一般的にトラブルシューティングとは、発生した障害の原因を調査し解決するまでの手順や方法論を指す。障害が発生したら早期解決が求められるのは当然のことである。しかし早期解決を目指していたはずが本来の目的を見失い、解決までむしろ時間がかかってしまうこともよく見受けられる。そのような事態を回避するためにも、ここではトラブルシューティングの基本的な流れを押さえ、それぞれの段階における作業のポイントをまとめる。
基本的な流れ
図表1はトラブルシューティングの一連の流れをまとめたものである。
【図表1 画像をクリックすると拡大します】
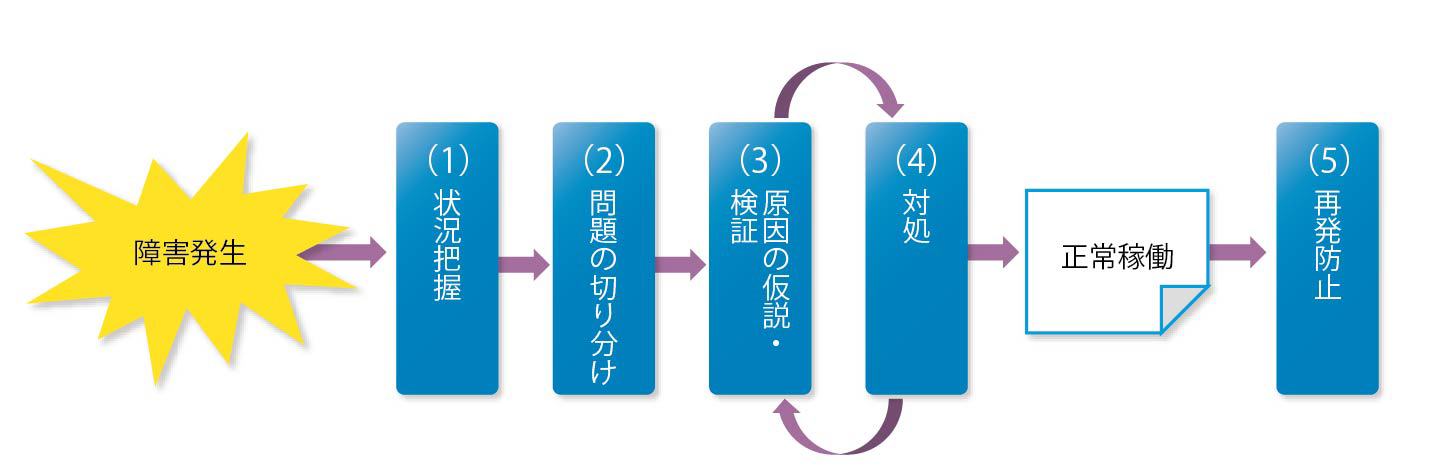
障害発生とは、本来あるべきとおりにシステムが稼働しないことを指す。問題解決にあたっては論理的に確実にステップを踏むことが重要である。そのためには、ゴールの明確化およびメンバーの役割と責任範囲の明確化を常に意識しておくことを忘れてはならない。
(1)状況把握
障害発生では、さまざまな要因が考えられる。状況把握では、正常時と比較して何がどのように違うのか、現象を正確に把握する必要がある。同時に、障害発生前後にシステムに変更点が発生していないか確認する。変更点は、内的要因と外的要因に大きく分けられる。
内的要因の例としては以下が該当する。
・PTFの適用
・アプリケーションの変更
・システム構成の変更(ハードウェアのパーツの交換、OSのバージョン・アップ、設定値の変更)
