データの活用場所による
メリット・デメリット
メインフレームは伝統的に企業の基幹業務用マシンとして使用され、バッチ処理やトランザクション処理を担ってきた。従来からのメインフレームを「強固なセキュリティと超高度な可用性を備えたバッチ/トランザクション用マシン」と断定しても、そう間違ってはいない。
しかし、世の中がデジタル・トランスフォーメーション(デジタル化によるビジネス改革)へ向けて大きく動き、企業が蓄積する業務上のデータや日々扱う情報に大きな注目が集まり、その活用が広範囲に進むにつれて、メインフレーム上のデータやメインフレームそのものに対する視線が変わってきた。
最初に動いたのは、メインフレームではないプレイヤーである。メインフレームとは別のプラットフォームにアナリティクスやマシン・ラーニング用のツール/アプリケーションを配置して、メインフレームからデータを取得して活用する動きが急速に広がった。
ただしこの方式は、利用が深まるにつれて課題や問題点も顕在化してきた。
1つはメインフレームから別サーバーへのデータの移動に伴うコストである。移動先のプラットフォーム(多くはオープン基盤)ではデータを保存するためのデータレイクの構築が必要になり、さらにデータを移動・加工するためのETLやレプリケーションも不可欠である。
もう1つは、データの移動にかかる時間である。データが大量になればなるほど移動に時間を要し、場合によってはクリティカルな問題になる。
また、オープン基盤をサポートするための要員の確保やその教育コストも課題となるが、何よりも見逃せないのは、メインフレーム上の業務データをメインフレームの外へ出すことのリスクである。メインフレームで扱う基幹データは機密性の高いクリティカルな情報であることが大半なので、それをオープンな基盤へ移動することによる漏洩が懸念されるのである。
これに対してメインフレーム上のデータをメインフレーム上で活用するメリットは大きい。たとえば、次のような点が挙げられる(図表1)。
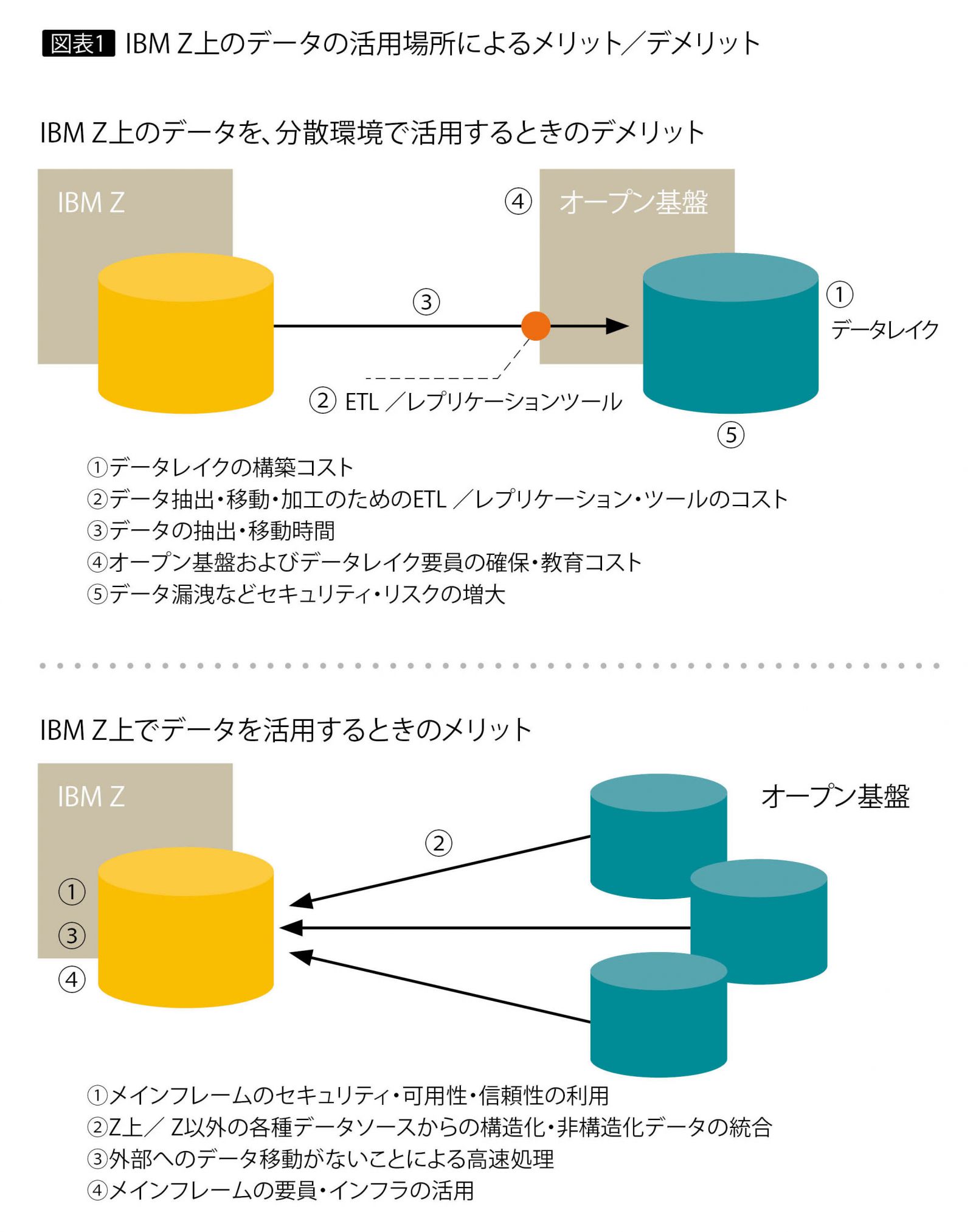
・メインフレームの業務アプリケーションと同等のセキュリティ・可用性・信頼性を得られる。
