Text=鈴木 翔大 日本アイ・ビー・エム システムズ・エンジニアリング
MLOpsとは
昨今AIのビジネスにおける活用範囲は拡大している。AIがビジネスへ活用され始めた過渡期においては、機械学習モデルの開発で手一杯となり、運用まで考慮できていないケースも多々見られた。しかし、活用範囲が拡大し知見が充実する中で、従来のソフトウェア開発と同様に、開発と運用を統合的に考える動きが広まってきている。これをMLOpsと呼ぶ。MLOpsとは、ML(Machine Learning:機械学習) + DevOpsの略語であり、機械学習モデルがデータやロジックによって変化することに対応するために、モデルを定期的に再学習させたり、機械学習モデルを利用したアプリケーションに動的にデプロイしたりする、仕組みや考え方の総称である。
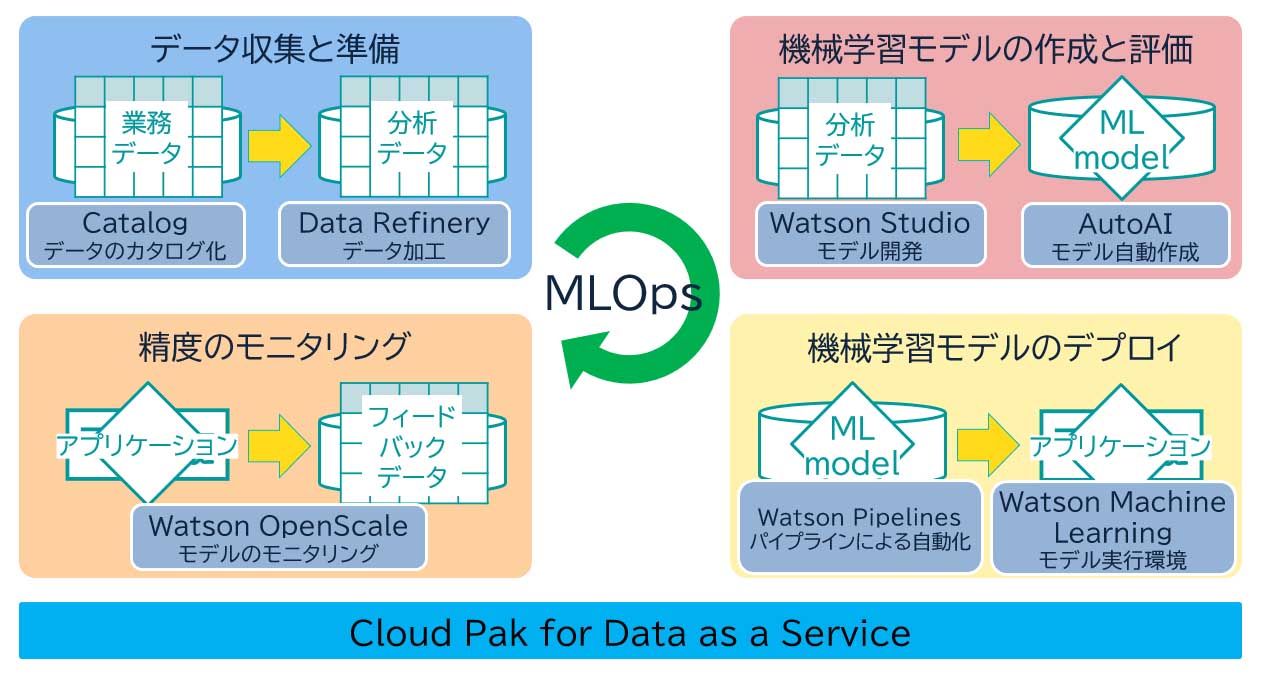
たとえば、住宅ローンなどのローン審査を手助けする機械学習モデルを作成したとしても、時代の流れに対応するために、定期的に精度を監視し、必要に応じて新しいデータを随時取り込んで新たなモデルを更新し続けなくてはならない。図表1にローン審査システムにおけるMLOpsの運用について記載する。
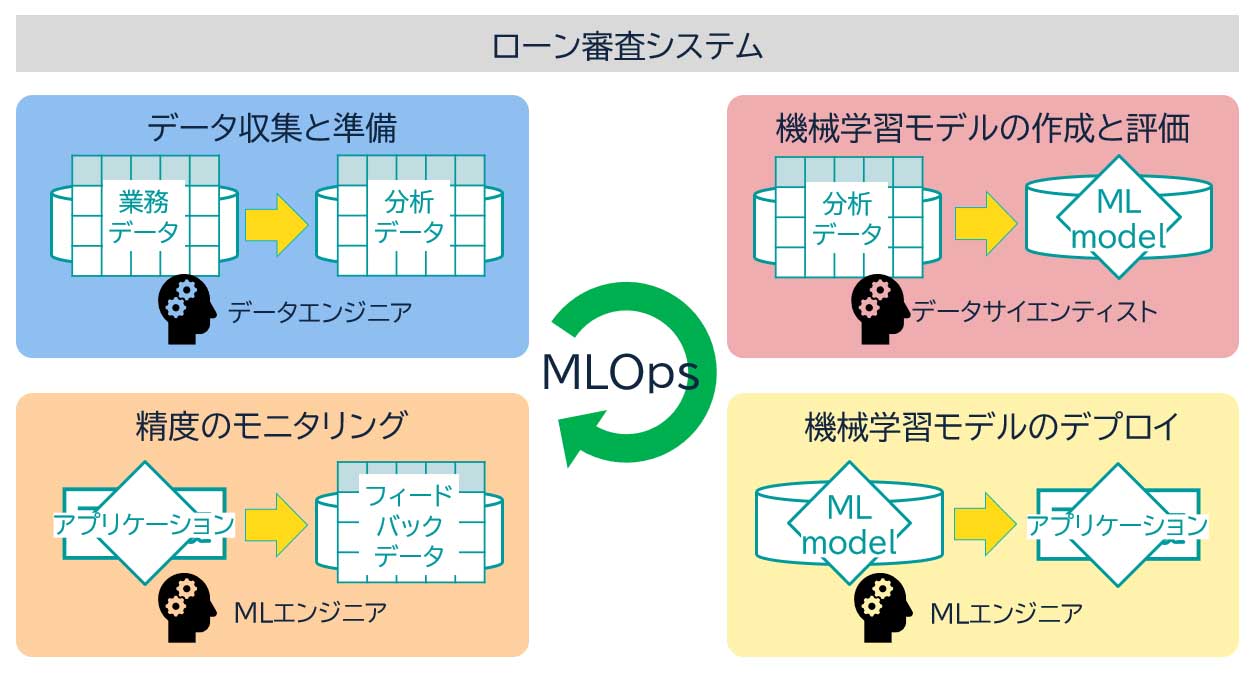
●データ収集と準備:データ・エンジニアは、融資可否を判断するための信用情報や雇用情報といった業務データを収集し、分析可能な形式に変換する。
●機械学習モデルの作成と評価:データサイエンティストは、データを分析し実験・評価して最適なモデルを作成する。
●機械学習モデルのデプロイ:MLエンジニアは、作成されたモデルを、アプリケーションで利用できるようにデプロイし、テストする。
●精度のモニタリング: MLエンジニアは、モデルの性能が劣化していないか監視を行い、アプリケーションを利用したビジネス・ユーザーからのフィードバック・データを元にモデルを評価する。