一方、外的要因の例としては以下が該当する。
・システムの連携先であるシステムの変更
・ネットワーク環境の変更
・接続するクライアントの変更(接続数や接続タイプ)
また障害発生時のシステム環境を正しく理解し整理することも必要となる。たとえばIBM iのバージョン、PTFレベル、ハードウェア/ソフトウェア構成、ネットワーク構成、クライアント構成などである。最後に、その障害が業務やユーザーに与えている影響も確認する。影響範囲によって、解決に求められるスピード感がおのずと決まってくる。
(2)問題の切り分け
障害として現れた現象については根本的な問題が原因で発生している現象と、2次的に発生している現象がある。全体のなかから問題のないところは切り分けていき、問題となっている範囲を狭めて明確にする必要がある。ここで切り分けをせず、場当たり的に感覚で対応を進めると、効率が悪く、かえって解決までに時間がかかってしまうこともある。問題の切り分けができたら、再現性のある条件を特定する。問題の発生条件の絞り込みを行うことにより、原因が見えてくることもある。
(3)原因の仮説・検証
次に原因の仮説を立て、検証する。机上の検証以外に、場合によっては実機を使用して事前に検証できる場合もある。実機検証では効果を見極めるためにも、一度に複数の検証項目は盛り込まず、1つずつ検証する。
