-- 「カタログファーストアプローチ」をネットで調べてもまったくヒットしません。どういうものなのですか。
村山 これは日本IBMの山田 敦さん(IBM AIセンター長)が一昨年(2020年)に考案された概念で、データ活用にかかわる課題を克服するためのアプローチです。
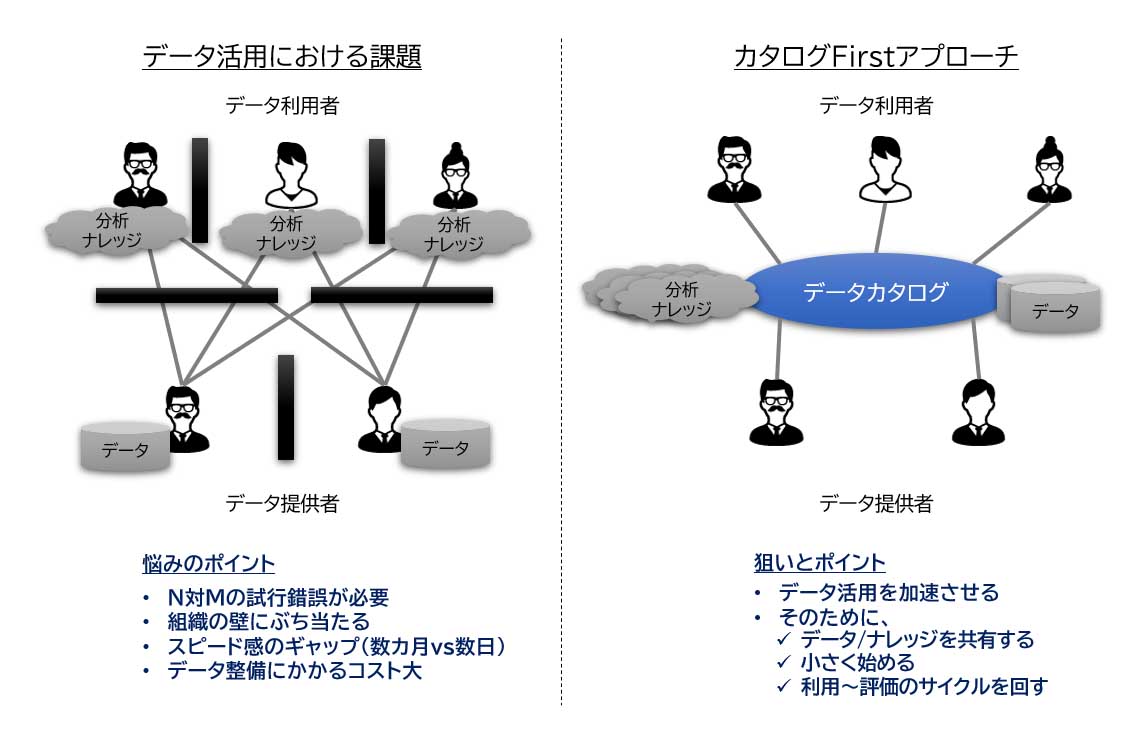
データ活用のアプローチとしてはこれまで、「データファーストアプローチ」と「AIファーストアプローチ」の2つがありました。データファーストアプローチは、データ基盤を整備してさまざまなデータを蓄積していき、そのデータを基にビジネス課題を設定するというアプローチです。それに対してAIファーストアプローチは、データの分析テーマやAIテーマを設定し、それに必要なデータを集めてビジネス課題を解決するというアプローチです。
この2つのアプローチには課題があって、データファーストアプローチはデータ基盤の構築に大規模な投資が必要で、さらに蓄積されたデータとビジネス課題の設定でミスマッチが起こるということがありました。一方のAIファーストアプローチは分析に必要なデータがなかなか揃わず、時間だけが過ぎていくということがありました。
カタログファーストアプローチはこの2つのアプローチの課題を克服するもので、ビジネス課題を設定したうえで必要最小限のデータを準備し、データカタログを整備するところから始めるアプローチです。これによってデータ利用者とデータ提供者が短サイクルで協業を始めることができ、さらにデータカタログを成長させていくことによってデータ活用の範囲の拡大も可能です(図表1)。
