昨今は技術者でなくても、多くの人たちがFacebookやTwitterといったソーシャルネットワーキング・サービス(以下、SNS)や乗換案内のアプリを利用している。膨大なデータからどのようにして、検索を起点にした関連情報を芋づる式に、しかも即座に取り出しているのだろうか。その背景にはグラフデータベース(以下、グラフDB)やそれに類した考え方がある。
グラフデータベースとは
グラフDBとは一言で言うと、グラフ構造を備えたデータベースのことである。データの構造が従来のリレーショナルではなくネットワーク状になっている場合に、格納・検索の面で威力を発揮する。
グラフは「ノード」「エッジ」「プロパティ」の3要素によって、ノード間の「関係性」を表現できる(図表1)。
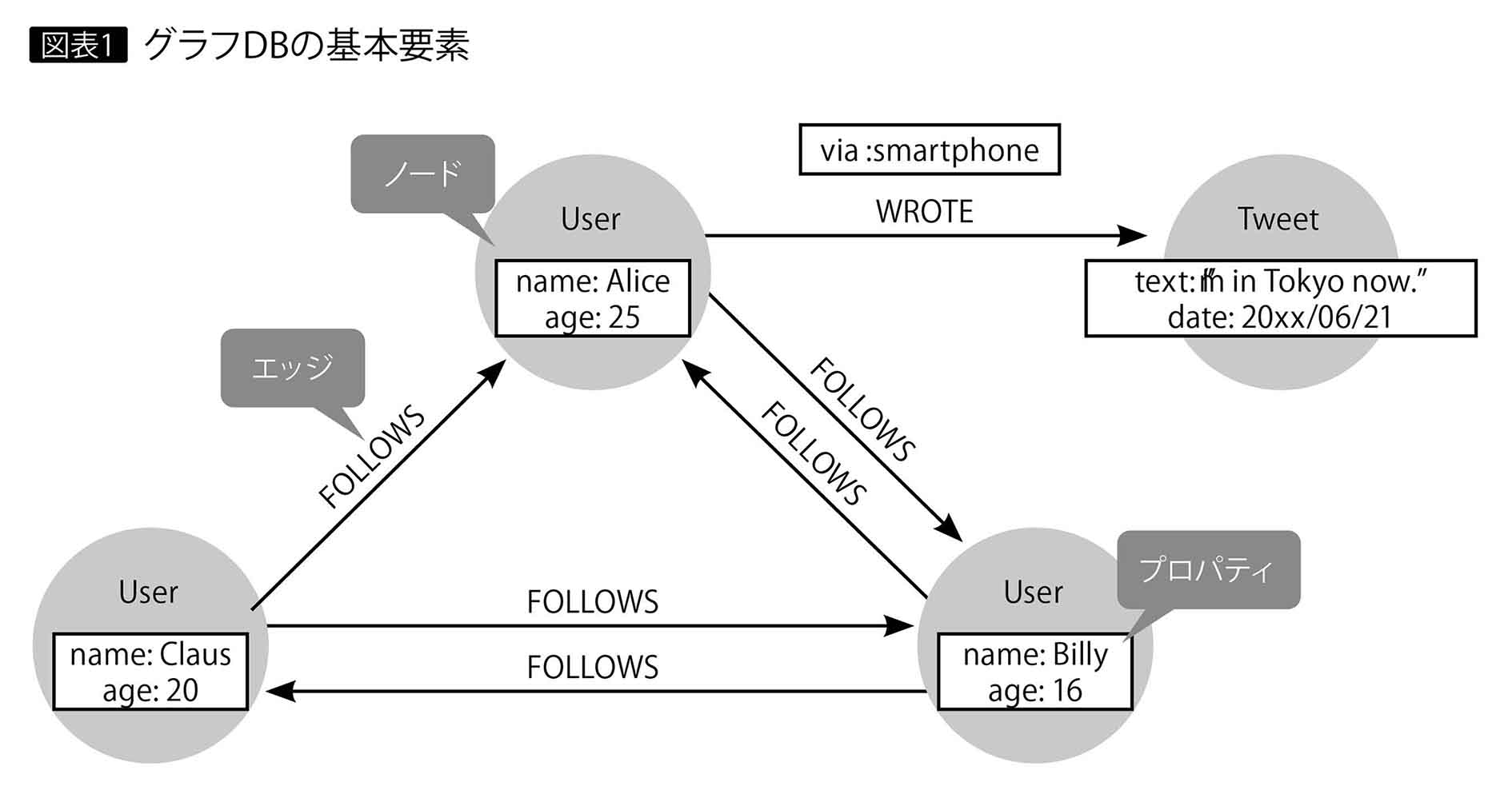
ノード(node):別名バーテックス、頂点。点や丸で表現されるエンティティー。「ラベル」を付けて種別を分類することが多い。
エッジ(edge):別名リレーションシップ、辺。ノード間の関係性を表す。方向とタイプを有する。
プロパティ(property):別名、属性。ノードとエッジにおける属性情報。データはkey/value形式で保持される。
ここでの「グラフ」とは、Excelの折れ線グラフ(=チャート)などではなく、ネットワーク状のデータ表現であることに注意されたい。グラフにはさまざまな表記レベルがあるが、グラフDBでは一般に、エッジは矢印で表現されるように一方通行の向きがあり(有向グラフ)、属性情報はプロパティという形で保持される(プロパティグラフ)。
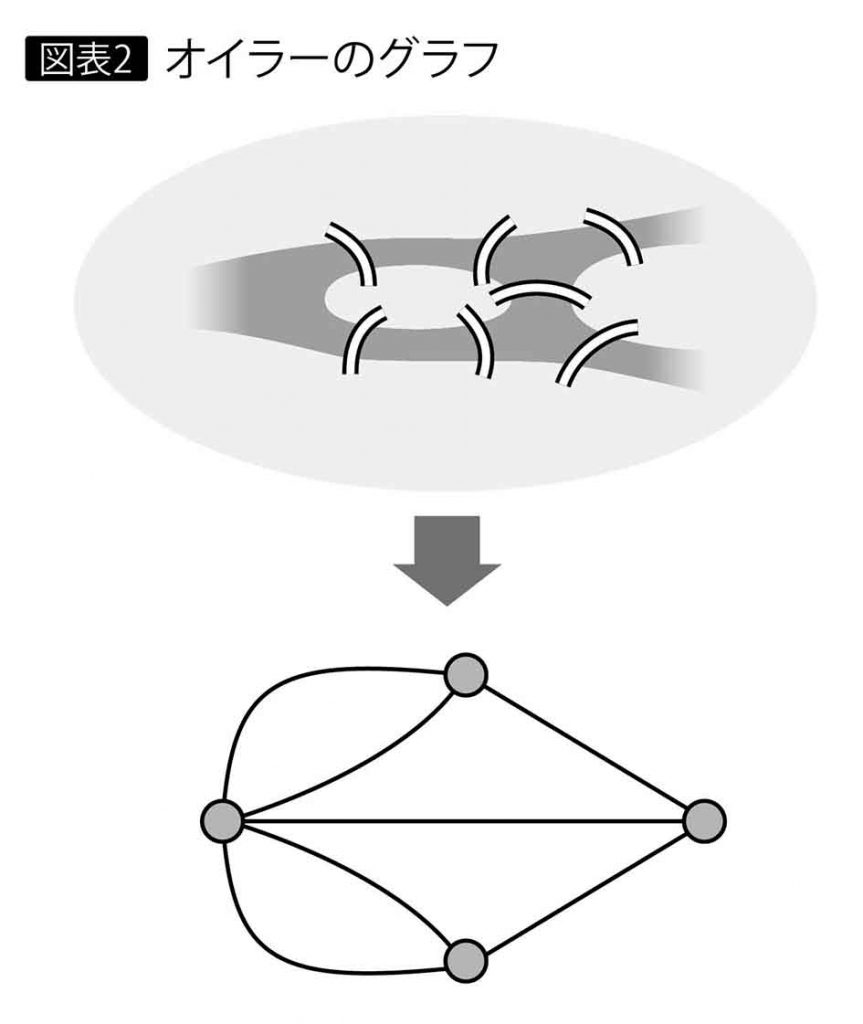
