前回は、ディープラーニングの中でも、とくに画像認識で利用される畳み込みネットワークを取り上げた。画像認識はディープラーニングの応用分野として、最も研究が盛んで、適用事例も多いエリアである。しかし、そのほかの分野でもさまざまな形での応用が進められており、そこでは畳み込みネットワーク以外の手法が利用されることも多い。
今回は、それらの中から「再帰型ニューラルネットワーク」と呼ばれる手法を取り上げて解説する。
ある時刻の値は、以前の
時刻の変化の延長上にある
再帰型ニューラルネットワーク(Recurrent Neural Network:以下、RNN)は、ニューラルネットワークを拡張して時系列データを扱えるようにしたものである。ここで言う時系列データとは、ある時間の経過とともに値が変化していくようなデータを指し、店舗の日次売上データやホームページのアクセス数履歴、工場設備のセンサデータなど、多種多様なデータが時系列データとして表現される(図表1)。
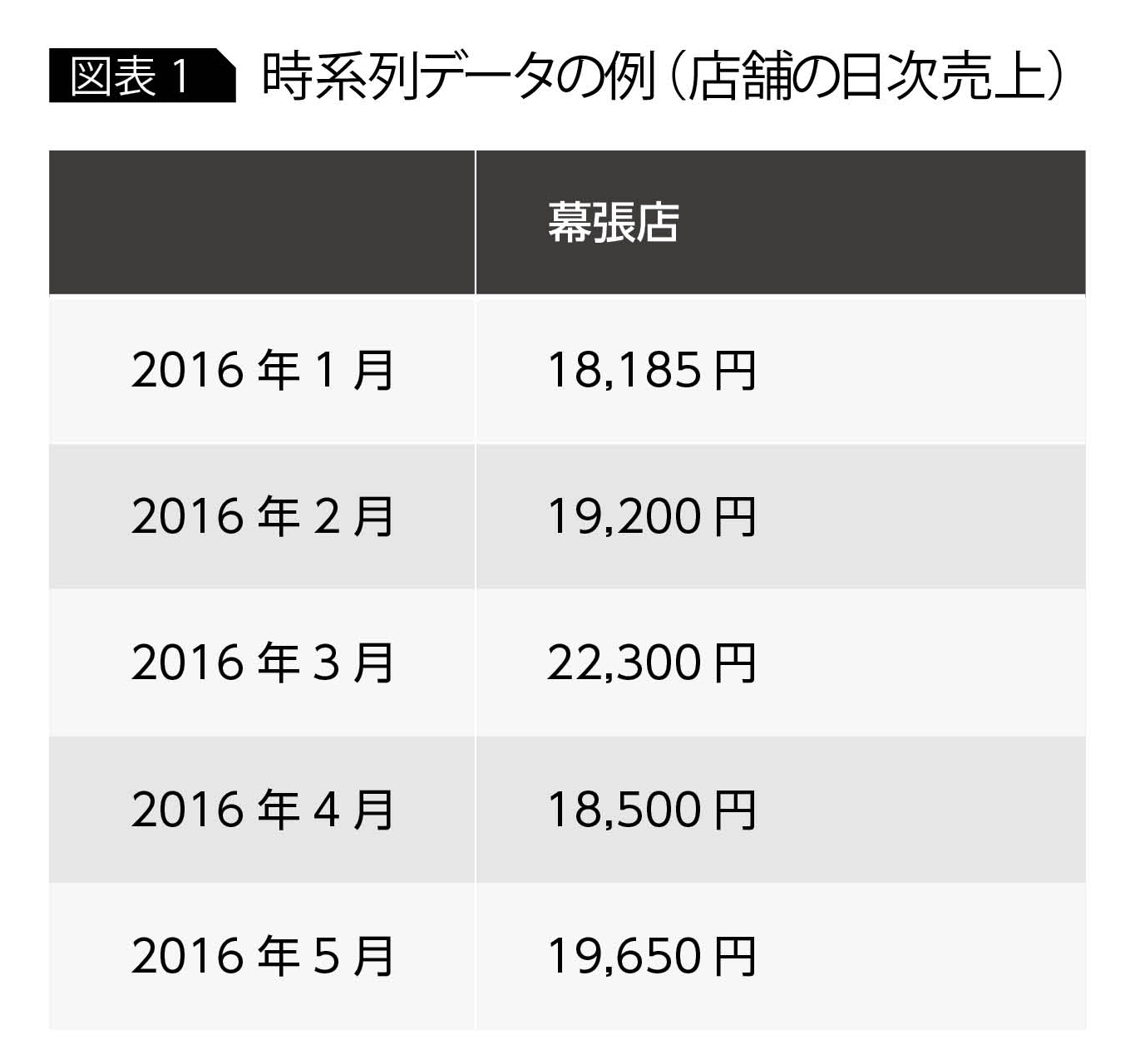
時系列データを分析する際に関心の対象となるのは、そのデータがどのようなトレンドや周期をもち、それに従って今後どのように変化するかという点である。
