text=杉本 篤 日本アイ・ビー・エム システムズ・エンジニアリング
重要データの宝庫であるIMS
歴史あるミドルウェアであるIMSは、その高い安定性から現在でも大規模システムの第一線で基幹業務を支えている。
IMSはデータベース管理とトランザクション管理の機能を併せ持つ製品だが、本稿では特に基幹業務の重要データが蓄積されているIMSデータベースに着目し、そのデータをオープンな環境で活用するためのソリューションを取り上げる。
その背景には、長年にわたり大規模システムの基幹業務を支えてきたIMSならではの事情がある。この用途ゆえにIMSには大量の有用なデータが蓄積されており、データ分析および活用への要請は非常に強い。
その一方、ミッションクリティカルな部分ゆえに、IMSシステムの構成には手を加えづらくなっている。またIMSは関係データベースの登場以前にデザインされた製品であり、階層型データベースという構造を取っている。データを活用するには、この独特のデータベース構造に対応する必要がある。
すなわち、「IMSシステム構成に手を加えず」「IMS階層型データベースに対応する」ことが、IMSデータ活用には求められている。また、すでにIMSデータベースのETLの仕組みを持っているシステムでも、データ鮮度に課題を抱えている場合も多い。さらに「リアルタイム性」も、抑えておく必要があるだろう。
本稿では、上記の3点を満たすソリューションとして、「IBM Data Virtualization Manager for z/OS(以下、DVM)」と「IBM InfoSphere Classic Change Data Capture for z/OS(以下、CCDC)」を扱う。
これらはともにIMS既存データ活用の最前線ソリューションでありながら、それぞれ全く異なるアプローチをとっている。
それぞれが何をするものなのか、何ができるのか、何が魅力なのか。そしてアプローチの異なる両者の選択検討に役立つような、使い分けの指針を以下に提示する。
IMSデータ活用を阻む3つの壁
まずIMSデータベースについて、ホスト外でのデータ活用を考慮しながらあらためて考えてみよう。
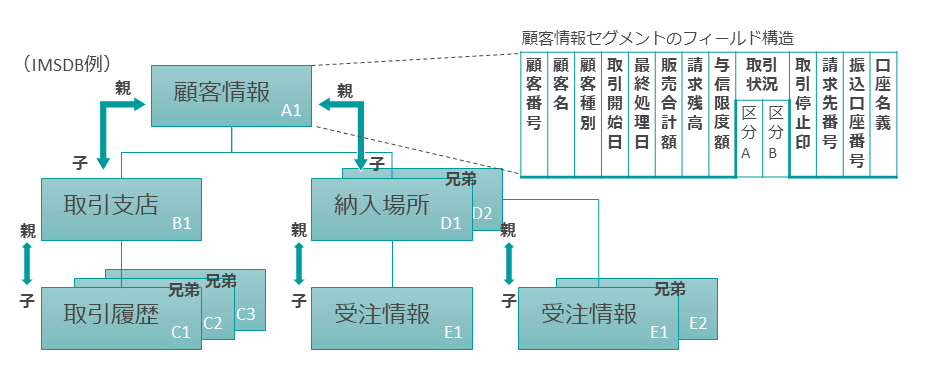
IMSデータベースの最大の特徴は、階層構造である。階層型データベースとして、前述したこのデータモデルではデータ間の関連は木構造によって表現され、エンティティ間には親子関係が存在する。
ルート・セグメントと呼ばれる一番上のエンティティにぶら下がる形で、その他のセグメント(=エンティティ)が存在し、各セグメントへ至るアクセスパスは一通りに限定される。
IMSデータベース上のデータをIMS外で活用するソリューションを用意しようとすると、以下のような「壁」が存在する。
❶ 階層構造の壁