・外部へのデータ移動がないので、より高速に処理を行える。
・メインフレーム上の各種データと、メインフレーム外のデータをメインフレーム上で統合できる。
・メインフレームの要員・インフラを活用できる。
IBM Zでは2011年から、Z上でデータ活用を行えるツール・製品が提供されてきた。
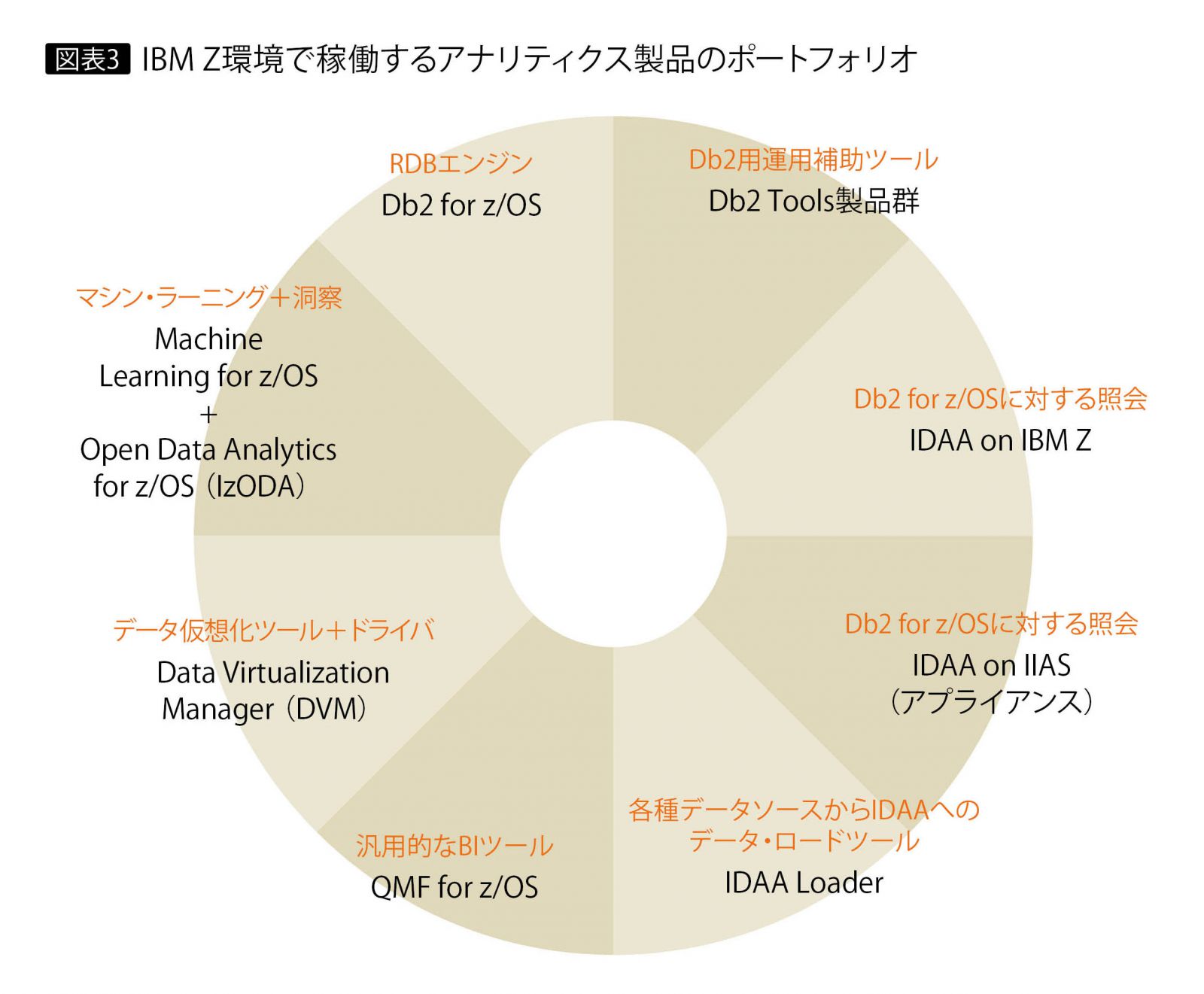
図表2は、主な製品のリリース時期をまとめたものだが、最近になって急速に対応が進んでいることが見て取れるだろう。図表3は、IBM Z上、ないしZ環境で利用可能な製品・ツールのポートフォリオである。以下、主だった製品を紹介しよう。

抜本的に作り変えられ
2製品になったIDAA
「IBM Db2 Analytics Accelerator」(以下、IDAA)は2011年にリリースされたアプライアンス(IBM Zの横に配置して利用。IAベース)で、「日本でも金融系と製造系のお客様の間で導入が進んでいる」(日本IBMの横田淳氏)が、2017年11月に従来のアーキテクチャを踏襲しつつ、データベースやハードウェア基盤を抜本的に改めた「IDAA V7.1」が発表された。

IDAA V7.1には、Z上で稼働する「IDAA on IBM Z」とPOWERをベースにしたアプライアンス「IDAA on IIAS」の2つのデプロイオプションがある。
「従来のIDAAのデータベース技術は、Netezzaテクノロジーを採用していましたが、V7.1ではインメモリ・カラム型テクノロジーの利用が可能なIBM BLUテクノロジーへと大幅な変更が行われました。Z上で稼働するIDAA on IBM Zは、Db2 for z/OSとの互換性が向上し、さらに高速の分析処理が可能になりました」と、横田氏は語る。
初めてのマシン・ラーニング用
フレームワーク