そのためにARIMA、GARCH、移動平均法などさまざまな手法が開発されているが、すべてに共通する考え方として、ある時刻(t)における値は、以前の時刻の値
(t-1、t-2、t-3、…)の変化の延長上として表現できるということである。
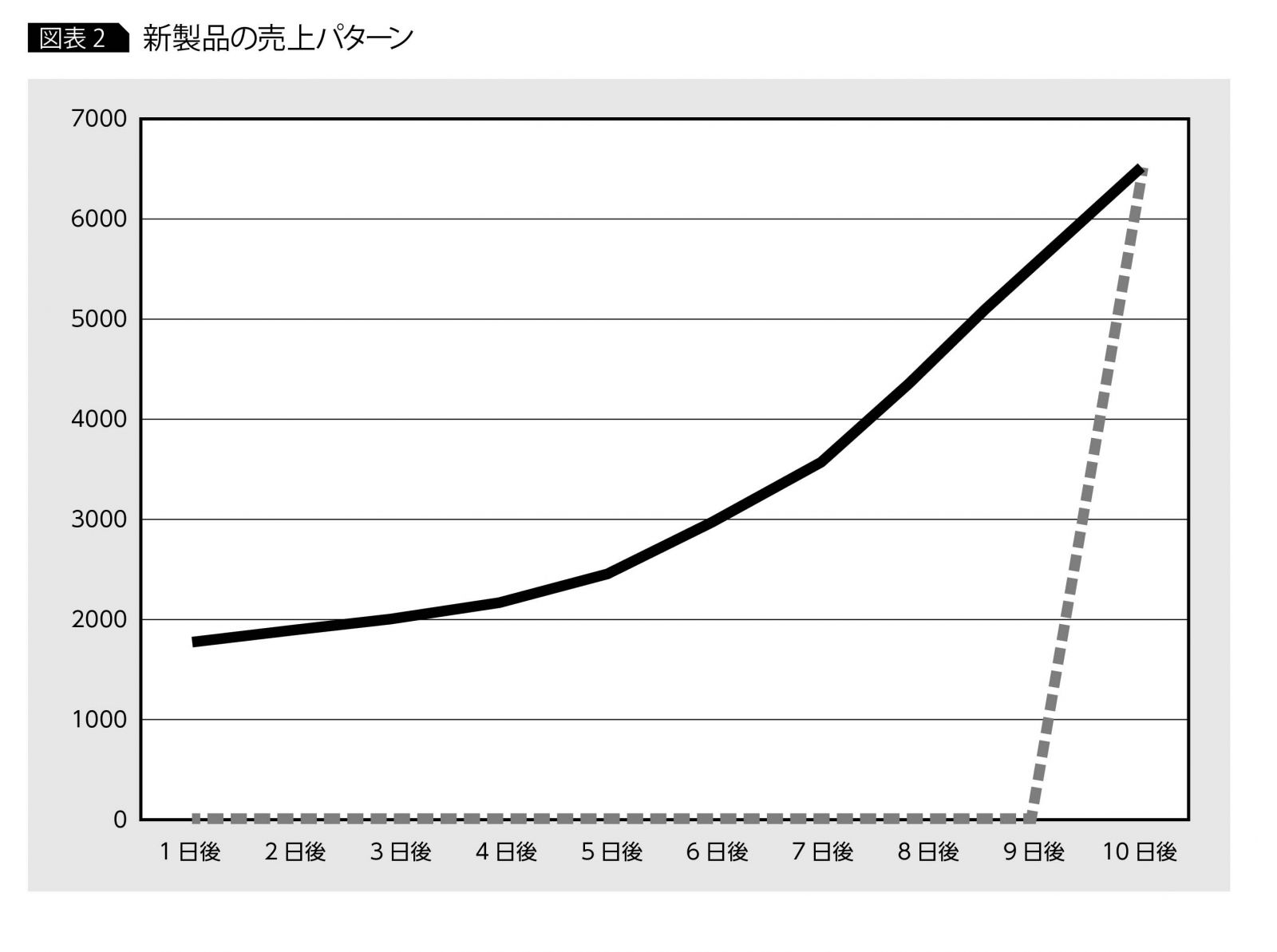
たとえば、ある新商品の日次売上の推移を考えてみると、通常、発売10日後に急に売れ出すことは考えにくく、ピークに達するまで一定の増加傾向を示し、ピークを過ぎると何らかの減少傾向を示しながら下降していくというパターンをとることが多い(図表2)。時系列分析では、この増加傾向・減少傾向を、ある時刻(t)とそれ以前の時刻(t-1、t-2、t-3、…)の関係で数式化することが一般的である。
RNNでも、時刻(t)の値がそれ以前の時刻(t-1、t-2、t-3、…)の値の影響を受けて変化するものと考える。この時刻間の関係をRNNがどのように表現するかを見てみよう。
再帰型ニューラルネットワークのアーキテクチャ
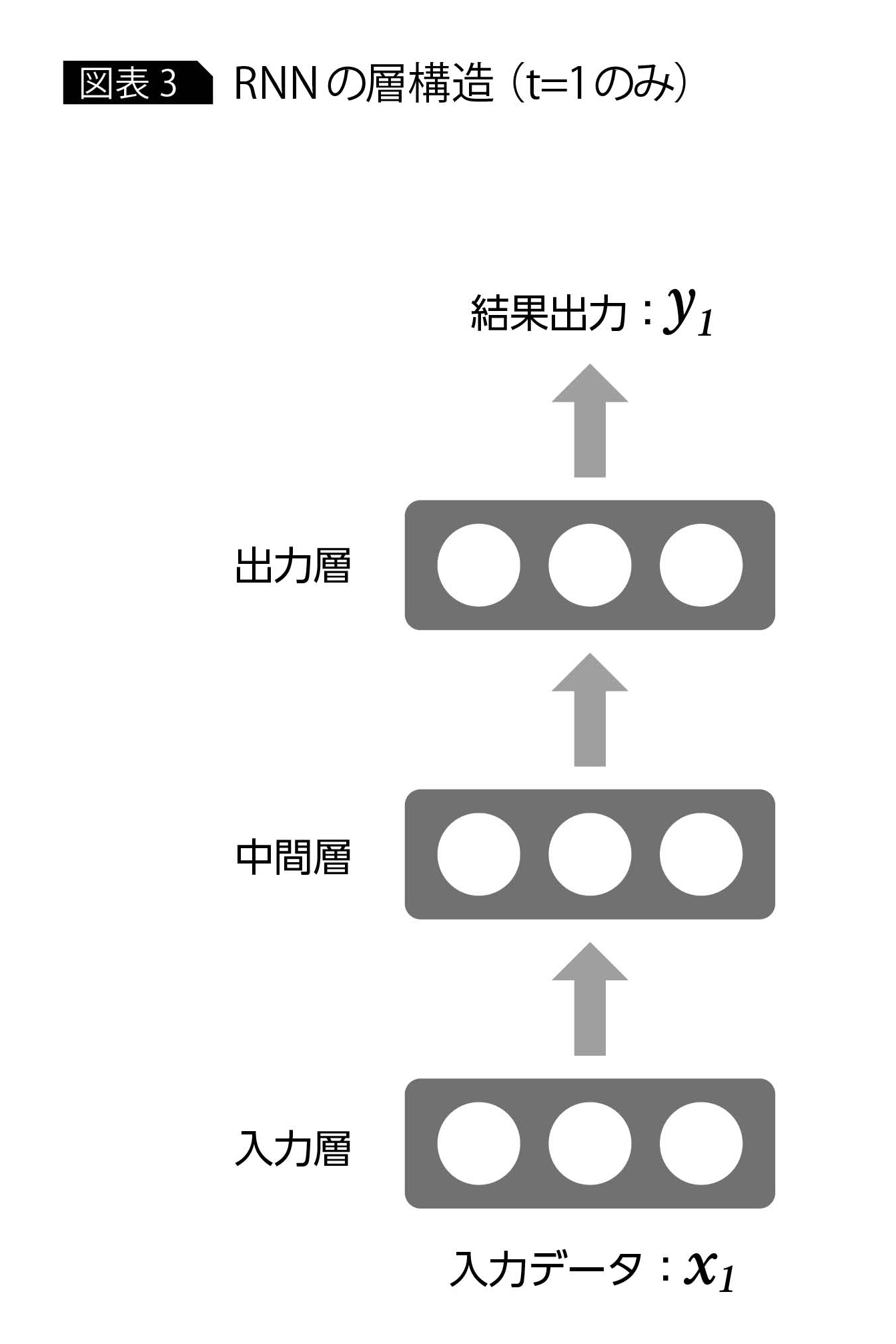
RNNもニューラルネットワークの一種であるため、入力層、中間層、出力層という3種類の層をもつ。入力層では、時刻ごとにデータを受け取り、出力層では時刻ごとの結果(たとえば分類問題の場合は分類カテゴリの確率値)を出力する(図表3)。