ここではクラウド型のデータ分析サービスであるWatson Analyticsを紹介する。
IBM iからクラウド上のWatson Analyticsへデータをアップロードし、今までとは異なるデータ分析と
ビジュアライズを実現することで、IBM iのデータ活用を大きくレベルアップする。
菅田丈士 氏
日本アイ・ビー・エム株式会社
Power Systemsテクニカル・セールス
アドバイザリーITスペシャリスト
Watson Analytics を知る
Part 1でも登場したWatson Analyticsは、クラウド型アナリティクス・ツールである。データをクラウド上にアップロードして、ガイドに従って操作すると、簡単にデータ分析を進められる。統計の専門知識をもたなくても、Watson Analyticsがデータの分析とビジュアライズを支援してくれる(図表1)。
【図表1】Watson Analyticsの利用イメージ

Watson Analyticsにアップロードするデータの形式は、基幹業務で多く利用されるテーブル形式のデータである。つまりIBM iに蓄積されているデータは、Watson Analyticsでの分析に非常に適していると言える。
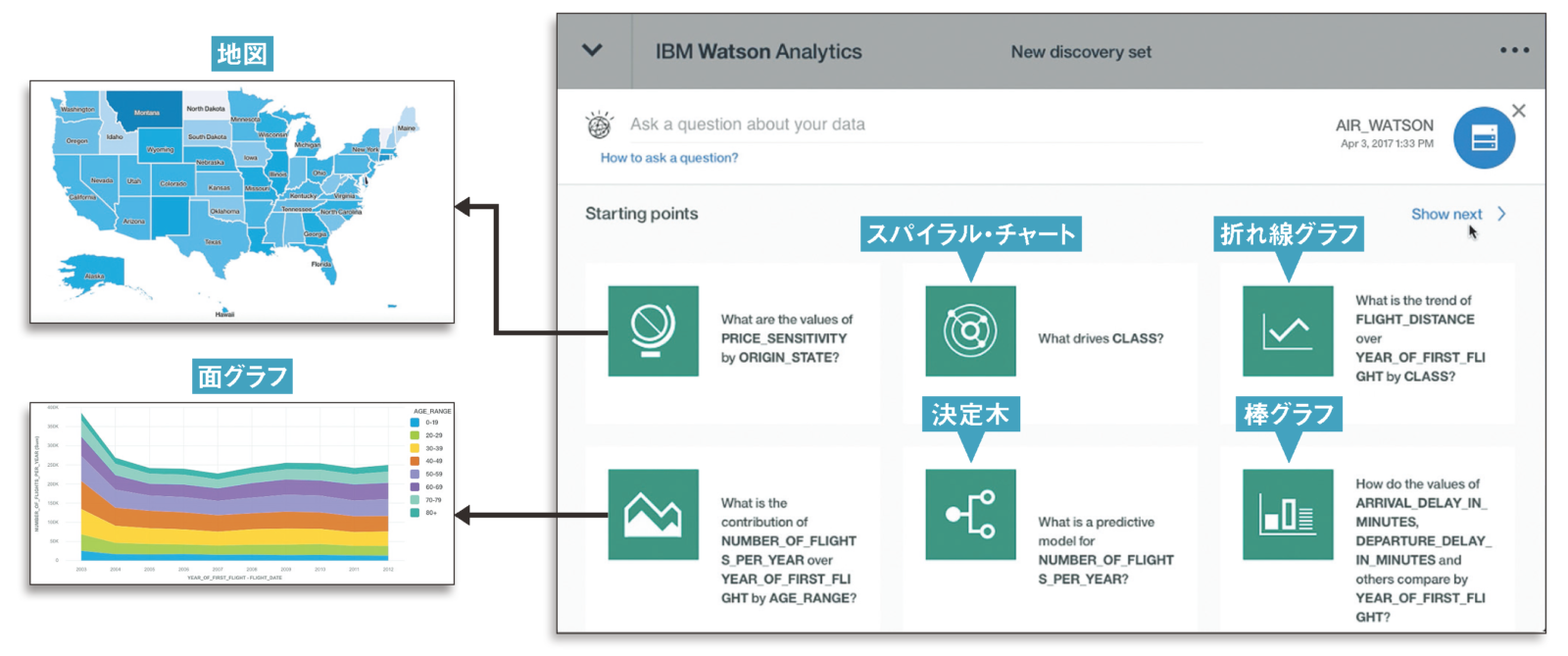
Watson Analyticsにデータをアップロードすると、Watson Analyticsはそのデータから、「こんなことがわかります」というStarting Pointsを表示する。Watson Analyticsは常に、多様なパターンのグラフを用いてビジュアルで結果を表示し、Starting Pointsのアイコンはどのようなビジュアルで表現しているかを示している(図表2)。
【図表2】Starting Pointsと結果表示の例
このようにWatson Analyticsは、コグニティブ技術を使ってデータの意味を理解し、アップロードしたデータに適した分析の切り口と可視化のパターンをリコメンデーションしてくれるわけだ。
