text:立石 孝彰 日本IBM
機械学習のプロセス
機械学習を効果的に利用するためには、データの前処理、機械学習アルゴリズムの選択、ハイパーパラメータと呼ばれるアルゴリズムへの設定値の調整が必要です。データの前処理では、書式や単位の統一化もあれば、元のデータをそのデータの特徴を表す数値などへ変換することも含まれます。このようなデータの特徴を計測可能な値として表現したものを特徴量と呼び、与えられたデータから新しい特徴量を作成する作業のことを特徴量エンジニアリングと呼びます。
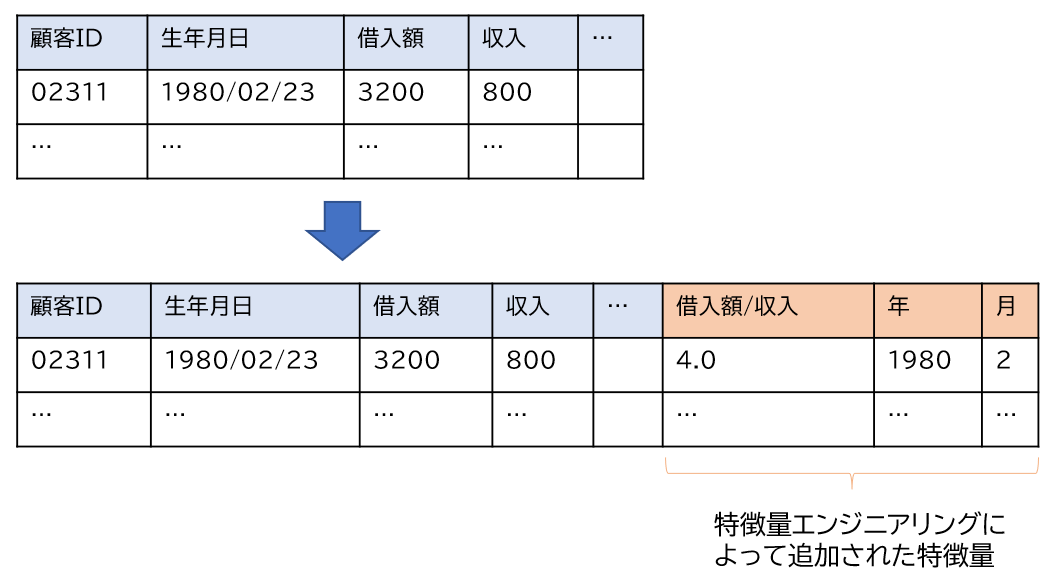
たとえば、“2021年11月1日”のような時刻を表す文字列データであれば、年月日の3つの数値データ(2021, 11, 1)、曜日、またはUNIX時間へ変換することなどです。あるいは、すでに数値データが与えられている場合であっても、複数の特徴量を組み合わせることによって新しい特徴量を作成することもあります。ローン完済の可能性を予測するために機械学習を使う場合は、収入と借入額のデータが与えられていれば、収入に対する借入額の割合(借入額÷収入)を新しい特徴量として作ることが多くあります(下図)。このようなデータの前処理や特徴量エンジニアリングは、元のデータの性質や機械学習を使う目的に応じて異なり、試行錯誤を繰り返すことによってよりよい特徴量を作り出すことが要求されます。
一般的に、機械学習プロジェクトでは、データの前処理工程に70%から80%の時間が費やされているという報告[1]があります。また、特徴量エンジニアリングは、機械学習の知識に加えて、ドメイン知識(対象とするビジネスドメインや与えられたデータに特化した知識)が必要となる属人性が高い作業であり、機械学習を用いたプロジェクトの成否に関わる[2]とも言われています。しかし、機械学習とビジネスドメイン両方の知識や経験を持つエンジニアの数は、どちらか一方の知識を持つエンジニアよりも限られてきます。このことが業務における機械学習利用の促進に影響を与えることもあります。
AutoML ―― 機械学習の自動化
特別な知識や経験を必要とせず、データの前処理、アルゴリズムの選択、ハイパーパラメータの調整などを自動的に行えれば、より多くの人が手軽に機械学習を使うことができるようになります。このような自動化された機械学習をAutoML[3][4]と呼び、H2O AutoMLのようなソフトウェアツールとして提供していることもあれば、IBM Watson Studio AutoAI、Google AutoML Tables、Microsoft Azure AutoMLなどのようにサービスとして提供されていることもあります。
これらのAutoMLサービスでは、特徴量エンジニアリングを含むデータの前処理の自動化も行っています。公開されているいくつかのドキュメント[5][6][7]を見る限りでは、欠損値の補完、数値のスケーリング、日付データの処理、テキストデータの特徴づけなど、表データにおける単一カラムの前処理を自動化の対象としていることが共通しています。さらに、IBM Watson Studio AutoAIでは特徴量の組み合わせによる計算も自動化されています。
学術分野においても特徴量エンジニアリングを自動化する技術[12][13][14]が提案されています。これらの技術では、予測や分類に有用な特徴量の組み合わせを、統計的手法あるいは機械学習を用いて効率よく探索する仕組みを利用しています。しかし、このような統計的手法は、人がドメイン知識を利用して特徴量の意味を理解しながら行う特徴量エンジニアリングとは異なり、総当たり的に特徴量を組み合わせます。その結果、自動的に作成された特徴量は、人間が理解し意味的な側面からその有効性について判断することが困難になることがあります。また、特徴量が増えるほど組み合わせ数も爆発的に増えるので、学習データが少ない時には、その中からテストデータに有効な特徴量を選択するのが困難になるという本質的な問題を常に持っている点にも注意が必要です。
