IBMは5月11日(現地時間)、IBM Cloud Pak for Dataの新バージョンを発表した。データの発見・収集の範囲を大きく拡大し、データ活用のための各種手続きを自動化する機能を搭載したバージョンで、IBMは「次世代のIBM Cloud Pak for Data」とアピールしている。
IBM Cloud Pak for Dataは、2018年にリリースされたデータ活用のための基盤。データの収集から編成(加工など)、分析(モデル構築など)、組込(AIモデルへの適用など)までの一連の機能を網羅的に備える。
IBMの最近の調査(Global AI Adoption Index 2021)によると、AIを活用するデータ駆動型の組織は高い確率で売上・収益性を伸ばしている半面、データが企業システム上のさまざまな場所に分散し、かつそれぞれがサイロ化しているために、AIをうまく活用できないユーザーが多数存在しているという。
今回発表されたIBM Cloud Pak for Dataは、データ活用に伴う複雑さや煩雑さを克服するためのソリューションで、「AutoSQL」「AutoCatalog」「AutoPrivacy」「AutoAI」という4つの機能が追加された。また、これら4つの機能をインテリジェントに統合する「データ・ファブリック」が新規に導入された。データファブリックはAIを搭載し、複雑なデータ管理タスクを自動化し、複数の環境にまたがるデータを発見、統合、カタログ化、保護、管理する機能を提供するという。
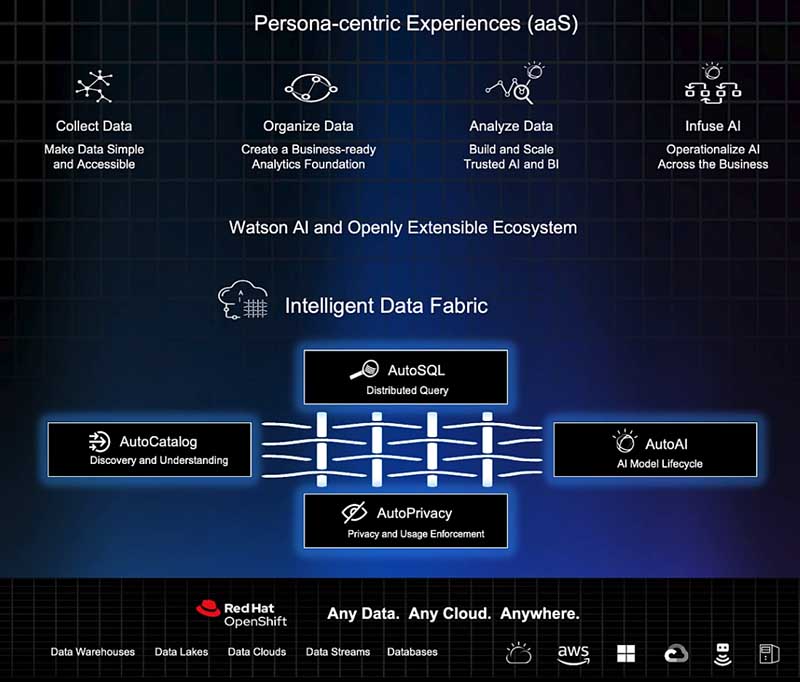
AutoSQLは、オンプレミスやクラウドのさまざまな場所に分散している多様な形式のデータを発見・収集・蓄積するための機能で、クエリの最適化とチューニングを自動で行う機能により、異種のデータソースを共通のデータ基盤に容易に一元化できる。クエリエンジンは、Db2やDb2 Big SQLなどの複数のSQLエンジン機能を集約したもので、IBMは「ユニバーサル・クエリ・エンジン」と称している。AutoSQLにより、IBM Cloud Pak for Dataの適用範囲は大きく広がったと言える。
AutoCatalogは、AutoSQLが収集・蓄積したデータをカタログ化し、ビジネスに役立つデータを提供する機能、AutoPrivacyはより安全なデータ活用のためのポリシー機能で、リスクの低減を可能にする。AutoAIは、AIアプリケーションのためのモデルを構築しデプロイするための機能で、幅広いスキルセットが提供されるという。
・新着の製品カタログ「IBM Cloud Pak for Data」
・紹介ビデオ「The next generation data and AI platform」(英語)
[i Magazine・IS magazine]