Watson Analyticsは最上位のプロフェッショナル・エディションでも、1ユーザーあたり月額1万1100円(税抜)であり、Watsonのテクノロジーを取り入れているサービスのなかでは導入しやすい価格設定である。
またIBM IDがあればプロフェッショナル版を30日間、無料トライアルで試せる(2017年9月時点)。SaaSサービスなので、無料トライアルに申し込めばすぐに試用開始できる。ぜひ試してみてほしい。
なぜIBM iにWatson Analyticsか
IBM iのデータに対応するBIツールは、従来からいろいろと提供されてきた。たとえば、「Db2 Web Query for i」(以下、Web Query)もその1つである。
Watson Analyticsが従来のBIツールと比べて大きく異なるのは、データをアップロードすると、とにかくビジュアライズして、視覚的にデータを見られる点である。そしてビジュアライズされた結果をベースに、ブラウザ上の簡単な操作で軸を入れ替えたり、分析を掘り下げたりといった多角的な視点での分析をスピーディに実現する。
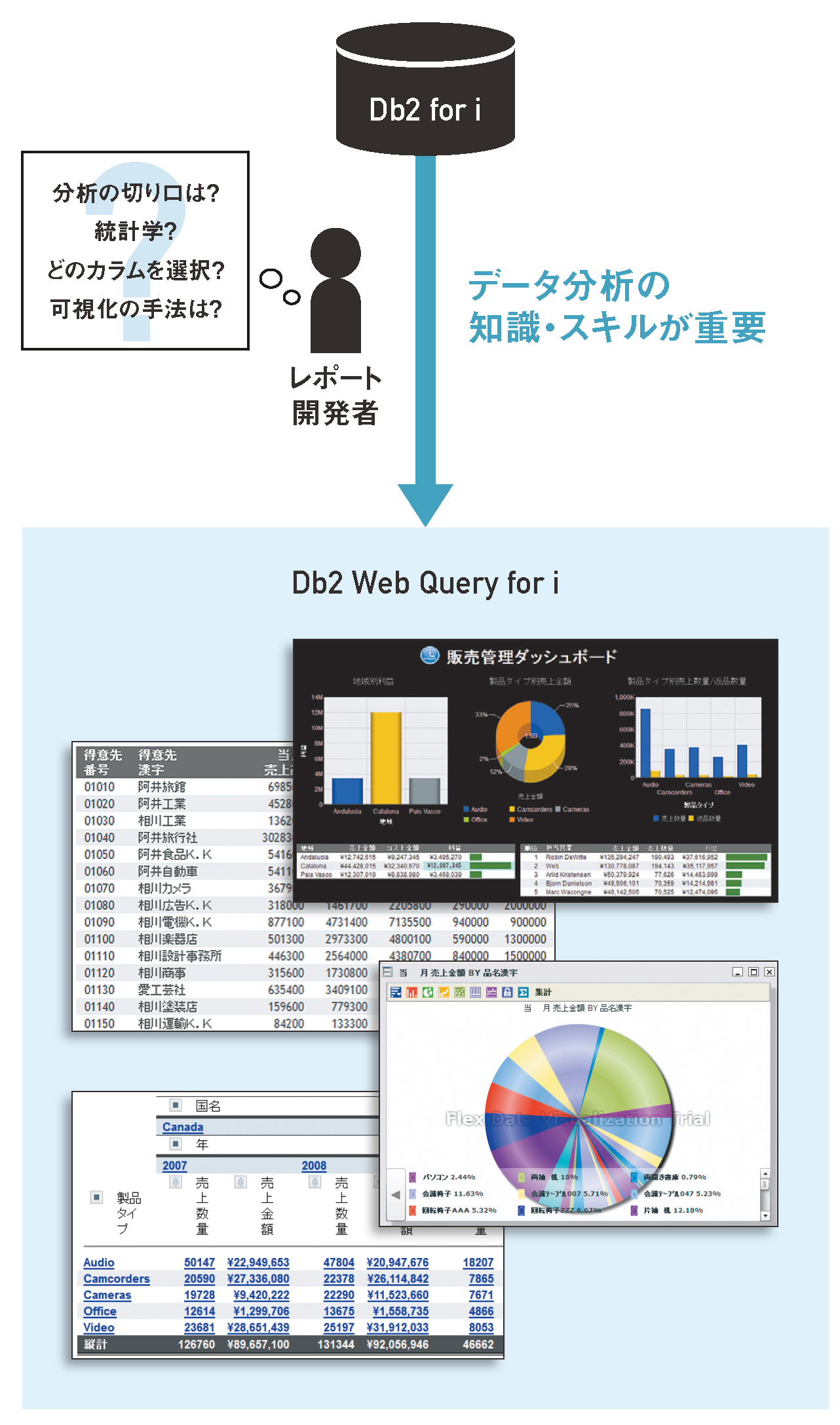
Web QueryをはじめとするBIツールは、データを可視化するまでにレポート開発の工程が必要である(図表3)。どんなに慣れたユーザーであっても、レポート開発にはそれなりの時間を伴う。データ活用では、さまざまなデータを多角的かつ試行錯誤的に、そして迅速に分析することで今まで得られなかった知見を得て、ビジネスに価値を提供することが求められている。
【図表3】Web Queryのレポート開発
Watson Analyticsは、従来のBIツールを置き換えるものではない。分析者が思考を途切らせることなく、Watson Analyticsのリコメンデーションを参考にしながら、多様な切り口での分析を試し、洞察を得るためのツールである。
したがって、従来型のBIツールと併せて用いることが重要となる。Watson AnalyticsはBIツールの活用を促進させるための、いわば専属のデータ・サイエンティストとしての役割を果たすことになる。
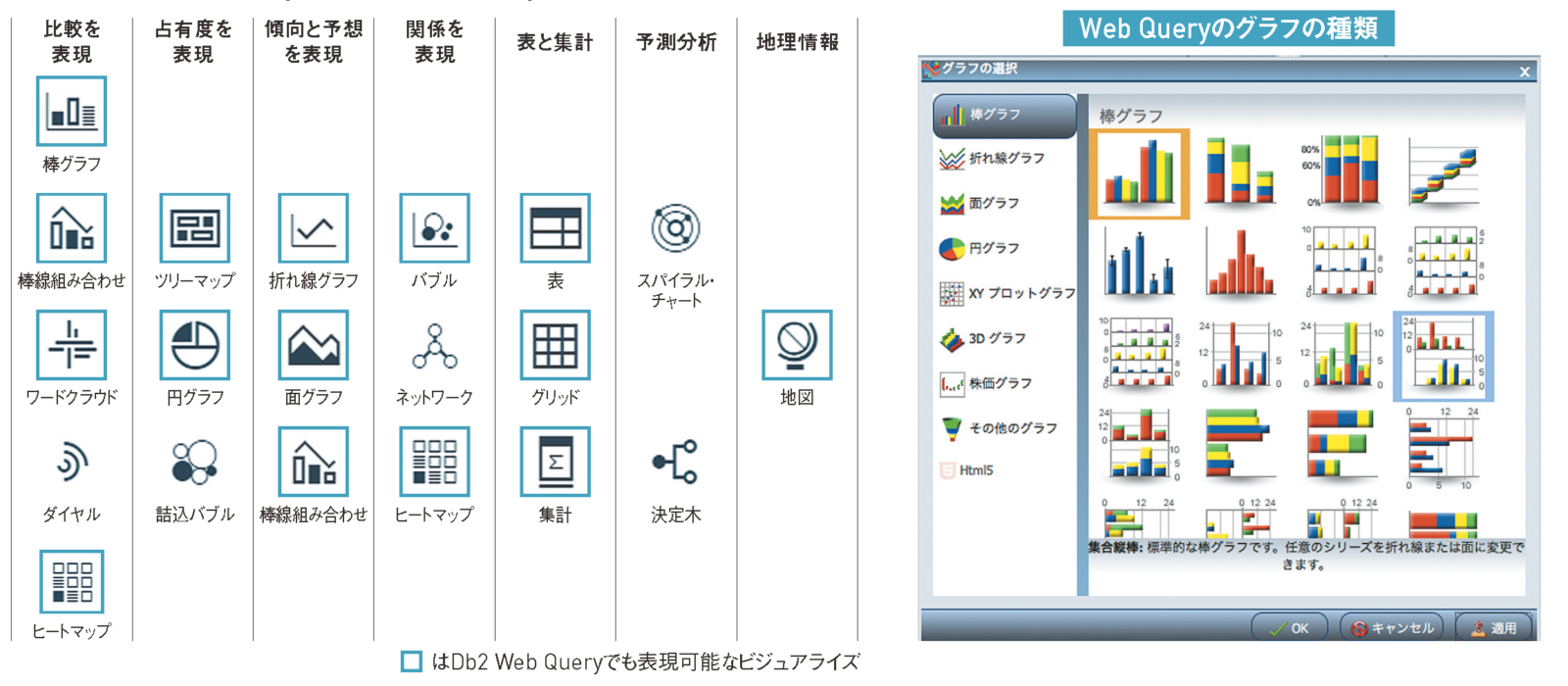
