2014年から2017年にかけて、国内のデータ通信量は3倍に膨らんだ。2020年には、世界で40ZBものデータが発生すると言われている。データ爆発時代と呼ばれる昨今、機械学習や予測分析、IoTの導入を検討、あるいはすでに導入済みの企業も増え、膨大なデータを溜め込み、バッチで分析業務を実施している例も少なくない。
最初は数時間で終わっていた処理も、データ量の増加に伴い夜間バッチになり、さらに処理時間が延びて夜間では終了できず、週末バッチになる。今はまだ業務時間に侵食していないかもしれないが、今も増え続け、蓄積され続けるデータに対して、今後バッチだけで処理できるだろうか。
そこで本稿では、ビッグデータを分散処理システムで扱う際の課題とその解決策について解説する。
分散アプリケーションの実装
ビッグデータを扱う分散処理システムとして、Hadoopが広く普及した。Hadoopとは、クラスタ上で分散処理を実行するアルゴリズム、または処理エンジンを指す「MapReduce」とそのファイルシステムの「HDFS(Hadoop Distributed File System)」を含む分散コンピューティングシステムのフレームワークである。
Hadoopを使用したシステムでデータを操作する場合、Map処理(入力を分割してKey-Valueに変換する)と、Reduce処理(Mapで分割したKey-ValueのデータをKeyごとに集約する)を実行するMapReduce(以下、M/R)というアルゴリズムを用いたJavaアプリケーションが必要である。
M/Rアプリケーションの実装は、従来のプログラミングパラダイムとは異なり扱いづらく、M/RのフレームワークやAPIに慣れるまでの学習コストもかかる。より精度の高い分析に向けて、アプリケーションコード内のパラメータや処理ロジックを見直し、実装し直すことも少なくないため、非常に時間がかかり、分析業務のスピード感が失われる。
このような背景から、RDBのように使い慣れたSQLを用いて蓄積したデータにアクセスし、検索・加工できるようなインタラクティブな機能が必要とされた。そこでアプリケーションエンジニアだけでなく、Javaプログラミング経験のない人でも、HDFSで管理しているデータをSQLライクにクエリできるHive、Pig、Presto、Impalaといったさまざまなクエリ処理ツールが実装された。