このグラフ検索を可能にしている土台には、「グラフ理論」がある。時代は18世紀に遡る。プロイセンのケーニヒスベルグ(現ロシア連邦)のプルーゲル川には、中洲を挟んで7つの橋がかかっており、当時、町の人たちは「どこか1つの場所から7つの橋を1度ずつ全部渡って、元の場所に帰ってこられるか」という問題を議論していた。
数学者のオイラー(Leonhard Euler)は、地点と橋を点と線(ノードとエッジ)の図形に単純化し、「この図形は一筆書きで書くことができない」ので、既述の問題の課題は無理であることを数学的に証明して見せた(図表2)。これがグラフ理論の始まりと言われている。
代表的なグラフ検索のアルゴリズムとしては、ツリー構造のグラフで目的の情報を探す「幅優先検索」や「深さ優先検索」、重み付けされたエッジを加味して最短経路検索を行うダイクストラ法やA*法などがある。
要は点と線を結んだネットワークなので、地下鉄の路線図、SNSの人と投稿記事の関係性、脳神経系、塩基配列、インターネットなども広い意味ではグラフとみなせる。グラフ構造は、身近なものと言えるだろう。
グラフDBは
なぜ検索が速いのか
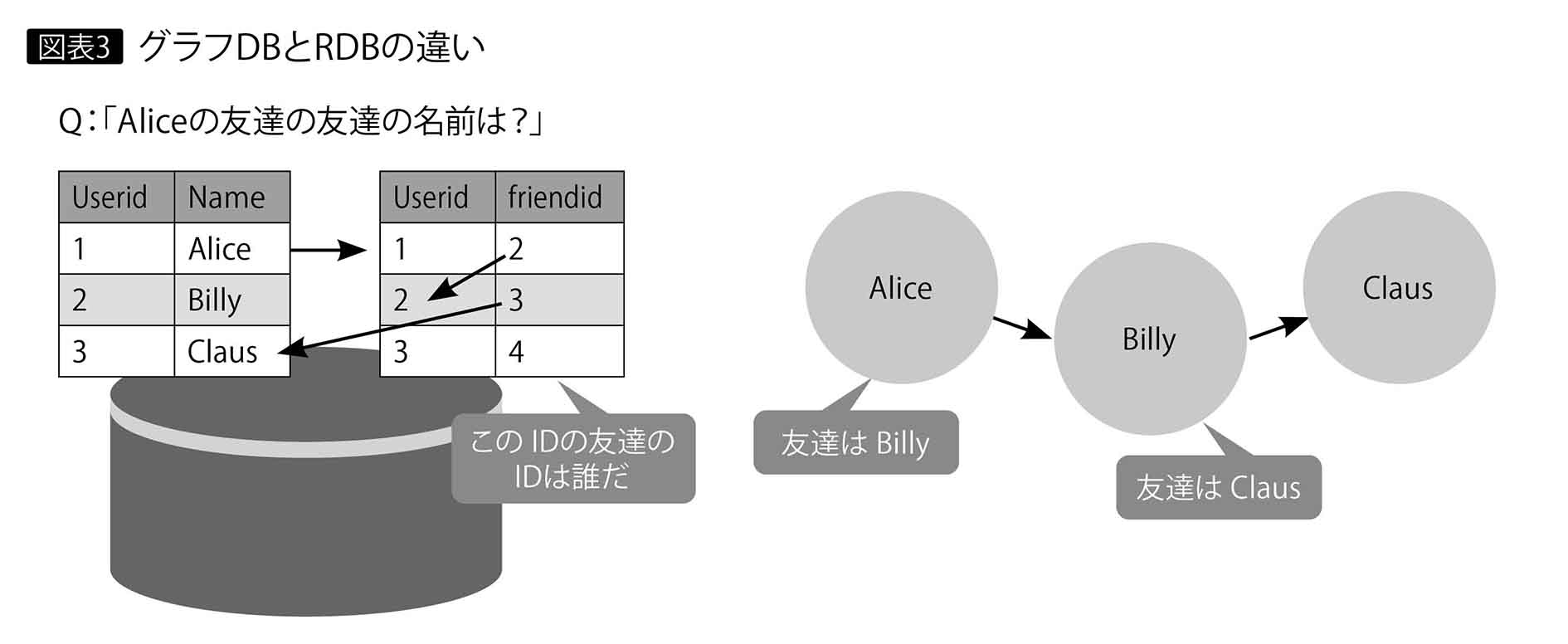
グラフDBは、つながりのあるデータを可視化する表現力があるのはわかる。しかし検索が速い、SNSのような大規模なデータからの検索が効率的なのは、どのような仕組みによるのだろうか。我々がよく知るリレーショナルデータベース(以下、RDB)と比べてみよう。