-- 魅力的なアプローチですね。
村山 ただし私がカタログファーストアプローチに出会った頃は、今お話ししたような概念しかありませんでした。それでカタログファーストアプローチの考え方に沿ったデモを作ってみようと考え、チームで開発しました。その結果、適用のイメージは掴めたものの、それを具体化し実現するアーキテクチャや進め方については探究が必要だろうと痛感しました。それがWG設立へとつながります。
-- デモはどのような内容ですか。
村山 4つのユースケースを想定しました。1つ目はユーザーがデータカタログ上でビジネス用語を用いて検索し、抽出されたデータの中身や各データ項目の品質を確認して利用するという流れです。2つ目はユーザーがデータカタログ上で高評価のデータを発見し、その評価内容を確認して利用するというユースケースです。ユーザーはデータカタログのレビュー機能を使って評価を書き込めるので、他のユーザーはそれを基に効率よくデータを活用できます。
3つ目はデータカタログに新規にデータ登録するときのユースケースで、ユーザーがデータ登録をデータスチュワード(データ提供者)に依頼すると、データスチュワードはそのデータがどのデータソースにあるかを確認し、システム側のデータエンジニアにデータソースの追加を依頼します。そしてデータエンジニアによってデータソースが追加されると、データスチュワードはデータソースの中から依頼のあったデータをデータカタログに登録し、ユーザーに通知するという流れです。
