、D2、D3を生成する。各データセットでのモデル精度を測定して、より精度の高いモデルができたデータセットへ新しい特徴量を加えていくように、探索を何度も繰り返す方法である。
このような新しい手法は、自動AI製品に組み込まれているものが多く、CognitoはIBM AutoAIに組み込まれている(2020年時点)。自分自身で論文を読み解いてアルゴリズムをコーディングするのは大変であるが、このような機能を備える自動AI製品を使えば容易に試すことができる。
*1 Cognito: Automated Feature Engineering for Supervised Learning,
https://ieeexplore.ieee.org/abstract/document/7836821
https://researcher.watson.ibm.com/researcher/view_group_pubs.php?grp=7500
特徴選択の考え方
大量に作成した特徴量群から有用な特徴量を絞り込んでいく作業を、特徴選択と呼ぶ。Cognitoなど特徴選択の機能を備えるアルゴリズムの利用はその1つであるが、汎用的な手法を図表10にまとめた。

有用な特徴量はモデルの予測対象との関係が強く、またモデルの予測精度にも強く寄与する。大量に作りすぎた特徴量群から図表中1や4のような簡易的な方法でバッサリと絞り込んでいく方法もあるが、本質的には図表中2や3のように、予測モデルの精度への貢献度を見ながら選択していくことを推奨する。
また自動AI製品ではなく、プロのデータサイエンティストが使用する汎用ツールとしては、Pythonのfeaturetools というライブラリがある。
featuretoolsでは、複数の表の結合からさまざまな集計値としての特徴量を生成できる強みがある。思いもしなかった変数の組み合わせや集計方法など、有用な特徴量を効率的かつ効果的に作り出すことが可能であり、筆者も強く推奨するツールである。
特徴量エンジニアリングの世界は奥深く、必ずモデル精度が向上する万能な特徴量手法があるわけではない。さまざまなテクニックだけでなく、業務知識とも照らし合わせて、データの意味からも有意な特徴量を作っていくことがよいAIモデルを作る基本であり、それは自動AI製品ではまだ到達できない「人間データサイエンティスト」が生み出せる価値とも言える。
紹介した手法やツールで、読者が日々作成されているAIモデルの精度をあと1歩改善する手助けになることを強く願っている。
著者
都竹 高広氏
日本アイ・ビー・エム システムズ・エンジニアリング株式会社
Advanced AI
コンサルティングITスペシャリスト
データサイエンティスト
2002年入社。ネットワーク製品の技術サポートを11年間担当した後、データサイエンス分野に転向。現在は、製造系を中心にデータ分析プロジェクトやAIシステム構築プロジェクトに従事。

[i Magazine・IS magazine]