このシステムからのフィードバック・データとそのモデルの評価を基に、データ・エンジニアとデータサイエンティストはさらに分析を行い、継続的にモデルを更新し続ける仕組みを回していくことがMLOpsによる運用となる。
責任あるAIについて
ローン審査システムの例では、モデルの性能が劣化していないか監視を行う精度のモニタリングをMLOpsの1つの要件として説明した。
ここでモニタリングする精度には、正答率といったモデルの品質だけでなく、モデルのバイアスが排除されていることや、モデルの判定に透明性があり説明可能性があることも強く求められている。このようなモデルは「責任あるAI」や「信頼できるAI」と呼ばれている。IBMでは責任あるAIを実現するための分野横断的で多角的なアプローチとして、以下を公開している。
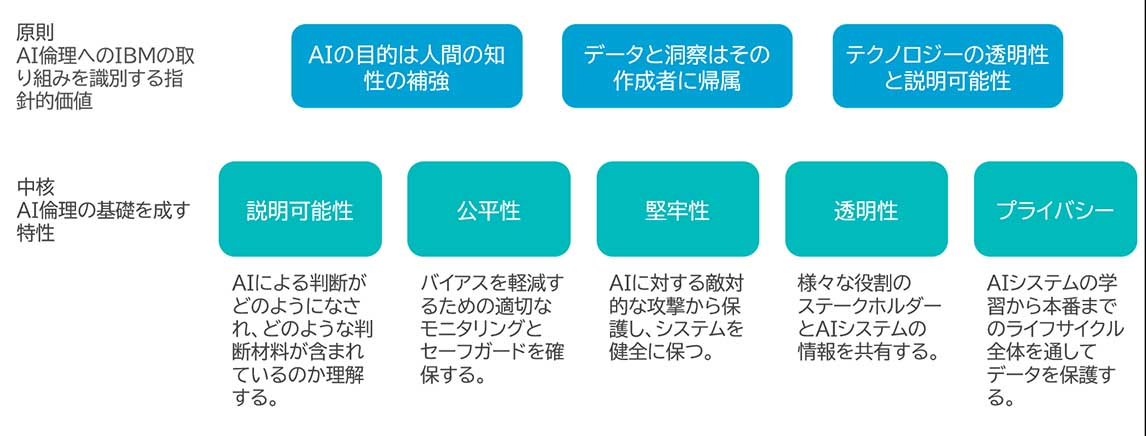
責任あるAIにおいて、本番リリース後のモデルのパフォーマンスと状況を継続的に把握し、公平性が保てていることや説明可能性があることを監視し続けることが重要である。MLOpsではこれらを継続的に監視するためのフレームワークを提供し、機械学習システム全体の信頼性を高めることができる。
MLOpsを実現する技術要素
MLOpsをオープンソース・ソフトウェア(OSS)で実現しようとした場合、実験管理ツールとしてのMLFlowや、パイプライン管理を実現するKubeflowなどを組み合わせることがある。また、クラウド・ベンダー各社も力を入れてきており、Microsoft Azure Machine Learning[5]、Google Vertex AI[6]、AWS Amazon SageMaker[7]などでMLOps機能が充実してきている。
IBMでは、次に説明するCloud Pak for Dataおよびサービスとして提供されるCloud Pak for Data as a Serviceを活用することで、MLOps基盤を構築することができる。
Cloud Pak for Dataとは
