Text=植田 佳明、水谷 好伸(日本アイ・ビー・エム システムズ・エンジニアリング)
今やAIやデータサイエンスの話題は、ChatGPTの登場もあり、IT業界だけではなく日常会話でも頻繁に登場する状況になっている。その一方、社会全般でAIを活用したオートメーションが進んでいるのかと言えば、自動運転などの特定分野を除けば、まだあまり実生活上、体感するほどには進んでいないのではないだろうか。
筆者らはデータサイエンティストとして、さまざまなデータ分析やAI実装のプロジェクトに参加しているが、そこで多くの場合にぶち当たる壁がある。それは「PoCの壁」とも言えるものだ。AIやデータ活用に関しては多くのユーザーが前向きで、PoCの形でプロジェクトを始めるが、そこで作成したAIや機械学習モデルを実際の業務プロセスに活用しようとすると、まったく進まないという問題である。
本稿では、PoCの壁問題の原因の特定と、それに対処するための提言を試みたいと思う。
データサイエンス/AIのビジネス適用の現状
ここにショッキングな事実がある。MIT Sloan(MITビジネススクール)の調査によると、AI投資を進めている企業のうち、投資利益が出ているのがたった10%という結果である(EXPANDING AI’S IMPACT WITH ORGANIZATIONAL LEARNING)。
ほかにもマッキンゼーの調査で、AIオートメーションのプロジェクトでの成功率が15%という結果もある(Operationalizing machine learning in processes)。
上記は主に経営層向けの調査であるが、技術者を中心としたアンケートでも、自らが実装したモデルが実際に業務適用された割合は0~20%に過ぎないとの回答が最も多くなっている(全体の58%)(Models Are Rarely Deployed: An Industry-wide Failure in Machine Learning Leadership)。
この業務適用に至らないという問題はここ数年、データ活用の試みが進むにつれて明らかになってきたもので、日本でも「社会実装」というキーワードを用いた提言などが見られる(機械学習を「社会実装」するということ)。
以上の調査に共通して見られる問題点は、「作ったAIや機械学習モデルが業務に使われない」という問題であり、現実には「モデルを作成するPoCフェーズで終わってしまう」という形で健在化することが多い。
そこで以下に、架空のデータ分析プロジェクトを取り上げて、PoCフェーズで終わってしまう原因とそれへの対処として何が考えられるかを見ていきたい。
とあるPoC分析プロジェクト
経験上、PoCから先に進まない分析プロジェクトは、概ね同じような流れを辿る。その典型例として以下の架空プロジェクトを想定し、そのプロセスを追ってみる。
プロジェクト名:CBM移行プロジェクト
◎業種
製造業
◎ビジネス的な狙い
ある工場にて機械のメンテナンス方針を従来のTBM(定期保全)からCBM(状態保全)へ移行したいと考えている。そのために機械の稼働状況(温度、電力等)から故障発生の有無を機械学習モデルによって予測し、故障の危険性がある機械のみをメンテナンスする仕組みを確立し、コスト削減につなげたい。
◎対象業務内容
週1回、特定曜日にメンテナンスを実施。
TBM:全機械を対象にメンテナンス
CBM:モデルが7日以内に故障すると予測したものを対象にメンテナンス
◎体制
ユーザー(事業部門責任者)、データサイエンティスト
この分析プロジェクトの計画段階から最後の業務適用検討段階までを、ユーザーとデータサイエンティストの間で起こりがちなやり取りを含めて再現してみよう。
① 計画段階
ユーザーからのヒアリングをもとに、分析目標とアプローチを策定する。
ユーザー
「当社の生産ラインで使っている機械は、古いものも新しいものもすべて定期メンテナンス(TBM)の対象としていますが、コストがかかり過ぎるという問題があります。これを、データ分析を用いて近々故障しそうな機械のみを選び出してメンテナンスする方式(CBM)に変更し、コストカットを図りたいと考えています」
データサイエンティスト
「それでは故障予測モデルを作成して、業務適用可能な精度が出るかを確認しましょう。データには機械のセンサーデータを使いましょう」
② 分析ゴールの設定
計画段階で、分析目標として「業務適用可能な精度のモデルを作ること」と定義されているため、具体的なゴール設定として、その精度目標を決めることになる。
データサイエンティスト
