「Watson Discovery Service」(以下、Discovery)は2016年12月、IBM Cloudで提供されるWatson API サービスに加わった。Watson APIサービス全体のロードマップのなかでも、重要な位置を占めるサービスとして大きな注目を集めている。そして2017年9月末には、日本語版の提供がスタートした。
本稿ではDiscoveryはどんなサービスなのか、何ができるのかを紹介したい。さらに検索精度の観点から、Discoveryをより効果的に活用するための情報を提供したい。
情報検索に必要な
複数の機能を統合
Discoveryは大まかに言うならば、情報検索システムである。基本的な使用方法は、検索対象の文書を投入し、検索のクエリーをかけて、検索結果を取得することである。
現在はサービスを終了した「Document Conversion」と「Retrieve & Rank」 という2つのWatson APIを覚えているだろうか。前者はさまざまなファイル形式のデータを変換するサービスであり、後者は機械学習モデルを利用した検索システムのサービスである。Discoveryは、この2つを組み合わせたAPIである。
またDiscoveryは、テキスト解析サービスを内部的に使用する「エンリッチメント」と呼ばれる機能を備える点も特徴である。同じくWatson APIである「Natural Language Understanding」や「Watson Knowledge Studio」を内部的に利用したテキスト解析が可能となる。
ちなみにNatural Language Under standingは、事前学習された汎用的なメタ情報を抽出する。一方のWatson Know
