近年、いわゆるAI を構成する要素技術として機械学習の発展が著しい。とくにディープラーニングはその火付け役であり、画像分類、物体検出、セグメンテーションなどの画像領域をはじめ、自然言語処理、音声認識といった分野にまで広く応用されている。その表現力の高さから、今や従来の機械学習手法を凌ぐ結果を見せている。
ディープラーニングの技術は日進月歩で進化しており、新たな研究が発表されると、すぐに実装コードが公開されたり、応用研究が進められたり、ビジネスに適用されたりする。
なかでも最近注目されている技術の1つに、「敵対的生成ネットワーク」(Genera tive Adversarial Networks。以下、GAN)がある。GANは生成モデルの一種であり、データから特徴を学習することで、実在しないデータを生成したり、存在するデータの特徴に沿って変換できる。
GANは、正解データを与えることなく特徴を学習する「教師なし学習」の一手法として注目されている。そのアーキテクチャの柔軟性から、アイデア次第で広範な領域に摘用できる。応用研究や理論的研究も急速に進んでおり、今後の発展が大いに期待されている。
以下に、GANが生成した画像データの例を示す。
図表1はベッドルームの写真に見えるが、すべて合成画像であり、実際には存在しない部屋である。図表2は、バッグの線画を入力として与えて、そこに本物のような着色を施した。図表3は、画家それぞれの画風を学習させ、入力として与えた写真(インプット)にその特徴を属性として付与して変換した。このように学習データから特徴を獲得し、画像の合成や画風の変換、特徴の付与などが可能である。