Watson Analyticsは、図表4のようなビジュアライズが可能であり、これらの多くはWeb Queryでも表現できる。一方、スパイラル・チャートはWatson Analyticsの特徴的なビジュアライズの1つで、Web Queryで同等の機能はサポートされていない。
【図表4】Watson AnalyticsとWeb Queryのビジュアライズ・パターン
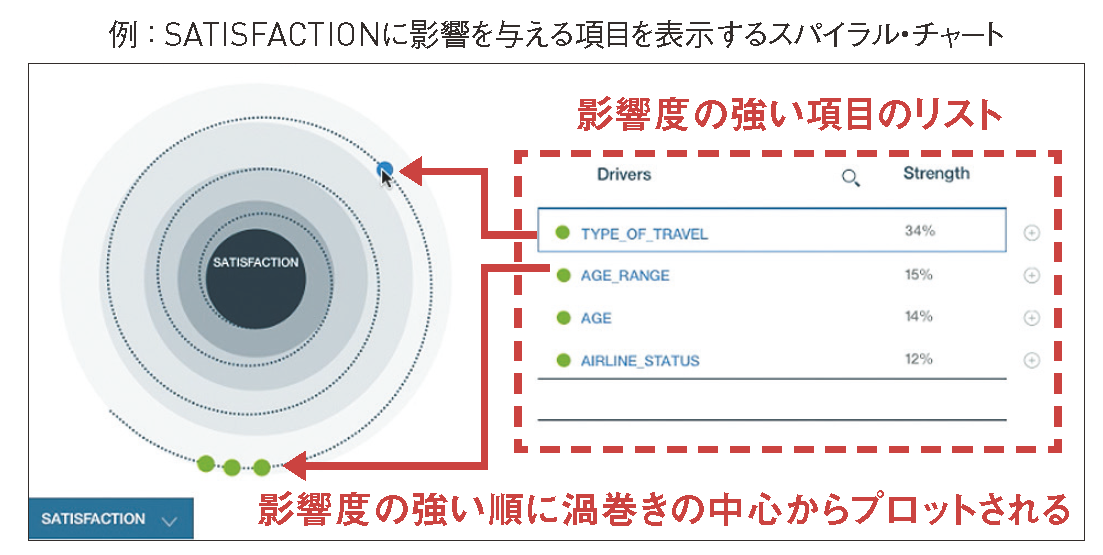
スパイラル・チャートは、特定の条件に対して影響を与える項目とその強さの度合いを渦巻上に示している(図表5)。このスパイラル・チャートを用いると、たとえば、「顧客満足度に影響を与えている因子は何か」といった問いかけにWatson Analyticsが回答してくれる。
【図表5】スパイラル・チャートの例
Watson AnalyticsとIBM iをつなぐ
Watson AnalyticsでIBM iのデータを分析する際に、まず必要になるのがIBM iのデータをクラウド上のWatson Analyticsにアップロードすることである。IBM iからアップロードする方法には、主に以下の2つがある。
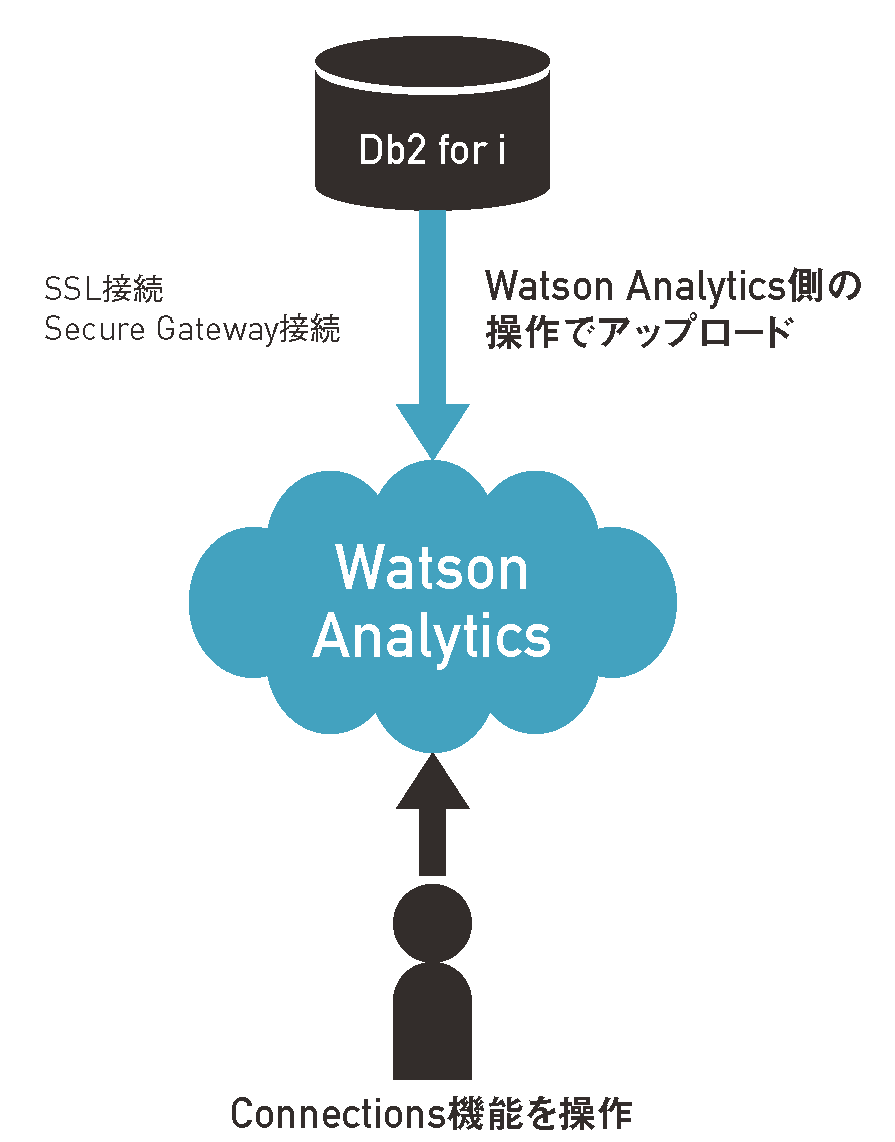
(1)Watson Analyticsの接続サービスを利用
Watson Analyticsには、オンプレミスやクラウドのデータベースへ接続する仕組みが用意されている。IBM i(Db2 for i)への接続コネクタもあるので、接続定義を行えば、Watson AnalyticsからIBM iのライブラリーとテーブルにアクセスしてデータを取得(Pull)できる。
取得したデータは、Watson Analyticsのクラウド上にデータセットとして保管される。業務での活用を本格化する場合には、Watson Analyticsからの操作でデータをアップロードできるこの仕組みが便利である。
接続には、Secure Gatewayを使用できる。さらにIBM i側でデジタル証明書をセットアップすることで、SSL接続も使用可能である(図表6)。