4つ目はデータ仮想化(Data Virtualization)機能を用いて新規データ登録を迅速に行うというユースケースです。ユーザーによってはデータをすぐに提供してほしいという依頼がありますが、既存データソースの表のJOINによって新しいデータソースにできるような場合、データスチュワードはデータ仮想化機能を使って操作を行い、データカタログに登録を行えます。
-- カタログファーストアプローチでは、何か特定の製品を想定していますか。
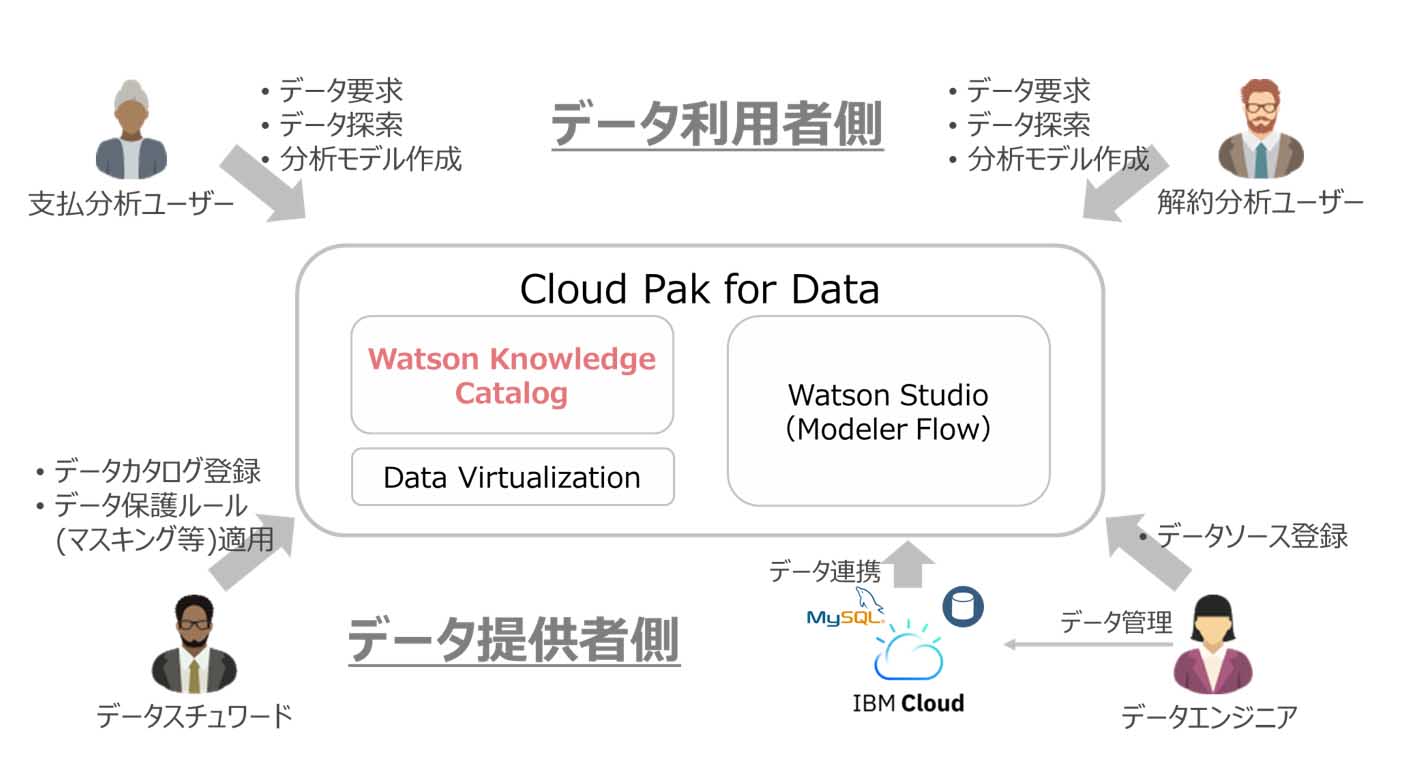
村山 デモの開発ではWatson Knowledge CatalogというデータカタログをもつIBM Cloud Pak for Dataを使いましたが、特定の製品に縛られるものではありません。データカタログという機能があり、カタログファーストアプローチを実現する機能さえあればどの製品でも問題ありません(図表2)。
-- WGはどのようなスケジュールで進んできたのですか。
村山 最初はカタログファーストアプローチの研究で何をやるのかメンバーの多くがピンと来ていなかったようなので、データカタログの事例や課題の収集から始めました。そして収集した事例や課題から、データ利用者、データ提供者、システム主幹の観点でどういった要件があるのかを整理し、実際にスモールスタートする場合を想定したプロセス・体制・技術について検討を進めていきました(図表3、図表4)。
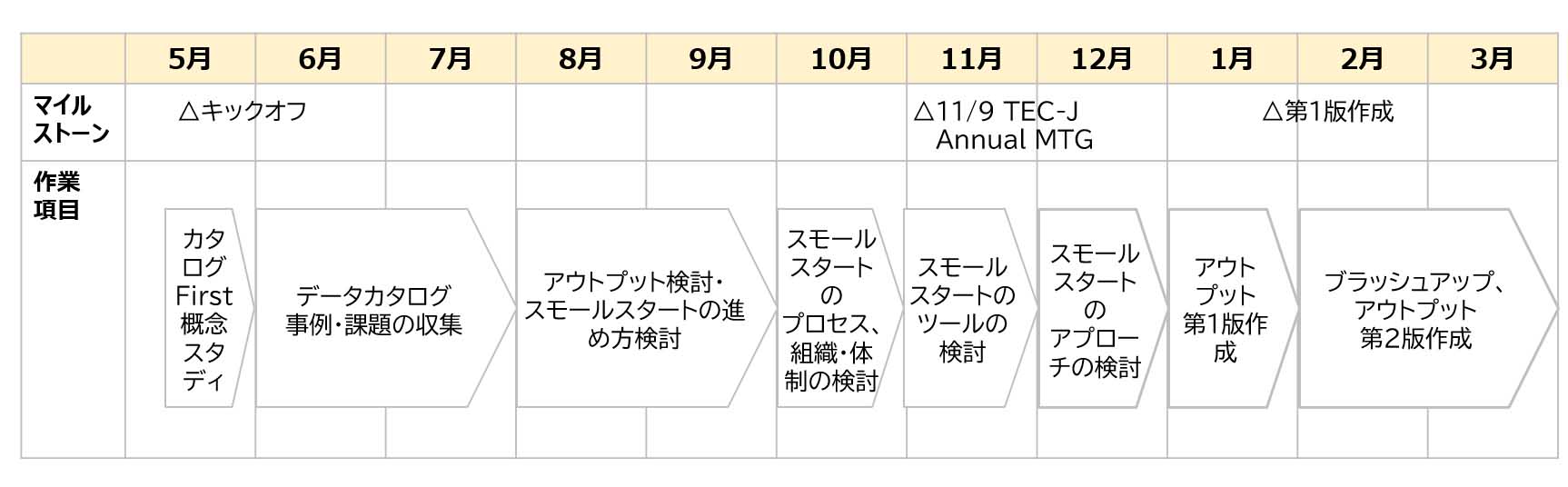