ドメイン知識を活用した自動化
特徴量が持つ意味を人が行うように把握することによって特徴量エンジニアリングを自動化する取り組み[8][9][10]も行われています。これらの取り組みでは、ドメイン知識を集めたデータベース(知識ベースまたは知識グラフ)を利用しています。
文献[9]は比較的古い技術になりますが、YAGOやDBpediaなどの既存の知識グラフを利用しています。そして、先の例で取り上げたような特徴量エンジニアリングではなく、与えられた文字列値に関連があるエンティティ(知識グラフ上のノード)を新しい特徴量として作成します。たとえば、映画を推薦することを目的とする場合、映画のタイトルから関連する予算、キャスト、リリース日などを追加の特徴量として知識グラフから抽出できます。また、このような外部の情報源を利用して対象のデータセットに特徴量を追加することは、人手による特徴量エンジニアリングを自動化したものです。
参考資料[8]中では、既存の知識ベースだけでなく、ドキュメントやコード中に存在する数式をドメイン知識として収集・利用し、先に取り上げた借入額の割合を求めるような特徴量エンジニアリングの自動化を取り上げています。このようなドメイン知識を活用した自動化の効果は、収集したドメイン知識のカバレッジ(収集した量と種類)に依存する部分が大きいという点に注意が必要です。そこで、ドメイン知識の収集方法について既存の知識ベースを参考にして考えてみることにします。
ドメイン知識の収集
よく知られている知識ベースには、CYC、FreeBase、DBpedia、Wikidata、Yagoがあり、これらの比較は文献[11]に詳しく説明されています。その知識の集め方は、人手による直接的な収集、Wikipediaからの抽出、またはこれらの併用に大別できるかと思います。機械学習の自動化あるいは半自動化の観点から考えると、人手による収集は作られる特徴量の正しさに貢献しますが、一方で、カバレッジは非常に限定的です。
Wikipediaからの抽出に関しては、Wikipediaのページがクラウドソーシングにより作成されているため、幅広くさまざまな情報は集まりますが、infoboxと呼ぶ各ページに付随する構造化データなどに頼って情報を抽出しています。Wikipediaのページそのものには数式などが含まれていますが、infoboxに基づいて作成された知識ベースには、どのように特徴量を組み合わせるのかを表す数式に該当する知識はほとんど含まれていません。これらの理由から、既存の知識ベースは、特徴量の組み合わせを行うには不向きではありますが、文献[9]のような特徴量エンジニアリングを行うことには効果が期待できます。
次に、特徴量の組み合わせを直接的に知識として収集することを考えます。ここでも、人手による方法と他の情報源からの抽出という2つの方法が取り得ます。既存の知識ベースと同様に人手によってそのような知識を収集を行う場合、知識を入力するためにドメイン知識と機械学習の両方に知見を持つエンジニアが必要です。
一方で、既存の知識ベースがWikipediaのinfoboxに頼っているように、他の情報源から特徴量作成に有用な知識を抽出するためには、この抽出のための技術が必要です。参考資料[8]では、既存の機械学習のプログラムや付随するドキュメントから抽出できる可能性を紹介しています。たとえば、プログラムからの抽出では、プログラム解析の技術を用いてカラム名を含む数式を抽出し、そのカラム名を既存の知識ベース中のエンティティへ対応づけることによって数式を汎化しています。
*