たとえばFacebook社で開発されたHiveというツールは、HDFSに保存されたデータを組み替え、構造化されたテーブルを提供する。Hiveのクエリ言語はHiveQL(Hive Query Language)と呼ばれ、クエリの実行時、自動的にM/Rのジョブに変換し、内部的にM/R処理を実行する。HiveはJDBC接続可能で、Javaアプリケーション内でもHiveQLを使用できる。例に挙げた図表1はJavaのM/RアプリケーションとHiveQLのクエリで、どちらもテキストファイル内の同一文字列の出現回数をカウントするサンプルコードである。

リアルタイムなデータ処理とは
データ量の増加に伴い、バッチ処理に要する時間も増える。どうすれば、業務時間に食い込まずに処理できるか。データ処理用のリソースを増やす前に考えられる対応策としては、流れてくるデータを即座に、かつ継続的に処理し、不要なデータを溜め込まないことがある。従来のバッチ処理のように溜め込まず、そのまま流動的にデータを扱うことを「ストリーム処理」と呼ぶ。
ストリーム処理は、以前のバッチアプリケーションのデータ処理とは異なる(図表2)。従来のバッチ処理では、外部から入力されるデータをデータベースやファイルに一時的に格納したあとに、クエリやM/Rアプリケーションなどでデータの変換処理を実行して結果を出力する形式だったが、ストリーム処理は流れてくるデータを即時に処理する。
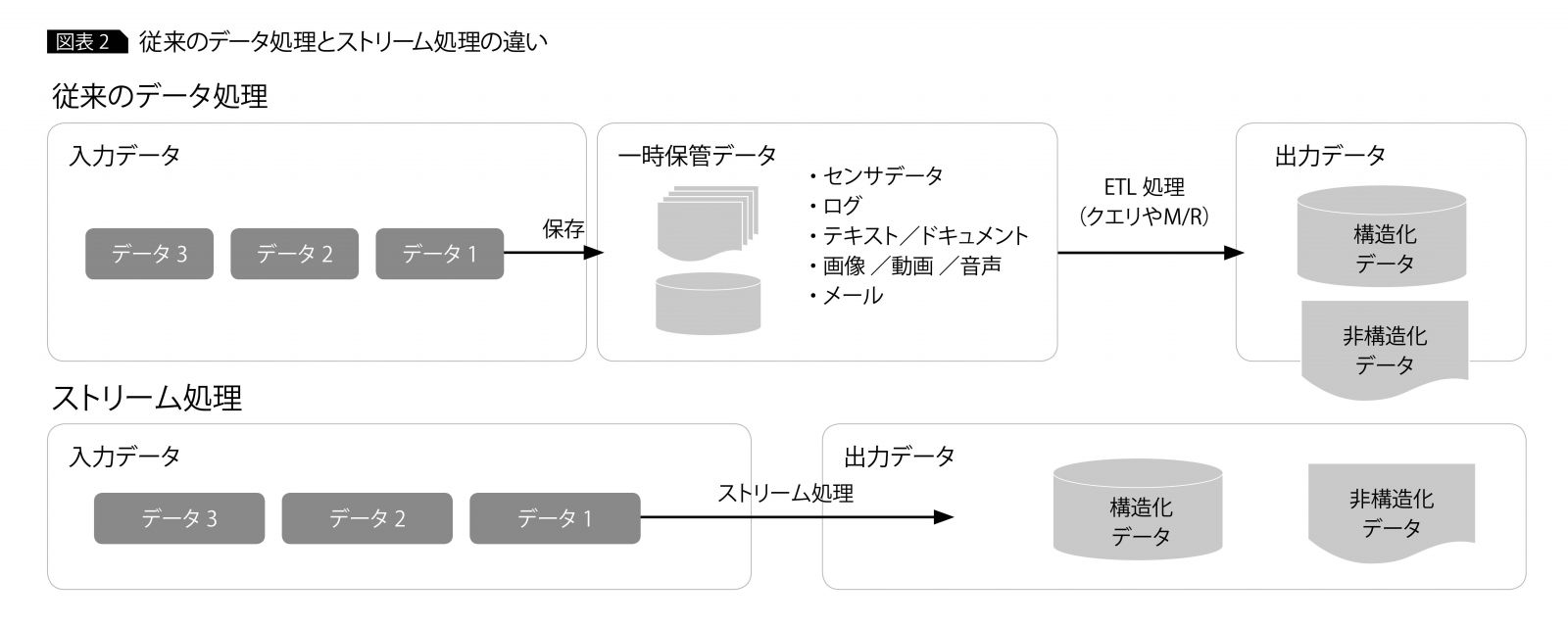
業務ログやWebアプリケーションログ、アクセスログ、さらにはIoT導入によるセンサデバイスのデータは、最大で毎秒数件生成される。上記のようなデータは溜めてから一括処理するバッチではなく、データが生成・到達したタイミングで活用することに価値がある。
ストリーム処理に適したデータはその瞬間に使わなければ、「とりあえず貯めておく」だけの必要のないデータとしてストレージを圧迫する。「今、この瞬間」に必要なデータがすぐに入手できれば、世の中のニーズに即応し、迅速に意思決定できる。
リアルタイム性の求められる処理としては、以下が挙げられる。
・従量課金制アプリケーション