実機検証は解決方法の安全性を確保できる一方で、不必要な検証まで実施してしまうケースも見受けられるので、検証のケースを策定する場合には目的を見失わないことが重要である。また複雑な障害や、原因が特定できてもPTF適用の必要などで早急に対処できない障害については、運用面での回避策の検討も考えねばならない。
(4)対処
検証結果を踏まえ、有効な方法を対処する。一度の対処で解決しない場合や被害を最小限に抑えるために一時的な対処を実施した場合は、前フェーズの「原因の仮説・検証」と「対処」を正常稼働するまで繰り返す。
(5)再発防止
今回発生した障害を事例として、再発防止策を検討し、必要に応じて運用に反映させる。システムが正常稼働したところまでではなく、再発防止の検討まで行い、はじめて障害が解決しトラブルシューティングが完了したと言える。
トラブルシューティングの例
次に、具体的にIBM iでのパフォーマンス・トラブルのケースを例にとり、これまで述べてきたトラブルシューティングの流れを確認する。なお、ここでは流れの確認を主目的とするため、極力シンプルなケースとなるような前提を置き、話を進める。
(1)状況把握
新規開発中の特定のアプリケーションが、目標レスポンスタイムで処理を完了できないので、パフォーマンス改善策が必要な状況にあると仮定する。新規アプリケーションのため、システム変更に関する考慮は不要である。
(2)問題の切り分け
問題のあるアプリケーションの特定はできているため、これ以上の問題切り分けは不要とする。
(3)原因の仮説・検証