本稿では、機械学習の自動化、特に、特徴量エンジニアリングの自動化にドメイン知識がどのように利用できるのか簡単に紹介しました。また、このようなドメイン知識を利用する手法は、ドメイン知識のカバレッジに頼る部分が大きいため、ドメイン知識の取集方法についていくつか例を取り上げました。自動化された機械学習というツールやサービスの話に留まらず、機械学習プロジェクトの管理や効率化を考える際の参考にもなれば幸いです。
◎参考文献
[1] Dipanjan Sarkar:“Continuous Numeric Data — Strategies for working with continuous numerical data”
[2] Pedro Domingos:“A few useful things to know about machine learning”
[3] Marc-André Zöller, Marco F. Huber: “Benchmark and Survey of Automated Machine Learning Frameworks”
[4] 田村広平, 八木真理奈, 喜多陵, 鶴田彰, 猪狩義貴: “機械学習モデル構築作業の煩雑さを解消する「AutoML」とは――歴史、動向、利用のメリットを整理する”
[5]“AutoAIの概説”
[6]“AutoML Tables の特徴と機能”
[7]“自動機械学習でのデータの特徴量化”
[8]“Scale business outcomes from AI with low-code application development”
[9]Weiwei Cheng, Gjergji Kasneci, Thore Graepel, David Stern, Ralf Herbrich: “Automated feature generation from structured knowledge”, CIKM 2011
[10] Martin Atzmueller, Eric Sternberg: “Mixed-initiative feature engineering using knowledge graphs”, K-CAP 2017
[11]Michael Färber, Basil Ell, Carsten Menne, Achim Rettinger: “A Comparative Survey of DBpedia, Freebase, OpenCyc, Wikidata, and YAGO”,
[12] James Max Kanter, Kalyan Veeramachaneni: “Deep feature synthesis: Towards automating data science endeavors”, DSAA 2015
[13] Gilad Katz, Eui Chul Richard Shin, Dawn Song: “Explorekit: Automatic feature generation and selection.”, ICDM 2016
[14] Udayan Khurana, Horst Samulowitz, Deepak Turaga. “Feature engineering for predictive modeling using reinforcement learning”, AAAI 2018
立石 孝彰 氏
日本アイ・ビー・エム株式会社
東京基礎研究所
研究員
ソフトウェア工学の側面からWebアプリケーションセキュリティ、モダナイゼーション、ブロックチェーン、機械学習などの研究開発活動に従事。
IBM Researchの研究員紹介ページ(英語) こちら

*本記事は筆者個人の見解であり、IBMの立場、戦略、意見を代表するものではありません。
当サイトでは、TEC-Jメンバーによる技術解説・コラムなどを掲載しています。
TEC-J技術記事:https://www.imagazine.co.jp/tec-j/
![]()
[i Magazine・IS magazine]