ledge Studioは自身で定義し、学習させたルールや機械学習モデルによる情報を抽出して、業界固有の用語に対応する。
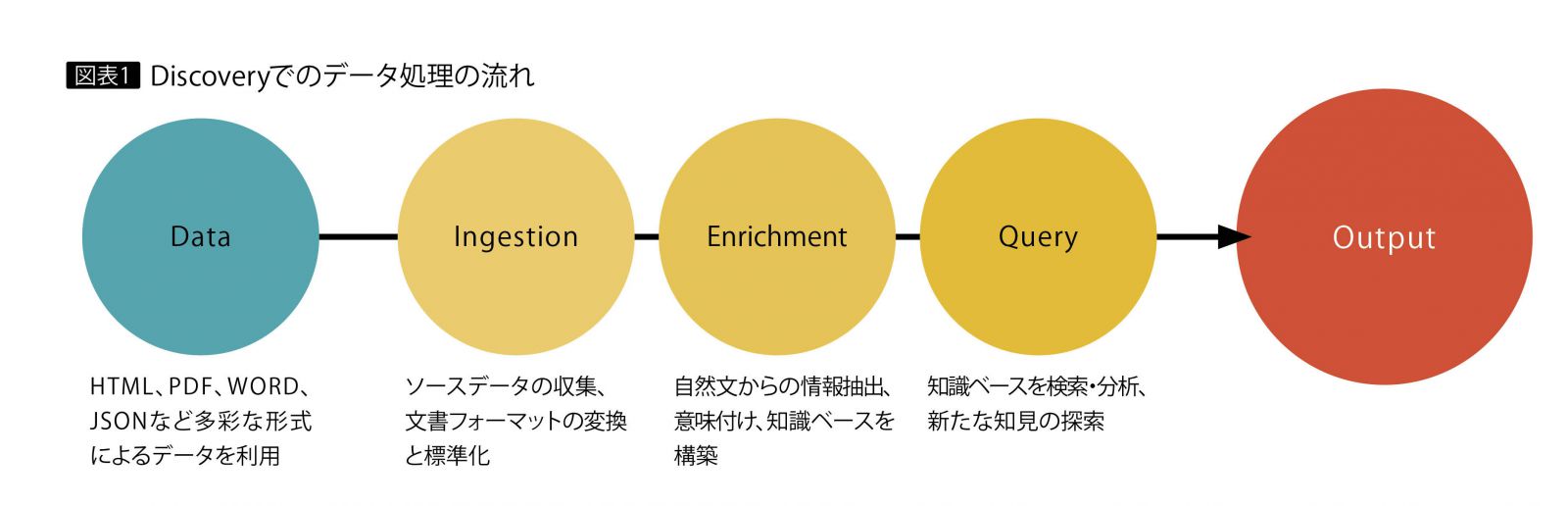
Natural Language Understanding などと連携させたDiscoveryのデータ処理の流れは、図表1になる。従来は、それぞれの機能を実現するために複数のWatson APIを組み合わせる煩雑な構成が必要であったが、現在はDiscovery だけで実現できる。検索システムの構築に必要な機能を統合していることが、Discoveryの強みである。
Discoveryを特徴づける
3つの機能
Discoveryの機能は、大きく以下の3つに分けられる。
文書取り込み機能
異なるファイル形式のデータを取り込み、保存する、いわゆるクローラ機能を備える。PDFやWord、HTMLのファイルをそのままDiscoveryに登録する文書データとしてアップロードできる。
文書データを取り込む方法はいくつか用意されている。たとえばサービスの管理画面を通じて、文書ファイルをドラッグ&ドロップで投入する。API経由でファイルを送る。Discovery用の外部プログラムのクローラを使用して、文書ファイルやDBデータなどを取り込む、などの方法がある。
エンリッチメント機能
エンリッチメントは前述したように、Natural Language UnderstandingやWatson Knowledge Studioを使ったテキスト解析機能である。投入された文書がCollectionに保存される際に、解析結果のメタ情報を付与する。このエンリッチされた情報を検索時のパラメータとして使用することで、元の文書データには存在しなかったメタ情報で検索できる。
