TEXT=山田 敦 日本IBM
DXにおける日本の立ち位置
DXが企業の競争力を強化すると言われて久しいが、日本のDXの状況は世界各国と比べてどうなのか。
2021年のIMD世界デジタル競争力ランキングによると、日本は28位と残念ながら決してデジタル先進国とは呼べない状況である(World Digital Competitiveness Ranking 2021, IMD)。
勝機はあるのか
研究や特許ではもはや挽回は困難な状況かもしれないが、「活用」において、まだ勝機は残されていると信じる。
つまりあらゆる業務や商品でAIが使われ、業務を圧倒的に効率化したり、商品を差別化する状況にいかにスピーディにもっていけるかだ。
3~4年前までは、日本企業の多くは正直、DXに対して「様子見」であった。しかし2020年から2021年の間に、主だった企業がDX部門を設立し、DXのスイッチを入れた。つまり「やる」と腹をくくったのである。デジタル庁の設置も、その1つの象徴と言えるだろう。
日本企業が歩むべき道筋
データとAIの活用は、やみくもに進めてもうまくいかない。よく見る失敗するケースは、全社データ基盤の整備、AIの実証実験、デジタル人材育成の研修整備を単独で走らせるケースだ。
これらは互いに密接に関連しており、どれか1つだけを一気に進めればよいというものではない。研修を終えたら、すぐリアルなAIプロジェクトに配属され腕を磨き、作ったデータ基盤が使われ、その規模が拡大していくというように、人材、AIプロジェクト、データを反復的に拡大していく仕掛けが必要である。
データとAIを企業全体に拡大していくための枠組みを図表1に示す。
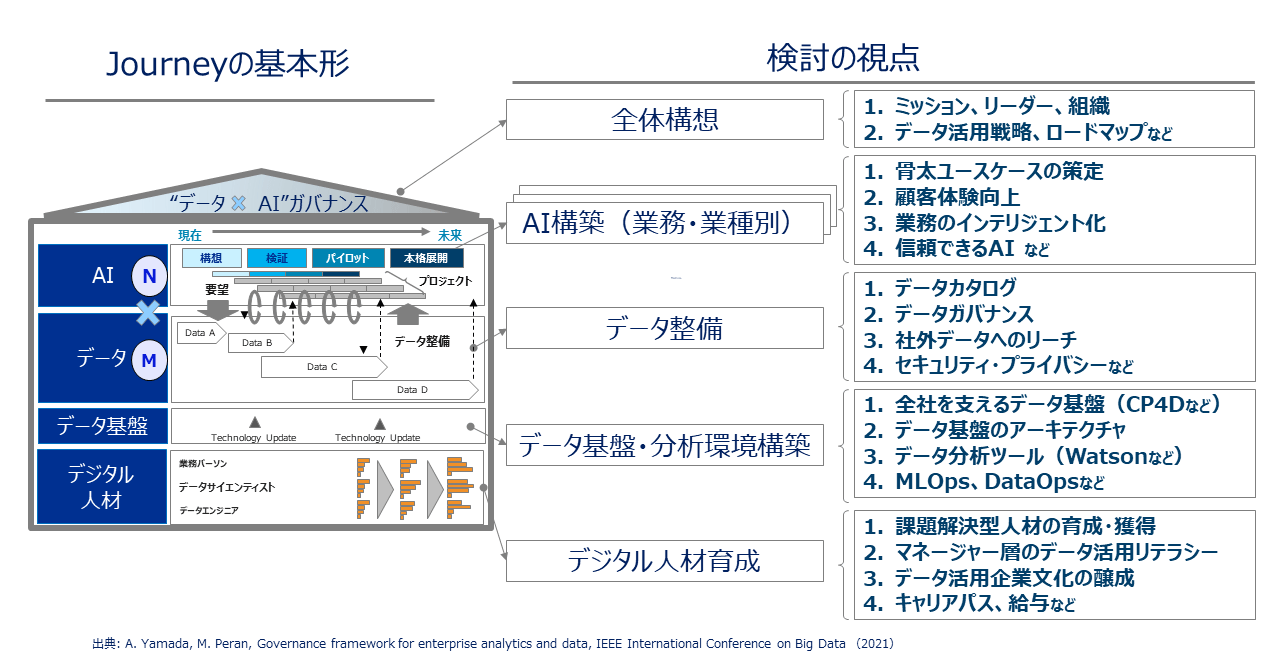
これは私が10年近く企業のデータ活用を支援してきた経験を基に、成功パターンを模試化したものであり、Journeyの基本形と呼んでいる(“Governance Framework for Enterprise Analytics and Data”,IEEE International Conference on Big Data, 2017)。
4+1層で構成されるJourneyの基本形
この基本形を個別の企業の事情に合わせてカスタマイズすることにより、データ活用を加速できる。
もう少し詳しく見ていくと、Journeyの基本形は、図表の左側にあるように4+1層で構成される。
「AI層」はAIを活用した価値創出活動を、「データ層」は企業が持つデータ整備を、「データ基盤層」はデータを入れる器の整備を、「デジタル人材層」はデータ活用を推進する人材の育成を表している。
そして4+1層の1に相当するのが“データ×AI”層で、4つの層がバラバラに推進されることがないように整合させる層である。
各層で検討すべき視点
一方、図表の右側には各層の活動を進める上で検討すべき視点を列挙した。
AI層:検討の視点
まずAI層における骨太ユースケースとは、経営インパクトに直結するユースケースを意味する。現場改善の小粒ユースケースを決して否定はしないが、それらの積み上げでは大きく会社を変革するのに時間がかかる。
IBMが実施した骨太ユースケースの1例が、「売上を最大化するために、全世界の営業員をどう最適配置すればよいか」というものである。
社長からこの課題解決を任された当時のChief Analytics Officerは、この問題をサブ問題に分解し、1つ1つ解決していき、経営に大きなインパクトを与えた。
またAI層においては、顧客体験の向上や業務のインテリジェント化に貢献するユースケースを意識してユースケース選定するとよい。AIの運用開始後、AIの性能を信頼できる状態に維持管理する仕掛けについても検討が必要である。