Cloud Pak for Dataとは、IBMが提供するデータ管理と分析のための統合プラットフォームである。このプラットフォームでは、データの収集、加工、分析、可視化、モデルの開発・デプロイなど、データ駆動型のビジネスやAIプロジェクトをサポートする。
これらのCloud Pak for Dataの機能をIBM Cloud上で提供されたフルマネージドサービスとして利用可能としたのがCloud Pak for Data as a Serviceである。Cloud Pak for Data as a Serviceでは、インフラの運用管理なしに、使用量ベースの課金方式で即座にIBM Cloud Pak for Dataを利用できるため、スモールスタートが可能となる。
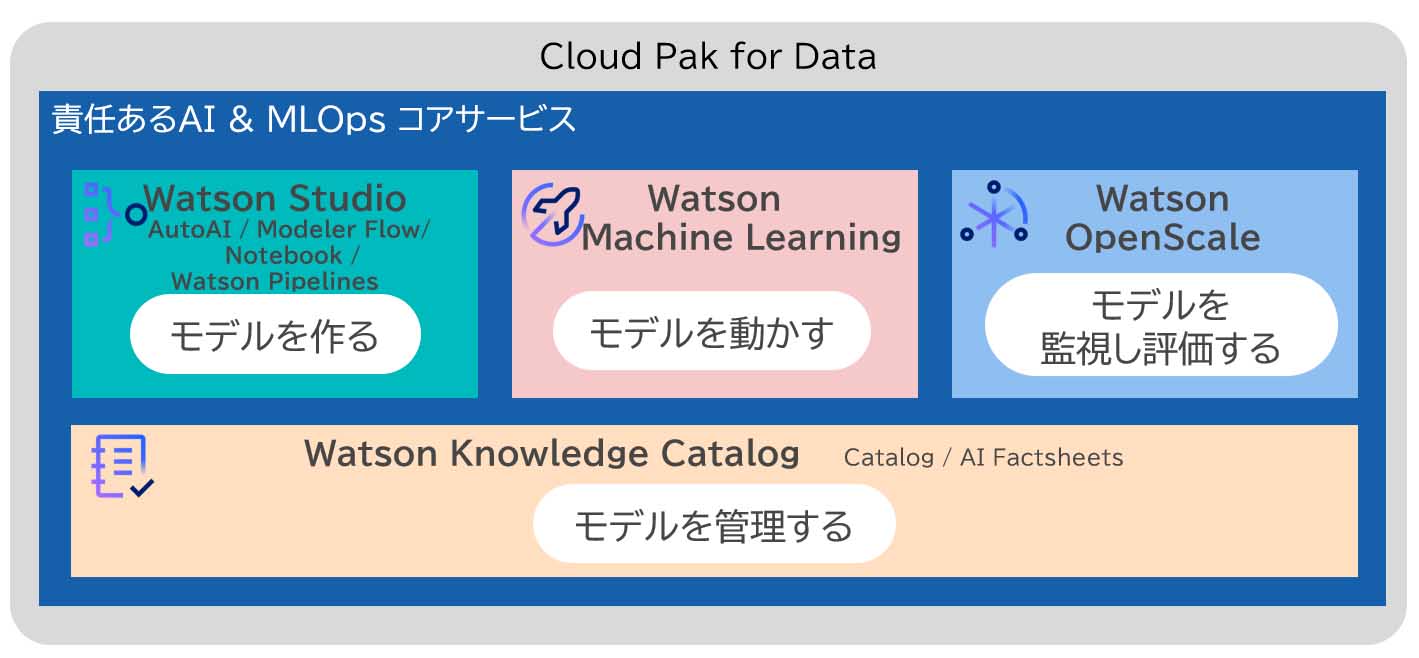
Cloud Pak for Data as a Serviceでのモデル開発・稼働
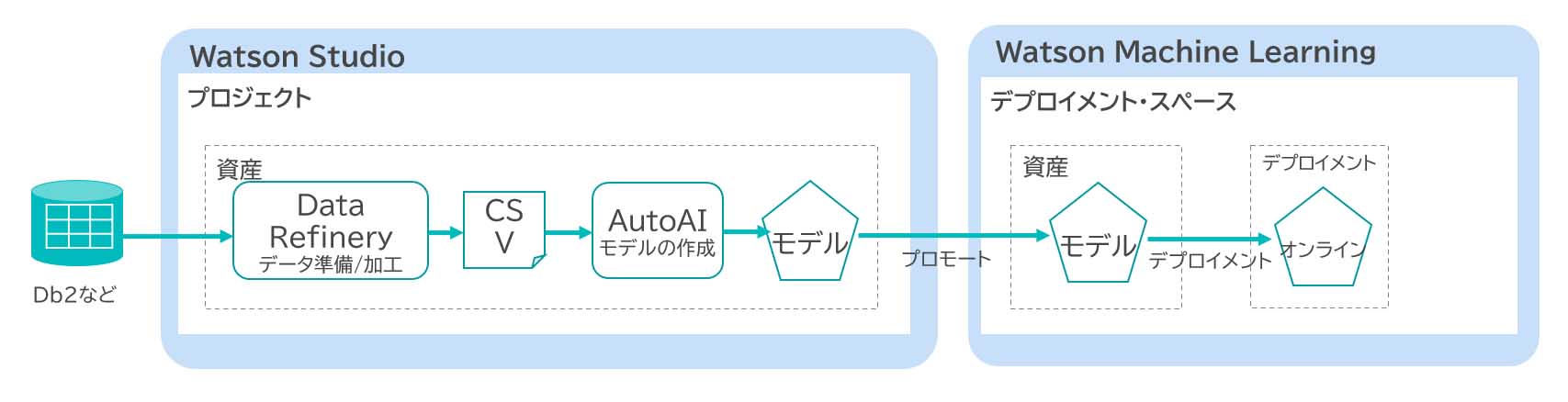
Cloud Pak for Data as a ServiceでMLOpsを実践する前に、モデルを開発し、稼働するまでの流れを確認する。モデルの開発と稼働には、「①データ収集と準備」、「②機械学習モデルの作成と評価」、「③機械学習モデルのデプロイ」の作業が必要である。これらの作業を行うためには、Cloud Pak for Data as a Service に含まれるWatson StudioやWatson Machine Learningを利用する。
Watson Studio
機械学習モデルを開発するための統合機械学習プラットフォームである。
「①データ取得と準備」を行うData Refineryや、「②機械学習モデルの作成と評価」をGUIで簡単に行えるAutoAIといったサービスは、Watson Studioに含まれる。そのほかにも、Jupyter NotebookのようなUIで、プログラミング言語でデータ分析や機械学習モデルの学習を行うことのできるNotebook、これらの処理を一連の流れとして自動化できるWatson Pipelinesなどが含まれている。