クエリー機能
クエリーを発行し、検索を実行する機能である。関連度を順位付けし、関連度が高い順での検索結果の取得、条件による絞り込み、検索結果の集約・集計が可能となる。
またキーワードベース検索に加えて、自然文でも検索できる。自然文検索により、ユーザーからの問い合わせ入力をそのまま検索のクエリーとして活用し、チャットボットなどの案件にも適用できる。
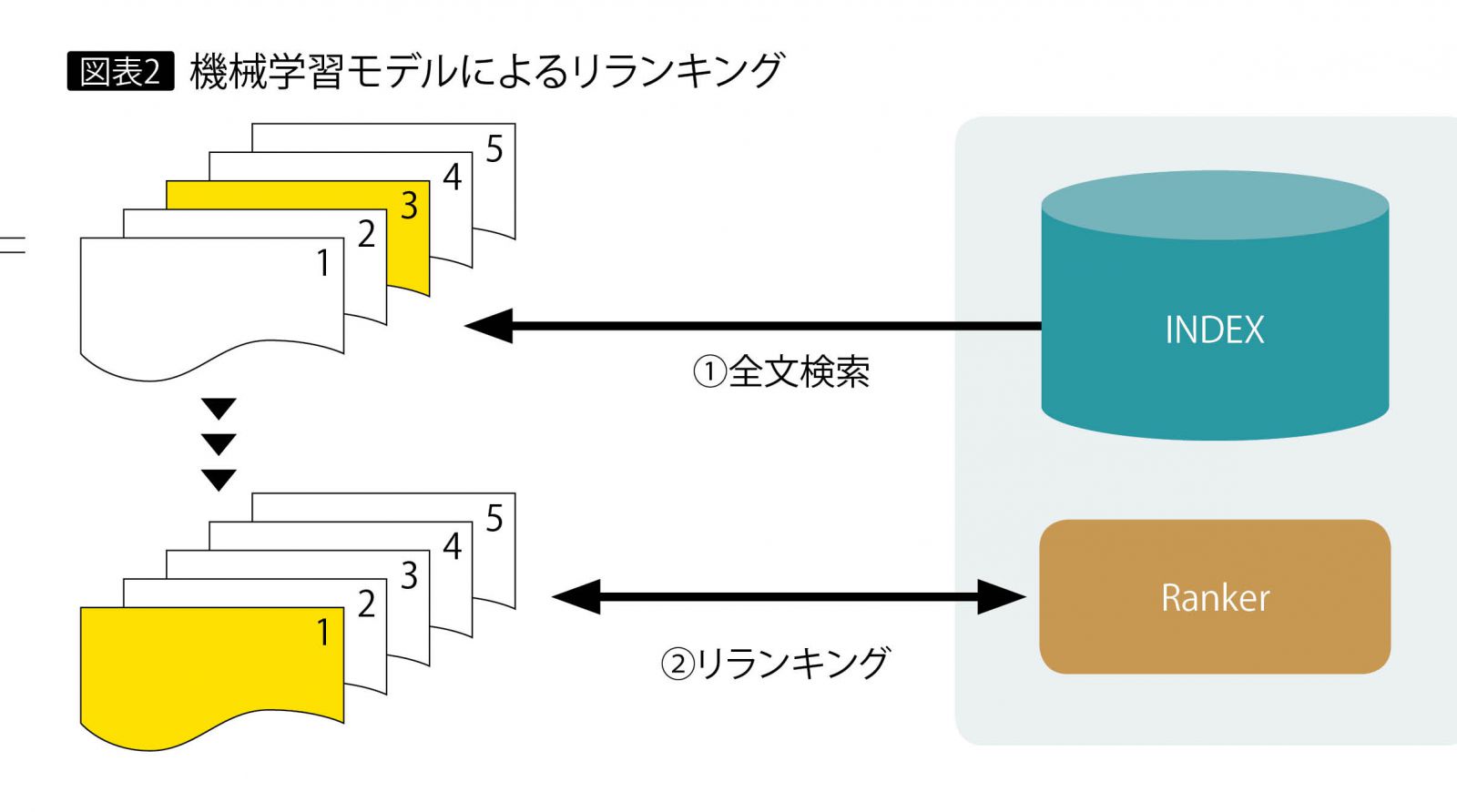
さらに期待される回答を、検索結果のより上位に並び替えるために、機械学習モデルの作成やトレーニング機能を備える。回答となる文書データとは別に、トレーニング用のテキストを準備。それぞれに回答候補の関連度を付与して学習させることでモデルを作成し、検索結果の並び替え(リランキング)を実行する。
図表2のように、通常の状態では全文検索の結果が返るが、トレーニングによる機械学習モデル(Ranker)を作成している場合には、全文検索の結果がリランキングされた形になる。このように通常の検索機能に加え、検索精度の向上を図るうえで欠かせない機械学習モデルによるリランキングという2つの仕組みを備える点がDiscoveryの大きな特徴である。
Watson Assistantとの
棲み分け
問い合わせの回答検索にWatsonを用いる場合、「Watson Assistant(旧Conversation。以下、Assistant)」がよく検討される。AssistantとDiscoveryの違いを説明しよう。