・携帯料金や通信料の計算
・不正アクセス検知
・センサデバイスからのデータによる機器異常検知、故障予測
・アプリケーションのユーザーログイン数や実行ログからの利用者状況把握
またリアルタイムなデータ処理が必要でない場合でも、以下のように繰り返して同じ処理を行う対象データに対しては、ストリーム処理を適用できる。
・オンライン機械学習(ストリームデータで学習したモデルを即時反映)
・受信した非構造化データを構造化し、データベースなどに保存、永続化
バッチで学習させる機械学習は通常、新たなデータを加えて再学習させる。その際、過去に使用したデータと新たなデータの両方を使用してモデルを再生成する必要があるので、多くの時間が必要になる。
一方、常に学習するオンライン機械学習は、新たなデータを取り込むごとに更新する。そのためバッチによる機械学習に比べて学習時間を削減でき、精度を常に高く保てる。
蓄積された膨大なデータは、用途に合わせて加工する必要がある。バッチ処理は大きく、「読み込み」「加工」「書き込み」の3つの過程に分かれる。センサデータや日々の業務で生み出されるログなど、ほとんどのデータは非構造化データで、蓄積されたファイルから ETL(Extract /Transform/Load)を実行し、構造化データに変換して分析などに活用する。ETLのように変換ルールが決まっており、反復的に実行するような処理はストリーム処理が適している。
Sparkという解決策
実装が難しく、学習コストがかかるM/Rアプリケーションも、SQLライクな処理エンジンの登場で容易に、かつインタラクティブにM/R処理を実行できる。流動的なデータはストレージに溜め込むことなく、リアルタイムに処理することで価値あるデータとして活かせるようになる。
バッチ処理の課題を解決する方法はあるが、具体的にどのようなツールがこれらの要件を満たすのか。クエリ実行エンジンは前述したように選択肢が多く、同様にストリーム処理用のツールもStorm、NiFi、Flinkなどさまざまである。
ここではクエリ実行、ストリーム処理の両方に対応しているツールの1つとして、「Apache Spark(以下、Spark)」というオープンソース・ソフトウェアを紹介する。