【図表6】Watson Analyticsの接続サービスでアップロード
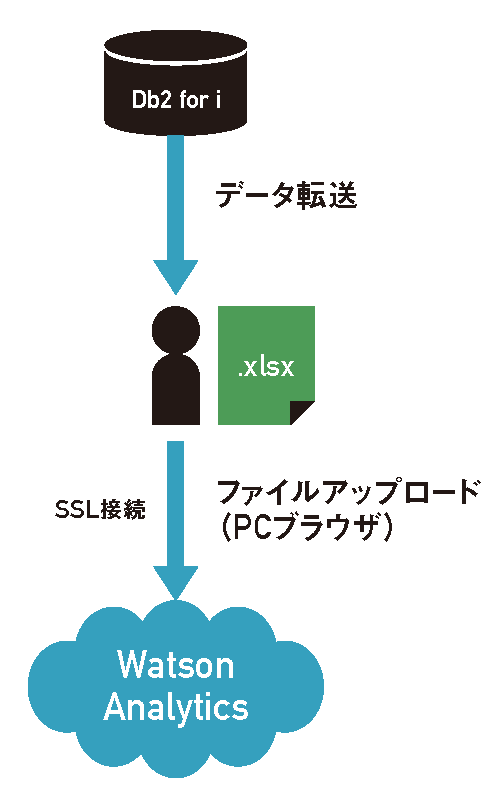
(2)PC経由でアップロード
Watson Analyticsには、ブラウザ経由でExcelファイルやcsvファイルをアップロードできる。IBM iのデータをアップロードする場合は、IBM iAccess Client Solutionsのデータ転送機能などを使って、いったんPCにファイルをダウンロードしてから、ブラウザ上でアップロードする。
この方法でも、アップロード後はクラウド上にデータセットとして保管される。トライアルでの使用であれば、PC経由のアップロードが簡便であろう(図表7)。
【図表7】PC経由でアップロード
データ活用の質を高める
さて、Watson AnalyticsにはIBM iのテーブル単位で簡単にアップロードできるが、データ活用としては、これだけでは十分ではない。実はデータ活用では、データ分析する対象データの選定や、分析ツールに入力する時点でのデータの整形・加工が非常に重要である。
それではデータ活用プロセスを、以下のように3つのステップに分解して説明しよう(図表8)。
【図表8】データ活用の質を高める3つのステップ
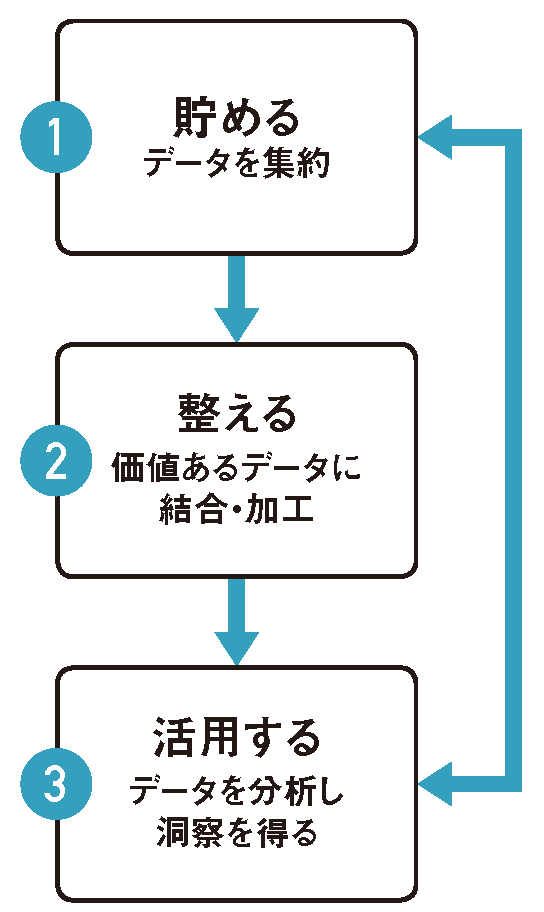
(1)データを貯める
データ活用の最初のステップは、データ活用の源泉であるデータを「貯める」ことである。本稿では、この段階でのデータを「Rawデータ」と呼ぶ。IBM iであれば、多くのRawデータが基幹業務の定型データとして蓄積されており、データ活用の対象となりうる。
Rawデータそのものを、Watson Analyticsにアップロードして分析するのは簡単である。しかしこの段階で分析するのではなく、保有しているデータの種類、ボリューム、更新頻度などを確認して、データ活用の候補として洗い出す。さらにIBM iの外部にあるデータベース・サーバーのデータや、PC上にあるファイルなども候補として範囲を広げると、より多くの洞察を得られる可能性が高まる。
(2)データを整える