Assistantはユーザーと会話し、問い合わせに回答するサービスとしてよく利用されている。会話フローの設計とともに、ユーザーの問い合わせテキストの意図を分類するIntent機能を備え、チャットボットなどでの問い合わせ応答に適したサービスである。
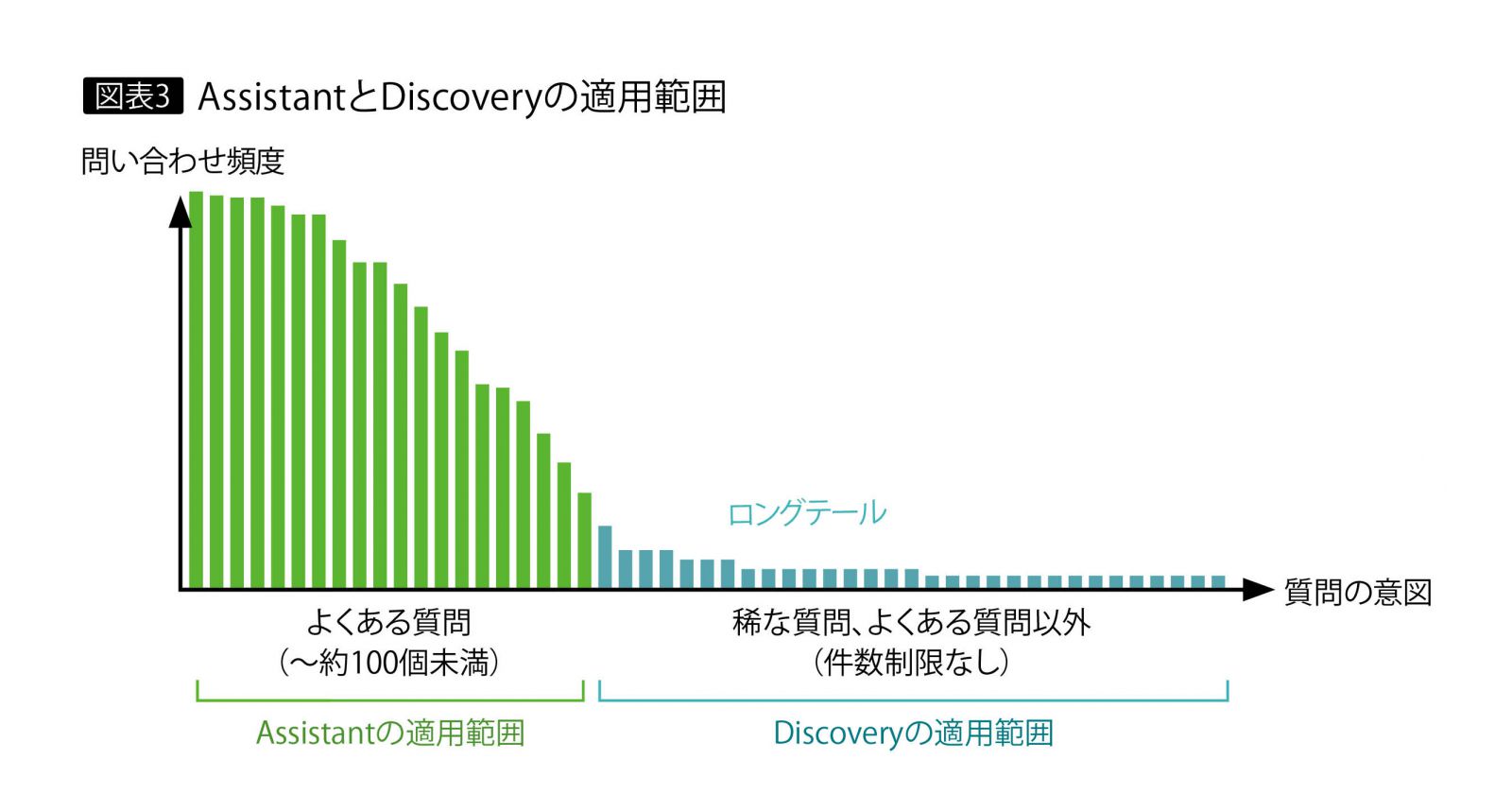
しかし応答すべき回答件数が膨大な場合は、話が違ってくる。Assistantでは、意図分類を実行する単位のIntentは最大2000までという制約がある。この制約数を超えない場合でも、何百という種類のIntentを即座に分類するのは困難なので、いわゆる「よくある質問」を取り出した形で適用するのが望ましい。ただし回答の件数が何百、何千とあるような場合は、Discoveryによる検索で複数の回答候補を提示するほうが効果的である。
図表3に、Assistantの意図分類とDiscoveryによる検索の適用範囲を示した。問い合わせ頻度の高い「よくある質問」に対してはAssistantの意図分類、頻度は低いものの件数が膨大、いわゆるロングテールの問い合わせ対応にはDiscoveryの検索を用いるのが適している。
Discovery適用時の
課題を解決する
Discoveryの適用を検討するうえで課題となるのは、その検索精度が要件を満たすかどうかという点である。具体的には、「検索結果上位○位以内に、期待する文書が何%含まれるか」といったことである。
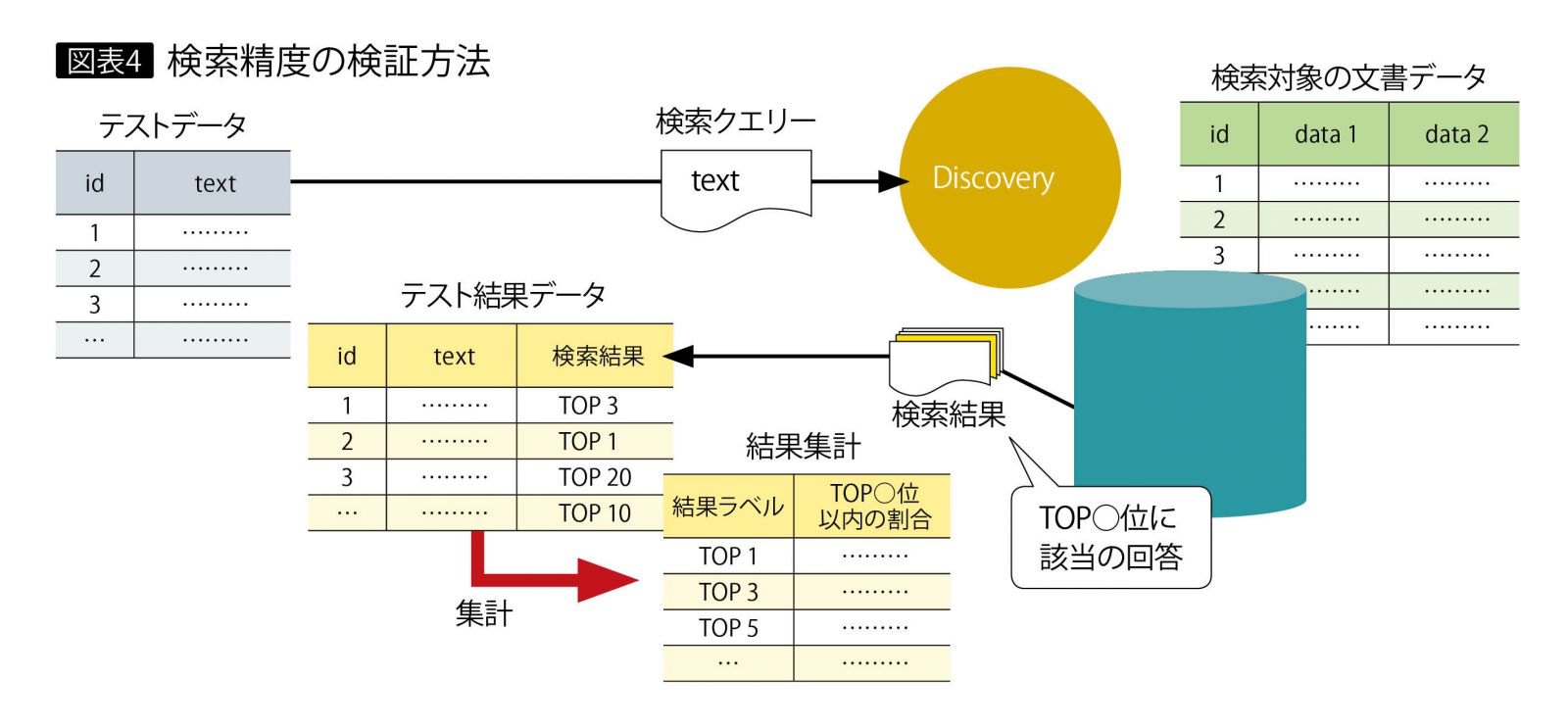
上位○位や何%といった具体的な数値は利用ケースでさまざまだが、Discoveryでは多くの場合、エンドユーザーに対して適切な回答候補が上位何位までに表示されるかが、検証可能な評価軸になると考えられる。そこで検証作業では、サンプルテキストとそのテキストで検索したい回答候補の文書、それに紐付けたテストデータを用意して、検索結果から期待する回答候補が上位何位以内に入ったかを集計する。