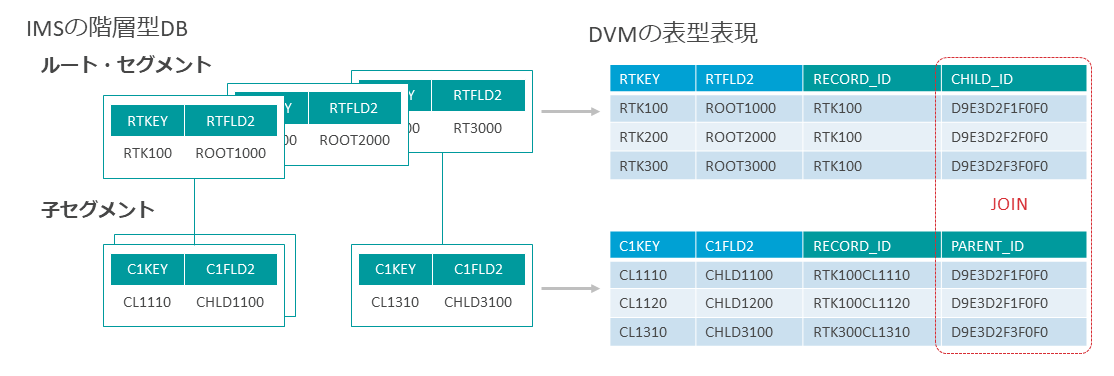
IMSデータベースの親子関係では、レコード同士の親子関係は物理的なポインタによって保持される。
たとえば図表1のような取引支店セグメントと取引履歴セグメントが親子関係にある構造で、支店Aレコードには支店Aの取引履歴、支店Bレコードには支店Bの取引履歴をぶら下げているとしよう。
この場合、必ずしも取引履歴レコードにどの支店の取引履歴であるかという情報を入れておく必要はない。なぜなら、その情報はどの支店レコードにぶら下がっているか(=どの支店レコードからポインタが張られているか)という親子関係によって自明だからだ。
これはIMSのデータベースアクセスAPIを使って、ポインタをたどってレコードを読む場合には便利だが、データ活用ソースとして一括で読み出す場合には注意が必要になる。
何に紐づくレコードか、という情報が物理的なポインタで保持されているため、レコードの中身だけを読んでもわからない場合があるからだ。
IMSのデータ活用では、この階層構造に合わせて最適化された情報の持ち方に対応する必要がある。
❷ 照会言語の壁
IMS階層型データベースでは、アクセスのための照会言語としてDL/Iという言語を使用している。
DL/Iは、階層構造やレコードの順序性といった階層型データベースならではの構造に対応した照会言語である。IMSの提供するアクセスAPIを使用してアプリケーションを開発する場合、このDL/Iないしはそれを内包したフレームワークの理解が必要となる。
なおIMSには、SQLによるIMSデータベースへのアクセスを可能にする機能も備えているが、小さくない規模のIMS構成変更が必要になるため、IMSシステム構成に手を加えないソリューションをテーマとする本稿では割愛する。これはIMS標準機能だけで使用可能なので、構成変更を行えるなら有力な選択肢となるだろう。
❸ 物理編成の壁
では、IMSのAPIを介さず、直接データセットを読むのはどうだろうか。しかしその場合も、IMS独自の多様な物理編成に対応する必要がある。
IMSはデータベースの物理編成を何種類か提供しており、網羅的な対応は容易ではない。前述のようなポインタによって管理される情報もあるので、読み出しのためのプログラムを新規に自作しようとすると工数は大きくなるだろう。
またデータセットを直接読むことは必然的にダーティー・リードになるため、前述した「リアルタイム性」を考えた際に問題を抱えることもあるだろう。
本稿で取り上げるDVMとCCDCは、これらの壁を乗り越えることのできるツールである。以下では、いよいよ各ソリューションについて検討する。
近くで見る:DVMでデータ仮想化
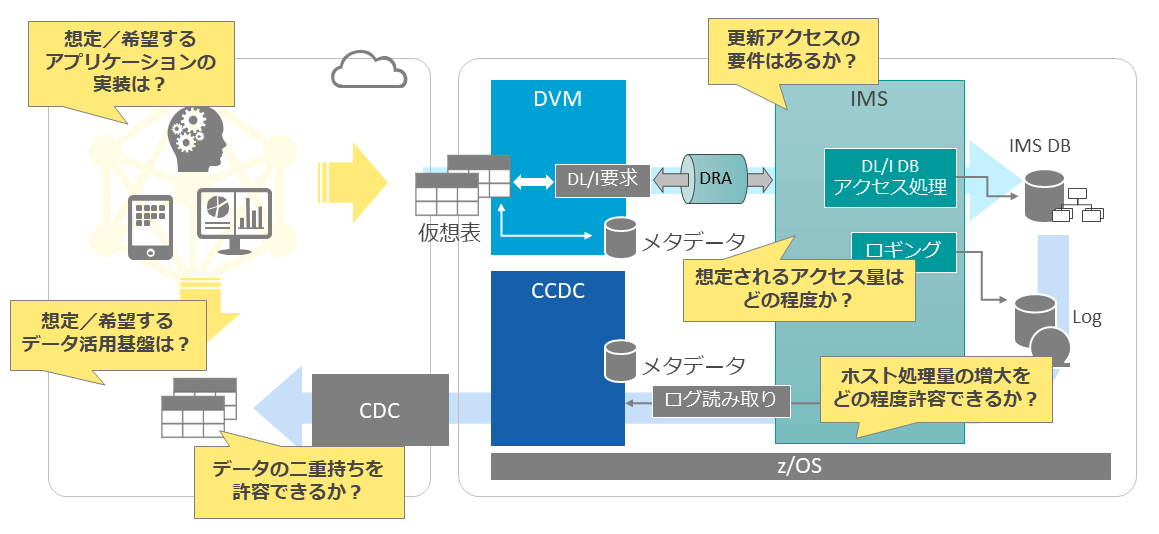