-- その検討の結果、今見えていることは何ですか。
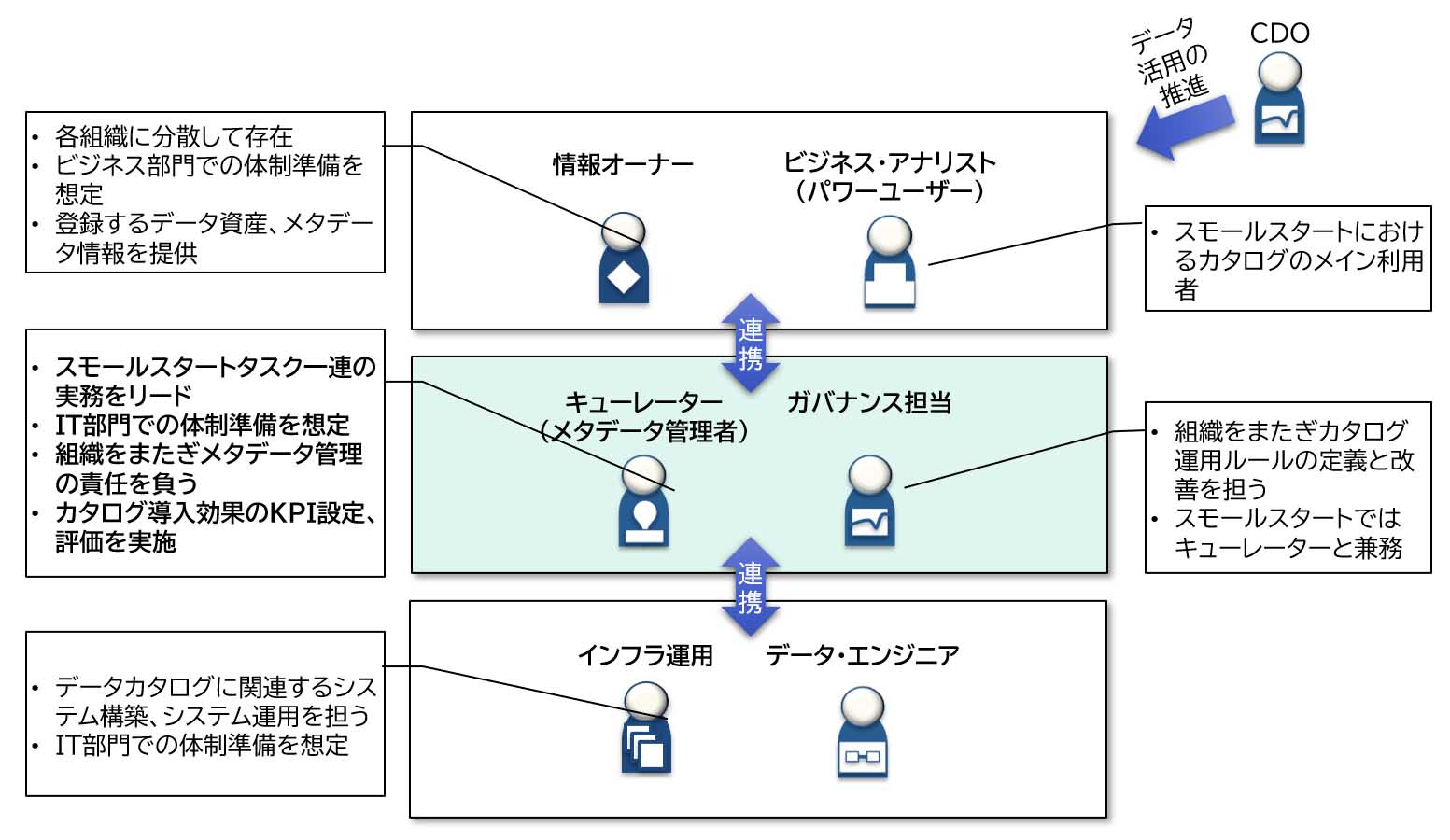
村山 データカタログを導入するとそれなりにコストもかかるので、適切なROIを得るには単一の組織ではなく複数の組織にまたがるデータの活用を考慮する必要があること、そしてデータガバナンスに関する最小限のルールやプロセス、体制の必要性と、ビジネスユーザーとデータサイエンティストの中間に位置するパワーユーザーの重要性です。
パワーユーザーについては、ビジネスユーザーと同じく業務部門に所属していて、自らも業務のためにデータに触って活用し、さらにビジネスユーザーのためにデータの加工や可視化も行える人、と定義しました。
-- いろいろな側面で考慮と要件定義が必要なのですね。データガバナンスについて、もう少し説明をお願いできますか。
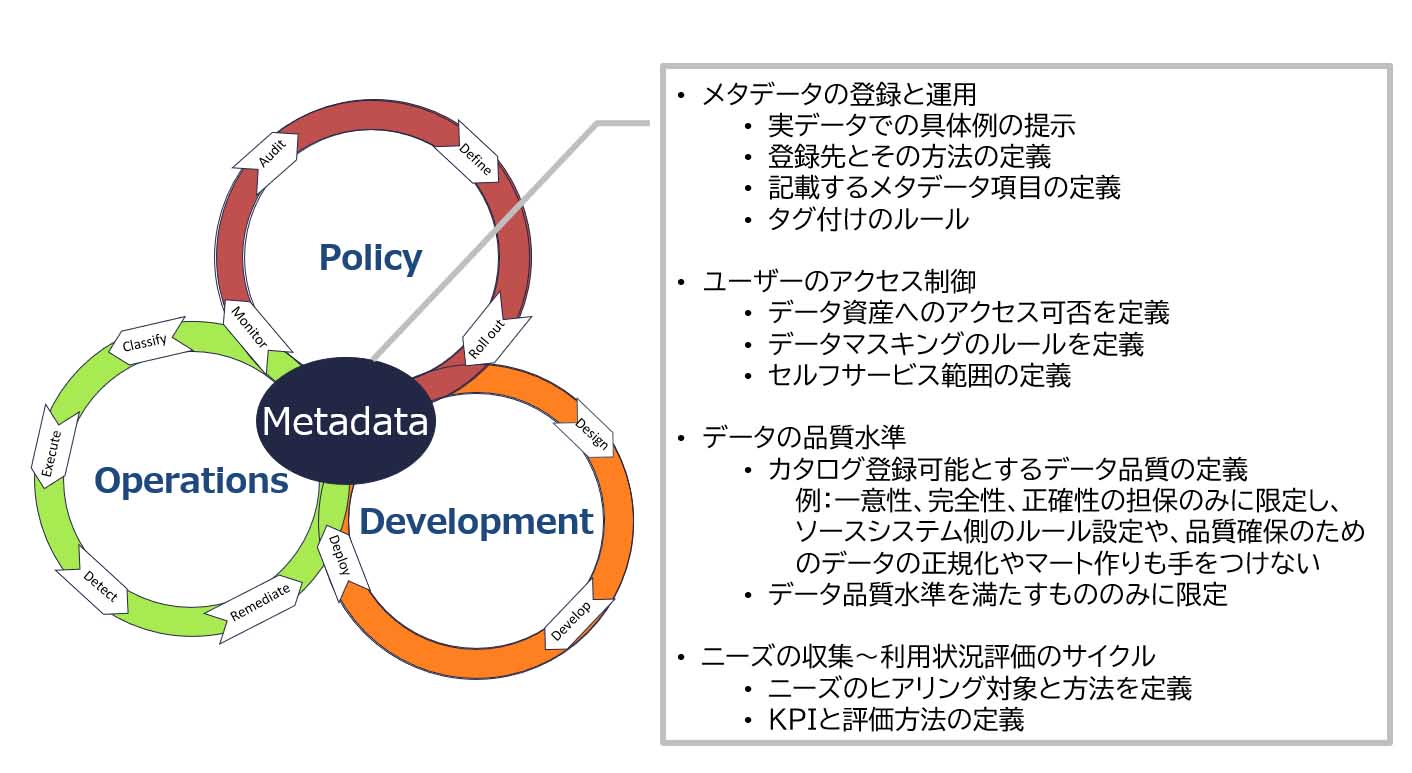
村山 それはデータカタログに登録するメタデータの運用ルールや、メタデータに対するユーザーのアクセス制御、メタデータの品質の水準をカバーするものです。品質の劣るデータが登録されていても結局は使われませんから、品質の面でもガバナンスは重要です。
それと、ルールやプロセスがあったとしても、ユーザーに使ってもらえなければ意味がありませんから、使ってもらうための視点も非常に重要だと感じています。それを担保するのは、データに対するニーズの収集や利用状況を評価するためのKPIですが、その定義とプロセスも必要になります。