Rawデータが揃い、分析ツールも準備済みであれば、すぐにRawデータを分析したくなるが、ひと呼吸置いて分析の質を高めることが大切である。この作業が「整える」である。
データ分析の目的に合わせて分析対象となるRawデータを選定し、必要に応じてJOINやフィルタリングする。さらには、あとで使用するデータ分析ツールの特性に合わせてこのステップに取り組めれば、データ活用の質をより高められる。「貯める」と「活用する」をつなぐ、この「整える」ステップが重要である。
(3)データを活用する
データの準備が整ったら、いよいよ「活用する」に進もう。活用の段階ではBIツールなどの分析ツールを利用するのが望ましい。データを多角的に分析し、可視化することで、Rawデータでは見えてこなかった傾向や特性を素早く発見する。それがデータ活用の価値となる。
「貯める」「整える」
DataMigratorで簡単に
「DataMigrator」はWeb Queryのオプション機能で、IBM i上でETL(データベースの抽出・変換・ロード)を可能にする。GUIベースのデータ管理コンソールを使って、ETLフローの作成・管理・実行が行える(図表9)。
【図表9】データ管理コンソール画面例
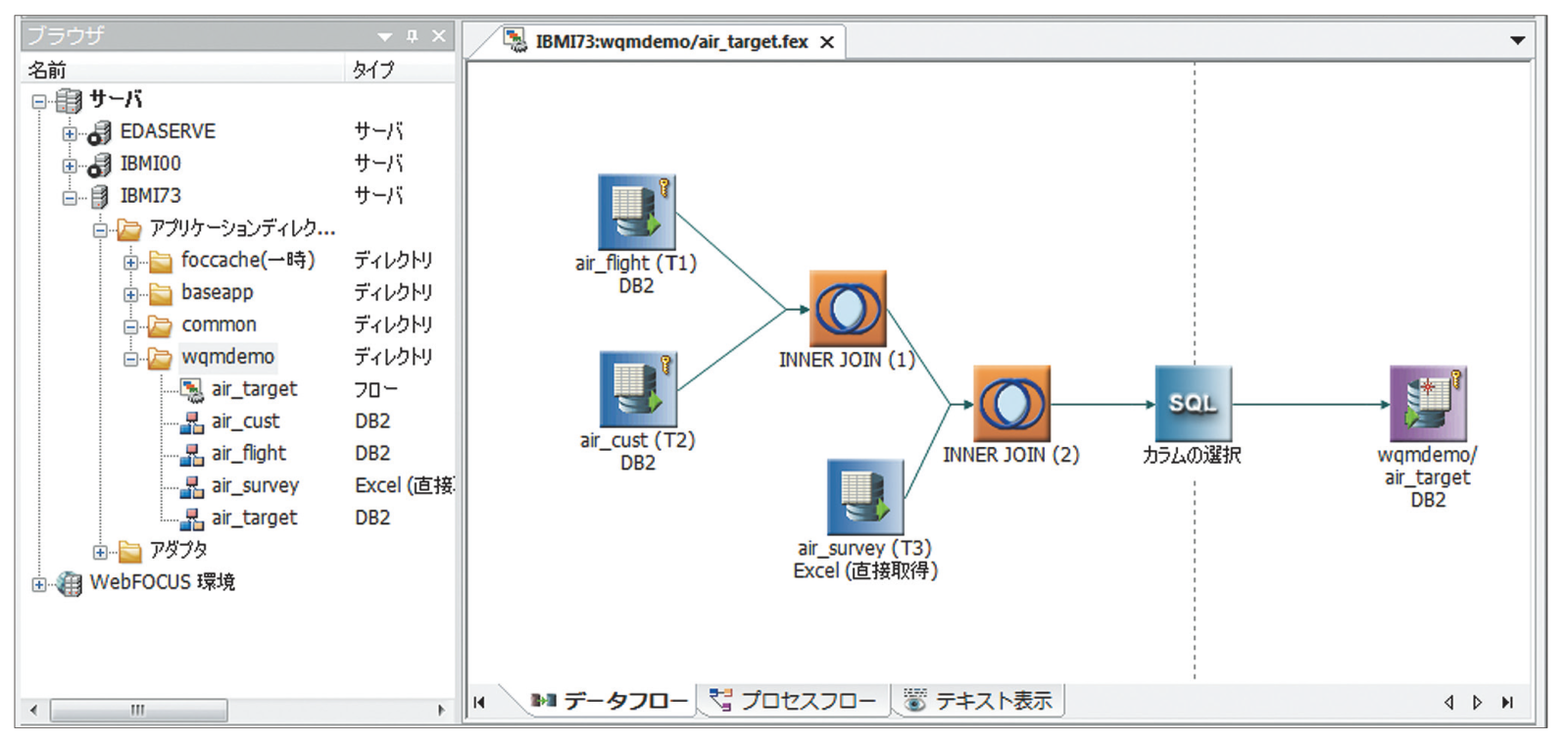
5250画面を操作することなく、複数のテーブルをJOINして、既存のデータソースから必要とする新しいターゲット・テーブルを作成できる。テーブルをJOINし、加工すること自体は表計算ソフトでも可能であるが、データの生成過程を管理するのはむずかしい。ETLツールを使う価値は、加工のプロセスをフローで定義して、可視化できる点にある。
フローで定義されたプロセスは再利用性が高く、データソースの更新や追加、加工条件を変えてターゲット・テーブルを複数生成することも容易であり、多様なデータを多角的に分析してデータ活用の生産性を高める。
また「貯める」「整える」でDataMigratorを活用する場合、扱えるデータソースがIBM i上のテーブルに限らないことがポイントになる。