Discoveryにデータを投入し、テストデータで検索した結果の精度がすぐさま目標を超えれば何も問題はないが、なかなか簡単にはいかない。そこで検索精度を向上させる手法が必要になる。
Discoveryの検索精度を検証するのに必要なデータは2種類ある。回答となる文書データ(Discoveryに投入し、検索対象とする文書)と、検索・評価するためのテストデータ(問い合わせ質問文と期待される回答をセットにしたデータ)である。この最低限の構成をベースに、トレーニングなどで精度向上を図る。
評価の方法としては、各テストデータの検索結果を取得し、それらを集計し、全体として検索結果上位○位以内に期待する文書が含まれる割合を測定する(図表4)。
Discoveryの
検索精度を向上させる
以下に、実案件でユーザーから提供されたデータを使用し、Discoveryの検索精度の検証、および精度向上を図ったプロセスを紹介する。
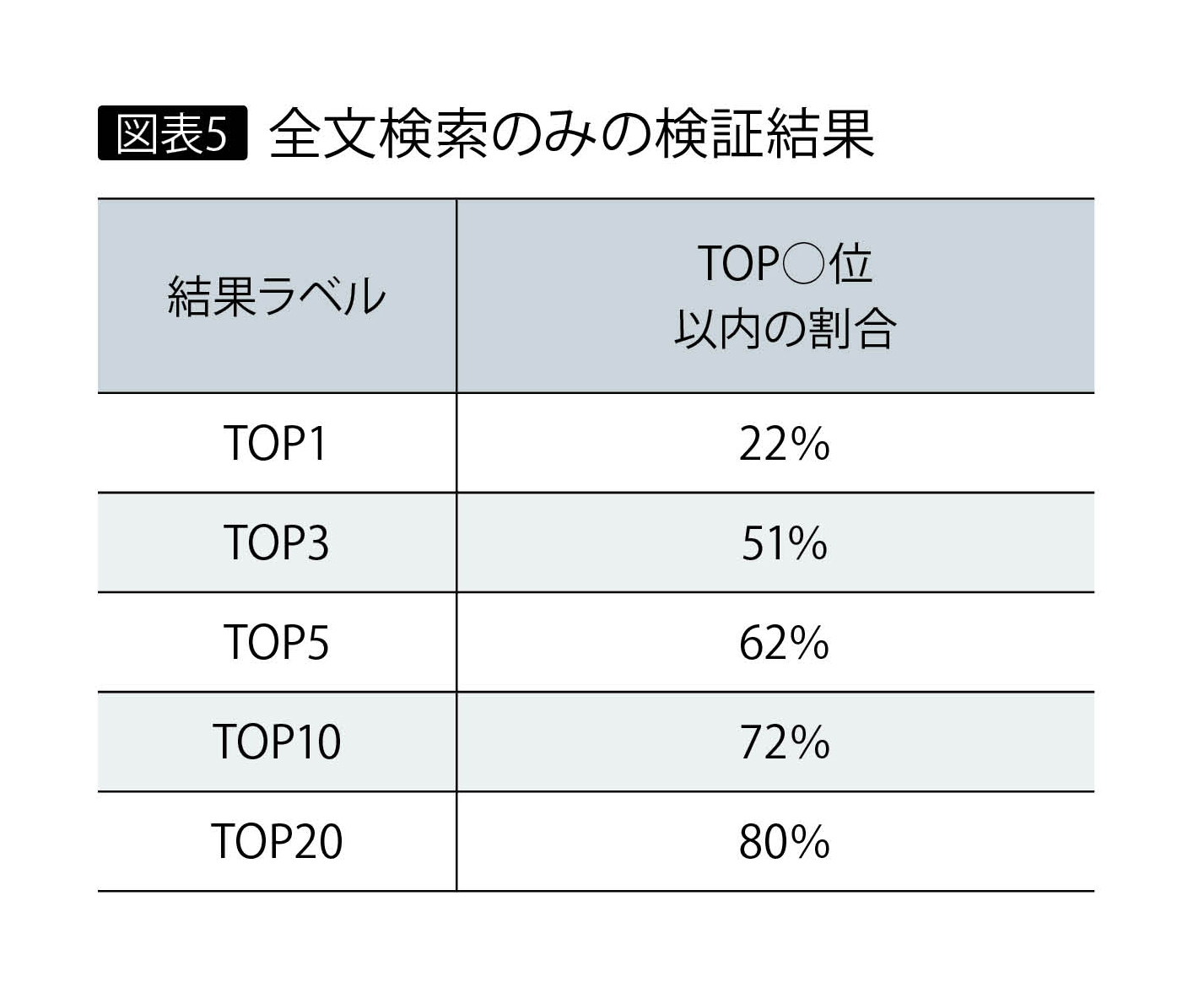
この場合の実データはヘルプページのFAQで、約1000件の文書データを検索対象として使用した。また、各文書に対してユーザーが問い合わせ時に入力すると思われるテキストを作成し、それをテストデータに使用した。目標の検索精度の値は、「検索結果上位3位以内に、期待する回答の入っている割合が80%を超える」と定めた。