Data Refinery
機械学習モデルにおける「①データ取得と準備」の自動化ツールである。
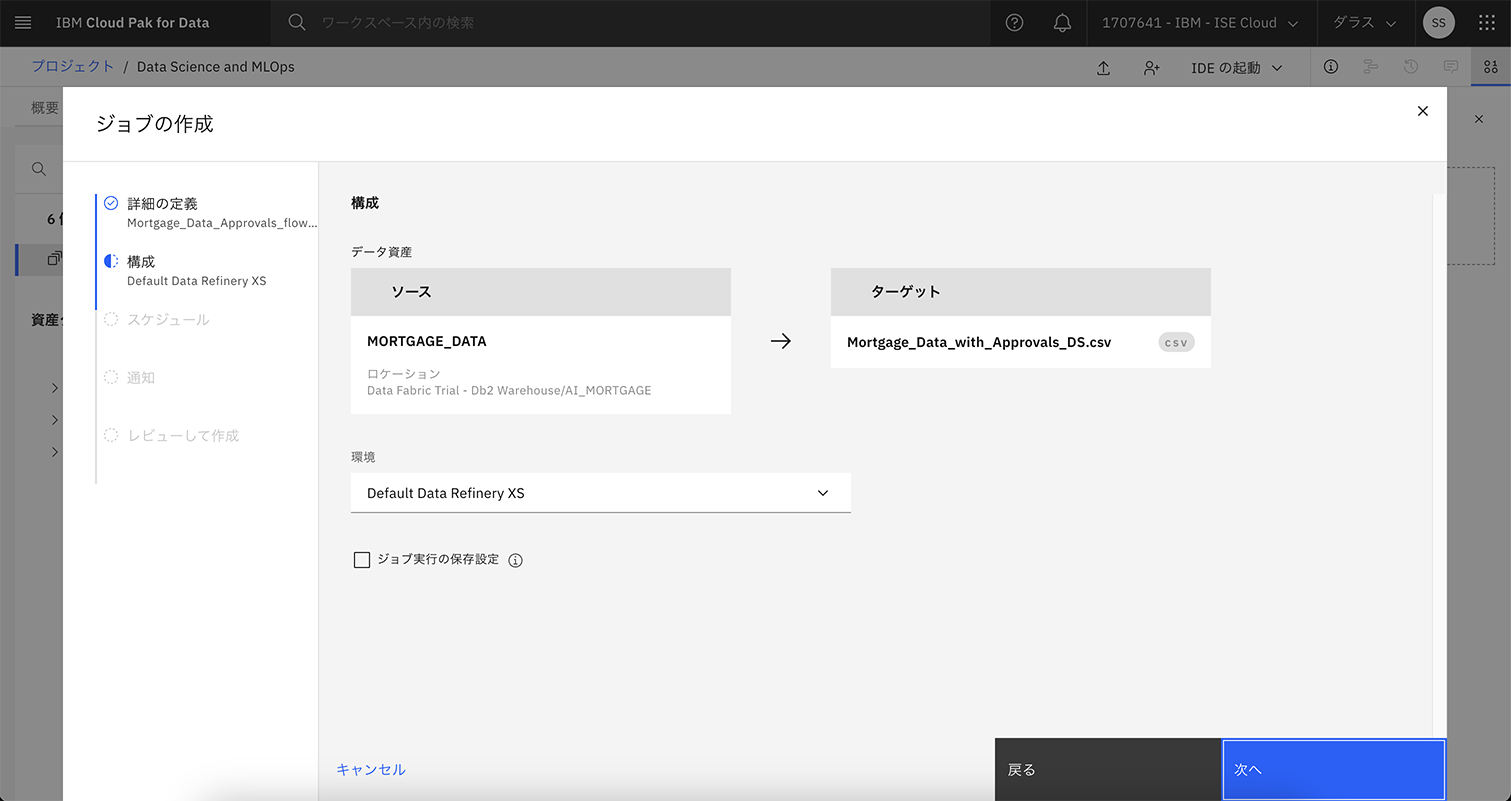
ICOS(IBM Cloud Object Storage)などのオブジェクトストレージや、Db2などのRDBMSからのデータを取得し、取得したデータの加工を行ったのち、csvなどの形式でデータを出力することができる。ここで出力したcsvなどのデータを、次のモデル学習で活用する。図表5は、Data Refineryでデータソースや出力先ファイルを設定する画面である。
AutoAI
「②機械学習モデルの作成と評価」の自動化ツールである。
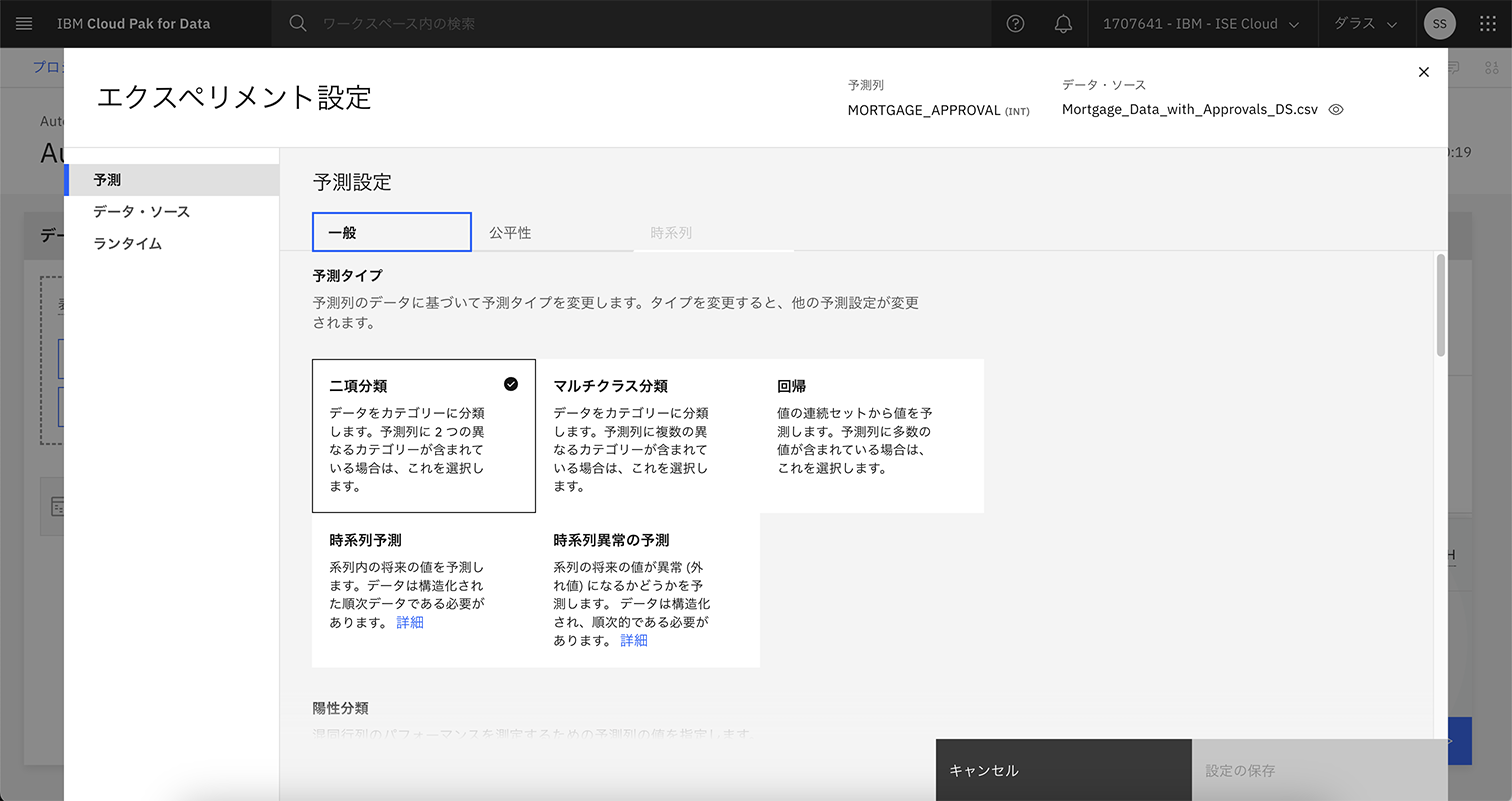
AutoAIではGUIで、モデルが予測する項目や予測タイプや最適化メトリクスなどを設定可能であり、機械学習モデルの学習に詳しくないユーザーでも簡単にモデルを作成できる。図表6は、モデルが二項分離、マルチクラス分離、回帰など、どのような予測を行うか設定する画面である。
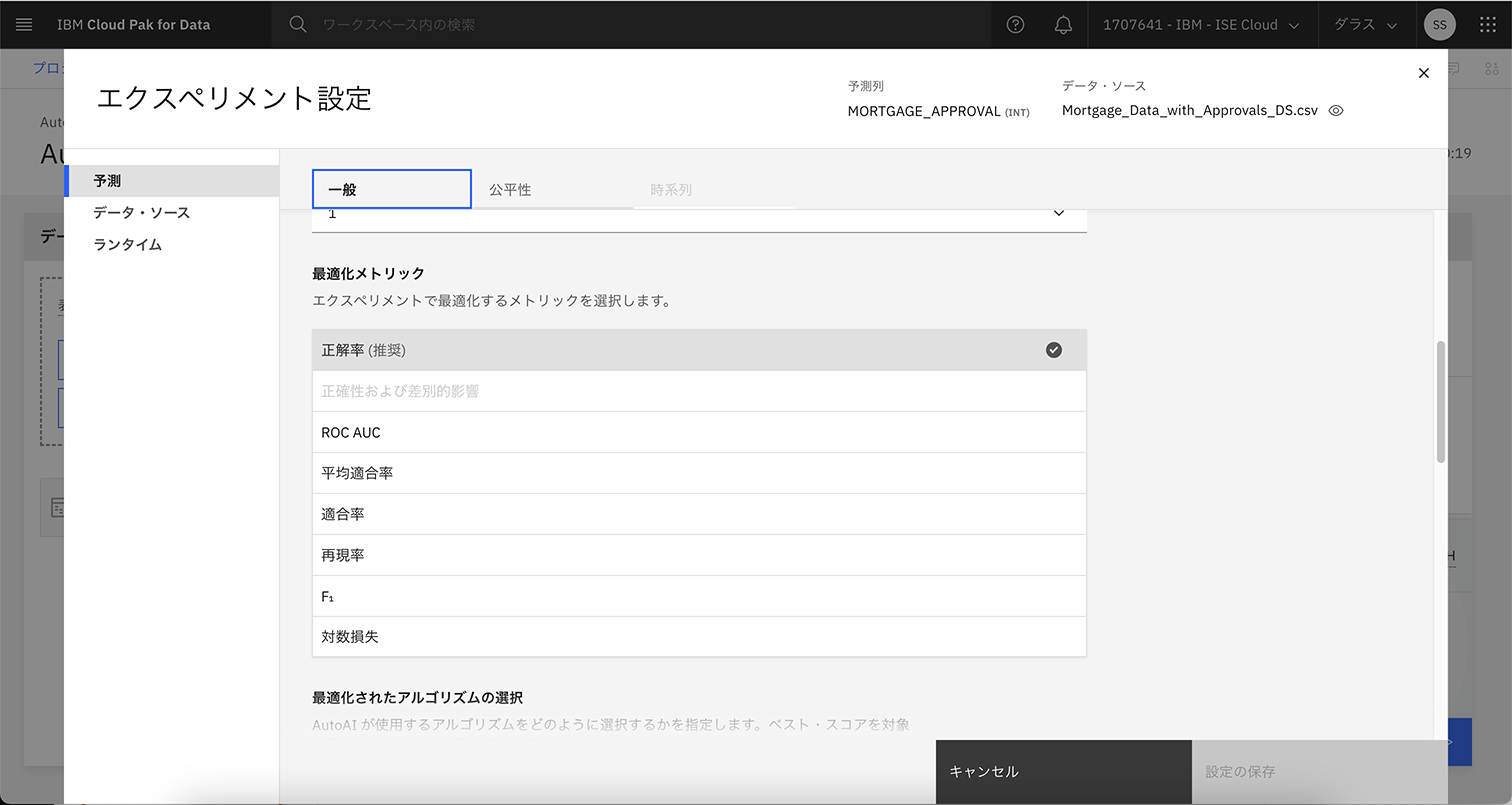
次に、図表7は、モデルが正解率やROC AUC(ROC(Receiver Operating Characteristic)曲線下の面積)などの最適化メトリクスを設定する画面である。最適化メトリクスとはモデルのパフォーマンスや効果を評価するための指標である。図表7で、正解率に(推奨)と記載されているように、機械学習モデルの学習に詳しくないユーザーでも、推奨される選択肢を使用することで容易にモデルを学習することが可能である。
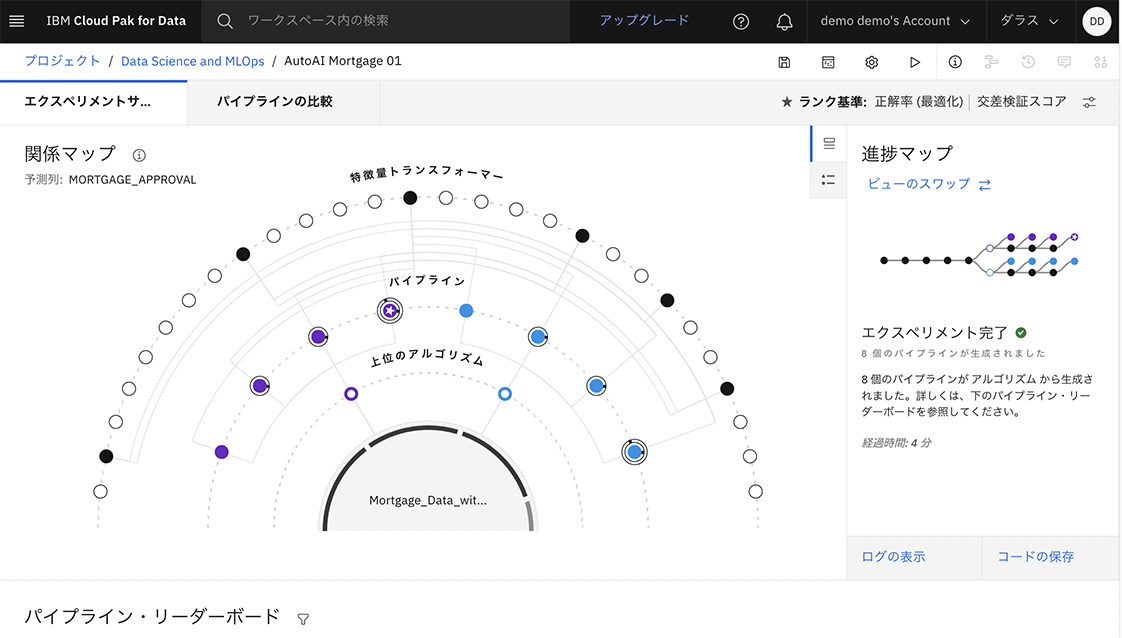
予測タイプや最適化メトリクスなどのパラメータを選択した後は、実際に学習を行う。学習時には、複数のアルゴリズムで学習が試行され、その中から最も評価指標に対する成績がよかったものを取得することができる。図表8のようなGUIで、どのようなアルゴリズムで学習が行われたかを学習後に確認することも可能である。