まだビジネス面での応用例はまだ少ないが、GANを利用した自動着色アプリ(*1)や画像を自動生成するAPI(*2)が公開されたり、 GANを実装したソフトウェア(*3)が登場している。後述するように、GANが本物と偽物を見分けるように学習する特徴に着目した応用研究も着々と進んでいる。
本稿では現在注目を集めているGANについて、発展の背景や学習の仕組み、その特徴や応用研究について概説する。
GAN発展の背景とその特徴
発展の背景
GANは、イアン・グッドフェローらが2014年に発表した論文で、2つのネットワークを競わせながら学習させるアーキテクチャとして提案された(*4)。この斬新な構成により、従来の生成モデルより鮮明で本物らしい画像生成が可能になった。
さらに2015年には、畳み込みニューラルネットワーク(CNN)で見られるような畳み込み層をネットワークに適用したDCGAN(Deep Convolutional GAN、*5)が提案された。後述のように、GANは学習時に不安定になるケースが見られ、意味をなさない画像を生成したり、生成データの種類が偏るなどの課題があった。
これに対してDCGANはより鮮明な画像生成を行うとともに、学習を安定化させる手法を提案したため、GANブームの火付け役となった。
GANの機械学習的分類
前述したように、GANは生成モデルであり、データの特徴を抽出して学習し、実在しないデータを生成できる。生成モデルに分類される手法としては、変分オートエンコーダやボルツマンマシンなども以前からあるが、GANはそれらの手法と比べてより鮮明な画像の生成が可能である。
また、GANは教師なし(ラベルなし)学習を基本とする。後述するConditional GANのように、学習と同時にデータにラベルを与えるケースもあるが、基本的には用意したデータにラベリングすることなく使用できるので、教師データを作成する手間が省ける(手法によって異なるので確認が必要である)。
GANの学習の仕組み
GANは、2つのニューラルネットワークで構成される。
アーキテクチャを図表4に示す。1つはGeneratorであり、その名のとおりデータを生成する。Generatorは、生成データの特徴の種に相当するランダムノイズ(図表4ではz)を入力することで、このノイズを所望のデータに近づけるようにマッピングする。もう1つはDiscriminatorであり、Generatorが生成した偽物のデータと本物のデータが与えられ、その真偽を判定する。
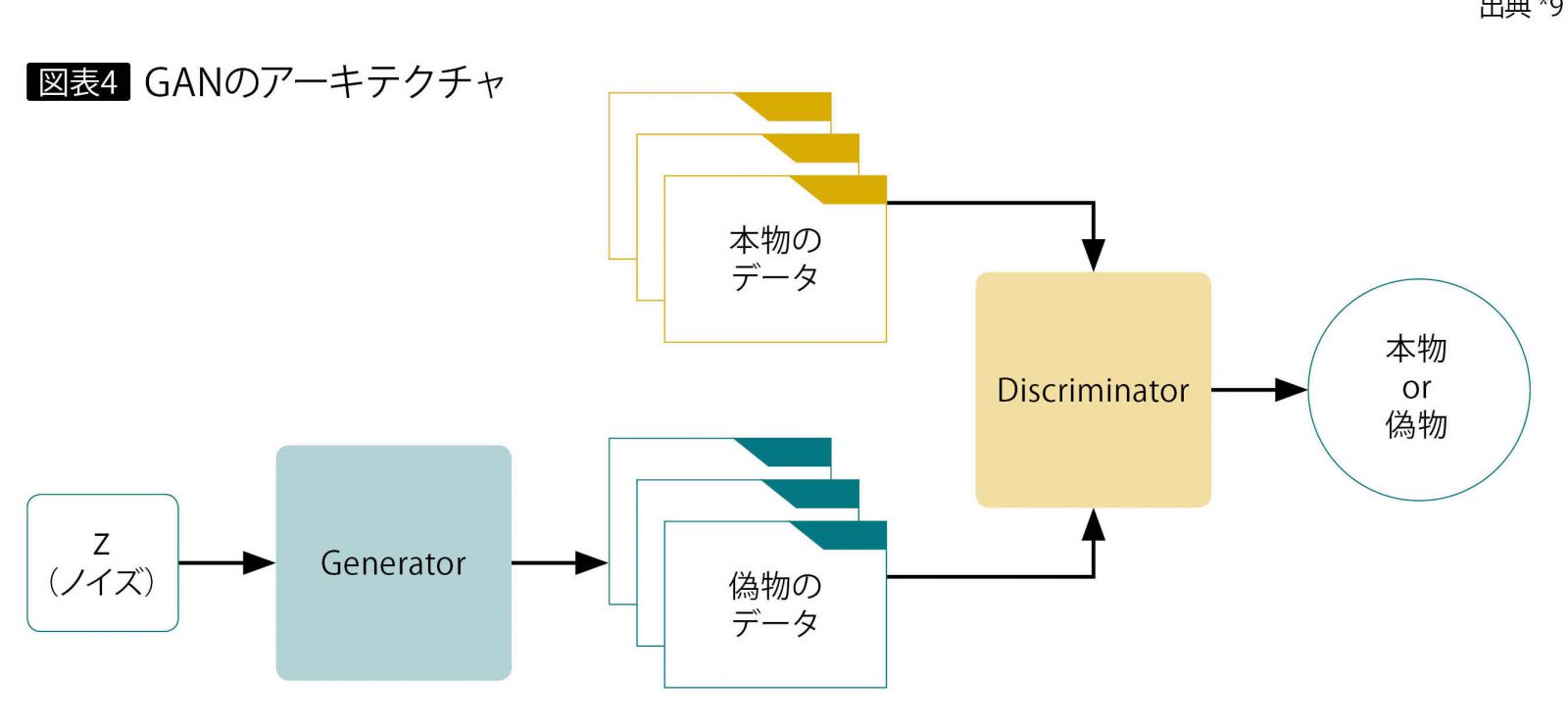
この2つのネットワークを交互に競合させ、学習を進めることで、Generatorは本物のデータに近い偽物データを生成できるようになる。この関係性は、しばしば紙幣の偽造に例えられる。偽造者(Generator)は本物に近い偽札を作ろうとし、警官(Discriminator)はそれが偽物であると見抜く。するとGeneratorは、より精巧な偽札を作り出すように技術を発展させる。こうした「いたちごっこ」が繰り返され、最終的には本物に近い偽札が生成されるようになる。
また補足だが、2つのネットワークの競合関係は、ロス(コスト)関数を共有させることで表現される。すなわち片方のロスが小さくなれば、もう一方にとってはそのロスが大きくなる。Generatorはロス関数の値を小さくすることを目的に、Discriminatorはロス関数の値を大きくすることを目的に学習させる。
ここが、CNNや再帰型ネットワーク(RNN)などロスの最小化を目指す他のアーキテクチャと異なる点であり、GANがぼやけにくい画像を生成するポイントである。ただし後述するように、これが学習を難しくさせている点でもある。
また学習させたGANから類似データを生成する場合、Generatorにはランダムノイズを入力するが、ここにランダム性をもたせることで、生成されるデータにもランダム性が生まれる。すなわち、サンプルするたびに異なる類似データが生成されることになる。
zが属する空間(潜在空間と呼ぶ)は、学習させた画像の特徴量が分布している空間とみなすことができ、空間上で近いzからは、類似の特徴をもったデータが生成されることを意味する。さらに、このzに演算を施すことで、画像に特徴量を付与・変換できる。たとえば人の顔を徐々に笑顔に変化させていく画像を生成できる(図表5)。