本稿執筆時点の最新バージョンであるWeb Query 2.2では、IBM i以外のデータソース接続アダプタも用意されている。
たとえばWeb Query Standard Editionであれば、従来からのMicrosoft SQL ServerとOracle JD Edwardsに加えて、Postgres、MySQL、Generic JDBC adapterが利用できる。DataMigratorはWeb Queryのオプション機能なので、Web Queryでサポートしているアダプタであれば、DataMigratorでも利用可能である。
IBM i以外のデータソースとして注目すべきは、Oracle社製のデータベースにも対応できる点であろう。Generic JDBC adapterでJDBCのType4ドライバがサポートされており、Oracle社製のデータベースからデータを抽出し、IBM iのDataMigrator上で、他のデータソースと同じレベルでETL対象として扱える。
さらに、データソースとして扱えるのはRDBに限らない。Excelファイルやcsvファイルもインポート可能である。これらのファイルをIFS上に配置すれば、DataMigratorを使って容易にIBM iのテーブル形式に変換できる。
データ活用のためのデータソースを考えた場合、データ分析に用いるべき最新データや、すでに1次加工された質の高いデータは、PCにExcelファイル形式で保管されていることが多い。そういったデータとIBM iのデータを組み合わせて分析することで、新たな知見を得る可能性が高まる。
このようにDataMigratorを利用すれば、データ活用の3つのステップのうち、「貯める」「整える」がIBM i上でシームレスに、かつ効率的に取り組める。IBM i以外のデータソース、それもRDBだけでなくExcelファイルをも「貯める」対象にでき、それらのデータソースをIBM i上でGUIツールを使って加工、管理できる。
「貯める」「整える」はデータ活用の質を高めるうえで重要であるが、あくまでもデータ活用の準備段階である。データ活用では3つのステップをサイクル化して、仮説と検証を繰り返すことで質が高まるので、効率的にサイクルを回すには各ステップに適したツールを選定することが大切である。