時刻ごとに入出力が発生するという特徴はあるが、入力層と出力層がそれぞれデータ入力、結果出力という機能をもつ点においては、通常のニューラルネットワークと同様である。
RNNで大きく異なるのは、中間層の構造である。RNNの中間層は、ある時刻の中間層からの出力を次の時刻の中間層に伝えるためのパスをもつ。それによって時刻tの中間層は、同じ時刻tの入力層からのインプットに加えて、前の時刻t-1の中間層からのインプットも受け取ることになる(図表4)。
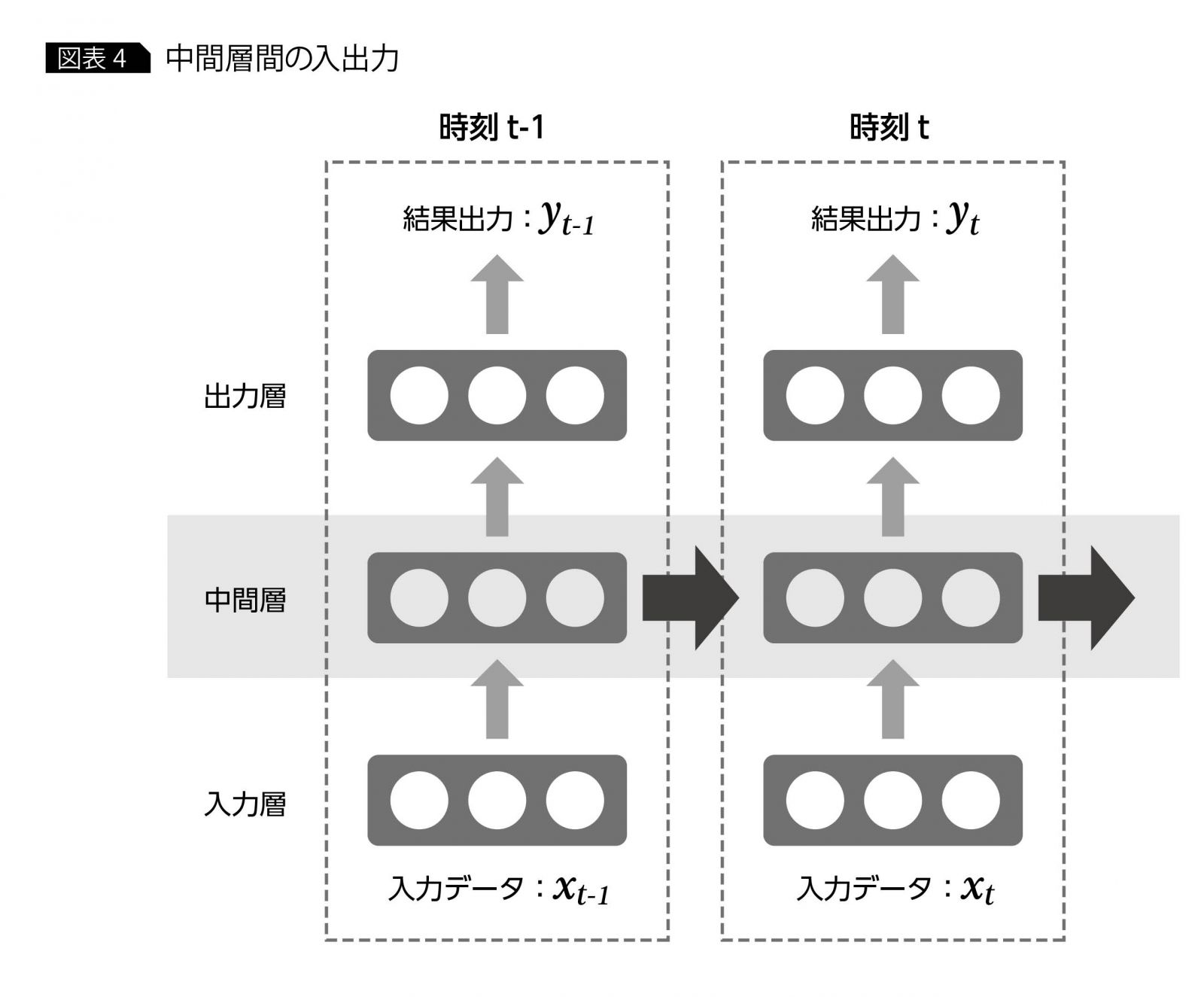
この前の時刻からのインプットがあることによって、時刻間の影響を考慮したニューラルネットワークを作ることが可能となっている。これを数式で表現すると下記のようになる。
中間層では、同時刻の入力データxtと前時刻の中間層出力zt-1をそれぞれ重みで線形和したもの(W(in) xt+Wzt-1)を入力としてとり、活性化関数 f(ニューロン発火を制御する関数。連載第1回を参照)で変換した値を層からの出力値としている。このzt-1を時刻tでの入力の一部とすることにより、過去時刻の値が再帰的に未来時刻へと影響していくことになる。