グラフDBでは、テーブル単位ではなく個々のデータ単位で「つながり」が保持される。RDBでは外部キー(インデックス)を使ってエンティティー(ノード)を2次的につなぐのに対し、グラフDBのモデルではエンティティー間のリレーションが明示的に組み込まれている。
RDBはインデックスの参照やテーブルを連結したビューの用意で時間がかかるのに対し、グラフDBはノードがもつ隣接ノードの情報をたどるだけなので、回答が速い(図表3)。ネットワークの規模が巨大になるほど、膨大な数のノードのネットワークから目的を探索する際に、パフォーマンスを落とさずに結果を返すことができ、ビッグデータ時代に活躍できる能力を秘めているのである。
図表4は、SNS内で友達の友達を最大5段階の深さまで見つける検証の結果である。それぞれが約50人の友達をもつ100万人規模のSNSでは、効率の差が如実に現れる。深さ3(友達の友達の友達)になると、RDBでは実用的な時間でクエリーに対処できないのは明らかだ。
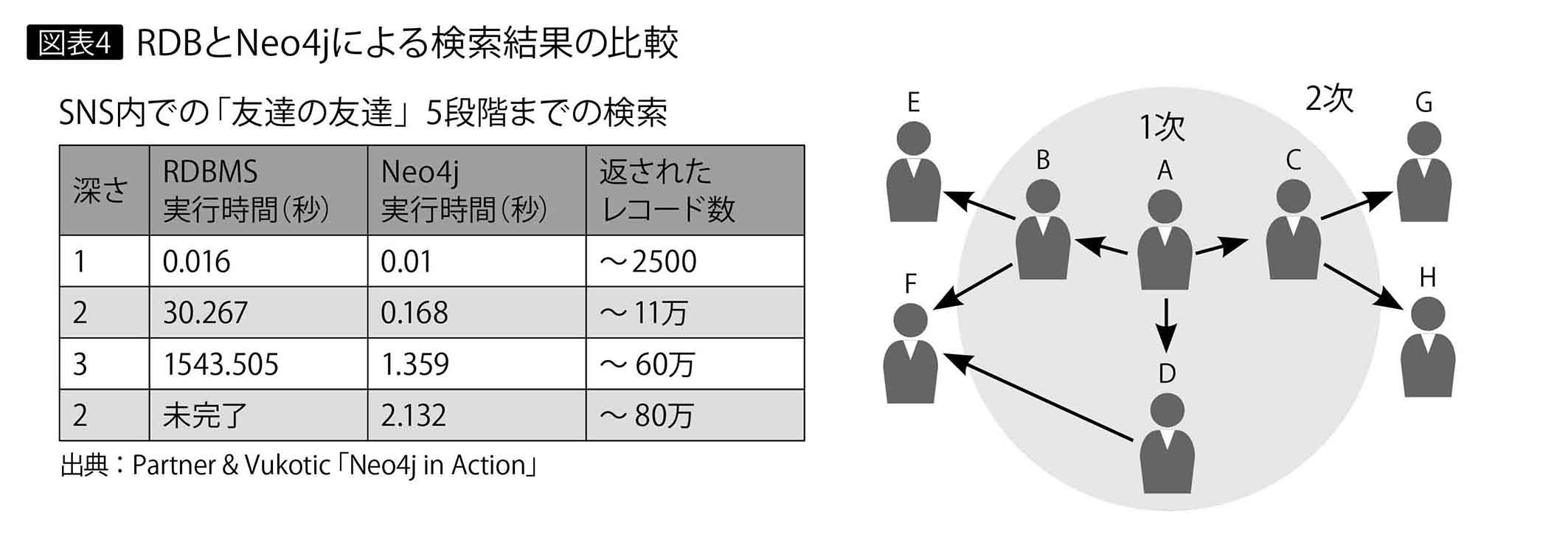
一方、グラフDBはデータ全体からの統計情報を分析する手続きなどは苦手で、そもそもデータ構造が「つながり」をもたない表だけであれば、グラフDBで処理するメリットは乏しい。どんなケースでもRDBに置き換わるわけではないということだ。ちなみにグラフDBは、非リレーショナルデータベースを意味するNoSQLデータベースの1つに分類されることもある。
グラフDBの活用例
ソーシャルグラフ
すでに見てきたように、SNSのソーシャルグラフはグラフ構造の典型である。友達の友達という探索ができるほか、フォロワーが多くて影響力の強いユーザーを見つけ、その行動や購買が個人の挙動に及ぼす影響の洞察も得られる。