パフォーマンス・トラブルの解決では、問題のあるアプリケーションの稼働中にパフォーマンス・データを取得/分析し、システム資源のバランスを確認することが基本である。
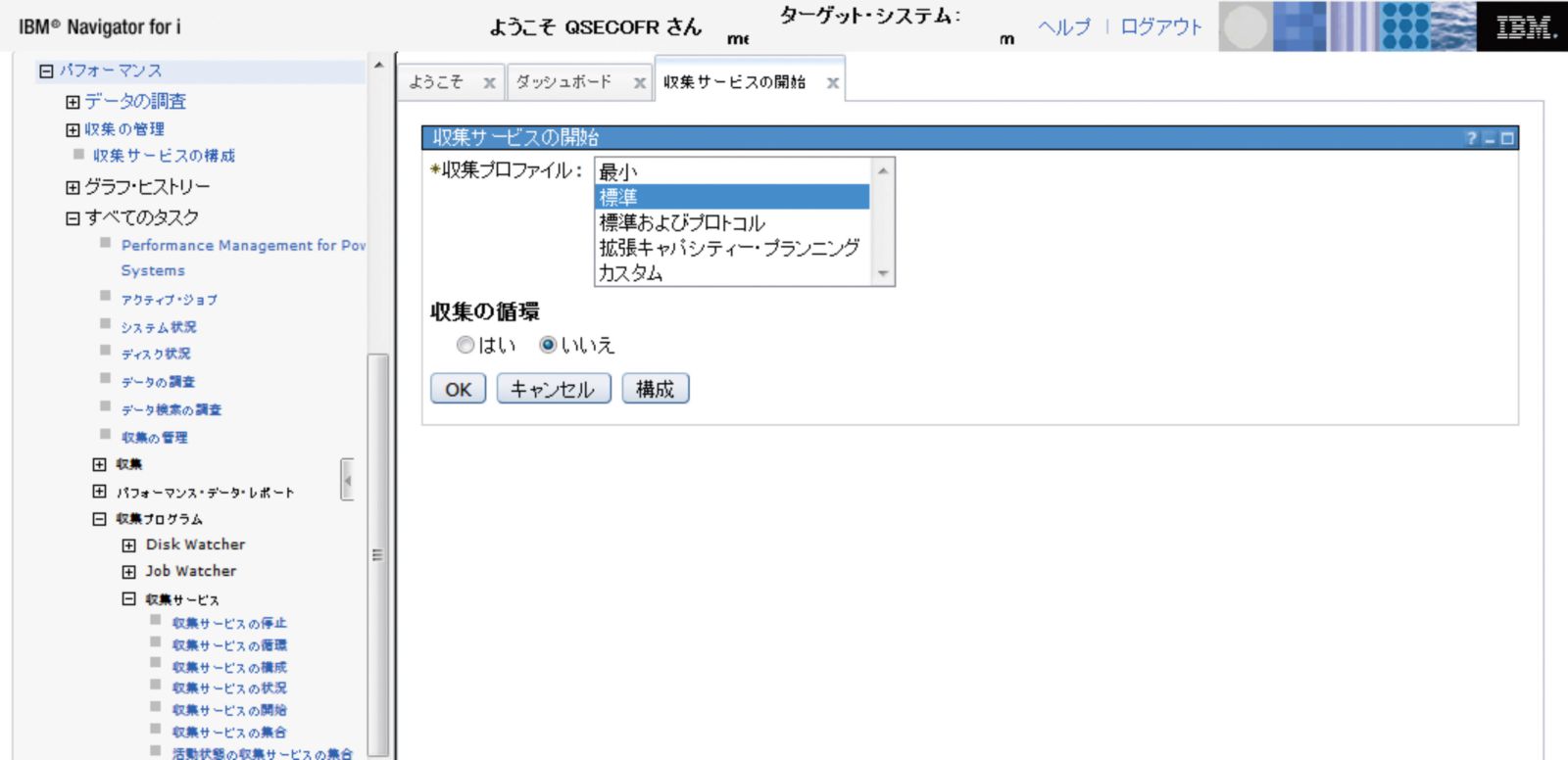
IBM iにおいてパフォーマンス・データの取得は、収集サービスという機能を使用する。収集サービスではCLコマンド、IBM Navigator for i、System iナビゲーターなど複数のインターフェースが提供されているが、ここでは、IBM Navigator for iの画面を図表2に示す。収集サービスのデータ取得の詳細については、IBM i Knowledge Center(http://bit.ly/trbl01)を参照されたい。
【図表2 画像をクリックすると拡大します】
次に取得したパフォーマンス・データを分析する。今回のように事前情報が少ない場合には段階を踏み、IBM Navigator for iの「ヘルス標識」で傾向を把握してから、システム全体におけるシステム資源の使用状況を調査するとわかりやすい。
図表3はIBM Navigator for iの「パフォーマンス」メニューで提供される「ヘルス標識」において「システム・リソース・ヘルス標識」を選択した画面である。「ヘルス標識」ではしきい値設定に応じた色分けにより、問題のあるシステム資源が一目でわかる。
【図表3 画像をクリックすると拡大します】