Watson Machine Learning
「③機械学習モデルのデプロイ」を行うためのサービスである。
Watson Studioなどで構築した機械学習モデルのプロモートやデプロイを行うことができる。モデルのプロモートとは、開発したモデルを本番環境に移行するプロセスであり、本番環境上で正しく動作し、期待通りのパフォーマンスを発揮することを評価する手順である。また、モデルのデプロイとは、本番環境上のモデルをユーザーが利用できる状態とすることであり、APIの公開などが行われる。モデルのプロモートとデプロイの関係は図表9の通りである。
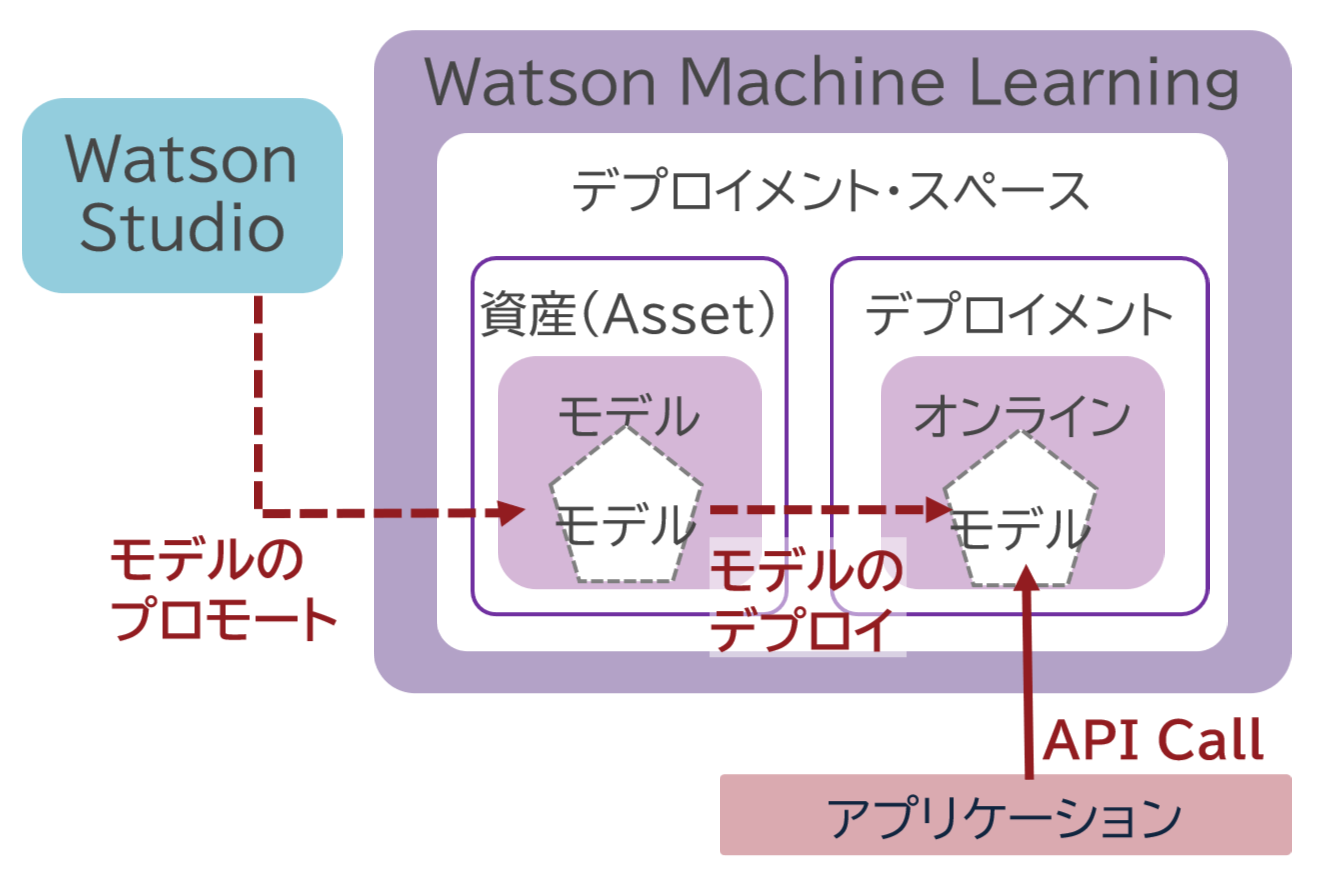
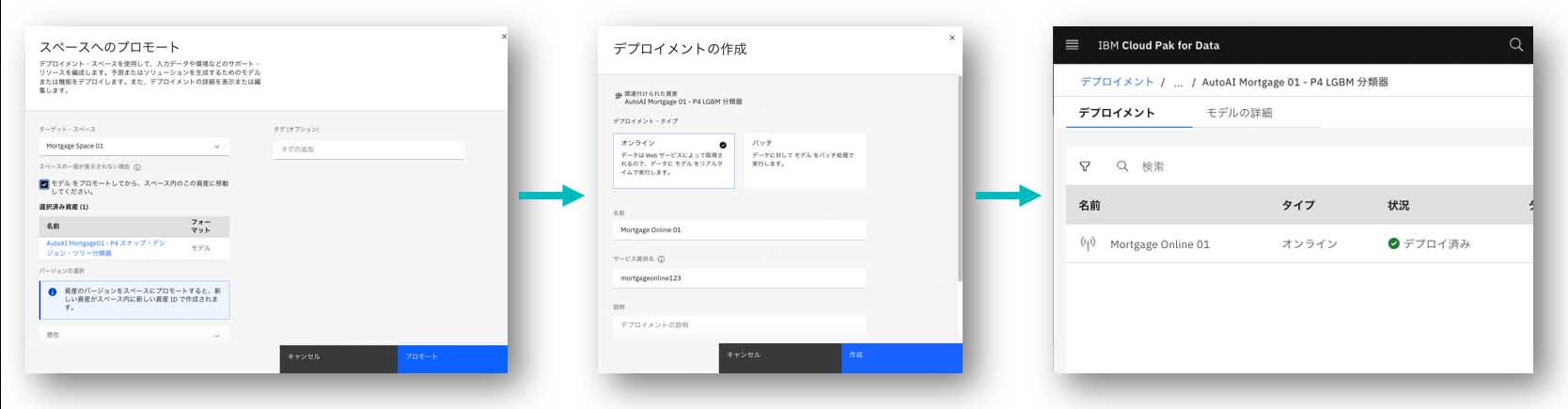
Cloud Pak for Data as a Service上でも、図表10の流れで、モデルをデプロイメント・スペースへプロモート後、モデルをデプロイする。
Cloud Pak for Data as a ServiceでのMLOps
ここまで、Data RefineryやAutoAI、Watson Machine Learningを利用して、データの収集からモデルの学習、モデルをデプロイする手順を説明した。一度モデルを開発してリリースするだけであれば、ここまでの作業で目的は達成できるだろう。
しかし、信頼性が求められるAIシステムでは、モデルを定期的に再学習し、機械学習モデルを利用したアプリケーションに動的にデプロイすることが求められる。また、モデルのパフォーマンスと状況を継続的に把握し、公平性が保てていることや説明可能性があることを監視し続けることが重要である。効率的なモデルの再学習やデプロイ済みのモデルを監視するための仕組みとしてMLOpsがあり、Cloud Pak for Data as a Serviceでは、Watson PipelinesやWatson OpenScaleを使うことで実現できる。Cloud Pak for Data as a ServiceでMLOpsを行う流れは以下の図表11の通りである。