「活用する」
IBM iのデータから知見を得る
データが整ったら、いよいよ「活用する」である。IBM iとWatson Analyticsを接続できる環境が整っていれば、Watson Analyticsにログインして、IBM iのデータをアップロードしよう。
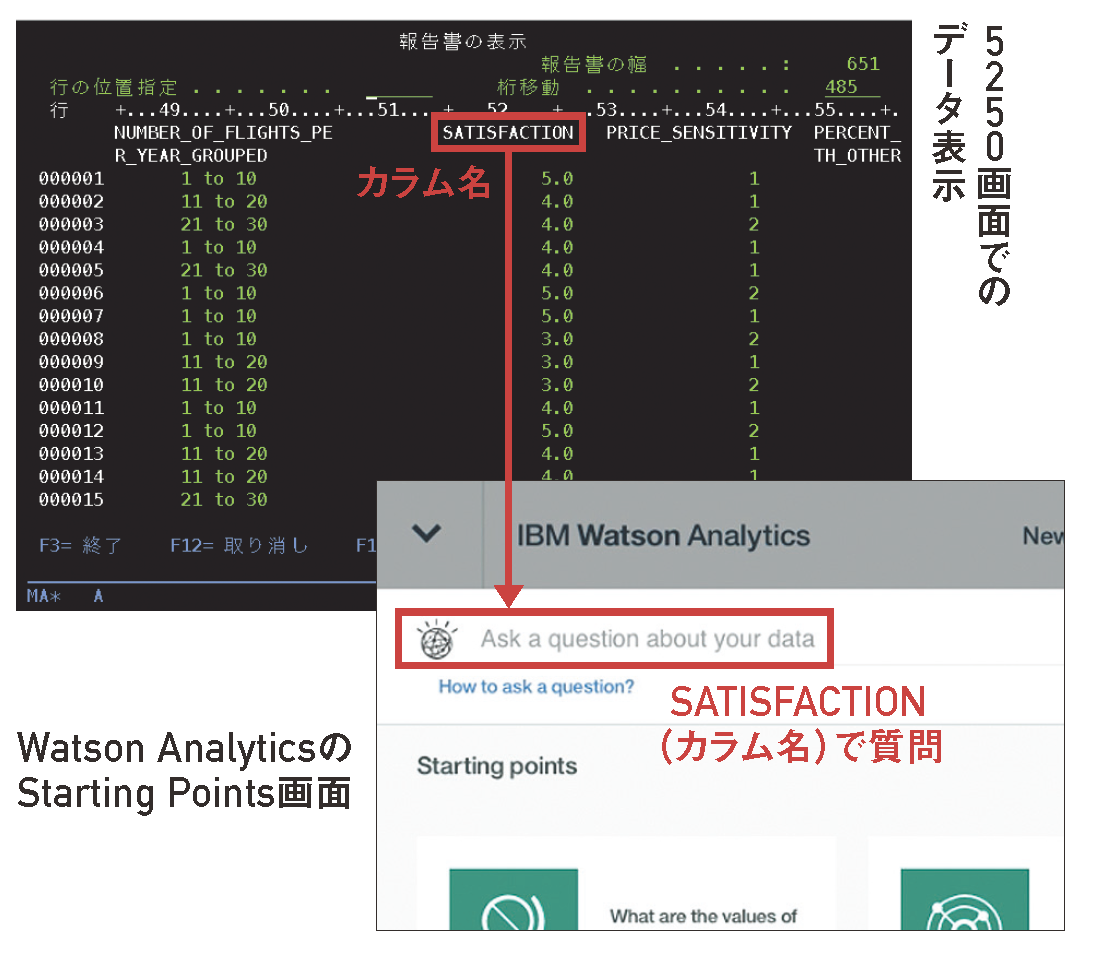
アップロードするとWatson Analyticsがデータを分析し、Starting Pointsを示す。もちろん、提示されたStarting Pointsを見ていくのもよいが、目的をもってデータを準備したのであれば、分析してほしいことを指示してみよう。方法は簡単で、「Ask a question about your data」と書かれているテキストフィールドに質問を投げかけるだけである。
Watson Analyticsのユーザーインターフェースは英語のみだが、アップロードデータのフィールド名を問いかけるだけでも、十分に回答してくれる。
たとえば図表10のようなデータをアップロードしていたのであれば、満足度に相当するフィールド名「SATISFACTION」と入力して問いかけると、満足度を軸にして新たなStarting Pointsが得られる。
【図表10】Watson Analyticsに質問する
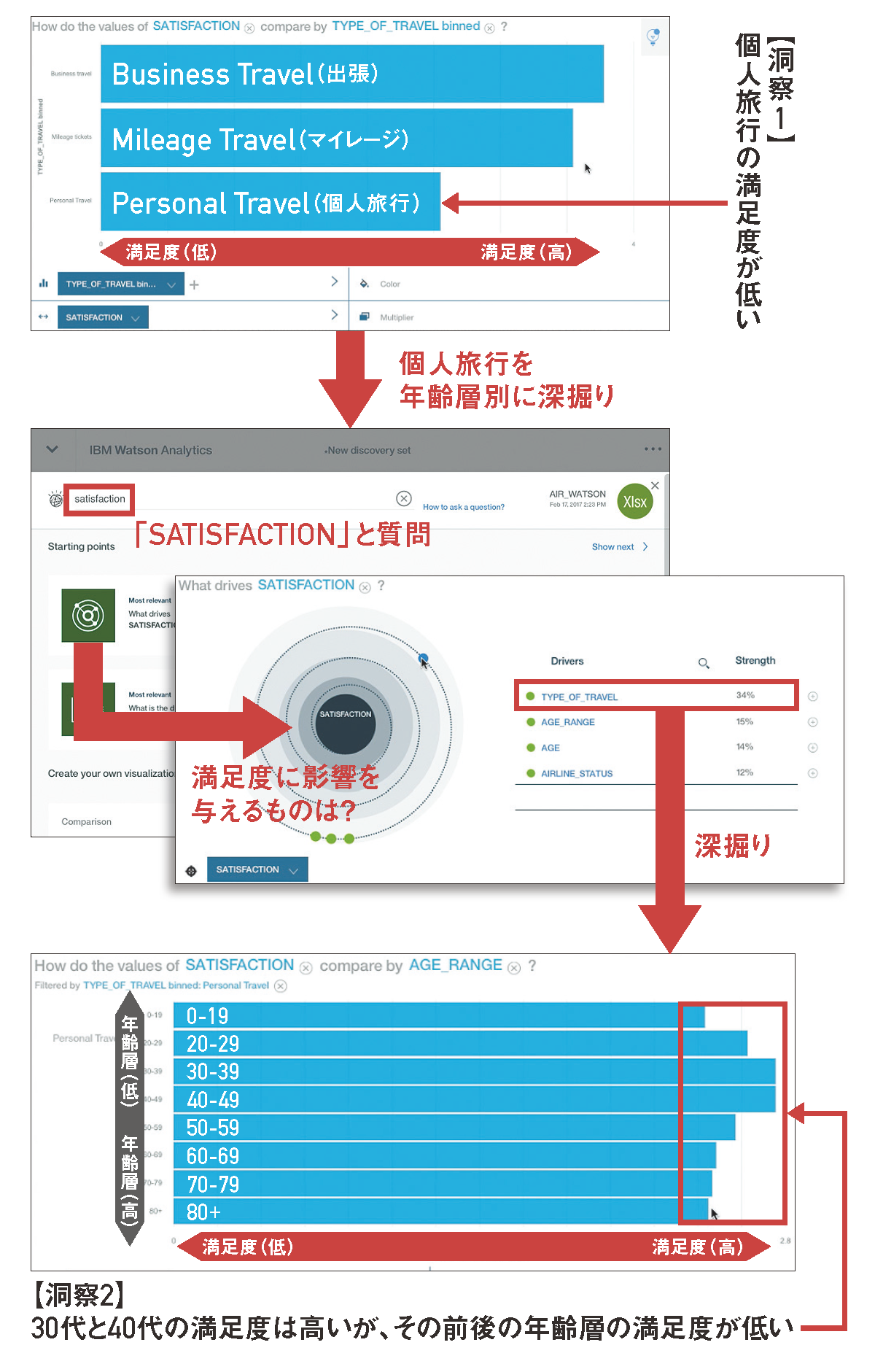
あとはStarting Pointsを選んでデータを視覚的に捉えて、そこから深掘りしたり、新たな質問をしてさまざまな角度から分析し、知見を得ていく(図表11)。
【図表11】Watson Analyticsを活用したデータ分析
Watson Analyticsは広義ではBIツールであるが、Watsonの認知エンジンが取り込まれており、従来型のBIツールとは異なるアプローチで分析を支援する。アップロードしたデータをまずは多角的に、より多くの切り口で見ていく際に有用であり、IBM iの定型データとの相性もよいうえに、接続性も高い。