DVM(IBM Data Virtualization Manager for z/OS)はその名が示すように、「データ仮想化(Data Virtualization)」を行うツールである。
具体的には、z/OS上の多様なデータソース群(IMS階層型データベース、Db2 for z/OSの関係データベース、順次データセットやVSAMデータセット上のデータベース化されていないデータソース)を仮想上のテーブル構造にマッピングし、ユーザーに対して関係データベースのテーブルであるかのように見せる。
ユーザーは汎用的な参照言語であるSQLを使って、各種データソース群へアクセスできるようになり、前述した「照会言語の壁」を意識する必要がない。
DVMの提供する2種類のアクセス方法
DVM自体はデータソースを持たず、アクセス要求を受けるとDVMが元のデータソースに対してアクセスする。データソースがIMSの場合、以下のように2種類のアクセス方法が提供されている。
1つは、「DBCTLアクセス」と呼ばれるアクセスである。これはIMSに対してDVMがDRA接続し、DL/Iコールを発行してデータベースアクセスを行う。CICSがIMSデータベースにアクセスする時と同じ方式である。
もう1つは、「Directアクセス」と呼ばれるアクセスである。こちらはDBCTLアクセスと異なり、IMSのデータベースAPIを介することなく、DVMが直接データベース・データセット(VSAMファイル)を読む。当然その解釈はDVMが行い、ユーザーが「物理編成の壁」を意識する必要はない。
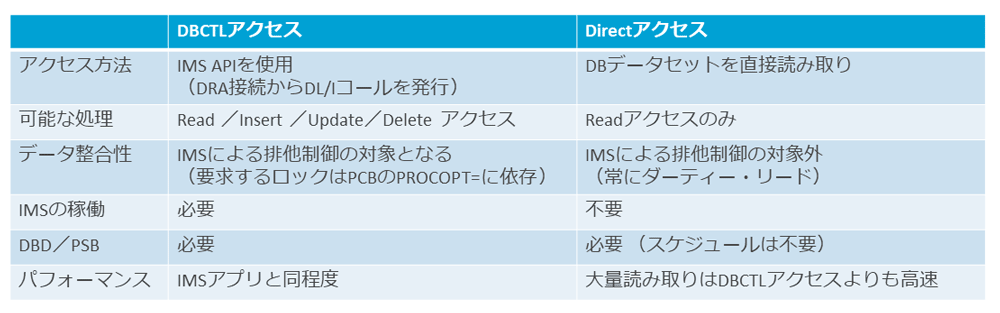
DBCTLアクセスは、DBMSとしてのIMSが提供するAPIに則ってアクセスするため、IMSによる排他制御の対象となる。読み取るデータは整合的なデータであり、また更新アクセスも行える。
一方、DirectアクセスはIMSを介さず、直接データセットを読み取ってDVMが解釈する。DBCTLアクセスにはIMSの稼働が必要なのに対し、DirectアクセスではIMSが稼働している必要はない。
ただし排他制御を受けられないため更新アクセスは行えず、読み取りは常にダーティー・リードとなる。
DBCTLアクセスのパフォーマンスは、概ね同じアクセスを行うIMSアプリと同程度である。大量のアクセスを行う場合は、相応にリソースを使用する。
DirectアクセスはDL/Iを介さず読み取るため、大量の読み取りを行う場合は概ねDBCTLよりも高いパフォーマンスを期待できる。
このようにDVMが提供する2種類のアクセス方法は、正反対の長所と短所を備える。
もちろん同じデータベースに対しても、場合に応じて双方のアクセスを使い分けることが可能となっている。更新アクセスやオンライン中の整合的な読み取りにはDBCTLアクセス、オンライン時間外の大量読み取りにはDirectアクセス、といった使い分けが考えられる。