Watson Pipelines
モデル開発・運用のライフサイクルの一連のタスクを定型化し、ワークフローを自動実行するためのツールである。
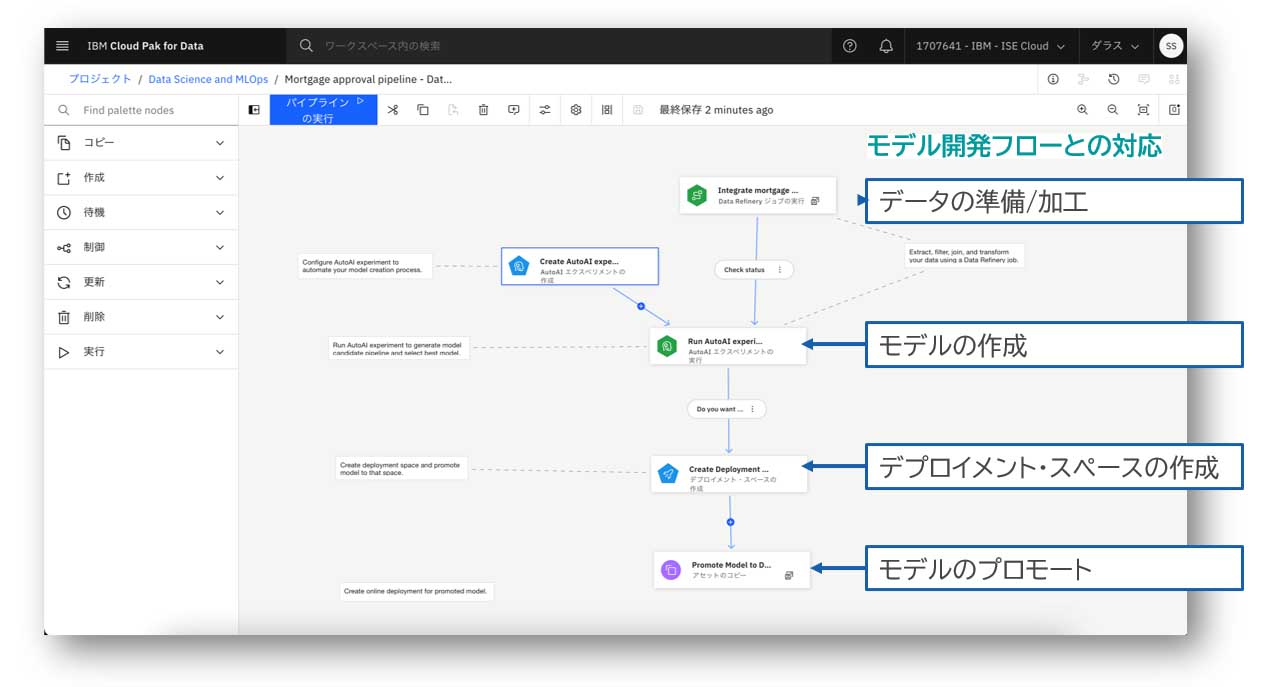
GUIのパイプライン・エディターを使用して開発を行うことができる。Watson Pipelinesの画面は図表12の通りである。フローを構成している1つ1つの要素をノードと呼ぶ。これらのノードは、Cloud Pak for Data as a Serviceでモデルの学習・稼働を行った際に使用したサービスと同じ役割を果たしている。図表12のように、各サービスの役割を持ったノードをフローとして紐づけることでパイプラインを構築し、各サービスの実行を一連の流れで自動化できる。
Watson OpenScale
AI モデルの結果を追跡および測定するモデルのモニタリング・ツールである。
自動的にモデルの入出力を監視し、公平性や精度について手間なく確認できるほか、モデルの判定根拠も確認でき、AIのブラックボックス問題を解決する。図表13の評価ダッシュボードでは、モデルの公平性や精度に異常がないことを可視化している。
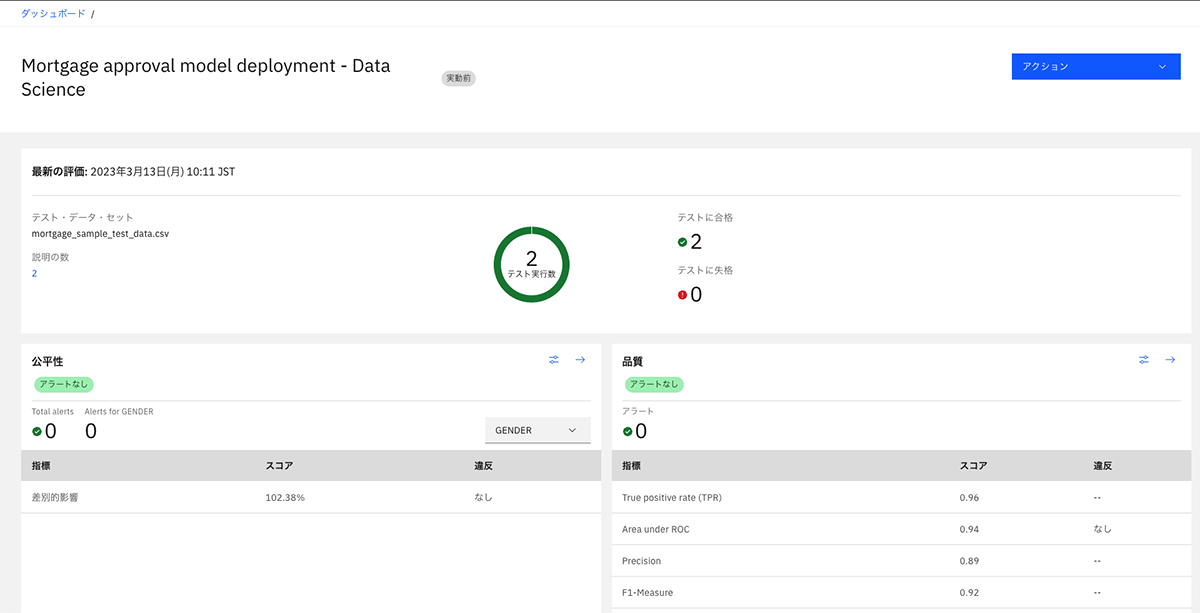
モデルの品質の確認
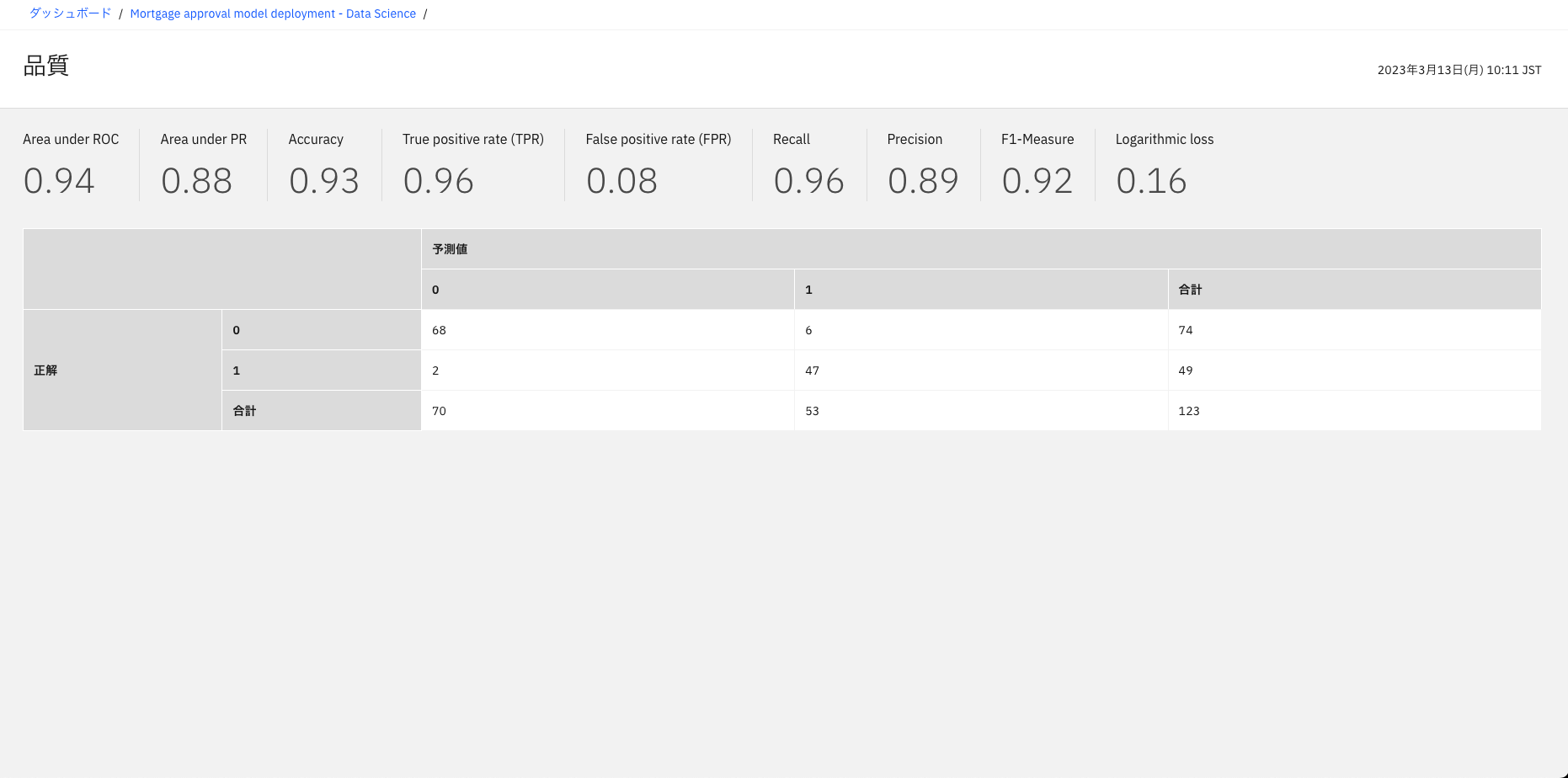
Watson OpenScaleでは、モデルの品質もモニタリングすることが可能である。品質の指標として「Area under ROC(ROC曲線下の面積)」や「True positive rate (TPR)」などが用意され、品質が満たされているかをさまざまな指標で確認することができる。たとえば、図表14ではArea under ROCの値は0.94である。一般的にROC曲線の下の領域が0.7のしきい値を超えれば精度のよいモデルと判断することが多いが、今回のモデルでは0.9以上であり、モデルは品質要件を満たしていると言える。