カタログファーストアプローチの運用にあたっては、データカタログ上のメタデータだけでなく、情報システム上のマスターデータやデータの信頼性・セキュリティ・品質などの基準も必要ですが、スモールスタートでは、メタデータの管理を中心にルール、プロセスを検討すべきだろうと思います。それとメタデータの管理者を中心とした最小限の体制ですね(図表5、図表6)。
-- スモールスタートに必要なデータカタログの機能は何でしょうか。
村山 それをまとめたのが図表7になります。主だったカテゴリーとしては、ユーザーの検索機能、ワークフロー、データアクセス制御、運用の自動化、対外データの利用、ユーザビリティの6つで、赤字が必要最小限の機能です。
-- 赤字以外は、データカタログを成長させていくときに必要になる機能というわけですね。
村山 そうなります。データカタログを成長させるという観点では、とくに外部データの利用や外部へのデータの公開が考えられますが、そうしたときにマーケットプレイス機能があると便利ですし、クラウドサービスに対する対応機能も必要と考えています。


-- 村山さんはカタログファーストアプローチWGのリーダーで、お仕事でもデータ活用のプロジェクトに入っておられます。企業における理想的なデータ活用について、何か考えていることはありますか。
村山 企業におけるデータ活用は、一部の先進的な企業を除いて、それほど進んでいないと感じています。データサイエンティストもまだ非常に少なく、改善の余地はたくさんあります。将来的にはデータファブリックが提示するような、データがどこにあっても、どのような形式で分散していても、誰でも好きなときに好きなように利用できるという世界が到来すると思っていますが、そのときにデータを縦横に使いこなすのは「市民データサイエンティスト」と呼ばれるような属性をもつ人たちではないかと思います。データを好きなときに取り出して、加工・分析も自由に行えるというスキルや知見をもった人たちです。
市民データサイエンティストがごく一般的になる時代では、データを活用するための自動化が進み、ローコードやノーコードのツールも広く普及しているでしょう。そしてその中心にあるコンポーネントが、データカタログではないかと思っています。
村山 浩之 氏
日本アイ・ビー・エム システムズ・エンジニアリング株式会社
DXソリューション Advanced AI
アドバイザリー・アーキテクト
2001年日本IBM入社。東海エリアでインフラエンジニアとして活動後、2007年日本IBMシステムズ・エンジニアリングに出向。アプリケーション・サーバー製品バックサポートを経て、近年はデータプラットフォームのアーキテクチャー策定やデータモデリング活動に従事。
*本記事は話し手個人の見解であり、IBMの立場、戦略、意見を代表するものではありません。
当サイトでは、TEC-Jメンバーによる技術解説・コラムなどを掲載しています。
TEC-J技術記事:https://www.imagazine.co.jp/tec-j/
![]()
[i Magazine・IS magazine]