分析データの特定を
いかに効率化するか
「データ・ドリブン(データ駆動型)」という言葉を最近よく耳にする。データを活用して、将来の予測や意思決定、企画立案に役立てようという動きを指す。今多くの企業は、先の見えない将来を把握するために過去のデータを経営に活かし、成長を加速させようとしている。そのなかから成功例もいくつか出てきている。企業が今後、競争優位を確立していくためにはデータの活用によって先手を打ち、ビジネスを推進していく必要があるだろう。
データの活用にはデータ分析が不可欠であり、データの分析は「現状把握」「仮設立案」「有効性の検証」の3つのステップで行われる。一般的には「現状把握」で分析に必要なデータを特定し、次に「仮設立案」と「有効性の検証」のサイクルを回すことが多い。この2つを繰り返す頻度が多ければ多い程、分析の質は高くなる。
ところが現実的には、分析対象となるデータを特定する「現状把握」のステップでデータ分析全体の2/3の時間が費やされるという問題がある。データを特定するこの時間を短縮できれば、データ分析の質をさらに向上させることができるだろう。
データ分析における
非構造化データの問題
データを分析しようとすると、分析対象としたいデータのおよそ8割が非構造化データであるという事実がある。構造化データであれば、行と列で必要な情報が整理されているので対象データを特定しやすいが、非構造化データには「データの連続性と大容量」「データに関する情報不足」「データの類似性」という、以下の3つの特性があり、分析に必要なデータを探し出して特定するのが難しい。
データの連続性と大容量化
ドローンや監視カメラ、4K・8K放送などの映像・音声・センサーデータは、1つのデータが連続しているのに加えて、1つのデータがメガバイト、ギガバイトと大容量化している。そのためファイルを開く(読み込む)のに時間がかかり、中身を確認するにはさらに時間を要する。
データに関する情報不足
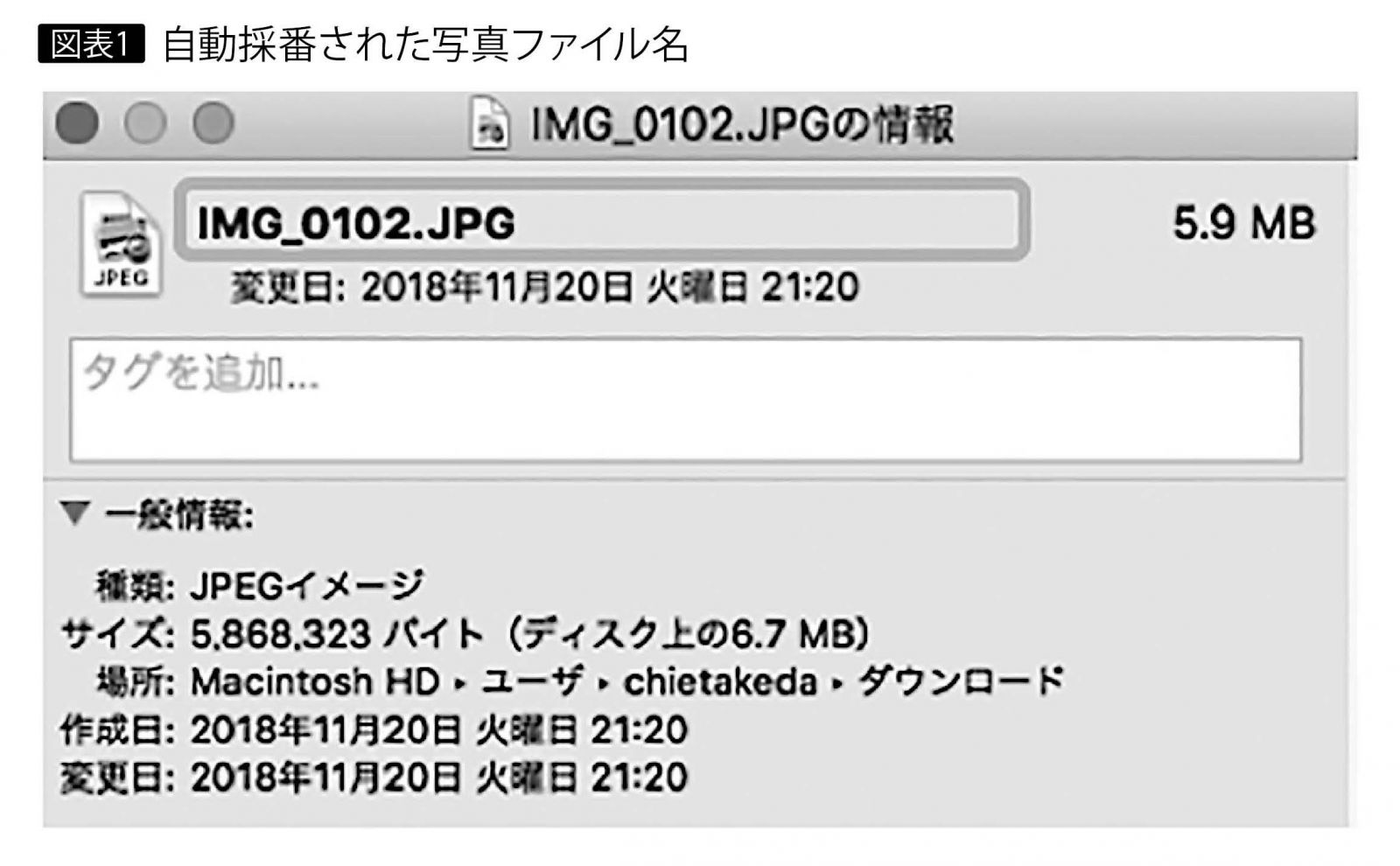
写真や映像データのファイル名は、撮影機械が自動で作成した英数字であるのが一般的である。このためファイル名を見ただけでは、何のデータであるのか判断するのが難しい(図表1)。
データの類似性
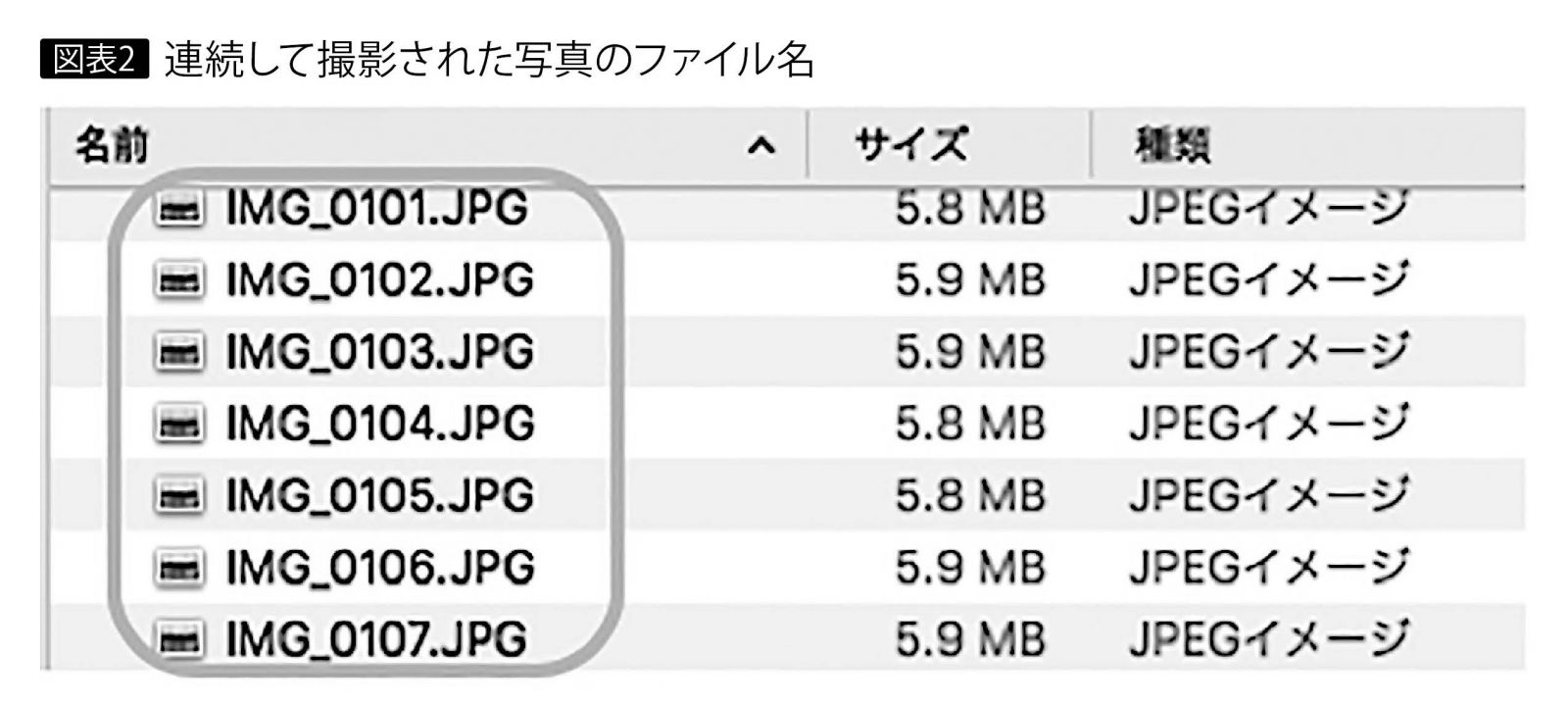
たとえば、連続して撮影した7枚の人物写真は、ファイル名が連続した異なる数字であるのでそれぞれが違う写真であることはわかるが、人物が目をつぶっているのか笑っているのか、ファイル名からは判断できない。そのため1枚だけを選んで分析対象とする場合は、選別が困難である(図表2)。