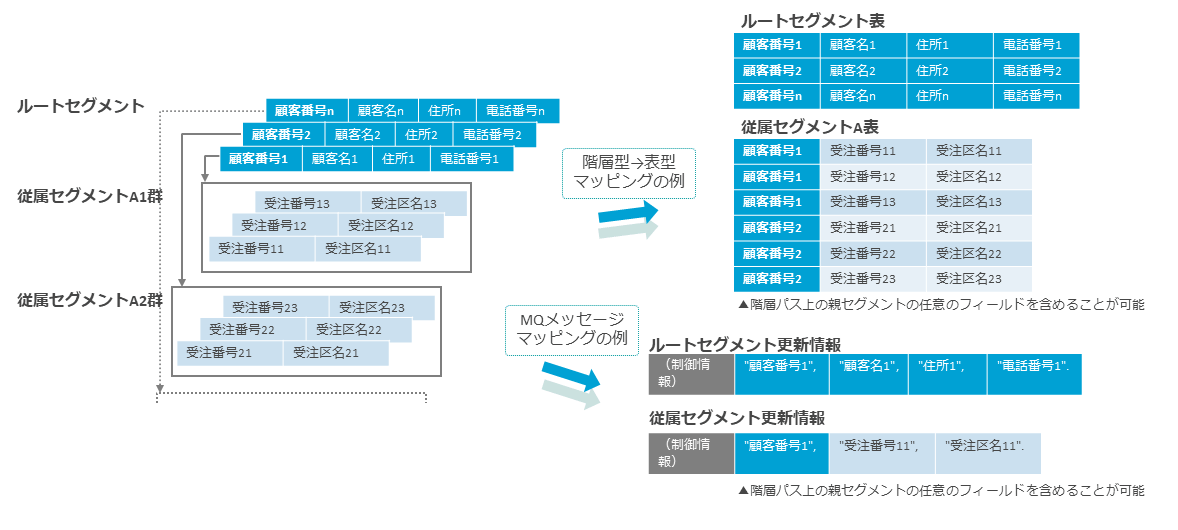
親子関係の再現
IMS階層型データベースを関係データベースに仮想化する場合、IMSのセグメントがテーブル(表)に対応する。
DVMでは仮想化元となるIMSデータベースのDBD(データベース定義)とPSB(プログラム定義)、そしてセグメントに対応したCOBOL Copy句やPL/I DECLARE文を入力としてGUIツールやJOBバッチで仮想表の定義を生成できる。
その際に、親子セグメントの紐づけを行うためのIDフィールドが自動的に生成される。
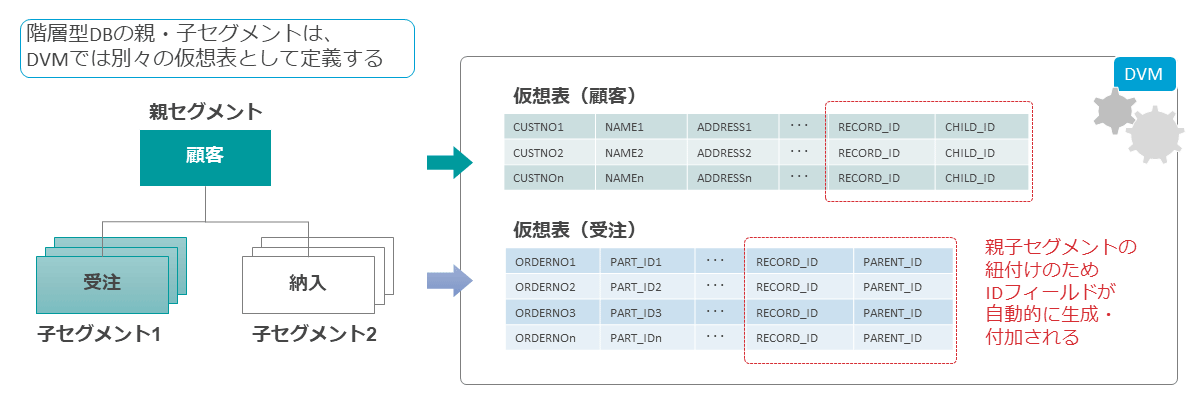
このIDフィールドが前述した「階層構造の壁」の攻略、すなわちレコードの中身を読むだけではわからない、物理ポインタで紐づけられた親子関係をデータ活用側で再現するためのカギとなる。
子セグメントを持つ親セグメント側では、CHILD_IDというカラムが生成され、そのレコードのキー値をHEX値で保持する。
そして子セグメントの側にはPARENT_IDというカラムが生成され、そのレコードが紐づく親レコードのキー値がHEX値で保持される。
つまり親子関係にある両レコードでは同じ値を持つことになり、これを使って両者を紐づけられる。
具体的には、親セグメントの仮想表と子セグメントの仮想表をCHILD_IDとPARENT_IDでJOINすれば、階層パス上に紐づけられた情報をひとつながりの形で取り出すことが可能になる。
パフォーマンス向上のテクニック
DVMを使用してIMSデータベース上のデータにアクセスする際の考慮点として、アクセスにはホストのリソースを使用することが挙げられる。
特にオンライン中に整合的なデータ読み取りを行うために必須となるDBCTLアクセスは、IMSのデータベースAPIを使用するため、大規模な参照を行うにはパフォーマンス影響への考慮が必要となる。
DVMにIMSのデータベースAPIを効率よく使用させるためのアプローチが存在するため、ここでベストプラクティスとして紹介したい。
DVMにSQLを発行する際に、仮想化元のセグメントにおけるキー・フィールドをWHERE句に”=”で指定すると、DVMはIMSに対してキー値で検索するようなDL/Iコール(修飾SSA)を生成し、最低限のアクセスだけを行う。
一方、キー以外の列にWHERE句を指定した場合、IMSに対しては全件アクセスを行うことになる。そのためアクセスしたいレコードのキー値が明らかな場合は、それを指定しアクセスを最低限に絞るべきである。
これは、子セグメントの仮想表にアクセスする場合にも応用できる。子セグメントの仮想表だけを参照するSQLでも、階層型データベースの特性として、アクセスは親セグメントに対しても行われる。