一方、出力層では通常のニューラルネットワークと同様、前段の中間層出力の線形和(W(out) zt)を関数f(out)で変換した値
f(out) (W(out) zt) を最終出力とする。関数 f(out) は、RNNに解かせたい問題によってさまざまなものを設定可能である。
たとえば、次の日の売上予測であれば、売上の数値を出力するような関数、今までの文脈から次にくる言葉を予測する言語モデルなどであれば、言葉の出現確率を出力するような関数(softmaxと呼ばれる)である。
再帰型ニューラル
ネットワークの学習方法
次にRNNの学習を考える。RNNでデータによる学習対象となるのは、上記の中間層、出力層の重みW(in)、W、W(out)(以降、全パラメータを含めてwと記述する)である。
RNNの学習でも、RNNからの出力値と正解値の誤差Eを計算し、その誤差の値が小さくなるように勾配降下法を使って重みwをチューニングしていく。
勾配降下法の仕組みを簡単におさらいしておくと、最初に重みwの初期値をランダムにとり、そのときの誤差Eを計算する。その後、誤差Eの初期値wでの勾配(傾き)を計算し、勾配の値が正だと重みwを少し小さくし、負だと大きくするようにwのチューニングを行う。その方法を図式化したのが図表5である(詳しくは連載第1回を参照)。