さらに口コミでの浸透を期待したバイラル・マーケティングを実施したり、特定の事項・趣味について集まる集団(クラスタ)に対してピンポイントに情報提供するターゲットマーケティングなどが商用でも期待されている。
リコメンデーション
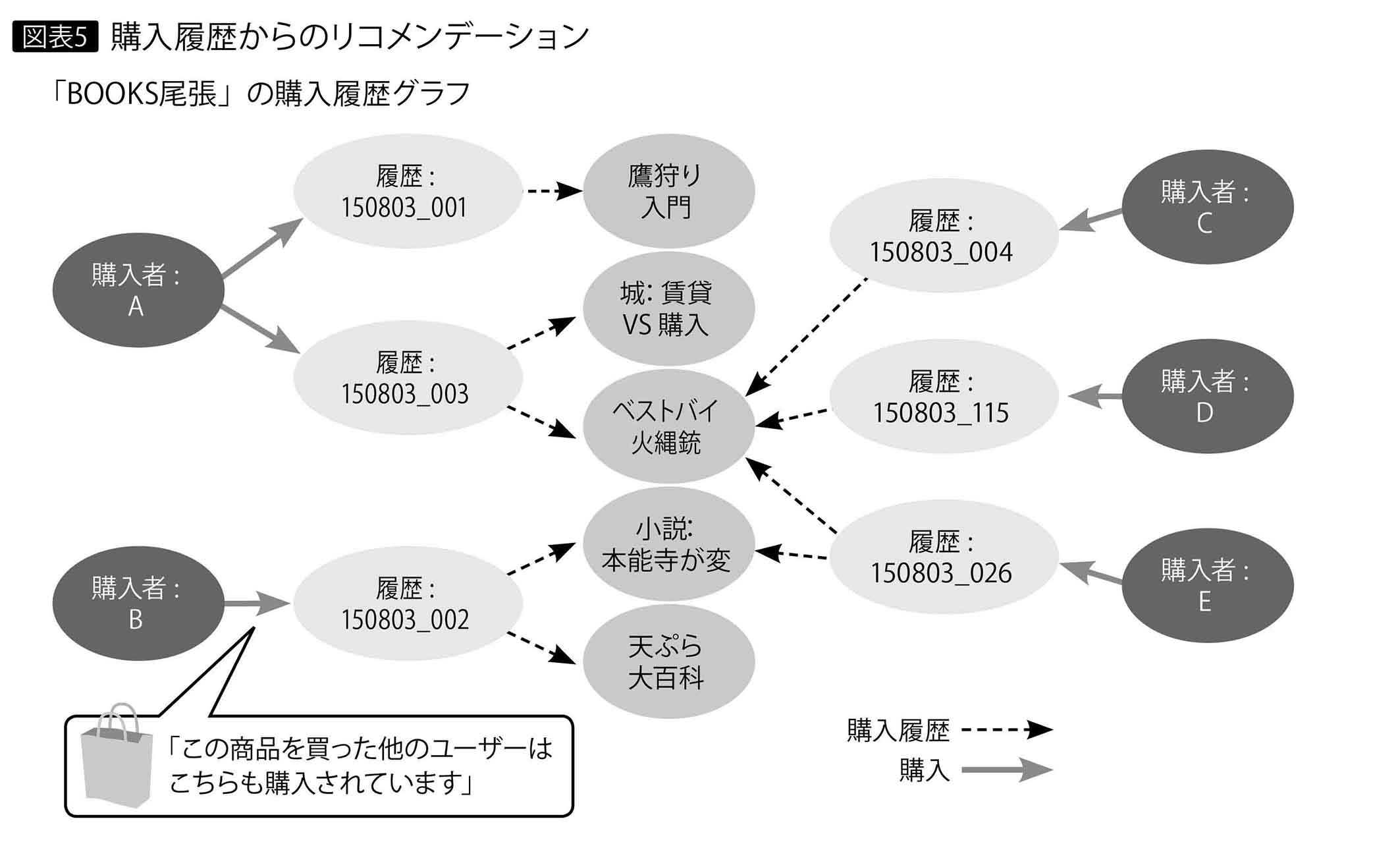
ソーシャルグラフの応用とも言えるが、とくにECサイトなど購買行動が関係する際に有効である。「スポーツ」をフォローしている3人の顧客ユーザーがおり、そのうち2人が実際に製品を購入したので、残りの1人も製品を購入するかもしれない。そのユーザーがログインしたECサイトのページには、「これを購入された方は、こちらも購入されています」と表示される(図表5)。
経路検索
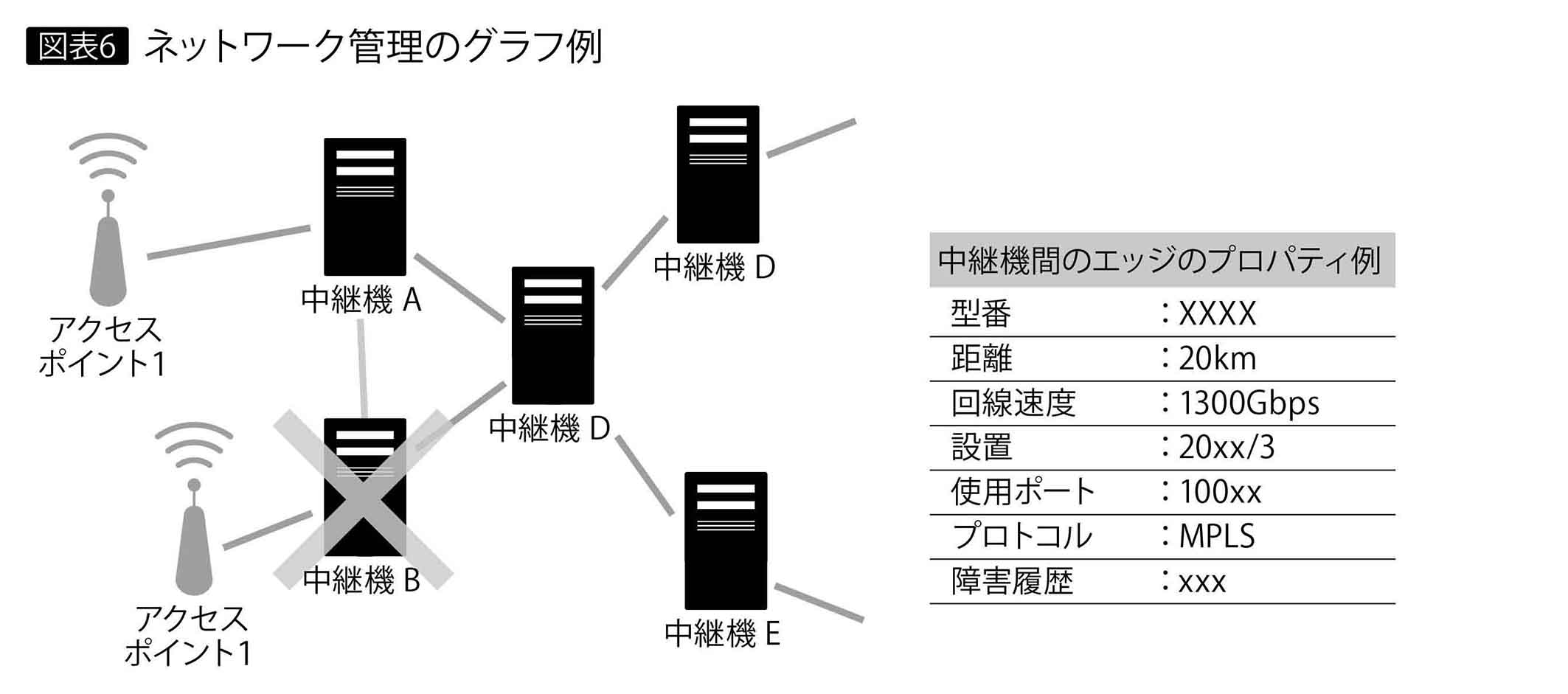
カーナビのような最短経路検索のほか、物流でどのルートを順に回れば一番効率がよいか、また交通網が事故で一時的に停止したときや複雑なアクセス権限のあるシステムで権限付与を変更したときに、後続にどのような影響が出るかをシミュレーションできる。図表6は中継機器ノード、ネットワーク回路をエッジに置き換えてグラフで図示している例である。故障したときにどの経路をたどれば通信品質を保てるか、古くなった機器を交換するときにどの順で止めればいいか、その影響度を調査できる。
不正検知
ネットワークアクセスやクレジットカードの取引履歴から、普段と異なる経路や使用のパターンを検出して、不正なアクセスや不正なアカウントを割り出すのに用いられている。
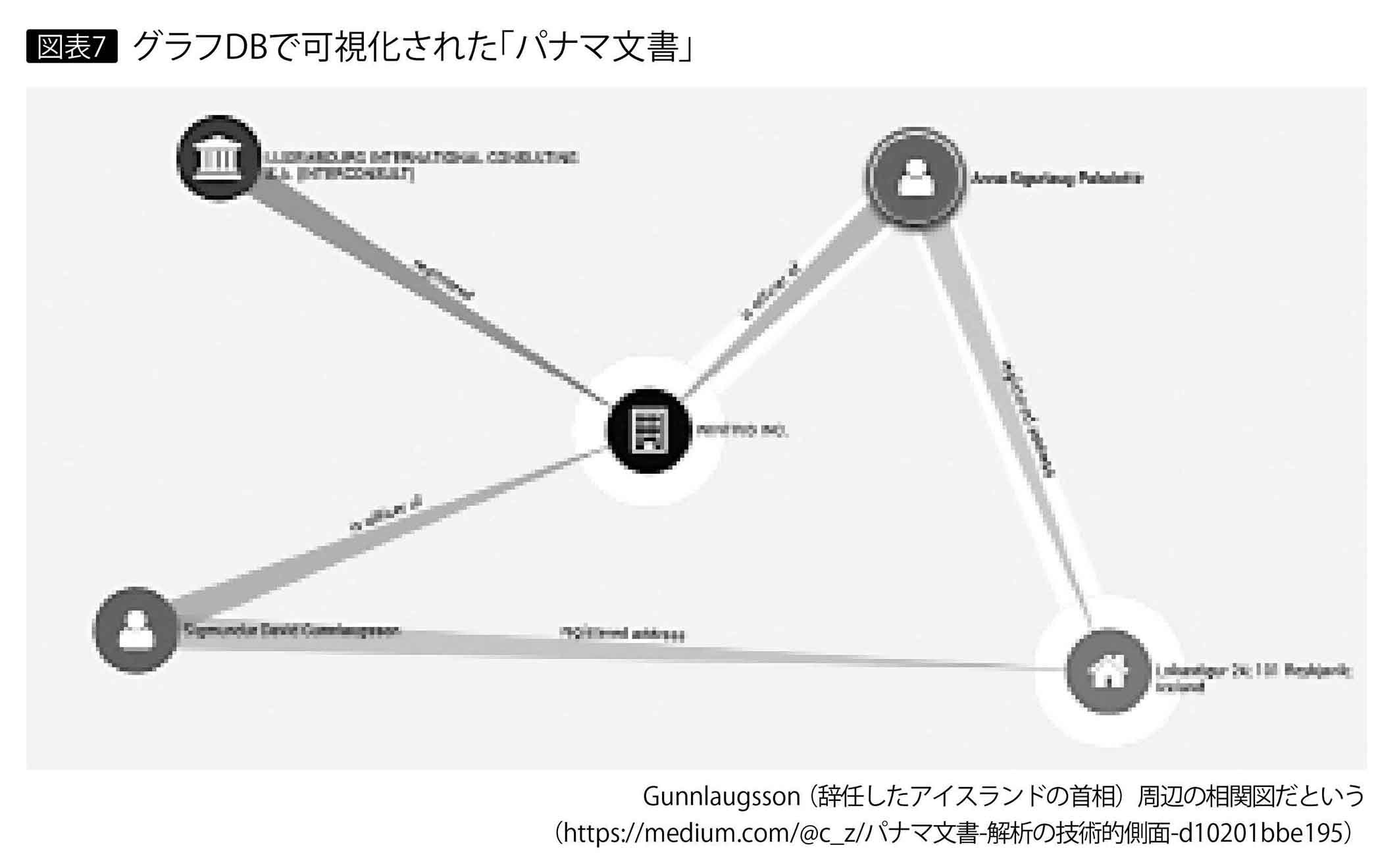