そこで、たとえアクセスしたいのが子セグメントだけであっても、親セグメントとJOINして親セグメントのキー値をWHERE句で指定すれば、DL/Iコール数を絞れる。アクセスしたい子セグメントのレコードがどの親に紐づいているか、あらかじめわかっている場合にはぜひ活用したいテクニックである。
DVMの特長と考慮点
DVMはデータの物理的な移動を行う必要なく、IMSにデータを置いたままリアルタイムなアクセスを可能にする、つまりIMSの「近くで見る」アプローチである。
IMS階層型データベースを関係データベースに仮想化でき、汎用的なデータベース言語であるSQLを用いたアクセスを可能にする。
DBCTLアクセスはIMSのデータベースAPIを使用するため、参照だけでなく更新アクセスも可能になる。
それに対して、DirectアクセスはAPIを使用せず、大量読み取りのパフォーマンス面で優れる。
この両者を状況に応じて使い分けられるのが、DVMの強みである。また今回は触れなかったが、VSAMやDb2等のホスト上の他のデータソースもカバーできるため、これらを統合した単一のインターフェースとしてDVMを立てることも考えられるだろう。
一方、DVMそのものがホストで稼働し、特にDBCTLアクセスはIMSアプリケーション相当の負荷が発生する。またDVMクライアント・アプリケーション開発には、JOINによる親子関係の再現やDL/Iコール数を絞るための工夫など、DVMによるIMSアクセスを理解することが望まれる。
DVMを検討する際には、これらを考慮する必要があるだろう。
遠くで見る:CCDCでレプリケーション
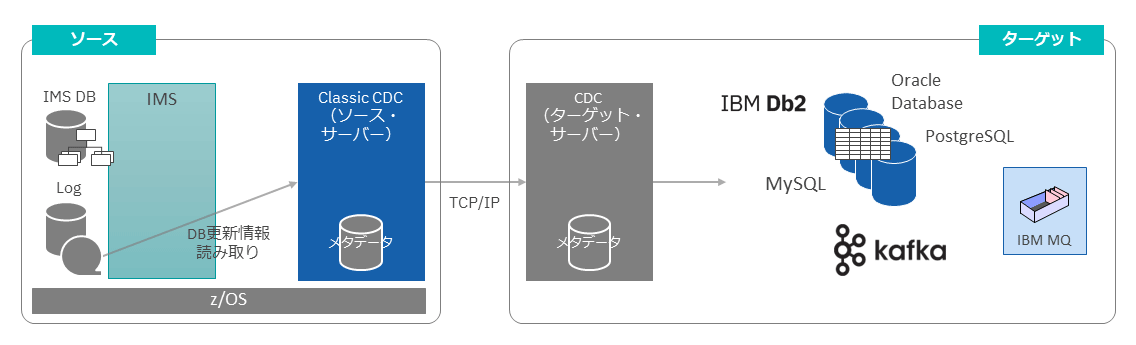
CCDC(IBM InfoSphere Classic Change Data Capture for z/OS)は、データ・レプリケーションを実行するCDCファミリー製品である。
レプリケーションのイメージ
データソースとなるIMSデータベースをリアルタイムに再現するレプリカをどこかに作成し、それをデータ活用のソースにする、というのがレプリケーションを使ったデータ活用の大まかなイメージになる。
DVMとの最大の違いは、データの移動を行うことである。データ活用のアクセス先はIMSデータベースでもなければ、そのデータセットでもないため、「照会言語の壁」「物理編成の壁」は存在しない。
レプリケーションのソースとなるのが、IMSデータベースの更新時にIMSが書く特殊な更新ログである。
CCDCがIMSオンライン・ログをキャプチャし、データベース更新をリアルタイムで捕捉・送信することで、レプリカに反映する。これによって、レプリカをほぼ最新の状態にアップデートし続ける。
レプリケーションとマッピング