データに情報を付与する
メタデータ
そこで着目したいのが、「データのためのデータ」とも呼ばれる、データの付随情報である「メタデータ」である。
たとえば、Aさん宛てにリンゴを送るとしよう。リンゴはダンボール箱に入れてあり、配送先(Aさん)の住所・宛名、配送元の住所・送り主名を記したラベルがダンボール箱に貼ってある。そしてリンゴの産地・品種・糖度・生産者・お奨めの調理法などを明記した紙がダンボール箱に同梱されている。
この場合、「データ」はリンゴそのもの、リンゴ(=データ)に関する付随情報として添えられている配送先・配送元の住所・名前が「システム・メタデータ」、リンゴごとに販売者が追記した詳細情報が「カスタム・メタデータ」になる(図表3)。
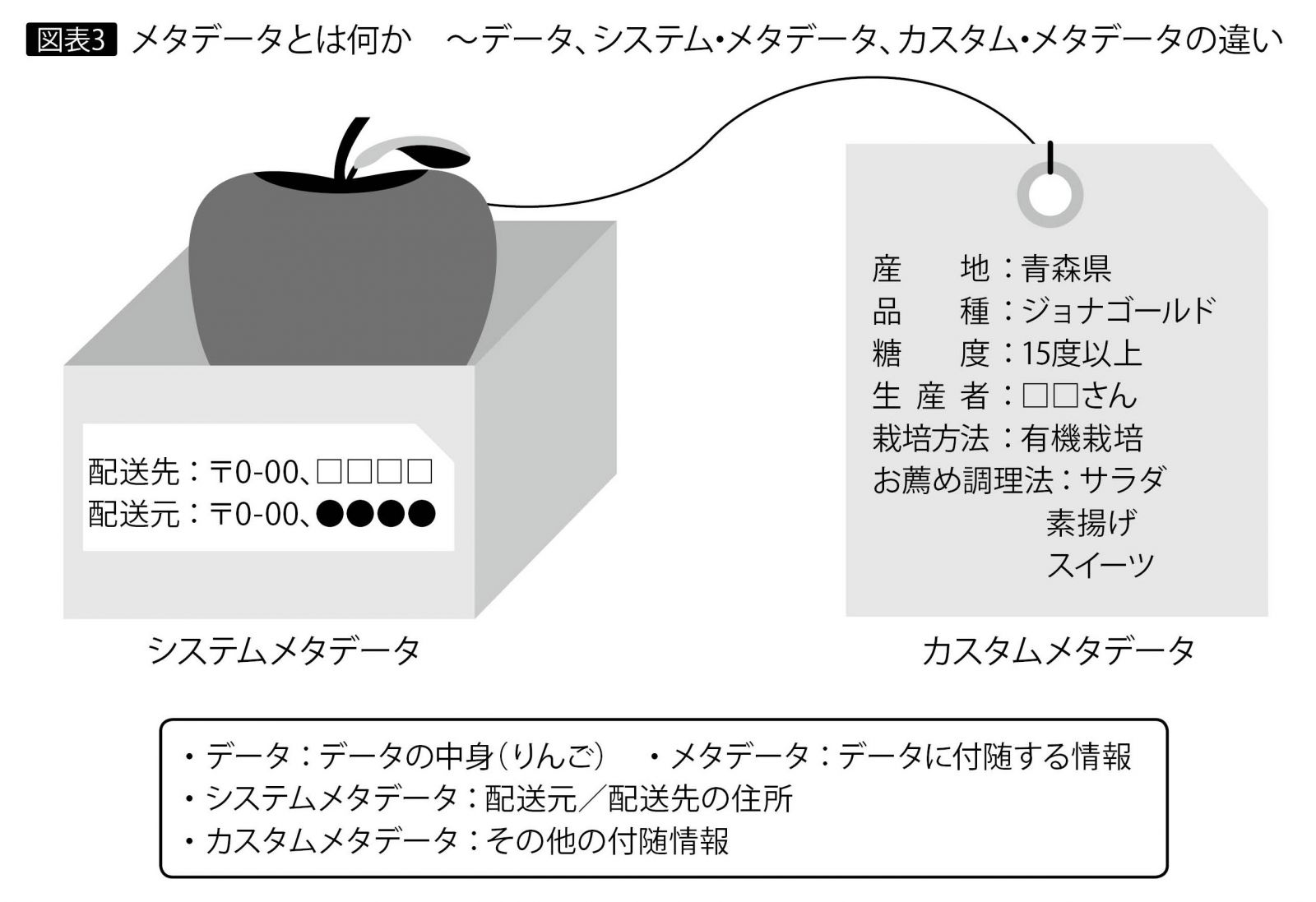
システム・メタデータとは、図表1の一般情報のように、種類、サイズ、場所、作成日、変更日などシステムによって自動で割り振られるメタデータである。一方のカスタム・メタデータは、個別のリンゴへの情報付加のように、必要に応じて自由かつ任意に定義できるメタデータである。たとえば映画なら、映画のタイトルのほかに、出演者名、監督名、制作年代、アカデミー賞の受賞有無、撮影のロケーション、あらすじ、などを明記しておくと、映画を見なくても必要な情報を入手できる。これがカスタム・メタデータである。