「モデルの精度はどの程度を目標としましょうか。故障を予測する分類問題のモデルなので、再現率と適合率それぞれで決めておきましょう」
ユーザー
「現場の責任者に確認しましたが、肌感覚的にはだいたい再現率、適合率ともに80%を超えていないと難しいのでは、ということでした。そこを目標としましょう」
③ モデル作成
モデル作成における精度改善は、データサイエンティストの腕の見せ所である。データサイエンティストは精度を向上することに全力を傾ける。
データサイエンティスト
「さまざまなデータ加工を工夫して初期モデルを作った。まずは精度70%だ。ここから先、80%まで向上させなければ」
「特徴量を追加したものの、だんだん精度は上がりづらくなってきている。なかなか80%までは到達しないが、何とか達成するための手段を講じよう」
④ モデル精度の評価
めでたくモデルの精度が目標を達成した場合、PoCとしては成功となる。
データサイエンティスト
「精度は再現率80%、適合率80%を達成しました!」
ユーザー
「素晴らしいですね。分析の組み立てや進め方もとても勉強になり、価値のある活動になりました」
⑤ 業務適用検討
ところが現実的に業務で使うことを考えたときに、本当にそのモデルを使って大丈夫か、という不安が出てくる。結局ここで頓挫して、PoCから先に進めなくなってしまった。
ユーザー
「この80%という精度って本当に高いのでしょうか。20%は間違えるわけですよね。今の定期保全の仕組みだとさすがに20%も間違えないと思うし、実際に使うとなると不安で使えないです」
データサイエンティスト
「(心の声)80%でよいって言いましたよね。じゃあ何%なら使えるの?」
こうして分析プロジェクトは、ゴールとして設定した目標精度は達成したものの、結局PoCから先に進められない形で終了を迎えることになった。ユーザーとは密に話を進めていたはずなのに、なぜこんなことが起こってしまったのだろうか。
CRISP-DMでPoCプロジェクトを見てみると
このようなCBM移行プロジェクトのように、PoCフェーズで精度がよいモデルが作成できたとしても、そこで終わってしまうというパターンは本当に多い。その原因を探るために、先ほどのプロジェクト例をCRISP-DMのフレームワークに当てはめ、あらためて整理してみる。
まずはCRISP-DMのおさらいをしておく。CRISP-DMはデータ分析のプロセスを「ビジネスの理解」から「展開」までの6つのステップに分け(CRISP-DMヘルプの概要)、この6ステップについて順を追って進めるのではなく、アジャイル的にステップ間を行きつ戻りつしつつ進めることを想定している。
ここで、先ほどのCBM移行プロジェクトをCRISP-DMで表現してみよう。

注目したいのは、「ビジネスの理解」の部分である。CRISP-DMではビジネスの理解として、以下の実施項目を挙げている(ビジネスの理解 ※一部文言修正)。
・ビジネス目標の確認
・状況の評価
・分析目標の決定
・プロジェクト計画の作成
・次のステップの準備
特に大切なのは、「ビジネス目標の確認」と「分析目標の決定」である。この2つの関係を考えてみると、
「ビジネス目標:TBMからCBMへの移行」→「分析目標:CBMで必要な予測モデル精度80%」
の順で決定され、現状、PoCでも必ず実施されている。ただし、ここで1つ問題として提起したいのは、逆の矢印は必ず成り立つのだろうか、ということだ。
「分析目標:CBMで必要な予測モデル精度80%」の達成 → 「ビジネス目標:TBMからCBMへの移行」の達成
答えはもちろん「No」であり、実際にTBMからCBMへ移行するには、精度のよいモデルを作るだけでは不十分なのは明らかである。
では、このモデル以外の要素はいつ、誰が考えるのだろうか。この問題に対しての大半のデータサイエンティストはおそらく、「評価フェーズ(業務適用フェーズ)で業務ユーザーが考える」と答えることだろう。この回答について考えてみる。
モデルの業務適用について
今回の例でのモデルの業務適用とは、「故障予測モデルを使ってCBM運用を行うこと」である。実際に故障予測モデルを使った運用を構築するには、さまざまな考慮点がある。
たとえば、どのくらいの故障確率だったら修理対象とすべきなのか。ユーザーが「肌感覚」で決められるものなのか。故障予測モデルを実行する頻度はどれくらいが適切なのか。今までの定期実行のタイミングで実施すべきものなのか。予測が外れた場合はどうすればよいのか。故障発生から修理までのダウンタイムの時間は許容できるものなのか。これを細部に渡るまで「評価フェーズ(業務適用フェーズ)で業務ユーザーが考える」ことは現実的だろうか。