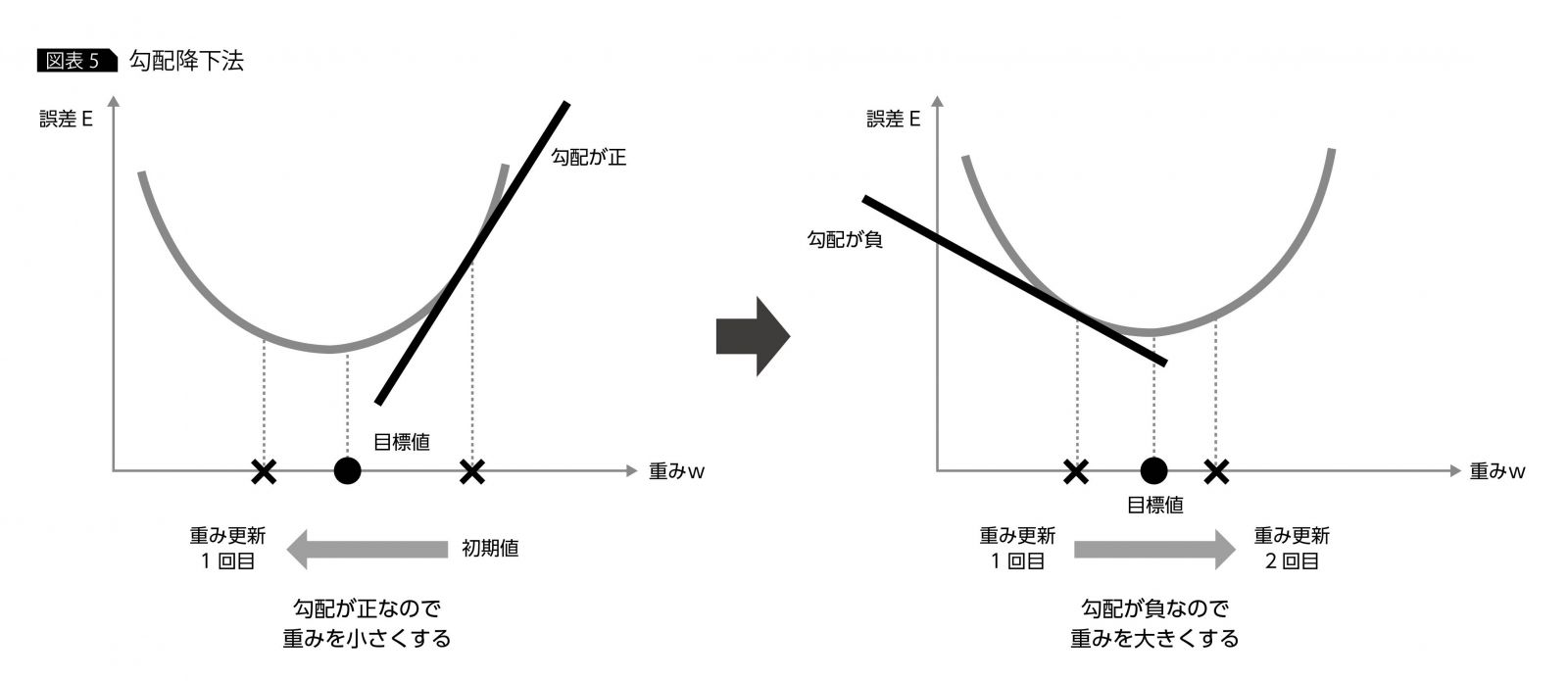
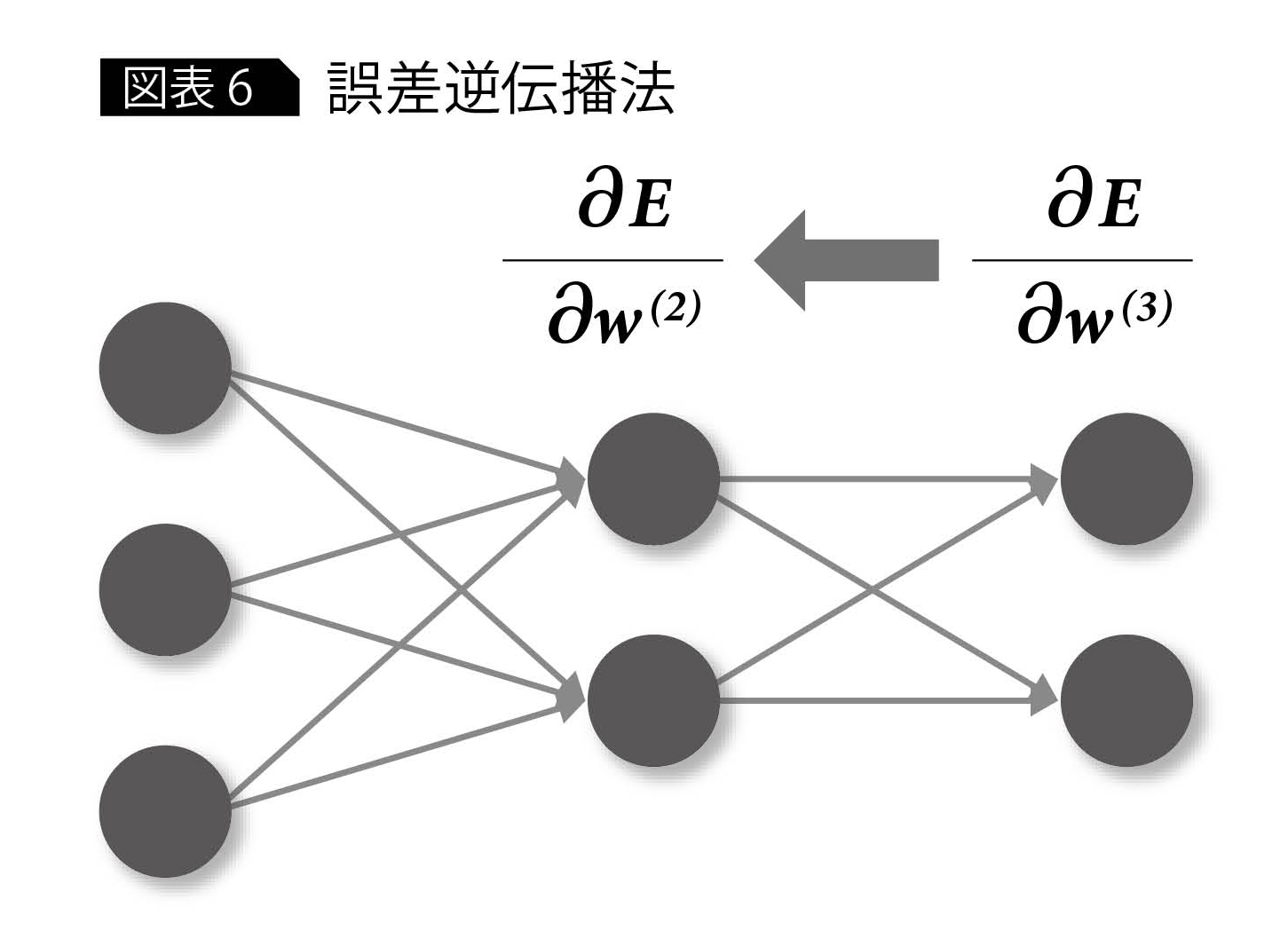
ここで肝となるのは、誤差Eのwにおける勾配情報である。一般的なニューラルネットワークの場合、勾配降下法という方法を使って、出力層の重みwから入力側の重みを順々に求めた。
ただし、RNNの場合、中間層の時間経過を考慮しなければならないので、そのままでは誤差逆伝播法を適用できない(図表6)。そこで、RNN用に時間経過を表現できるような形に改良された手法が何種類か提案されている。
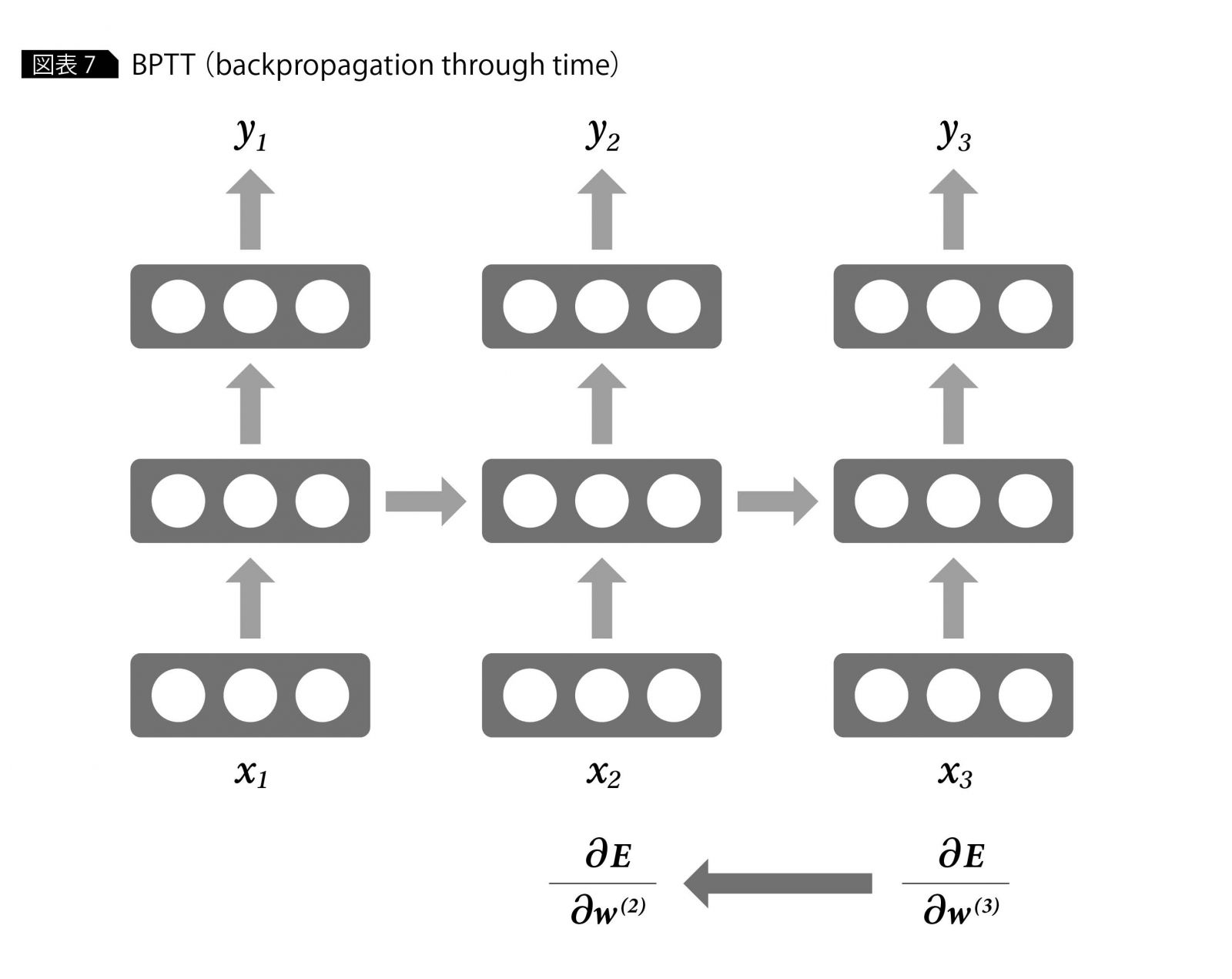
その中でもシンプルでよく使われているのがBPTT(backpropagation through time)という手法で、これは、RNNのネットワークを中間層出力を介して時間方向に展開する方法である(図表7)。それによって、RNNを時間経過を含めて1つの大きなニューラルネットワークとみなすことにより、誤差逆伝播法を適用することが可能となる。 この方法によって求めた勾配情報により、勾配降下法を使ってwのチューニングを行う。
改良を加えた
LSTMネットワーク