モデルの公平性の確認
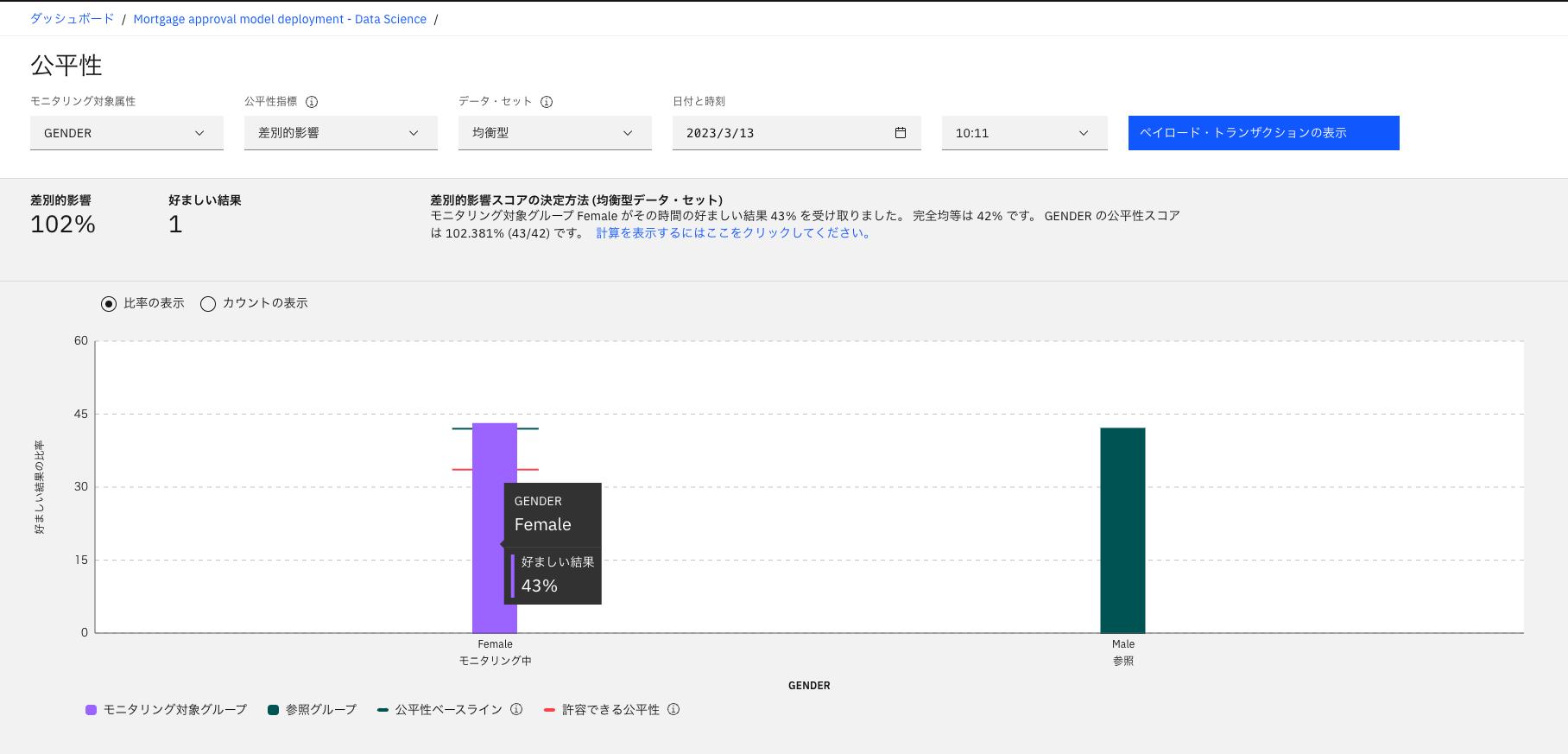
また、Watson OpenScaleでは、モデルの公平性も監視できる。図表15の2つの棒グラフは監視対象のパラメータの各候補における好ましい結果の数を示している。この例では性別パラメータに対して、男女間の好ましい結果を2つの棒グラフで示している。ここでは、公平性スコア(男女の好ましい結果の割合の一致率)が約100%であり、一般的に公平性を確保できていると判断される80%の公平性しきい値を超えているため、公平性要件を満たしていると言える。
モデルの説明可能性の確認
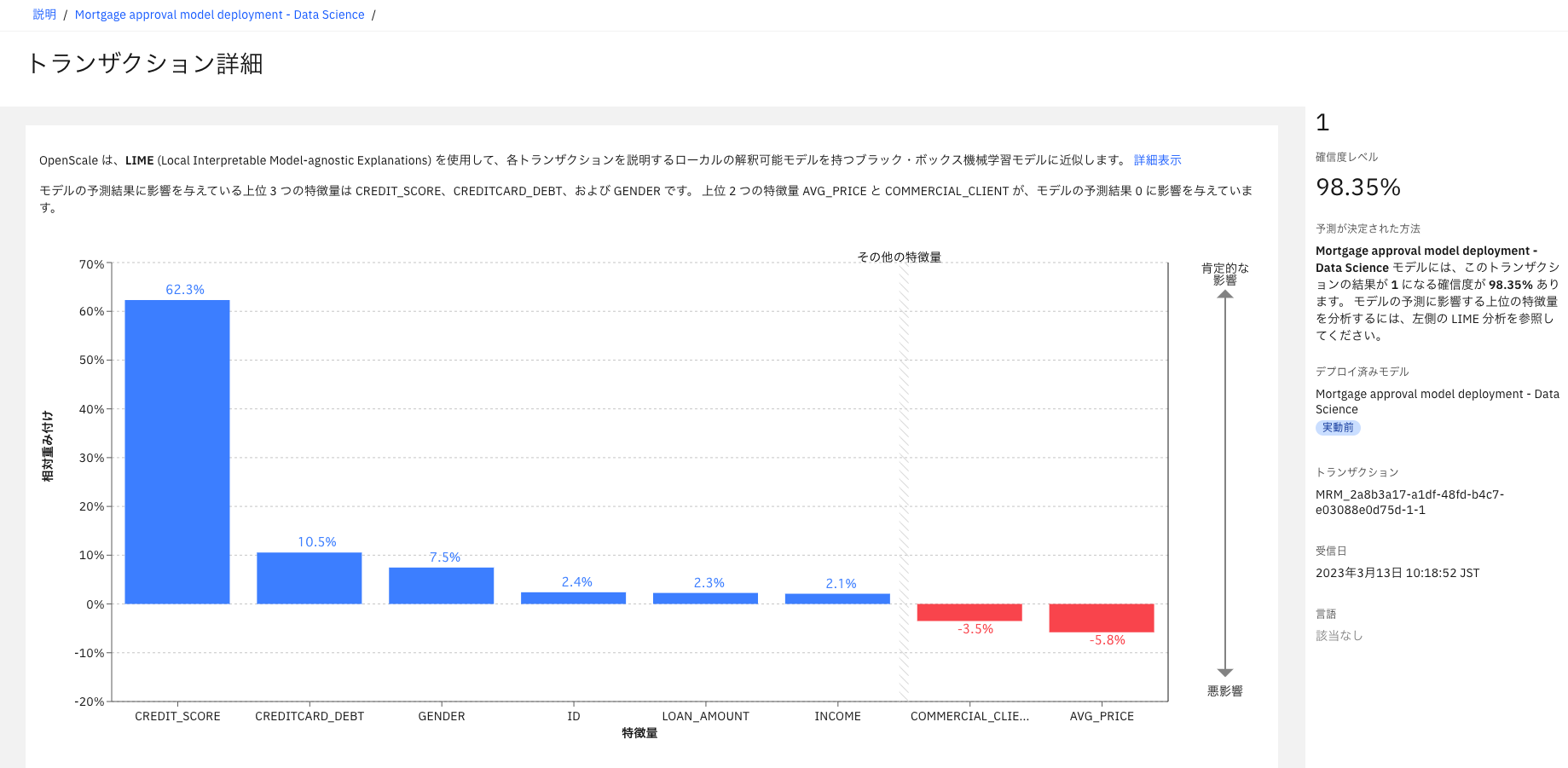
このほかにも、Watson OpenScaleでは、モデルの説明可能性を示すことができる。図表16は、あるトランザクション(テストデータの判定)について、判定結果を出すにあたりどのパラメータがどの程度寄与しているかを示している。青色の棒グラフは、「ローン申請が承認されるべき」と判断する方向にどの程度寄与したかを、赤色の棒グラフは、「ローン申請が拒否されるべき」と判断する方向にどの程度寄与したかを示している。図16では、一番左のCREDIT_SCOREの寄与が高いので、クレジット額の大小がローン審査において重要な判断基準であることがわかる。このように、判定結果を出すにあたりどのパラメータがどの程度寄与しているかを示すことで、判定根拠を示すことができる。
最後に
2019年に開催されたG20貿易・デジタル経済大臣会合では「AI原則」が議論され、AIの透明性および説明可能性が注目を集めた。また、2023年に開催されたG7のデジタル・技術相会合では、責任あるAIの普及に向けた取り組みが合意された。これらの例のほかにも、官民問わず、責任あるAIの議論は活発化しており、今後責任あるAIのニーズはますます広がると考えられる。