CCDCもDVMと同様、IMS側の構成変更をほとんど必要としない。ただし、前述した特殊な更新ログを出力させる設定は必要になる。
レプリケーション対象データベースの変更データおよびレプリケーションに必要な情報を含むX’99’ログは、対象データベースのDBD定義を編集することで書き出されるようになる。

参考 X’99’ログとは
DL/I更新コールごとに書かれ、基本的に以下の情報を含む (情報量はEXIT=パラメーター指定値に依存して異なる)
更新前情報:オフセット/長さ/更新データ (圧縮あり)
更新後情報:フルセグメント・イメージ (圧縮あり)
CCDCもDVMと同様、IMSデータベースのセグメントを関係データベースの表に見立ててマッピングする。そしてこのマッピングのための情報としてフィールド名、データ型、オフセット開始位置、データ長などを含むメタデータをCCDC内に保持する。
このマッピングは、CCDCがIMS更新情報をMQメッセージとして送信するオプションでも用いられ、データ区切りやデータ型はその情報に従う。
データベースおよびセグメントに対するメタデータの生成・登録は、CCDCに付属のツールで実行でき、こちらもDBDとセグメントに対応したCOBOL Copy句やPL/I DECLARE文を入力として生成できる。
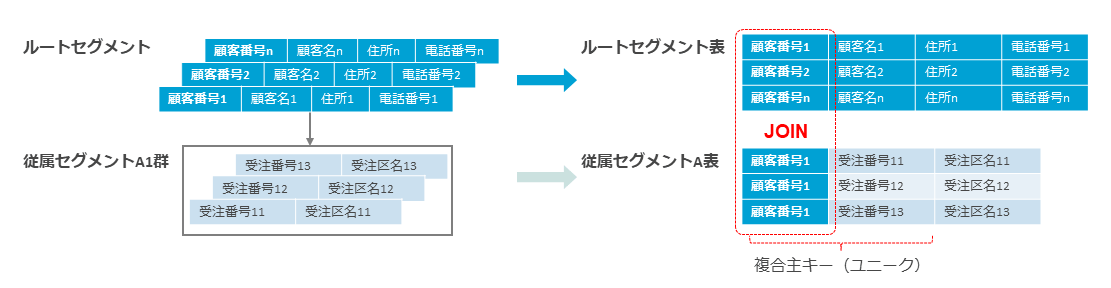
CCDCでは、子セグメントと対応する表に親セグメント表の任意の列を含めることが可能である。
これによって親セグメント表のキー値を含めることで、DVMのように親子セグメント表をJOINできる。
「単に、どの親にぶら下がる子セグメントかを判別さえできればよい」という状況なら、子セグメント表に含めた親セグメント表のキー列を見るだけで、JOINすら不要という状況もしばしばあるだろう。
また親セグメント表のキー列と子セグメント表のキー列の2列を使って、子セグメント表の主キーをユニーク化することもできる(IMSはたとえユニークキー制約を設けていても、異なる親にぶら下がる子同士ではキーの重複が許される。内部的に子セグメントは階層パス上の全キーを連結した「連結キー」を持つと解釈されるため)。
ただし、親セグメント表側で更新が行われても、子セグメント表に含まれた列にその更新はレプリケーションされない。そのため親セグメント表のキー列以外の列を子セグメント表に含める場合は、更新が発生しないかに注意する必要がある。
セグメントの更新に言及したので、セグメントの削除が気になる人もいるかもしれない。
IMS階層データベースでは、あるセグメントでレコードの削除が発生すると、そのレコードにぶら下がる子セグメント群も削除される。
このように、「親セグメントが削除されたことによる削除」でも、X’99’ログの書き出しが行われるようDBD定義で設定でき、親セグメントの削除に伴う子セグメントのカスケード削除もレプリケーションされるようになっている。