IBM Spectrum Discoverの
3つのソリューション
IBMが昨年(2018年)10月に発表した「IBM Spectrum Discover」は、ペタバイト・クラスの非構造化データにメタデータを付与できるSoftware Defined-Storage(SDS)である。SDSとは汎用サーバーにソフトウェアをインストールしストレージとして稼働させる製品で、IBM Spectrum Discoverは以下の3つの機能を提供する。
カスタム・メタデータの付与
(非構造化データ検索の効率化)
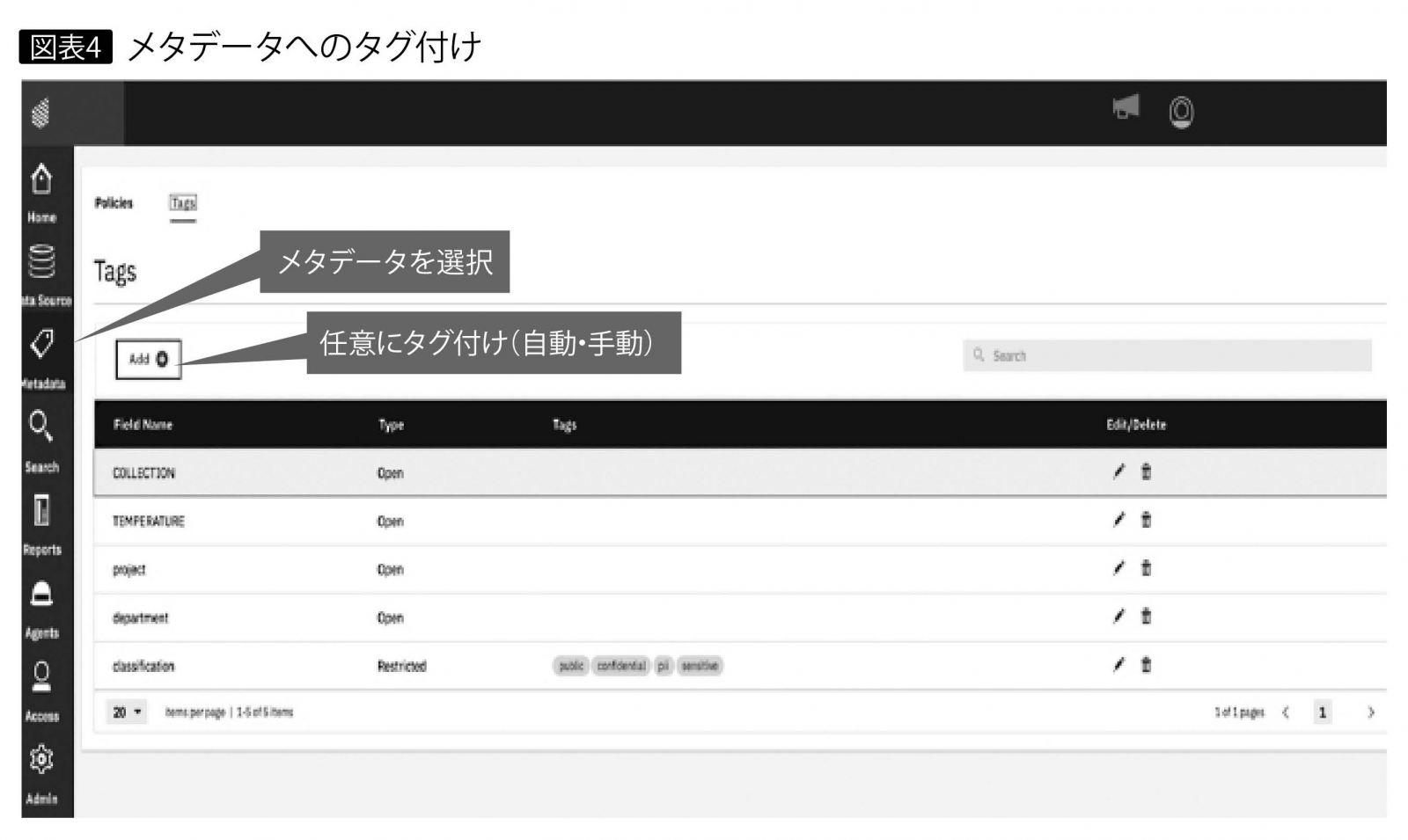
大容量かつ連続した非構造化データであっても、カスタム・メタデータを付与する機能を提供する。これにより、データの中身をREADしなくても判別可能となり、データの検索時間を短縮できる(図表4)。
ポリシー設定とカタログの自動作成
(標準ルール化)
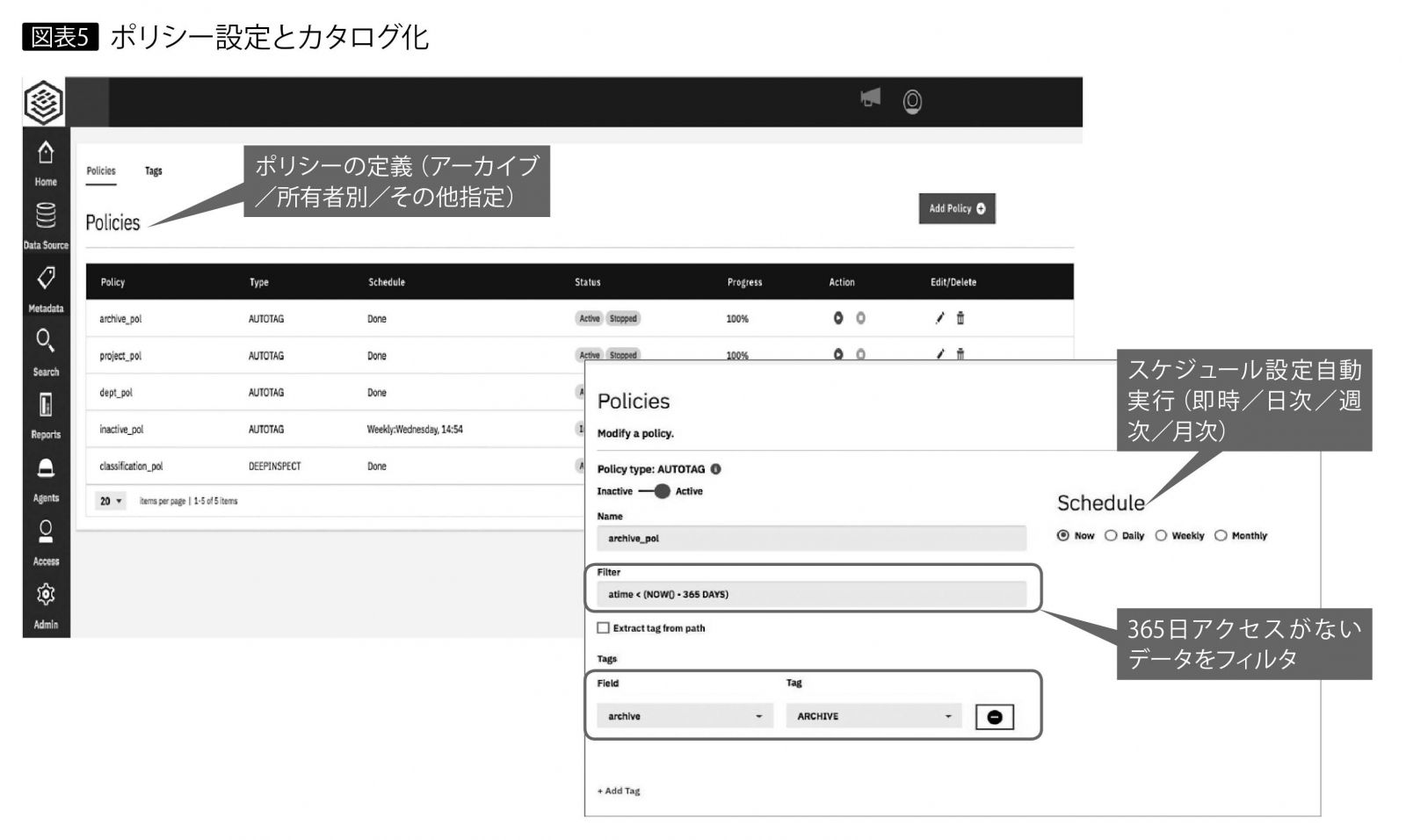