「IBM Machine Learning for z/OS」(以下、IML for z/OS)は2017年2月に発表された、z/OS上で稼働する初めてのマシン・ラーニング用フレームワークである。これは、言語・データ処理用のエンジンとして「IBM Open Data Analytics for z/OS」(以下、IzODA)を使用する。IzODAは、大容量のデータをインメモリで高速処理可能な「Spark」と、マシン・ラーニングのための言語/ツールセットである「Pyhon/Anaconda」、データ仮想化のツールを同梱した「Optimized Data Layer」の3つのツールで構成される製品である。
このIML for z/OSと前述のIDAAを連携させると、Z上のDb2、IMS、SMF、SAM/VSAMなどの各種データを取り込んでIDAAでデータ整形処理を行い、さらにIML for z/OSでマシン・ラーンングのためのモデル開発からトレーニング、モデルの評価・デプロイ、結果のスコアリング、モニタリングまでを一貫してスピーディに処理することができる。IBM Zをマシン・ラーニング向けのプラットフォームに変える製品と言うこともできるだろう。
多様なデータソースから
データを取得可能なDVM
IBM Z上でデータの分析や活用を行うには、さまざまなデータソースからデータを取得、あるいはデータを仮想的に利用できる環境が重要になる。これには、データ仮想化ツールの「IBM Data Virtualization Manager for z/OS」(以下、DVM)が強力なパワーとなる。
IBM Zでは、Z上でデータを活用する環境が着々と整備されつつある。このインパクトについて、日本IBMの夏目幸子氏は、次のように指摘する。
「IBM Z上のデータはどれもクリティカルで、とくにIMSデータで顕著なように、データの構造が堅牢なうえにも堅牢なためアクセスすることすら困難な側面がありました。しかし、データ活用の環境が整ってきたことにより、IMSを含めてZ上のデータをストアして、直接アクセスすることが可能になっています。過去を知るものにとってはそのこと自体、夢の世界で、大きな扉を開けたと言えるかと思います。今後は、IBM Zに対する概念を私ども自身が変え、お客様にデータ活用の可能性豊かな世界をご紹介していく必要性を感じています」

[IS magazine No.21(2018年10月)掲載]