マルチレイアウトの再現
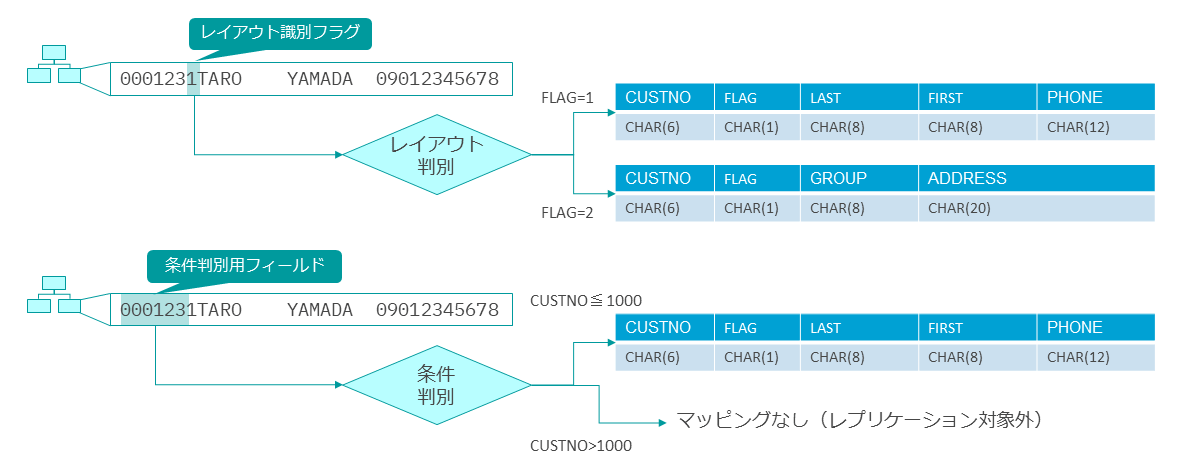
IMSは、データ区切りとデータ型の定義をアプリ側で持つのが一般的である。これを利用し、レコード中に持たせた識別子によって、読み取りに使うレイアウトを変えるようなマルチレイアウト構成がしばしば用いられている。
このようなデータをレプリケーションする場合は、レイアウトそれぞれに対してマッピングを行い、レプリケーション時にどのマッピングを使用するかをレコードごとに判断させられる。
レコードごとに特定箇所を参照して仕分けを行う機能は、レプリケーション対象レコードの選択にも使用できる。たとえば、「○番台の店番は研修用のダミーデータ」等のように、特定のフィールドの値によってレプリケーションが必要ないレコードを判別できる場合、CCDCの機能で選別することが可能である。
CCDCの特長と考慮点
CCDCによるレプリケーションは、IMSデータベースのレプリカを他プラットフォーム上に作成してデータソースとする、いわばIMSから「遠くで見る」アプローチである。多様なターゲット・コンポーネントが提供されており、用途に応じた柔軟な選択が可能である。
このアプローチの最大の美点は、ホストに負担をかけずに検索や集計処理が可能なことであろう。
アクセスはレプリケーション・ターゲットに対して発生するため、DVMと異なり、アクセスのたびにホストのリソースを使用することがない。いわゆるCQRS(Command Query Responsibility Segregation:コマンドクエリ責務分離)を実現することが可能になる。
ただしホスト側にも、X’99’ログ書き出しのオーバーヘッドが生じることは考慮が必要である。
多くのデータベース、多くの更新情報をレプリケーションしようとすると、それだけログ書き出しのオーバーヘッドが大きくなる。またレプリケーションのソースはオンライン・ログであるため、データベースのオフライン更新の伝播には別途検討が必要になる。
またCCDCによるレプリケーションを実装する時、必ず考慮すべきなのが初期データ移行である。
ターゲットがDb2やOracle DB、Kafka等の場合はフル・リフレッシュ機能(IMSにDRA接続してDBの全件読み取りを行い、ターゲット側へ送信する機能)を利用することも可能だが、データ量が多い場合は長時間を要する。そのため先行事例では、アンロード/リロードでデータを移行するバッチ・プログラムを別途準備していることが多い。
◎CDCファミリーでサポートされるソースおよびターゲット
-IBM InfoSphere Data Replication documentation 製品オンライン・マニュアル
近くで見るか、遠くで見るか?