これまでRNNのアーキテクチャおよび学習方法を見てきたが、実際の適用時には、そのままの形ではなく、若干の改良を加えたネットワークを利用することが多い。とくにRNNは遠い過去の中間層出力を反映するのが難しいという弱点をもっているため、それを改善したLSTM(Long Short Term Memory)と呼ばれるネットワークがよく利用されている。
LSTMは、神経科学の短期記憶、長期記憶からヒントを得てデザインされたものである。短期記憶とは、初めて聞いた電話番号を記憶するような場合で、数分程度の一時的な想起は可能であるが、数日程度の長い期間がたつと忘れてしまうような種類の記憶である。
一方、長期記憶は、自宅の電話番号のようなものであり、こちらは何年もの期間にわたって記憶されている。LSTMは、RNNの中間層出力に対して、記憶期間の長さの考え方を導入することにより、遠い過去の出力の影響を保持することを可能にしている。
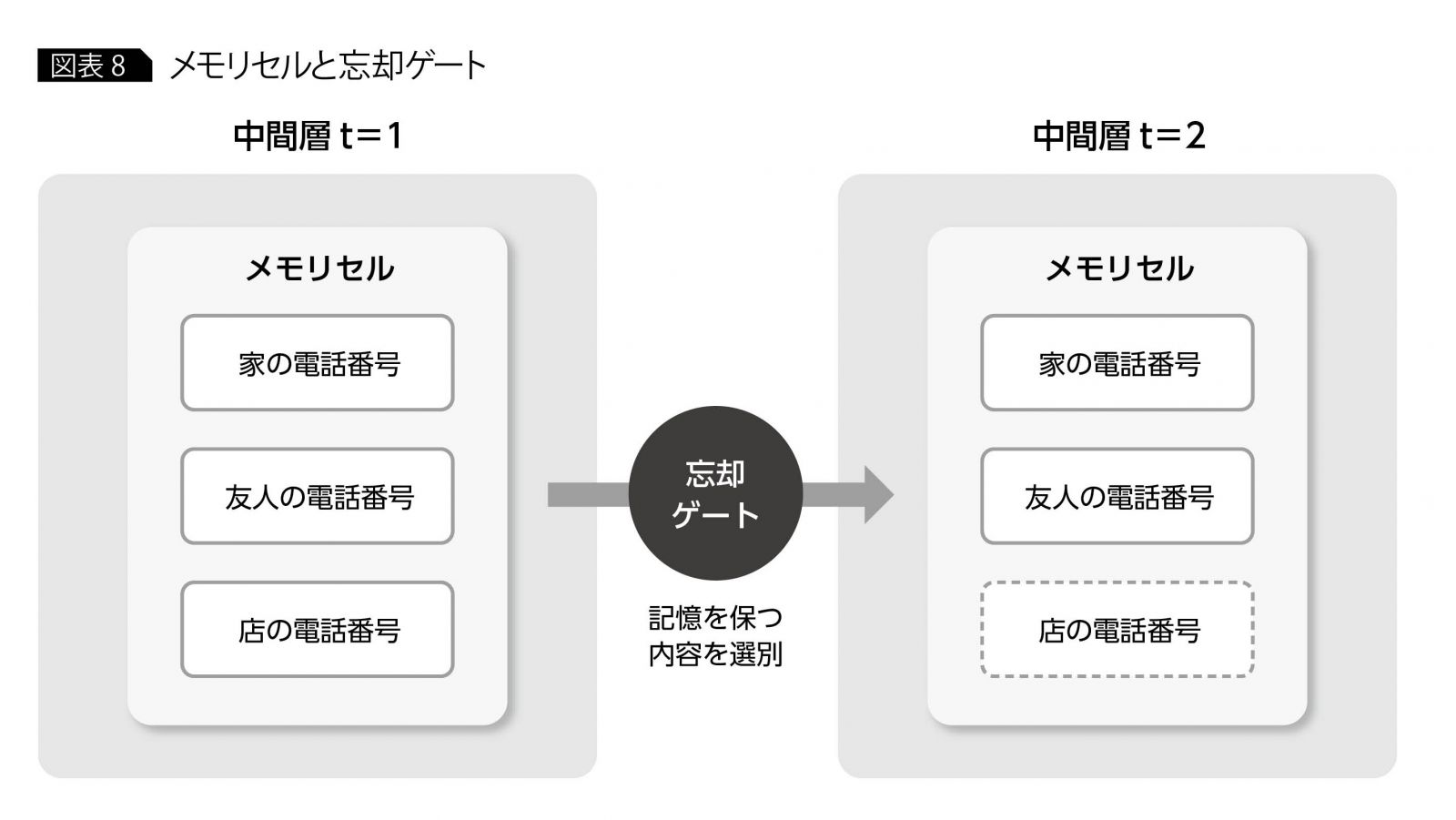
LSTMの仕組みを少し詳しく見てみると、RNNとの違いで最も目につくのはメモリセルと呼ばれる中間層の状態を保持するパラメータである。メモリセルは、いくつかの次元をもち、時刻経過とともに変化する性質をもつ。
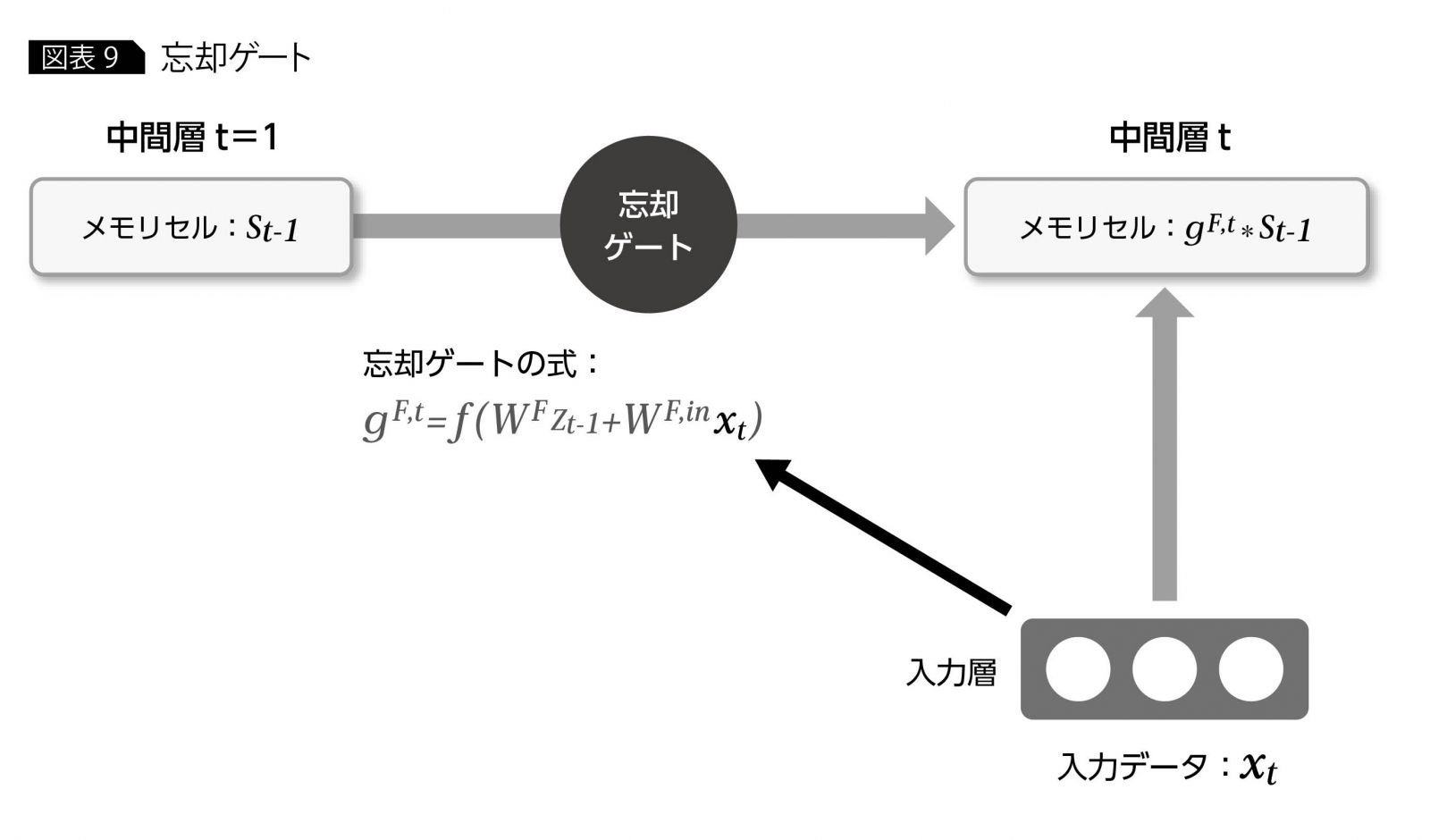