用途に応じてポリシーを自由に設定可能で、ポリシーに基づくカタログを自動で作成できる。たとえば、365日以上アクセスのないデータの検出をポリシーとして指定すると、ダッシュボード画面にアーカイブ推奨のデータとして表示される(図表5)。またデータが複数のファイルシステムやオブジェクトストレージなどに分散配置されていても、メタデータによる検索エンジンによって横断的に検索できるので、一元的な把握が可能だ。これにより、アーカイブすべきデータの特定と、高価で高速なストレージ層から安価で大容量なストレージ層への移動が効率よく行える。
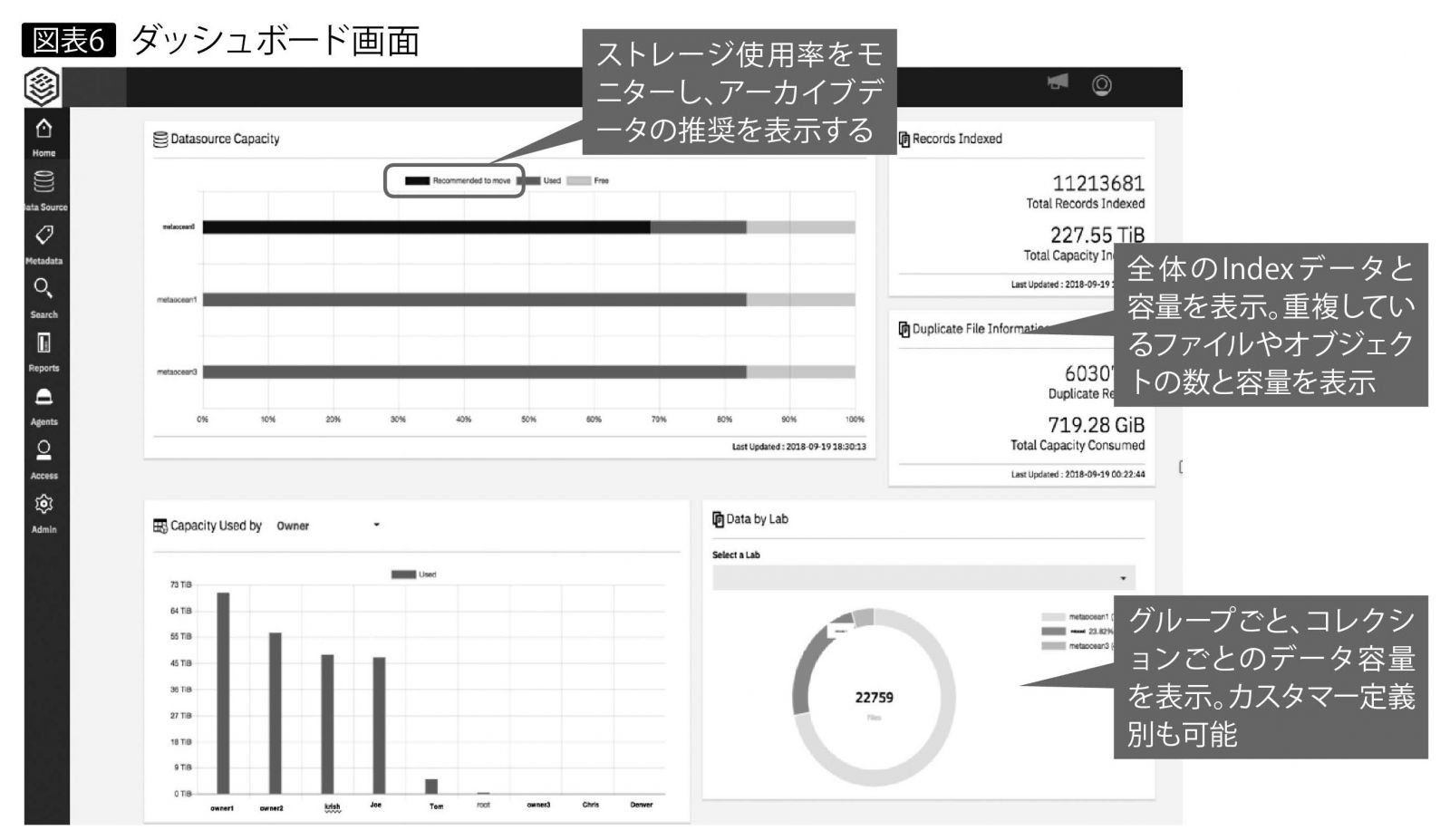
図表6のダッシュボード画面は、IBM Spectrum Discoverへのログイン後に表示される。この例では、オブジェクトとファイルの数は約1100万個あり、容量は約227TiB(テビバイト *1)、重複データは約600万個で719GiBであることが示されている。アーカイブ推奨のデータは黄色枠内の「Recommended to move」パートに表示される。
レポーティング作成
(データ証跡)
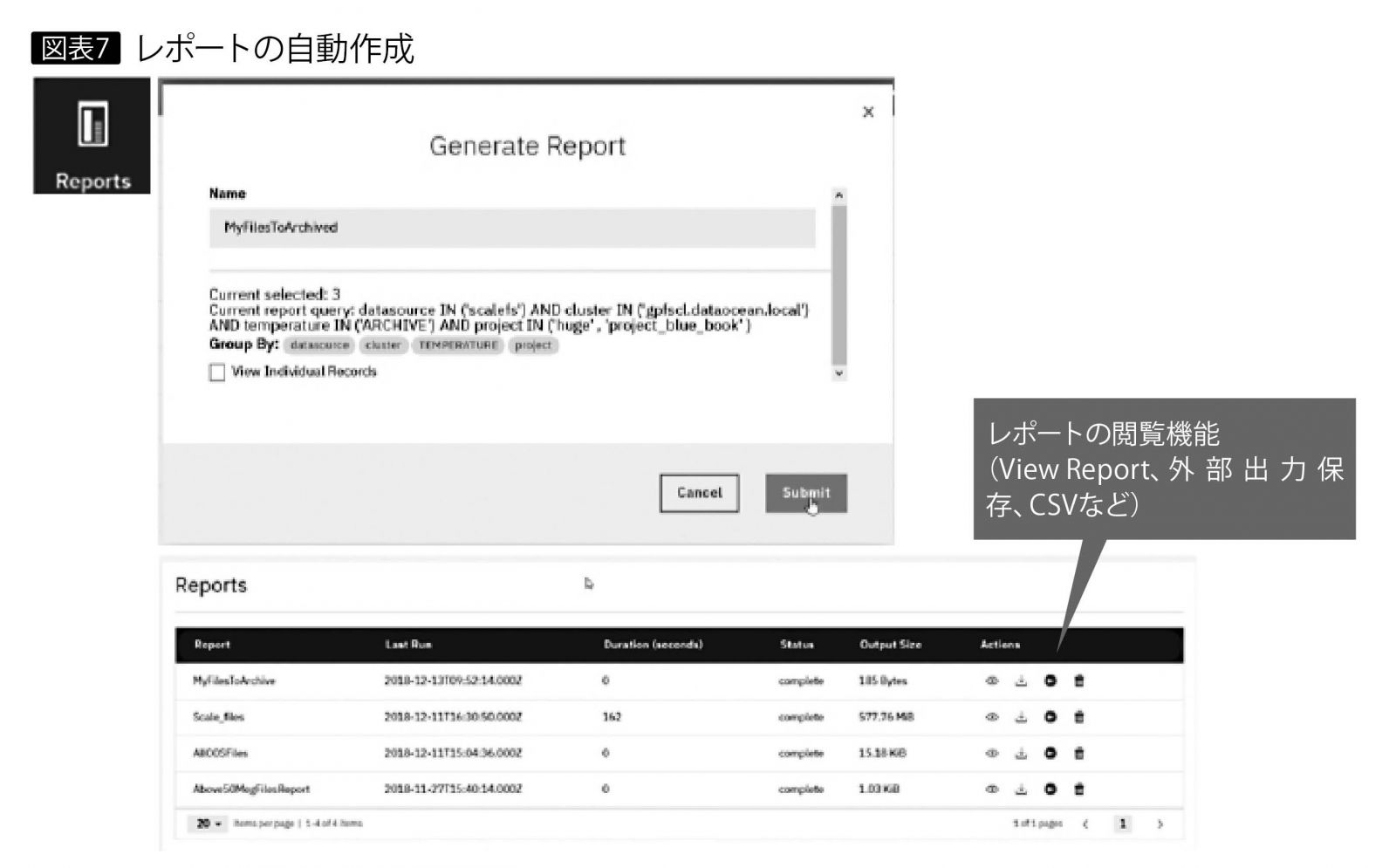