グラフDBの事例で有名なのは、「パナマ文書の可視化」だろう。パナマの法律事務所から流出した2.6TBにもおよぶ膨大な内部文書で暴露された不正な送金や隠し資産を可視化するのに、国際調査報道ジャーナリスト連合(ICIJ)などが分析し、2016年4月に結果を公表した(図表7)。グラフDBとしてNeo4j、可視化ツールとしてLinkriousを採用しており、今も人名や組織名などのキーワードにより関係性をグラフで閲覧できる(*1)。
このほか興味深い事例として、ツール・ド・フランスのチームとステージごとの関連、サッカーのFIFAワールドカップの戦績やパス成功率など、スポーツの戦績分析にも使われている。つながりのあるデータのアナリティクスとビジュアライゼーションには、もってこいのツールである。
ソリューションとクエリー環境
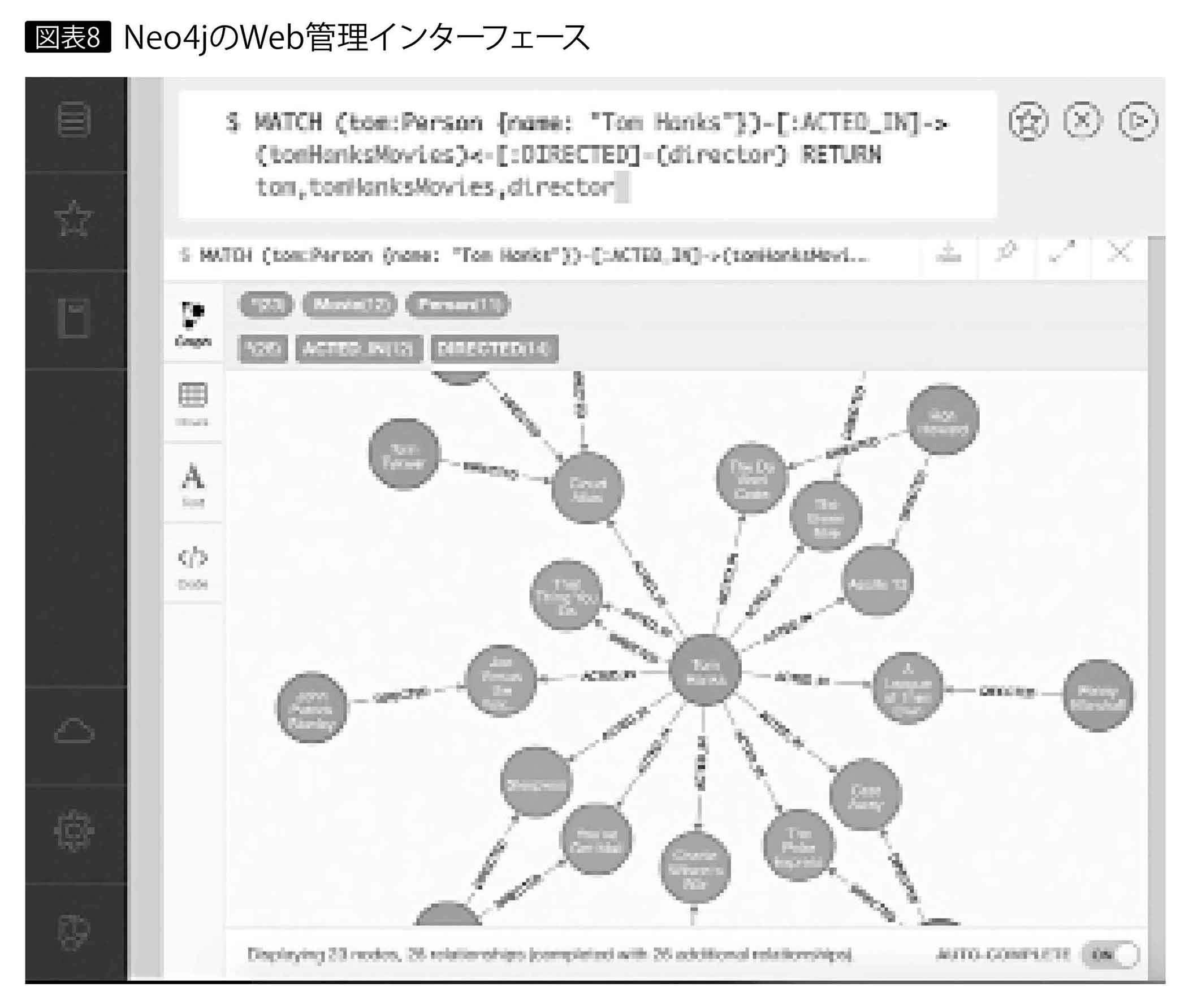
ベンダー製品では、Neo Technology社のNeo4j(*2)が圧倒的なシェアを占める。検索結果がグラフ描画や表、JSONでインタラクティブに表示されるWebの管理ユーザーインターフェースも付属していて使いやすい(図表8)。
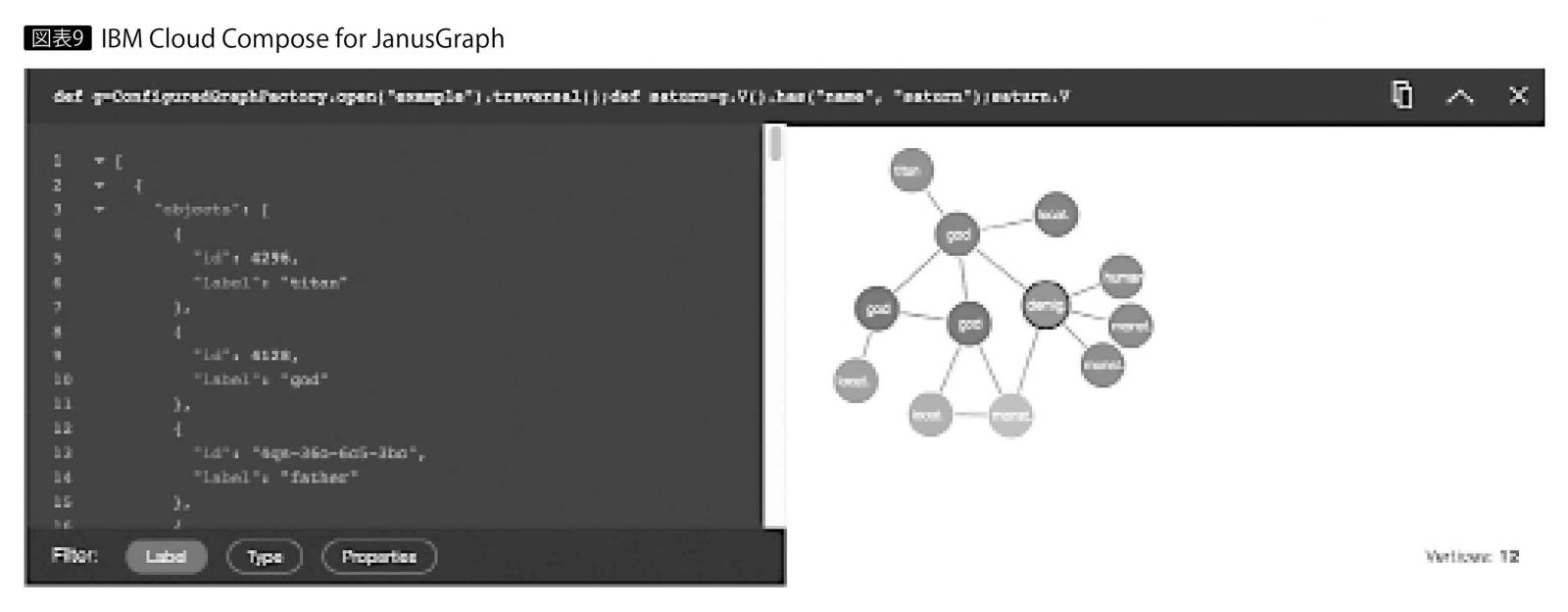
IBMのソリューションでは、オープンソースのJanusGraphを使える「IBM Cloud Compose for JanusGraph」がIBM Cloud上で提供されている(*3)。コンソール上でのクエリー発行やJSONレスポンスの確認、グラフ描画にも対応しているが、現時点(2018年8時点)ではベータ版での提供である(図表9)。登録するデータのつながりの深さで、課金体系が設けられている。