Sparkは概念的にRDBのテーブルと同様、カラムで表現される構造化データとして容易に扱えるSpark SQLが用意されており、さまざまな種類のフォーマット、データソースをサポートする。
またSpark Streamingは、連続するストリーミングデータを一定間隔(通常500ms)で細かく区切ったデータに対してバッチ処理するマイクロバッチ処理という方法でストリーム処理を実現しており、ストリーム処理で使用できる集計用の関数など、多彩な関数が用意されている。
Spark SQLでM/R処理を容易に、そしてSpark Streamingでリアルタイムなストリーム処理を実装する。Spark StreamingとSpark SQLを組み合わせると、インタラクティブに開発したSpark SQLのクエリをM/R処理として、ストリームデータに対して実行できる。
図表1のWordCountのM/Rサンプルコードは、図表3のように変わる。HiveQLに比べてコード量が増えたように見えるが、HiveQLは流動的に流れてきたデータがHDFSにすでに保存・蓄積されていることが前提である。 一方で、Spark StreamingとSpark SQLによるWordCountのコードは、データの取得・加工・出力までのすべての流れを1ファイルで記載できる。
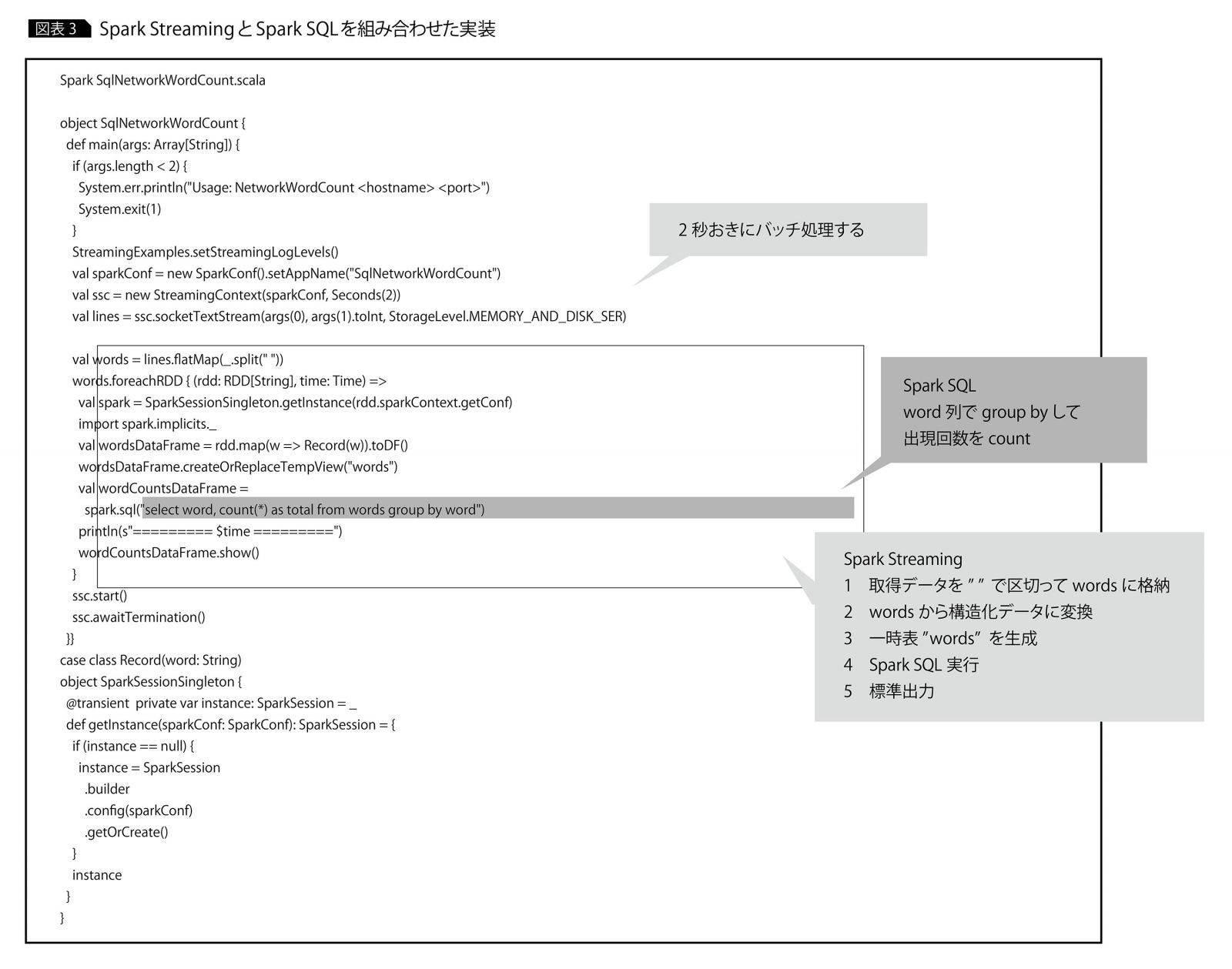
このようにSparkを活用することで、M/Rのバッチアプリケーションに比べ、ストリーム処理でも容易にコーディングでき、コード量も大幅に削減できる。
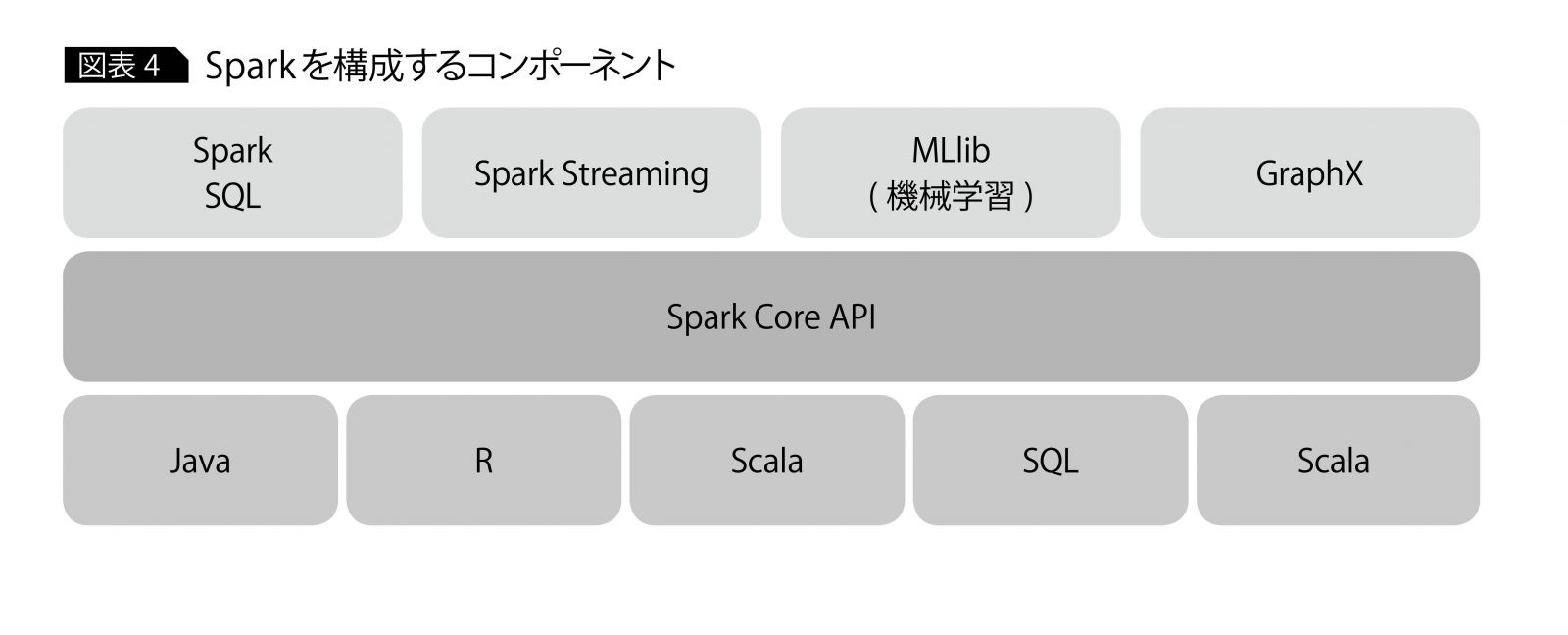
そもそもSparkは、HadoopのM/Rモデルを拡張した大規模データ分散処理プラットフォームとして開発されており、メモリ上で演算処理するため、M/Rに比べて高速と言われている。またSparkは前述したSQL、ストリーム処理以外にも、バッチ処理はもちろん、機械学習ライブラリやグラフ分析なども提供している。
ただしSparkは、Hadoopという分散フレームワークに置き換わるものではない。HadoopのM/R処理部分に相当する。Spark自体はデータ管理機能を備えていないので、既存のHDFSを使用してM/RからSparkに移行するケースや、HDFSのない環境でもさまざまなフォーマット(テキスト、CSV、JSON、Parquet、Sequence