カスタム・メタデータやポリシーに基づくカタログに従い、レポートの作成が可能である(図表7)。これにより分析で使ったデータ群を特定してデータの証跡を辿ることが容易で、たとえば「ある交差点では夜21時以降に事故が多い」という仮説に基づくデータ分析Aで使った動画や写真を「データ群A」、同じ仮説に基づくデータ分析Bを行ったときの動画や写真は「データ群B」というような、データ分析における「データの振り返り」に役に立つ。
IBM Spectrum Discoverの
活用シーン
このようにメタデータ管理ソリューションは、非構造化データを分析するうえで欠かせない。
利用シーンとして、たとえばデータが重複しているかどうか、ROTデータ(Redundant:冗長、Obsolete:陳腐、Trivial:無駄)かどうかはどのように判断するのだろうか。
連写された写真の場合、データのファイル名は図表2の「IMG_0101.JPEG? IMG_0107.JPG」のような連続した数字なので、ファイル名からは何が写っているのかわからない。しかしカスタム・メタデータを付与すれば、連続したデータそのものが重複データであるとの定義付けが可能である。つまりデータの正確性を向上でき、重複データであるという判断に役立てることができる。
また別の利用シーンとしては、カスタム・メタデータをPII(Personally Identifiable Information:個人情報)とNon-PII(Non-Personally Identifiable Information)データの分類に適用することも可能だ。本来、セキュリティレベルが高く、暗号化されたファイルシステムに保存してあるべきはずのPIIデータが会社の規定に反してパブリッククラウド上に保管されていたような場合、カスタム・メタデータによってこれらのファイルやオブジェクトを特定することができる。ガバナンスやコンプライアンスのためにカスタム・メタデータを活用できる例である。
このほか、ストレージ全体の容量が逼迫してきた際に、どの部門の誰がデータを多く使用しているかをカスタム・メタデータによって確認し、不要なデータの削除を促すような使い方も可能である。
データをメタ・レベルで整理する
強力なエンジン
IBM Spectrum Discoverは現在、IBM Cloud Object StorageとIBM Spectrum Scaleとの接続をサポートしており、数十億のファイルおよびオブジェクトのメタデータをすばやく取り込み、統合化してタグ付けが可能である。今後、他社製品を含め、NASやオブジェクトストレージを中心に接続対象を増やしていく予定だ。
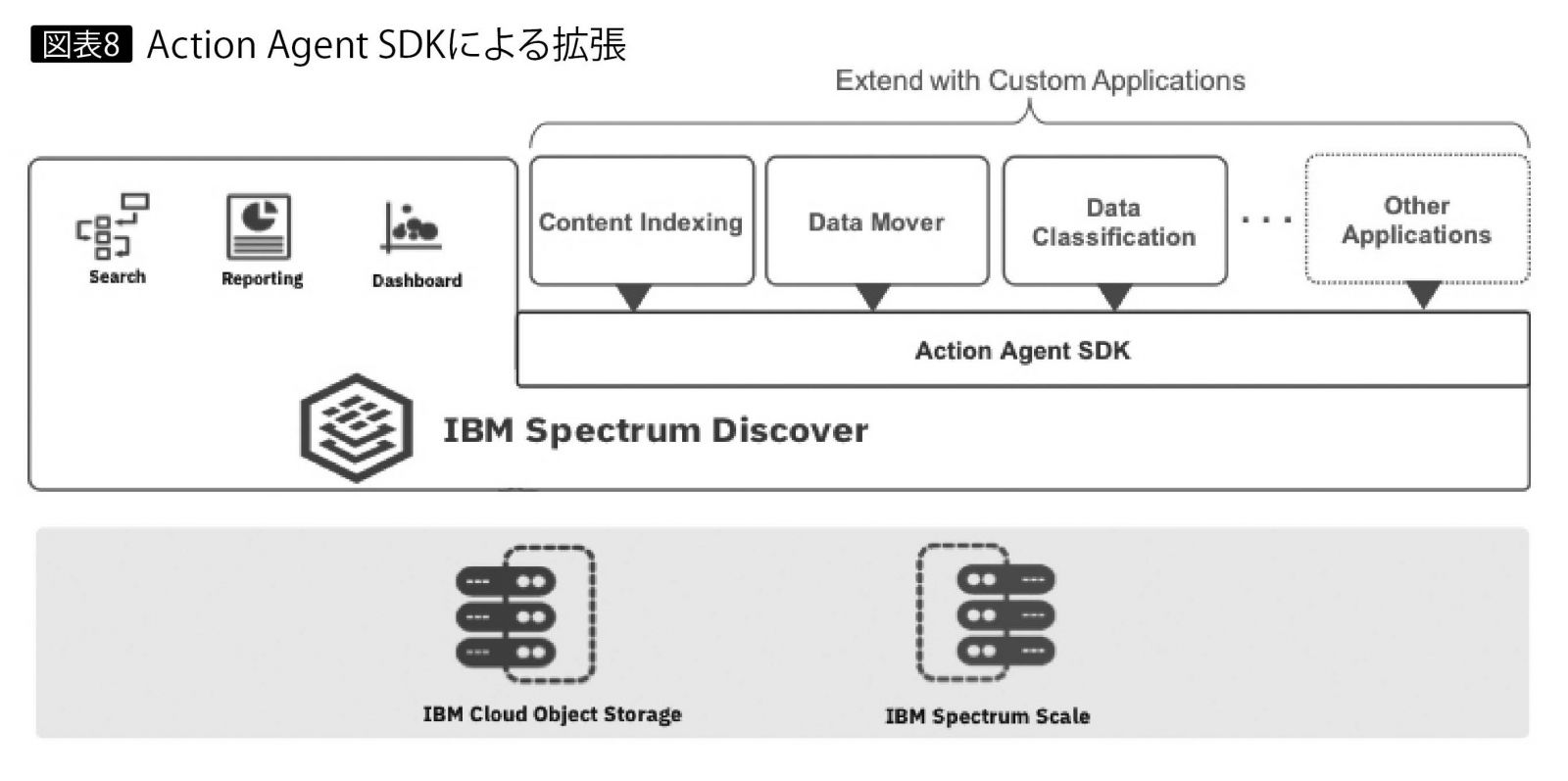
また、IBM Spectrum DiscoverのAct ion Agent SDKを用いることによってアプリケーションAPIを介した機能拡張が可能で、コンテンツの索引作成や機密データの識別なども行える(図表8)。この点に注目すれば、IBM Spectrum Discoverは、企業に分散する大量かつ複雑なさまざまなデータをメタ・レベルで明解に整理・統合する強力なエンジンと言うことができるだろう。
企業がデータ・ドリブンを実践し競争優位を目指すには、メタデータ管理ソリューションをベースとするデータ分析が欠かせない。IBM Spectrum Discoverに注目していただきたく思う。
著者|竹田 千恵氏
日本アイ・ビー・エム株式会社
システムズ・ハードウェア事業本部
ソリューション事業部
シニアITスペシャリスト

日本IBMに入社以来、ストレージSEおよびストレージ・テクニカル・セールスとして製造・流通・通信・金融など幅広い業界のITインフラ基盤の提案に携わってきた。現在、SDIテクニカルセールスとして、IBM Cloud Object StorageやSDSを中心に普及活動に努めるかたわら、IBM女性技術者コミュニティ「COSMOS」のコアメンバーとしても活動中。
[IS magazine No.22(2019年1月)掲載]