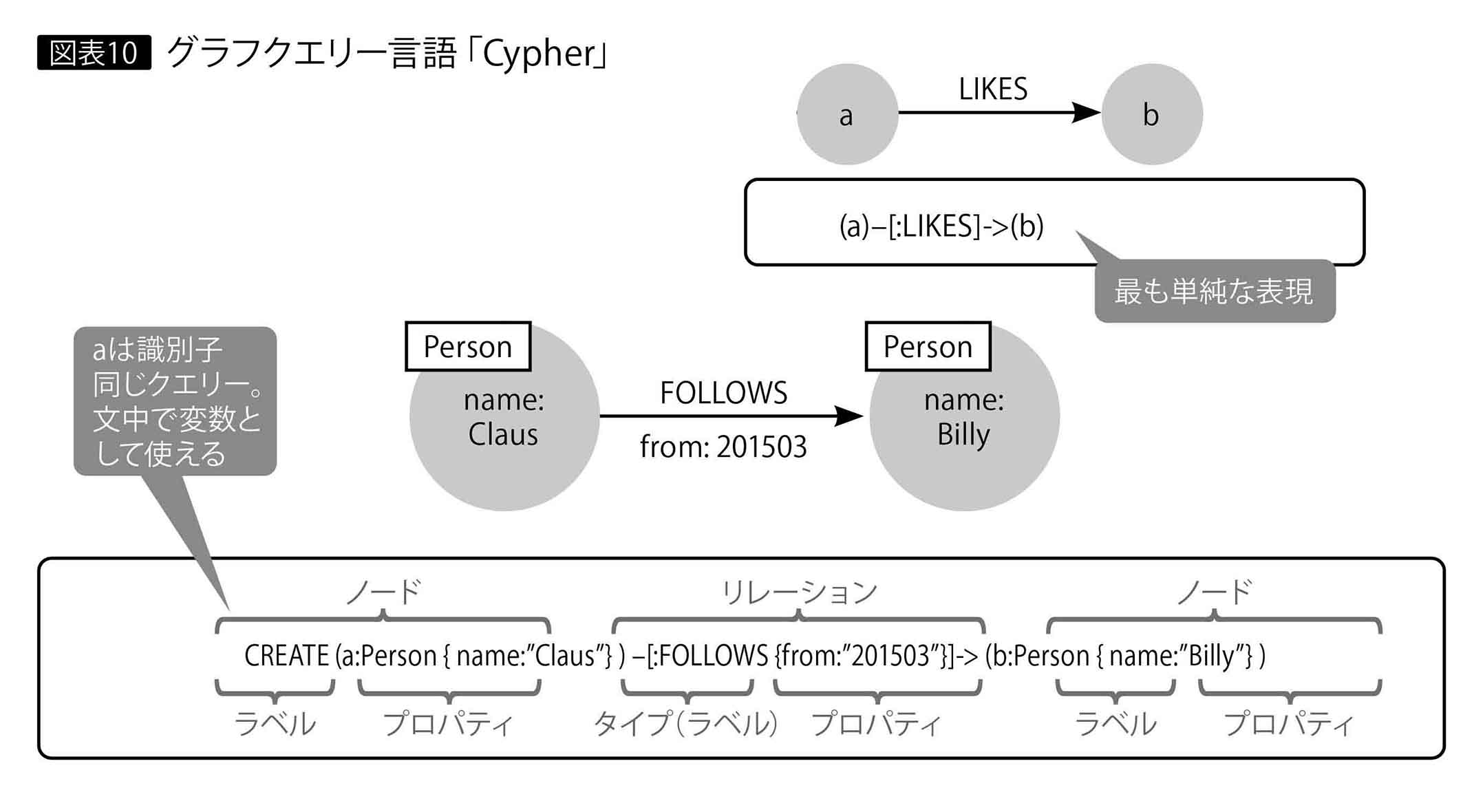
Neo4jでグラフ構造のデータ処理を行う場合は、CypherというSQLライクなクエリー言語を用いる(図表10)。ホワイトボードに書いたネットワーク図をそのまま文字に起こしたようなアスキーアートに似ていて、扱いが容易である。
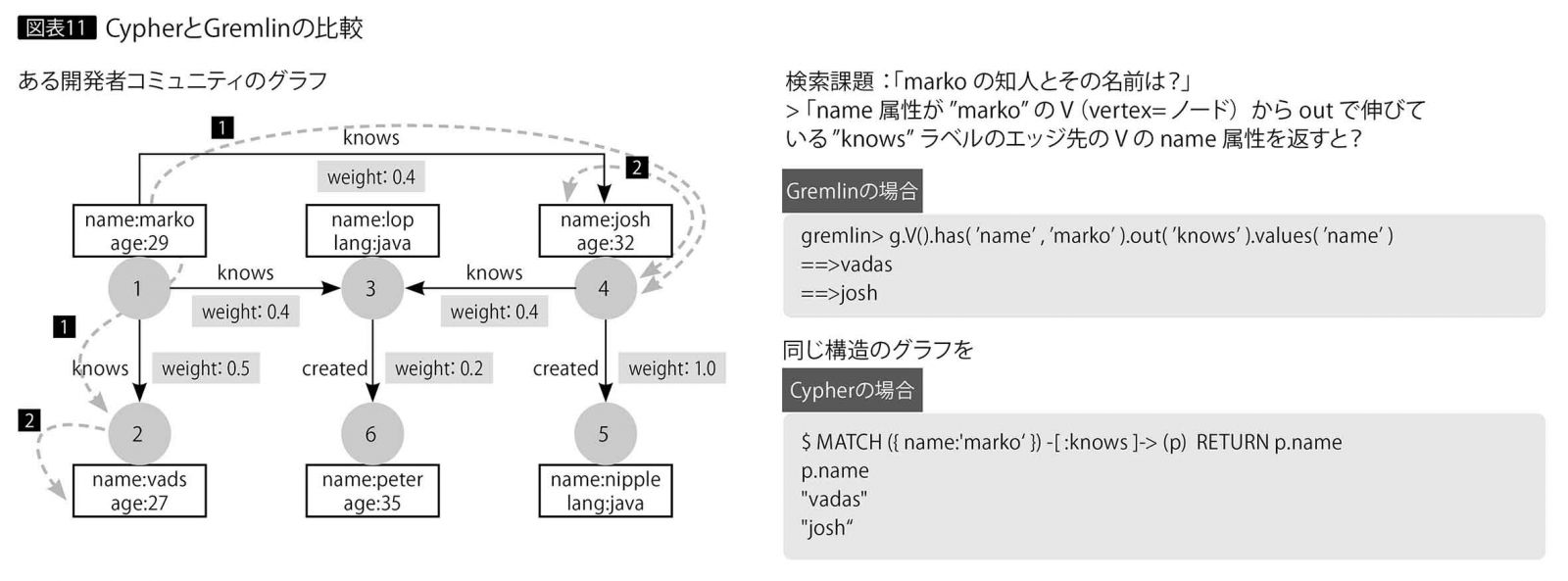
JanusGraphはグラフDBの共通フレームワークを目指すApache TinkerPop(以下、TinkerPop)を採用しており、これに内包されるGremlinというクエリー言語でデータを操作する。TinkerPopは他のグラフDB、たとえばMicrosoftのAzure Cosmos DB、AWSで利用できるAmazon Neptuneでも採用されている(Neo4jもGremlinでデータ操作可能である)。図表11は、開発者とソフトウェアの関係を表した小さなグラフに対する検索をCypherとGremlinで比較した例である。
上記の活用例で紹介した最短経路検索などのグラフ理論のアルゴリズムは、CypherでもGremlinでもパターン構文として盛り込まれているので、複雑な構文を書かなくても計算できる。TinkerPopのドキュメント(*4)は、Gremlinのキャラクターがあちこちに出現する楽しい読み物となっている。