DVMとCCDCの使い分け
大きく異なるアプローチをとるDVMとCCDCであるが、「IMSのデータをデータ活用の文脈に載せるなら」という観点および筆者のインフラ技術者としての視点から、検討のポイントとなる各要素を次の表にまとめた。
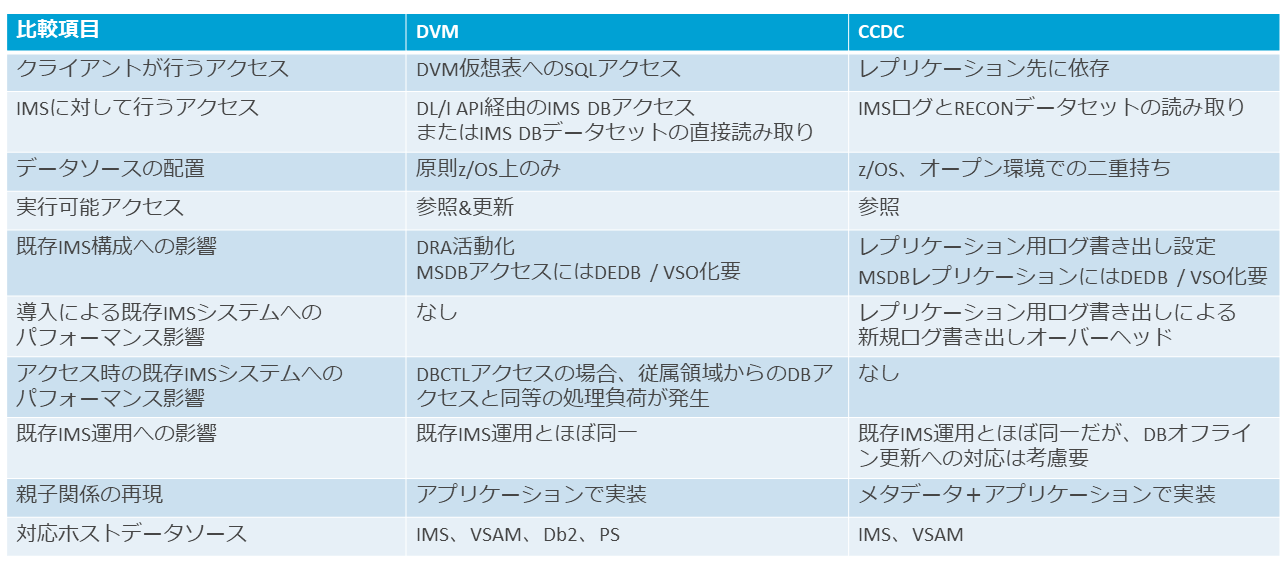
ここでわかるように、最大の違いはデータの所在であろう。
DVMはホストIMSにデータを置いたままアクセスするため、新規にデータストアを設ける必要がない。これに対してCCDCはレプリケーション先が必要になるが、その選択肢が多く、拡張性も高い。まずデータの二重持ちを許容できるか確認することが、DVMもしくはCCDCを検討する第一歩となる。
DVMによるDBCTLアクセスの場合は、IMSにアクセス負荷がかかり、場合によってはロック競合も発生する。これに対してCCDCによるレプリケーションは、X’99’ログの書き出しが必要となり、オーバーヘッドが発生する。
DVMは外部からのアクセス時に発生する負荷、CCDCはIMS側での更新発生時の負荷なので一概には比較しがたいが、一般的にはDVMのほうがホストへの負荷は大きいと考えられる。
DVMを検討する際には、想定されるデータ活用のためのアクセスがいつ、どの程度の規模で発生するか、ホスト処理量の増大をどの程度許容できるかがポイントになるだろう。
DVMのアクセス負荷の見積もりは難しいが、基本的にはIMSアプリケーションから行うデータベースアクセスと同程度と考えて差し支えない。
DVMとCCDCはともに、IMSデータの活用に伴う3つの壁をツールの機能によって超えられるソリューションであり、それぞれ異なるアプローチを用いる選択肢であることが理解できたことと思う。
冒頭に述べたように、IMSデータベースは基幹中の基幹データが生き続けている重要データの宝庫である。そのデータを活用することの意味は非常に大きく、まさに時代の求めるところであろう。
勘所の見極めが難しいテーマであるが、インフラ観点の検討において本稿が助けとなれば幸いである。