GANの考慮点
GANを扱う場合に、留意すべき点が2つある。
1点目は学習の不安定さ、つまり生成されるデータに偏りが生じることである。これはmode colla pseと呼ばれる現象であり、GANが備える構成の複雑さから生じる。発生の予見は難しく、回避するにはひたすら試行錯誤を重ね、パラメータやネットワーク構成の見直しが必要となる。
2点目は、生成モデル全般に共通する点であるが、生成データの評価が難しいことである。分類問題や将来値の予測が対象であれば、定量的にその学習結果を評価することは可能である。しかし生成モデルの場合は、生成された類似データを定量的なメトリックを用いて評価すること(何をもって「よい類似」とみなすか)は難しいので、学習データに精通した者が、実際に生成された画像を見て学習結果を評価することが望ましい。
GANの応用研究
以下に、GANの応用研究をいくつか紹介する。
Conditional GAN
通常のGANのデータ生成は、ランダムにサンプルされるので、生成されるデータの種類を制御できない。Conditional GANは学習時にラベルを与えることで、推論時にもラベルを入力してデータを生成できる。図表6はその例で、数字の種類を指定してデータを生成している(*6)。

SRGAN
低解像度の画像を高解像度に復元する、超解像を目的としたGANである(図表7)。Bicubic法のような従来の超解像手法による復元では、ぼやけた画像になりやすい。SRGANでは、GANの特性を利用することで、ぼやけの少ない画像の復元が可能である(*7)。
pix2pix
pix2pixは言語翻訳のように、画像間の特徴を変換する。図表8では、セグメンテーションされた景色に対して、たとえば「航空写真を地図化する」「日中の写真を夜間のシーンに変換する」などを行っており、入力時に変換前の画像をラベルとして与えるconditional な設定と考えられる。「ある特徴をもつ画像から、別の特徴へ変換する」と捉えると、応用アイデアが広がる(*8)。

Cycle GAN
pix2pixと同じく、画像の特徴間の変換を実行する。すでに紹介したように画風に応じて変換した図表3や、ウマとシマウマを変換した図表9がこの手法を使用している。ここでは学習データの変換元と変換先の対応付けが必要なく、共通した特徴(ドメインと呼ぶ)をもつ画像を集めて、GeneratorとDiscriminatorのそれぞれに学習させることで、各特徴間を相互に変換する(*9)。

以上はGANの応用研究のごく一部である。そのほかにもGANの特性を利用した応用研究として、以下が挙げられる。
・ データ数が少ない場合に、GANで生成した画像を学習データとして加え、CNNの分類精度を改善する(*10)
・ GANによる超解像を利用して、物体検出における解像度の低い検知対象の検知率を向上させる(*11)
・ 低解像度X線やCT画像のノイズを除去する(*12)
本稿では生成モデルしての画像合成を中心に紹介したが、物体検出やセグメンテーション、異常検知などへの改善手法としてGANを利用する例、さらにテキストや音声、音楽、動画、3次元データ、医療データを対象にした拡張研究も見受けられる。
また学習時の安定性の向上や理論的背景を探る研究など、多種多様な研究が次々と公開されており、今後も目が離せない。
GANではオープンに、さまざまな研究や適用の試みがなされている。この手法が初めて登場してから、研究が急速に進展していることを考えると、生成モデルとしての注目度は非常に高く、今後もさらなる発展が期待される。
・・・・・・・・
参考データ
*1 PaintsChainer https://paintschainer.preferred.tech/index_ja.html
*2 Image Generate API https://a3rt.recruit-tech.co.jp/product/imageGenerateAPI/
*3 NVIDIA/DIGITS https://github.com/NVIDIA/DIGITS/tree/master/examples/gan
*4 「Generative Adversarial Nets」 https://papers.nips.cc/paper/5423-generative-adversarial-nets.pdf
*6 「Conditional Generative Adversarial Nets」 https://arxiv.org/pdf/1411.1784.pdf
・・・・・・・・
著者|平内 雅則 氏
日本アイ・ビー・エム システムズ・エンジニアリング株式会社
アナリティクス・ソリューション
IT スペシャリスト

ひらうち まさのり/2014年、日本IBMに入社。最近は日本アイ・ビー・エム システムズ・エンジニアリングで、ディープラーニングを中心に、機械学習に関連するプロジェクトに参画している。
[IS magazine No.20(2018年7月)掲載]