Neo4j もオープンソースであり、GPLv3 の下でライセンスされるCommunity Edition(無償)もあるが、AGPLv3 の下でライセンスされるEnter prise Edition(有償)もあり、クラスタなどの拡張性やサポートを望むなら、こちらを選択したほうがよい。
グラフDBを学ぶには、日本語で書かれた書籍が数種出ている(例:オライリー社の『グラフデータベース』)(*5)。
Neo4jやCypherはブログなどの紹介記事、グラフモデル事例の紹介が豊富であり、英語版であれば書籍や説明動画も多い。Gremlinは公式ドキュメントやスライドシェアの情報が充実している。Neo4jやTinkerPopの無償バージョンをダウンロードして、サンプルデータを操作するチュートリアルで学ぶのが近道だろう。
AI時代の活用法「ナレッジグラフ」
ガートナーが発表した「先進テクノロジーのハイプ・サイクル」(2018年度版)によれば、エコシステムのデジタル化基盤として、「ナレッジグラフ」が黎明期のステージに登場している。ガートナーは、「ナレッジグラフは行と列のテーブルではなく、ノードとエッジのネットワーク(グラフ)に配置されたデータとして情報(知識)をエンコードする」「AIテクノロジーを使用して洞察を提供する際のコンテンツとコンテキストの役割の高まりからのニーズがあり、自然言語処理の分析結果の格納先などとして期待される」と説明している。
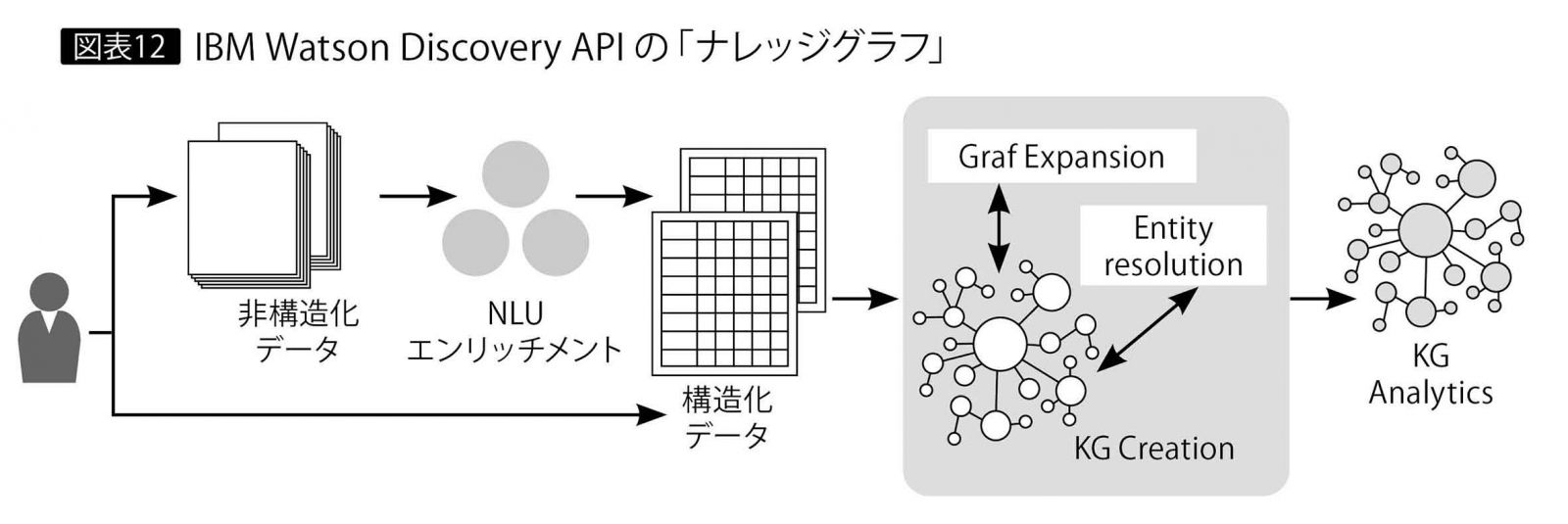
IBM WatsonのDiscovery APIでも自然言語処理の分析結果のデータを、バックエンドにあるグラフ構造「Knowledge Graph」に格納して活用しており、こうした利用形態の1つと言える(図表12)。