最初に回答文書データ、テストデータによる最低限の構成で検証した結果が、図表5である。これは全文検索のみの結果なので、トレーニングによるリランキングを実行すれば、検索精度をさらに改善する余地はある。とは言うものの、目標の上位3位以内で80%を超える結果を得るのは、このままでは難しい。実際の上位3位以内の結果は51%と、目標を大きく下回っている。80%を超えるには、上位20位以内での検索結果をすべて上位3位以内にする必要がある。
たとえばトレーニングによりリランキングすれば、トレーニング前には50位だった回答を20位ぐらいには上昇させられるだろう。それは、「期待した回答が、より上位で検索できるようになった」という意味では、確かに改善である。しかし実際の利用時に、ユーザーに表示される適切な回答の件数に入る、と言うにはほど遠い。
そこでトレーニングに移行する前に、ほかに改善策がないかを検討した。期待する回答が、上位何十位にも入らない誤答データを中心に問題点を探った。そして原因は、テストデータのテキストと期待する回答データの関連が認識されない、両者に類似性が欠けることにあると判断した。検索結果の上位になるのは関連度のスコアが高いデータであり、そのスコアはキーワードとなる特徴的な単語の有無、その組みあわせに左右される。
期待する回答データが圏外になるケースでは、質問文のテキストに含まれる特徴的な単語が回答データに含まれていない。また単純に回答データのテキストが短く、特徴となる単語が少ない場合もある。ヘルプページの回答などは、その回答ページだけでは情報量が足りず、ただリンクを紹介するだけの例も多い。それらをベースに検索するのは難しいと、一見してわかるケースが多く見られた。
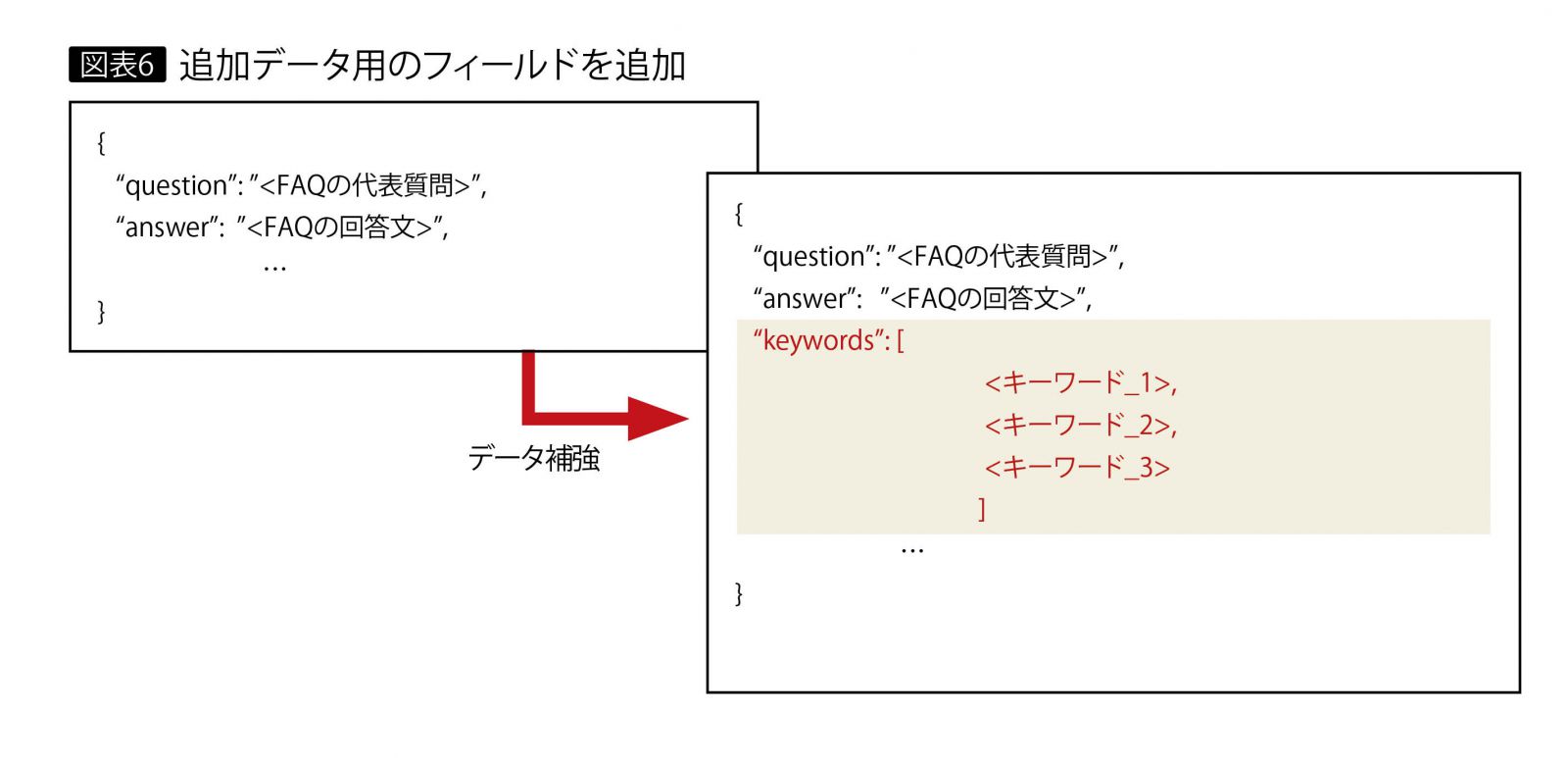