データ層:検討の視点
2番目のデータ層では、まずデータカタログ。これは、データ利用者とデータ整備者との間のコミュニケーションインターフェースとなる重要な機能である。
「こういうデータはある?」という利用者の要望を集め、投資効果の高いデータから段階的に拡充していくための要となる。
安全かつ快適にデータを活用できるように、データガバナンスの一環としてデータ活用のルールを整備していく。とりわけ、セキュリティとプライバシーに関するルール整備は、安全なデータ活用のために欠かすことができない。
また社内データに留まらず、社外データにまで範囲を拡大していくことで、データ活用のユースケースはさらに増えていく。
データ基盤層:検討の視点
3番目のデータ基盤層では、データを入れる器としてのデータ基盤、またデータ分析環境を整備していく。
全社で長期に渡り使えるデータ基盤にするには、複数社のクラウドやオンプレのどの計算環境でも稼働できるテクノロジーの選択が重要となる。
そしてデータの発生源である既存基幹システムとの関係をデータ基盤のアーキテクチャとして設計する。データのコピーを増幅させないために、Data Fabricと呼ばれるデータ仮想化技術の選択も、柔軟性の高いアーキテクチャを作るために有益であろう。
データ分析ツールと併せて、MLOps、DataOpsと呼ばれるAI、データの運用を効率化するテクノロジーの検討もお勧めしたい。
デジタル人材層:検討の視点
4番目はデジタル人材層であるが、世の中に圧倒的に不足している人材が「課題解決型人材」、つまり問題を自ら発掘し、その解決アプローチを設計できる人材である。
世の中には、Python講座、機械学習講座といった知識やスキルを学ぶ研修は豊富にあるが、それを受講するだけでは課題解決型人材は育たない。
顧客の声を聞いて整理し、AIの知識を駆使して解決アプローチを提案し、顧客を納得させる実体験を、トレーニングと実践を通して積む必要がある。
またマネージャー層のデータ活用リテラシーが低い会社では、実務者がいかに優れたAIモデルを開発しても、部門の仕事として採用されず、お蔵入りするケースを数多く見てきた。
マネージャー層に必要なことは、担当部門でのデータ活用を、「自分事」として推進するマインドセットである。そのためには、必要最低限のデータとAIのリテラシーを身につけた上で、若手の力を信じて自部門でのデータ活用を宣言することが大切である。
実務者であれマネージャーであれ、研修で習っただけで使わないと3日で忘れる。学びを使ってリアルな業務で実践し、その成果を披露する。そういうサイクルを回せる仕掛けを企業の中に構築していくことで、データ活用の企業文化が醸成されていく。
またせっかく育てたDX人材が、会社を去っていくという話をよく耳にする。育てた人材が、社内で自身の未来を描けるように、キャリアパスや競争力のある給与体系が求められる。
“データ×AI”ガバナンス層 :検討の視点
最後に“データ×AI”ガバナンス層は、これまで述べた4つの層がバラバラにならず、互いに連携して反復的に拡大するように統括する層である。
ユースケースのパイプラインを把握し優先順位づけし、その推進のために足りないデータと人材を把握し、ユースケースの推進が滞りなく流れるように各層のリーダーと連携して課題解決にあたる。
これまで4+1層に整理して検討の視点を述べてきたが、どこから着手していけばよいのか。それには一番遅れている層を特定し、そこにテコ入れしていくことを薦める。
冒頭に述べたように、この4層は反復的に拡大していくものであり、どれか1つの層が停滞すると、DXの活動全体がペースダウンする。