「活用する」のステップでWatson Analyticsを取り入れれば、データ・サイエンティストのように分析業務をサポートするツールとして活躍してくれる。
テクノロジー・ミックスで
データ活用をレベルアップ
以上、本稿ではWatson Analyticsを取り入れて、IBM iのデータを活用する方法を紹介してきた。データ活用に取り組む理由はさまざまであろう。だが、データ活用する以上は「貯める」「整える」の準備はスピーディに、そして「活用する」に一刻も早く取り組んで、1つでも多くの知見を得ることが大切である(図表12)。
【図表12】データ活用をビジネスに活かす
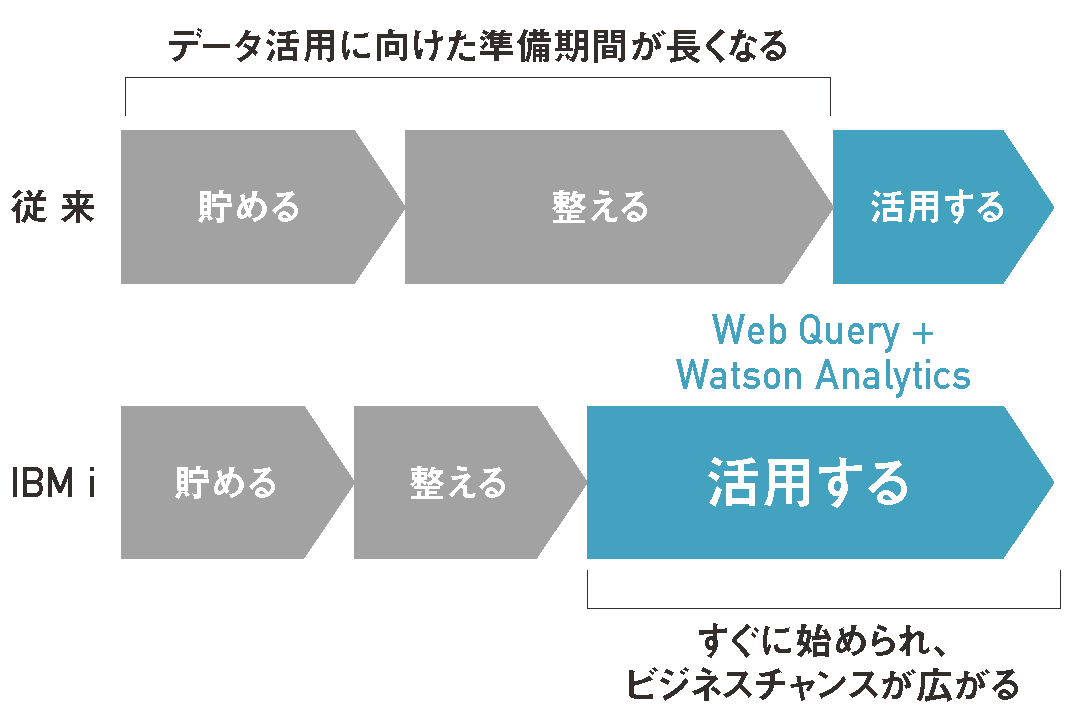
IBM iであれば、オールインワンで「貯める」「整える」に取り組める。さらにWatson Analyticsと連携して、分析の切り口を学びながら知見を得ることができる。知見やノウハウが蓄積されれば、Web Queryのレポート開発に応用してリアルタイム分析レポートを業務に組み込める(図表13)。
【図表13】Watson AnalyticsとWeb Queryの活用
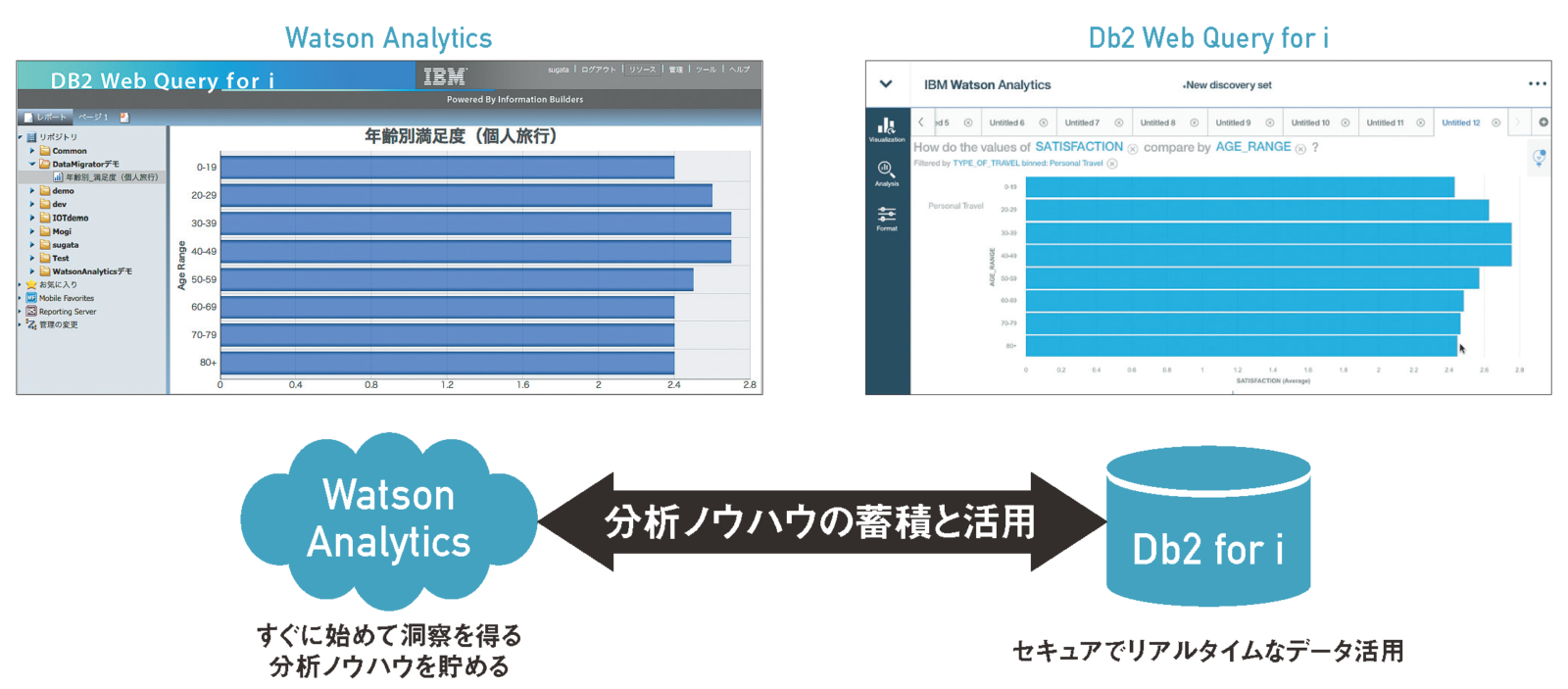
企業を取り巻く環境が急激に変化していく今、データ活用は企業の成長を左右する重要な鍵となる。同様に、テクノロジーも非常に速いスピードで進化しているので、Watson Analyticsのような新しいテクノロジーを、クラウドサービスで迅速に取り入れていくことが望まれる。IBM iとWatson Analytics、適材適所のソリューションを組み合わせることで、より高いレベルのデータ活用を業務に取り入れてみてはどうだろうか。
・・・・・・・・
著者プロフィール
菅田丈士 氏
2008年、日本IBMへ入社。GTSデリバリー部門でIBM iの設計・構築・移行プロジェクトに従事。2014年、テクニカル・セールス部門に異動し、Power Systemsおよび IBM iの提案活動の技術支援を担当、現在に至る。

・・・・・・・・
i Magazine 2017 Winter(11月)掲載