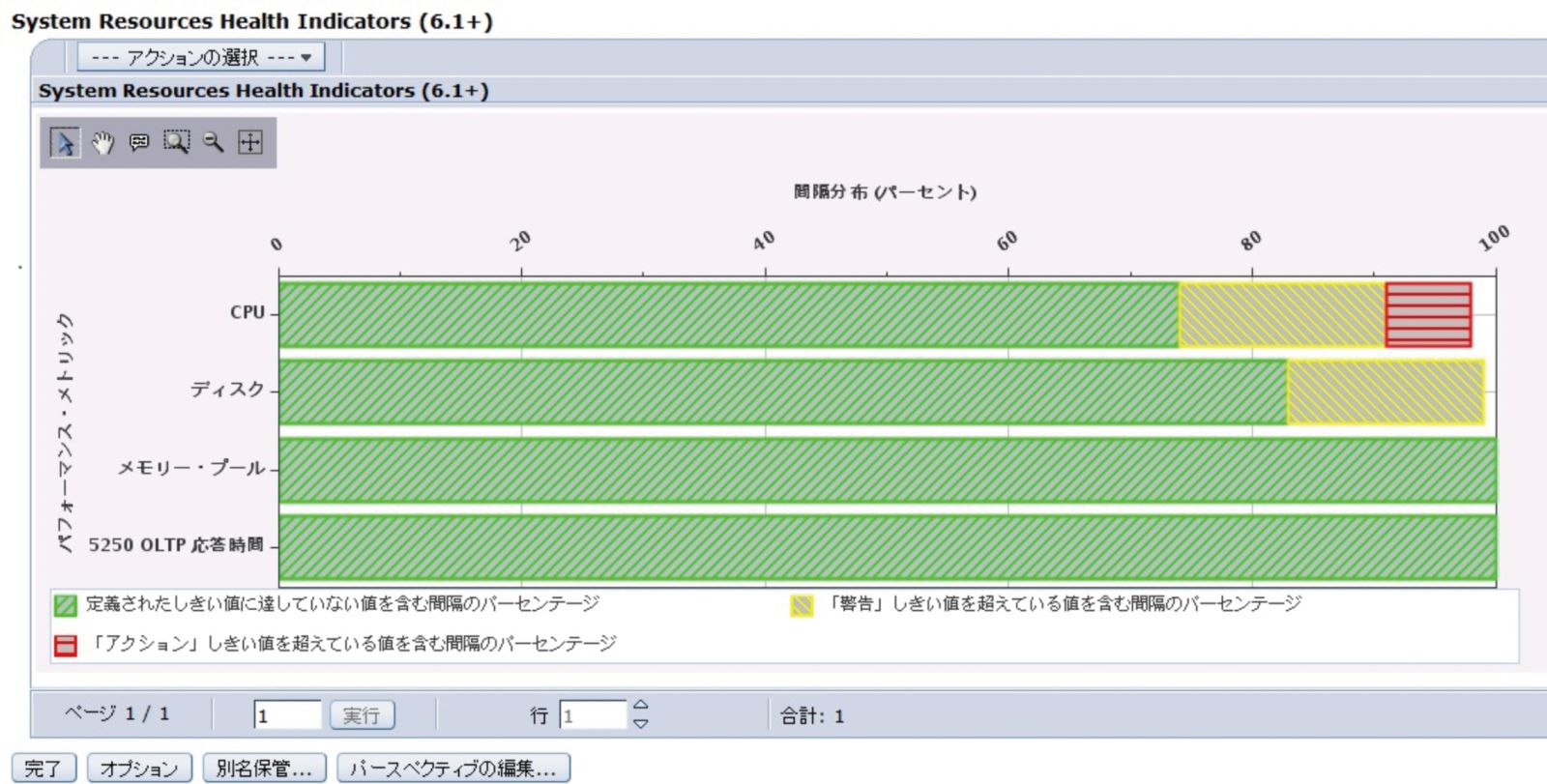
この例ではCPUにアクションが必要な赤色の箇所があり、優先して確認すべき資源であることがわかる。CPUについてさらなる調査が必要なため、「CPUヘルス標識」を選択してみる(図表4)。
【図表4 画像をクリックすると拡大します】

するとCPUキューイングとCPU使用率に問題がありそうなことがわかる。CPUキューイングとは、割り振られたCPU時間の間で、CPUを実際に利用できるまでの待ち時間を指す。この時間が大きいとCPU時間が有効に利用されず、CPU使用率は高いが、処理が進まないといった状態となる。
続いて、同じくIBM Navigator for iの「パフォーマンス」メニューで提供される「収集サービス」において「CPU使用率および待機の概要」を選択してみる(図表5)。待機の概要ではIBM iのスレッドやタスクがCPUで実行中でない場合に何を待機しているのかを確認できるため、当項目は収集サービスの分析で最初に確認すべき項目の1つと言える。
図表5を見ると、CPUキューイングが多発しており、CPU使用率は100%のまま推移している時間帯もあり全体としてCPU使用率が高い状態が続いていることがわかる。
【図表5 画像をクリックすると拡大します】
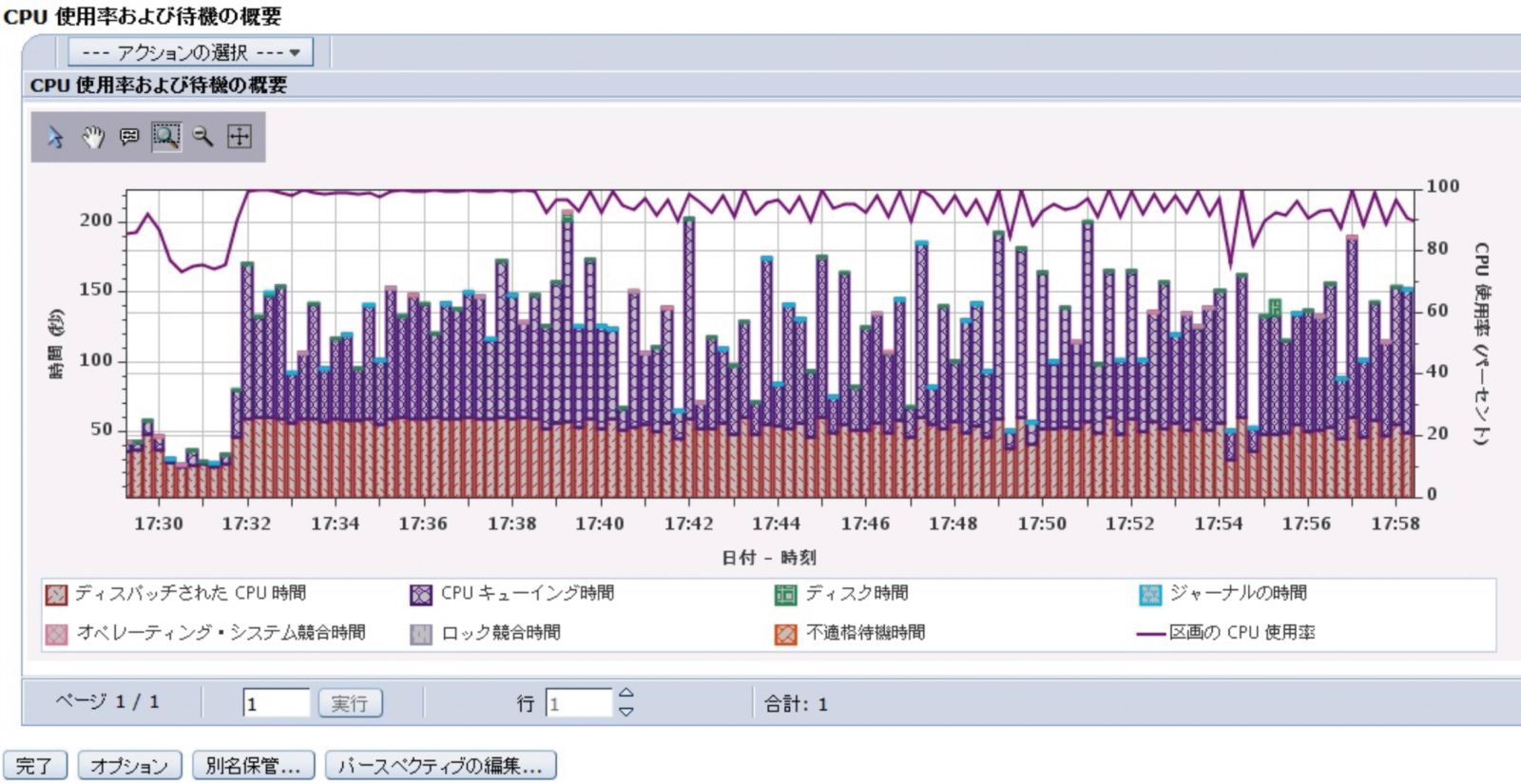