このように質問文と回答データのミスマッチは、データの情報量やキーワード不足に起因する。そこで足りないなら補充することで、検索を容易にする対応策をとった。図表6のように、DiscoveryのCollectionに投入されている文書に追加データ用のフィールドを追加し、更新する(DiscoveryのAPIにデータ更新用のAPIを利用する)。これはWebサイトの運営者が、自らのサイトがGoogleやYahoo!の検索でより上位に表示されるように、タイトルやメタディスクリプションを調整するのに似ている。
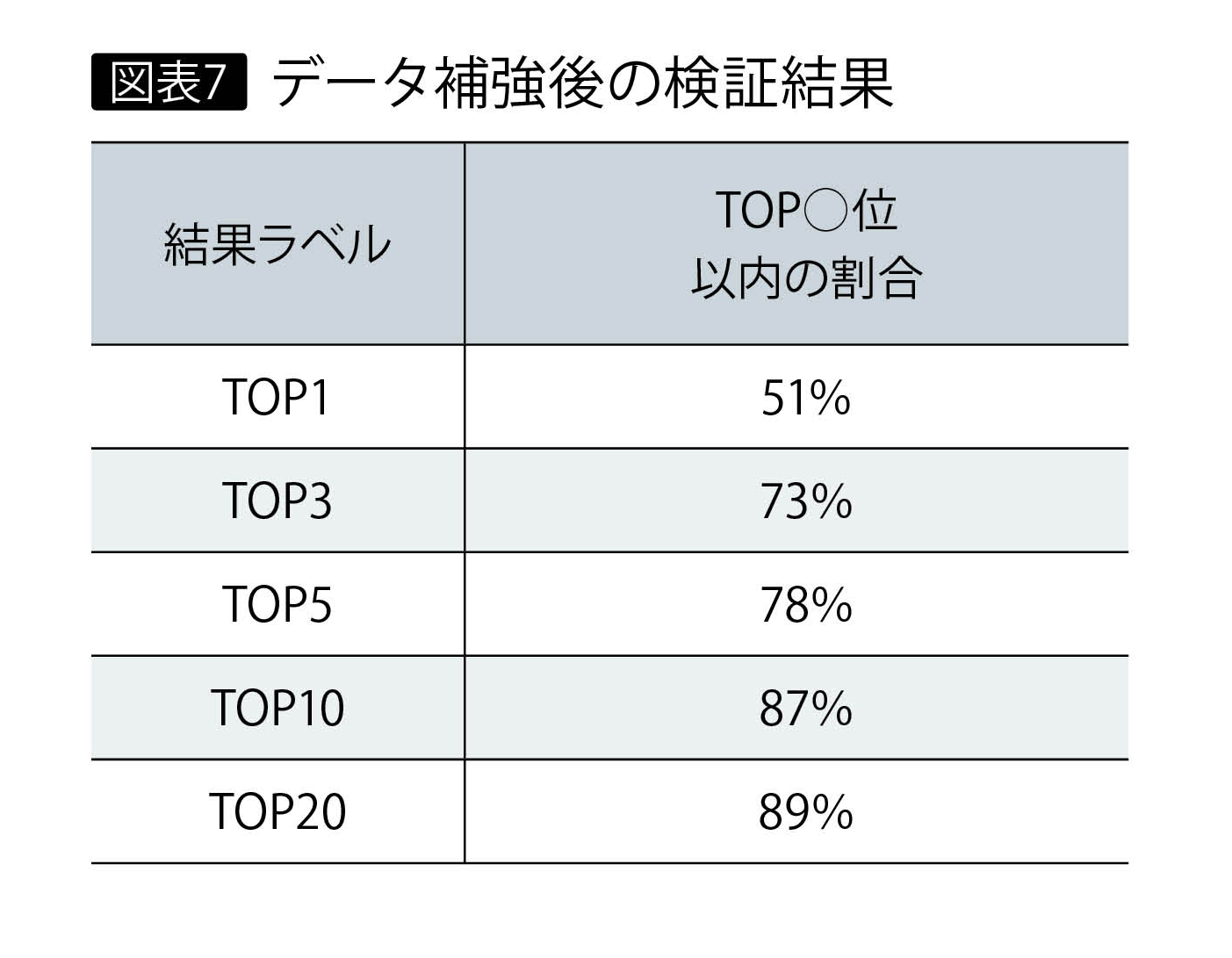
こうしてデータを補強し、同じテストデータを用いて検証を実施した。その検索結果が、図表7である。上位3位以内の割合は73%。目標の精度80%まで、あと7%にまで近づいた。データの補強が有効であることを示すとともに、トレーニングによるリランキングで目標をクリアできる圏内に入ったと考えられる。
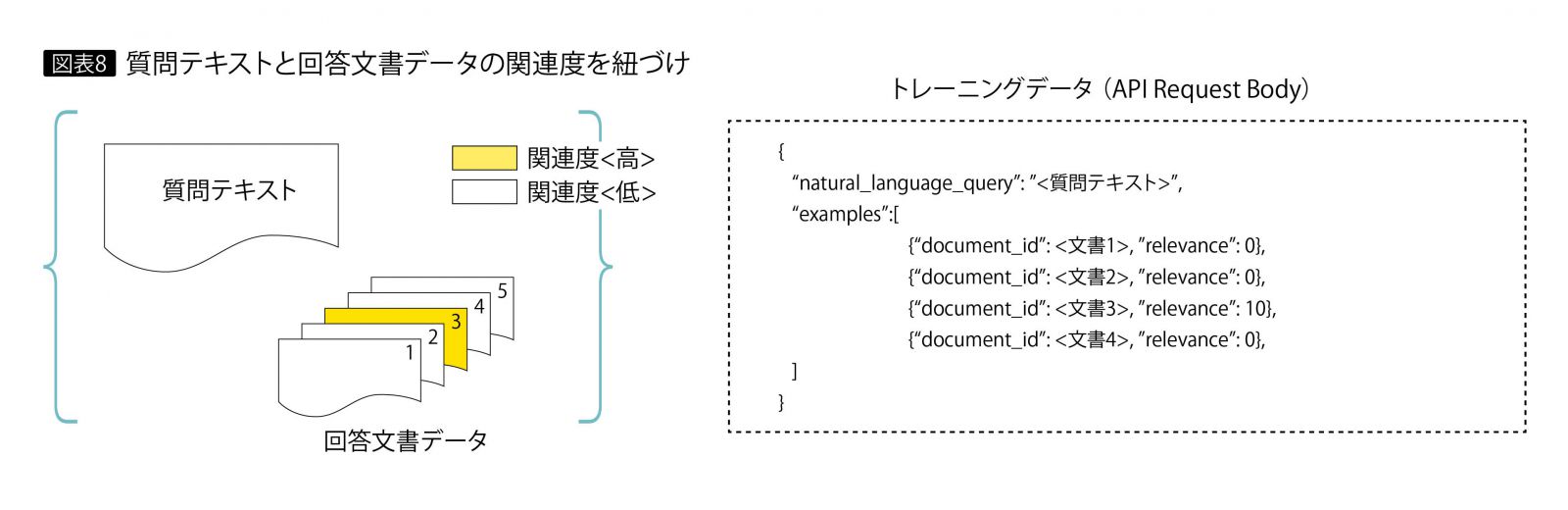
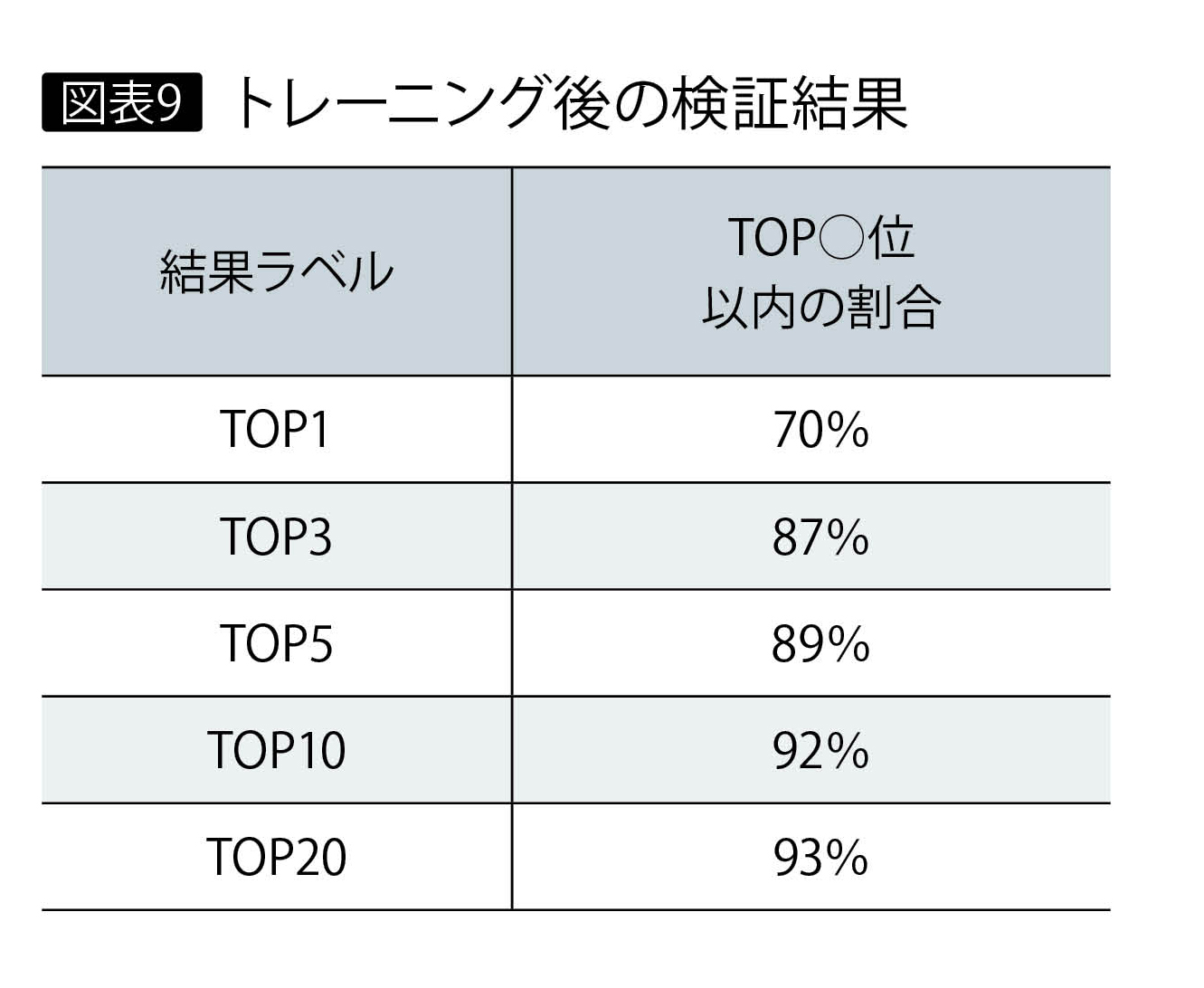
ここでトレーニングを実施した。トレーニング用の質問文をもとに、トレーニングデータを生成し、投入する。図表8のように、質問テキストと回答文書データの間に関連度の値を紐付ける。今回は「関連あり・なし」を、関連度10/0の値で設定している。トレーニング後の検証結果では、図表9のように上位3位以内の割合は87%に上昇し、見事に目標をクリアした。
精度改善の流れは、以下のようになる。
①データの補強、整備による全文検索の精度改善を実施
②トレーニングの実行、リランキングによる検索結果の改善を実施