3つの技術で壁を突破する
データとAIを全社で活用するための全体的仕組みに加えて、筆者が注力するゲームチェンジャーとなり得る重要技術を3つ、簡単に紹介しておく。
Federated Learning
1つめはFederated Learning、連合学習とも呼ばれる。
これはデータそのものを他社と共有はせずに、AIのモデルに相当する情報を他社と共有することで、1社ではデータ不足で作れない高性能なAIモデルを、複数社が連合して作成する技術である。
AIはデータがないと無力である。しかしデジタルジャイアントのような巨大なデータを自社で保有している企業は、日本にはほとんどない。
このデータの壁を突破する技術がFederated Learningである。日本企業が連合を組むことで、海外のデジタル先進企業と戦うことを可能にする技術である。
Intelligent Data Fabric
2つ目はIntelligent Data Fabricで、データ基盤に関わる技術である。
これまでのデータ基盤の主流は、データ発生源からデータをコピーし、蓄えるアプローチが主流であった。このアプローチは、多大な時間と投資を伴う。
一方で、AIモデルを構築する活動は試行錯誤を繰り返す必要があり、従来のアプローチでは時間軸が合わない。
Intelligent Data Fabricは、データ仮想化技術を使うことで、データのコピーを最小限に抑えてAIモデル構築活動のニーズにスピーディに応えることができる。
AIを本格運用すると決めた段階で、要件に合致した必要なデータコピーのロジックを構築すればよい。
AI品質を高める仕組み
3つ目は、AI品質を高める仕組みである。
AIの予測性能は、時間と共に劣化する。また近年は、予測結果に含まれる人種性別等のバイアスが社会問題を引き起こす事例も報告されている。
AIの開発・運用の各工程に、AIの品質を定めて測定し改善する仕組みを構築し、AI品質を高めていくことが求められる。
日本IBMでは産業技術総合研究所が主となり開発した「機械学習品質マネジメントガイドライン」を活用して、お客様が開発するAIモデルの品質向上を支援する活動を推進している(安心して使えるAI構築を支援する「IBM ML品質診断サービス」を発表― AIの安全性や有用性、公平性を診断し、課題や改善策を提示―,2021 )。
「日本企業がリリースするAIは、とにかく品質がよい」という方向に導いて行きたいと思う。
データとAIで日本企業を再び世界で輝かせる
データとAIについて、日本は敗戦国だとはまだ思っておらず、「活用」に活路はまだ残されている。その活路を切り開いていくのが、企業のDXリーダーの仕事である。
データとAIを駆使して日本企業を再び世界で輝かせるために、DXリーダーの活動を、全力でサポートし、そして次の世代にバトンを渡していきたい。
著者|
山田 敦氏
日本アイ・ビー・エム株式会社
IBM AIセンター長
データサイエンティスト職リーダー
技術理事
1995年、日本IBMに入社。東京基礎研究所にて、主に3次元形状処理の研究に貢献。2008年にコンサルティング部門に異動後、2009年に新設された「先進的アナリティクスと最適化」チームのリーダーを務める。併せてデータサイエンティストとして、製造業、流通業、保険業を始めとした多くの企業に対して、データとアナリティクスを活用した業務変革を支援。 2017年よりIBM技術理事。社内では、データサイエンティスト職のリーダーを務める。2019年より現職。IBM Academy of Technologyメンバ ー、工学博士。