これらの問題は、業務ユーザーだけでもデータサイエンティストだけでも決められるものではなく、やはり両者で議論しながら作り上げていくべきものであろう。ただし現状、こういったことがデータ分析プロジェクトの現場で語られることは滅多にない。
PoCフェーズから進まない大きな原因は、ここにあると我々は考えている。つまり、「作ったモデルを本気で業務適用することを誰も考えていない」という点である。
PoCプロジェクトでの業務プロセス設計
そこで本稿では、PoCプロジェクトの初期段階でモデル適用時の業務プロセス設計を行うことを提案する。CRISP-DMに当てはめると、「ビジネスの理解」フェーズでのビジネス目標の確認の1つとして行うイメージである。

これを評価フェーズではなく、ビジネスの理解フェーズで行うのにはいくつか理由がある。その中の大きな理由として、モデルをどう業務プロセスに組み込むかによって目標とすべき精度が大きく変わってくる点が挙げられる。
PoCではモデルの目標精度を設定し、それがクリアできたかどうかを定量的な達成基準にすることが多い。しかしそれは、「データサイエンティストの今までの経験」や「業務ユーザーの肌感」という不明瞭な根拠に基づいて決められることも多い。
経験や肌感が必ずしも悪いとは言えないかもしれないが、モデルを本気で活用していくという現実を考えれば、活用後の業務プロセスをきちんと描き、そのプロセスに必要な精度をモデルの目標精度として設定すべきであろう。
たとえば、今回のTBMとCBMの例でも、交換対象の機械のシビアさ(ダウンタイムの許容時間)や故障時のリカバリー体制の有無などによっても、故障予測モデルの目標とすべき精度も変わってくるのは容易に想像できるであろう。
業務プロセス設計の例(CBM移行プロジェクト)
最後にCBM移行プロジェクトの例を使って、実際にモデル適用後の業務プロセスを描き、実際に適用する場合に、プロセス設計上、問題になりそうな点を考えてみたい。
CBMの場合、メンテナンス業務の起点となるのは、モデル実行による故障機械の予測からである。故障すると予測された機械はすべてメンテナンス対象となり、故障しないと予測されたものに対するアクションは何も行われない。
ただし故障しないと予測された場合には、100%の精度の予測モデルを作れない以上、必ず予測の間違いが発生し、故障する機械が出てくることになる。以上を単純化すると、以下の図表のようになる
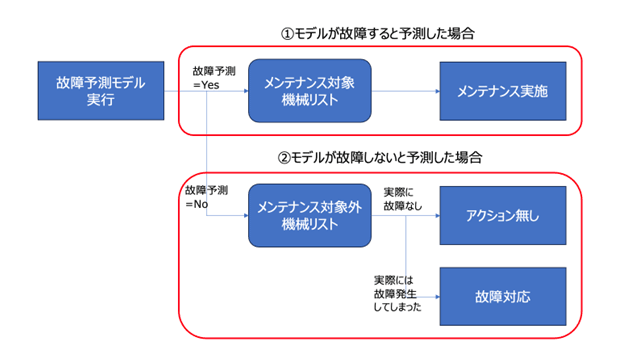
プロセスの大きな流れとしては、「①モデルが故障すると予測した場合」と「②モデルが故障しないと予測した場合」の2つがある。
このうち①に関しては、故障予測=Yesの定義(分類モデルの閾値設定)をどうするかなどのモデル設計上、考えるべき点はあるが、業務プロセスとしては、リストされた機械をメンテナンスするというだけなので、特に不明確な点はないであろう。
問題は②で、こちらの場合は、故障=Noと予測されたにもかかわらず、故障する機械が発生し、それに対して実際に現場としてどうするか、ということが大きな問題となる。
TBMの場合に、もし故障発生時の対応が定義されており、それがそのまま適用できるのであれば、その対応プランをここに適用する可能性も考えられる。一定の許容ダウンタイム時間内での対応が必須なのであれば、故障発生を通知してメンテナンス手配をし、修理するというプロセスを確立する必要があるだろう。
この例からもわかるように、業務適用に当たっては、予測が間違った時のリカバリーをどうするかというのが、最も問題になる部分であり、このリカバリープランを描いておくだけでも、PoCフェーズ後の業務適用検討時のスムーズさは大きく変わってくる。
PoCフェーズでは、業務ユーザー側も適用までのイメージを完全に描くのは難しい場合も多いので、まずは「モデルが間違った時に業務上どういうアクションをするか」から始めるのも、一案であると考えられる。
以上のように、筆者らはデータサイエンティストとしての現場での経験からも、PoCで作ったモデルが業務適用されないという問題は、モデルの精度というよりも、誰も本気で使うことを考えていない(またはどう使っていいかわからない)という点が大きいと痛感している。
それに対し本稿では、以下の2点を提言したい。
1点目は、CRISP-DMの「ビジネスの理解」フェーズで、モデル適用後の業務プロセス設計をすること。2点目はその中において、特にモデル予測が外れた場合のリカバリープランを描いておくこと、である。
これらの提言が少しでも参考になり、データ分析モデルの社会実装に役立ってくれるならば、筆者らにとってこの上なく幸いである。