Cloud Pak for Data as a Serviceで提供されるサービスを活用することで、機械学習モデルを学習、デプロイするだけでなく、効率的なモデルの再学習やデプロイ済みモデルの品質の監視が可能となる。Cloud Pak for Data as a ServiceでMLOpsを実践し、責任あるAIをより迅速に構築することが、今後の競争優位性につながることだろう。
[参考]
[1] IBM Community Japan – なぜMLOpsが必要なのか(vol97-0014-ai)
https://community.ibm.com/community/user/japan/blogs/provision-ibm1/2021/08/17/vol97-0014-ai
[2] IBM リューションブログ – MLOpsのキホンと動向
https://www.ibm.com/blogs/solutions/jp-ja/mlops-2021-data/
[3] IBM – AI倫理
https://www.ibm.com/jp-ja/artificial-intelligence/ethics
[4] IBM Cloud Pak for Data as a Service製品資料
https://dataplatform.cloud.ibm.com/docs/content/wsj/getting-started/welcome-main.html?context=analytics
[5] Microsoft: Azure Machine Learning,
https://azure.microsoft.com/ja-jp/services/machine-learning/
[6] Google: Vertex AI,
https://cloud.google.com/vertex-ai
[7] Amazon Web Service: Amazon SageMaker,
https://aws.amazon.com/jp/sagemaker/