CPUキューイングはシステムに割り振られているCPU数が不足していると発生することが多い。そこで現行システムで割り振られているCPU数設定値を確認するとともに、CPU数の増強により、CPU数不足の状態を改善する必要がある。
(4)対処
CPUを追加し、アプリケーション稼働中に再度パフォーマンス・データを取得し、分析した結果が図表6である。
【図表6 画像をクリックすると拡大します】
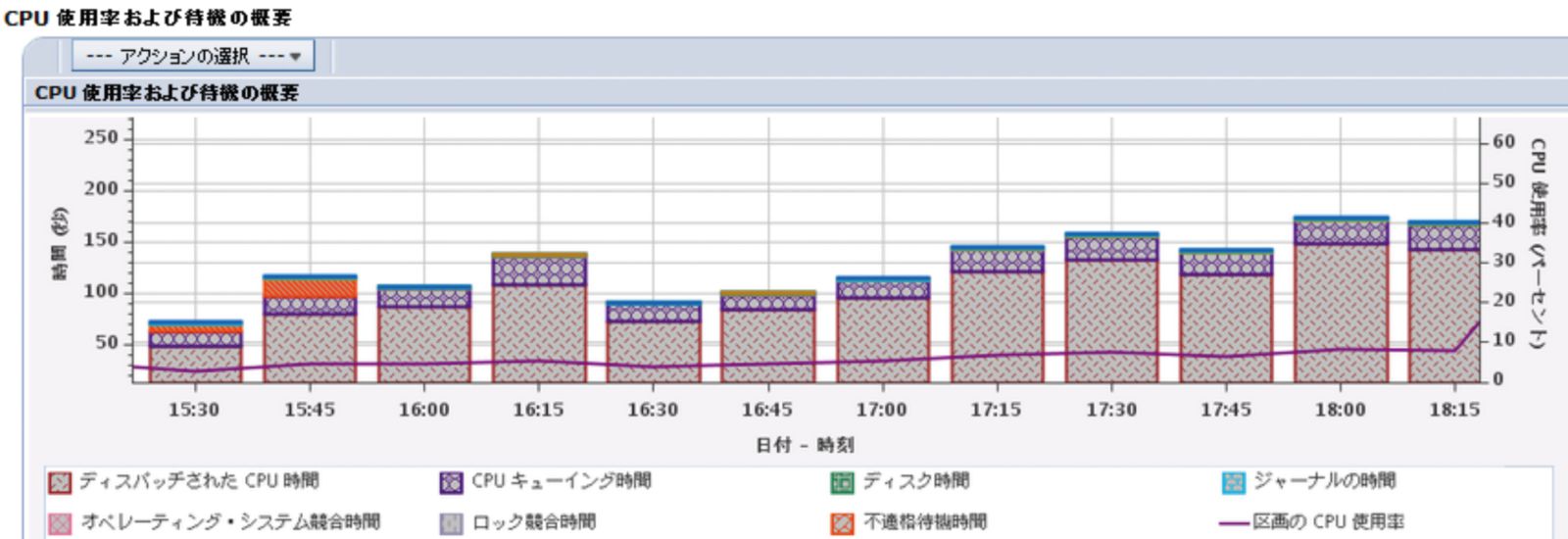
CPU増強後のシステムでは、CPU増強前システムで多発していたCPUキューイングが減り、CPU使用率も低くなり、ボトルネックが解消されたことがわかる。本来の目的であるアプリケーションの応答時間も、目標値に収めることができた。
(5)再発防止
今回は開発フェーズにおけるパフォーマンス・トラブルの例だったので、必須となる運用改善はない。ただし新規アプリケーションをリリースする際に懸念されるパフォーマンス・トラブルの対応策として本番運用環境におけるパフォーマンス・データの収集することは、予期せぬトラブル発生時に速やかな原因調査のための有効な手段であり、検討に値する。
*
システムを運用する以上、残念ながら何らかの障害は発生してしまう。発生する障害は多種多様であり、障害の規模や種類によって解決にかかる時間も異なるため、一概に解決策のガイドはできない。しかし各ステップで対応すべき基本的な作業は変わらないことを理解し、問題解決にあたっていただきたい。[松川 真由美]