Fileなど)、データソース(Hive、HBase、Cassandra、JDBC接続したRDBなど)で利用可能である。
ちなみにSpark 2.0から、Spark SQLエンジン上に構築されたエンジンでストリーム処理を実行する「Structured Streaming」という機能が正式に追加された。Spark Streamingの弱点である遅延データの扱い方や格納時のデータ欠損、データ生成時間に基づく処理を克服し、実際にデータが生成された時間に基づいて遅延データや順不同データを集計結果に入れるのか、削除するのかを自動で判断できる。
業務処理では、日次や週次の大型定期バッチ処理が不可欠である。IoT導入やビッグデータ活用に着手し、その分析結果を活かして業務改善を進めていく必要もある。しかし、データ増加に伴う問題から目を背けてはならない。
もちろん、全バッチ処理をSQLやストリームで置き換えられるわけではない。重要なのは、これから集めようとしているデータ、すでに所持しているデータは「溜めておく」のではなく、それらがどのような種類のデータなのか、本来どのように扱うべきかを理解することである。データを正しく扱えれば、バッチの突き抜けやストレージの管理、リソースの増設などのコストも抑えられる。
Sparkはバッチ、SQL、ストリーミングだけでなく、機械学習、Rによる分析、グラフ分析など1つのソフトウェアでさまざまな分析用コンポーネントを提供している(図表4)。データが増えてバッチが限界に至る前に、データとその処理に無駄がないかを確認してはどうだろうか。
参考:総務省『平成26年版 情報通信白書 ICTの進化が促すビッグデータの生成・流通・蓄積』
・・・・・・・・
著者:高橋 裕大
日本アイ・ビー・エム
システムズ・エンジニアリング株式会社
コグニティブ・ソリューション
デジタル・イノベーション
ITスペシャリスト

2014年に日本アイ・ビー・エム システムズ・エンジニアリング入社。アプリケーションのコーディングからミドルウェア、インフラまで幅広く経験。自動車業界、保険業界、官公庁のアプリケーション開発案件から、インフラ構築案件などに従事。