グラフ構造となった知識データをAIシステムが適切な回答へ導くのに用いる方法は、1980年代の第2次AIブームでもさまざまに試行されたが、データメンテナンスなどのリソース問題でいったんは廃れた。しかしビッグデータや柔軟な設計に対応するグラフDBは、現代のAIシステムのデータリポジトリとしての機能を期待でき、今後は多様な利用形態が試されるだろう。いわば、古くて新しいテクノロジーとしての再チャレンジである。グラフ界隈は今後も注目すべきテクノロジーである。
関連記事◎人気記事の著者に聞く|グラフデータベースは、ほかに代わるものがない(2021年2月掲載)
・・・・・・・・
参考
*1 https://offshoreleaks.icij.org/
*3 https://www.ibm.com/cloud/compose/janusgraph
*4 http://tinkerpop.apache.org/docs/current/reference/
*5 https://www.oreilly.co.jp/books/9784873117140/
・・・・・・・・
著者
岡本 茂久
日本アイ・ビー・エム システムズ・エンジニアリング株式会社
第2ワトソン・ソリューション
アドバイザリーITスペシャリスト
1997年、日本IBMに入社、2005年から日本アイ・ビー・エム システムズ・エンジニアリングに出向。エンタープライズ・コラボレーションのミドルウェア、ECソリューションのエンジニアを担当。現在はWatson関連のプロジェクトで設計・開発に従事しながら、グラフデータベースやAR/VRにも興味範囲を伸ばしている。

[IS magazine No.21(2018年9月)掲載]