つまりDiscoveryの検索を支える2つの仕組みのそれぞれで、検索精度を向上させている。検索対象のデータと検索アルゴリズムの双方をチューニングすることが、Discoveryの検索精度向上のポイントとなる。
以上のように、文書データを操作する豊富な機能、トレーニング機能、それらの管理画面やAPIなどのインターフェースを備えたDiscoveryは、検索精度向上のためのチューニングを実施しやすいサービスと言えるだろう。
・・・・・・・・
著者|小栗 開 氏
日本アイ・ビー・エム システムズ・エンジニアリング株式会社
コグニティブ・ソリューション 第2ワトソン・ソリューション
ITスペシャリスト

2015年4月、日本アイ・ビー・エム システムズ・エンジニアリングに入社。成長エリアの技術を担当する部門に配属され、Watson関連の検証・案件に参画。以来、IBM CloudのWatson APIやWatson Explorer を利用したWatson案件に従事。主にWatson製品群の検証、それらを組み込んだアプリ開発を担当。現在もユーザーとの協業によるWatson案件に参画中。
[IS magazine No.20 (2018年7月)掲載]
●特集|Watson Update
Part 1
Watson API&サービスの進化の方向性を探る ~データプラットフォームとAIの完全一体化に向けたロードマップ
Part 2
Watson Knowledge Studio ~機械学習とルールベースで業界固有の用語や表現をWatsonに教える
Part 3
Watson Discovery Service ~質問と回答の類似性に焦点を当て、回答候補をランキング提示する