メモリセルの各要素は、それぞれ家の電話番号、友人の電話番号、店の電話番号のようなものであり、時刻変化とともに保持すべき情報と忘れるべき情報とを含んでいる。時間経過による各要素の変化を制御するのが、忘却ゲートと呼ばれる関数であり、時刻経過のたびに家の電話番号は記憶に残し、店の電話番号の記憶を忘れるという変化をもたらしている(図表8)。
ここで、忘却の仕組みを考えてみると、各時刻で重大な影響のある入力があれば(たとえば、忘れかけている店の電話番号をもう一度使用するような場合)、メモリセルの重要でない内容を忘れたり、逆に記憶を強化したりという制御が必要となる。そのため、忘却ゲートの関数は、現在時刻の入力データの影響が加味されたものとなっており、そのようにして計算された忘却ゲートの値が前時刻t-1のメモリセルに作用することによって、現在時刻tのメモリセルの制御がなされる(図表9)。
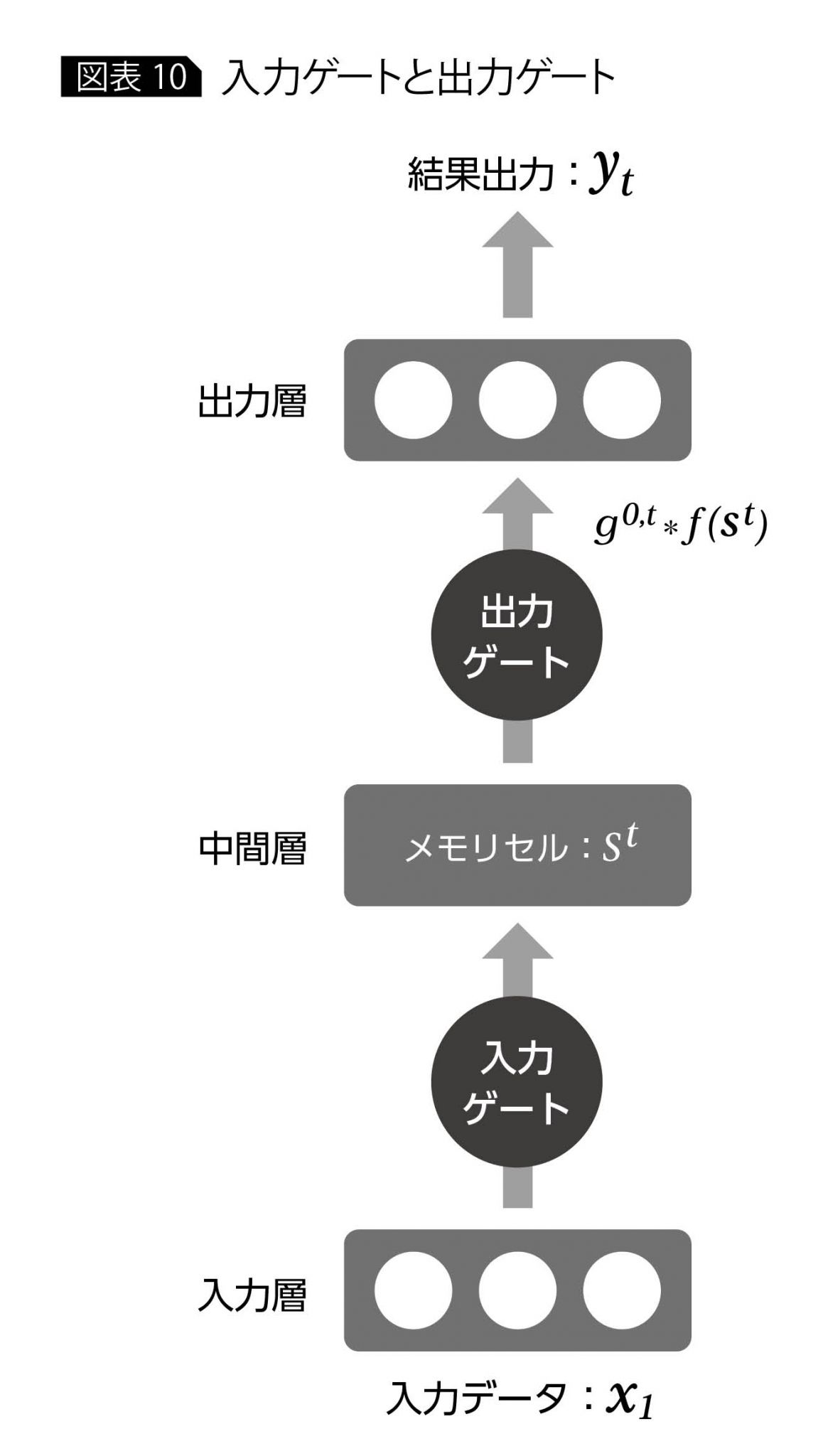
以上のメモリセルと忘却ゲートがLSTMのコアとなるアイデアであるが、LSTMでは中間層の入出力データに対してもそれぞれ入力ゲート、出力ゲートが設けられており(各ゲートの構成方法は忘却ゲートと同様)、各時刻でどれくらい新しいデータを反映するか、または出力するかということが制御できるようになっている。
LSTMの中間層の出力は出力ゲートg0,tとメモリセルstの活性化関数fを用いて
g0,t*f(st)のように表わされる。なお、出力層はRNNと同様、ネットワークの目的に応じてさまざまな関数を選択できる(図表10)。
LSTMの学習対象となるのはRNNの重みに各ゲートを構成する重みを加えたものであり、学習方法はRNNと同様に勾配降下法による。
再帰型ニューラル
ネットワークの適用例
最後に、RNNの適用例として研究が盛んな自然言語処理について触れてみたい。
数理的に自然言語を扱う際に、最も基本となるのが言語モデルで、これは、ある一定のボキャブラリのもとで、個々の文章が生成される確率を与えるものである。
1つの文章の構造を考えてみると、あるワードが現れる確率は、それ以前に文章内に現れたワードに依存すると考えられる。たとえば、「私は公園を歩く」という文章なら、最後の「歩く」というワードは、「私は 公園を」という前2つのワードを前提として現れている。つまり、全ボキャブラリの中からいきなり「歩く」というワードが現れる確率を考えるよりも、その前にある「私は 公園を」というワードが現われている条件下での「歩く」の確率を考えるほうが、より現実に即した言語モデルとなる。
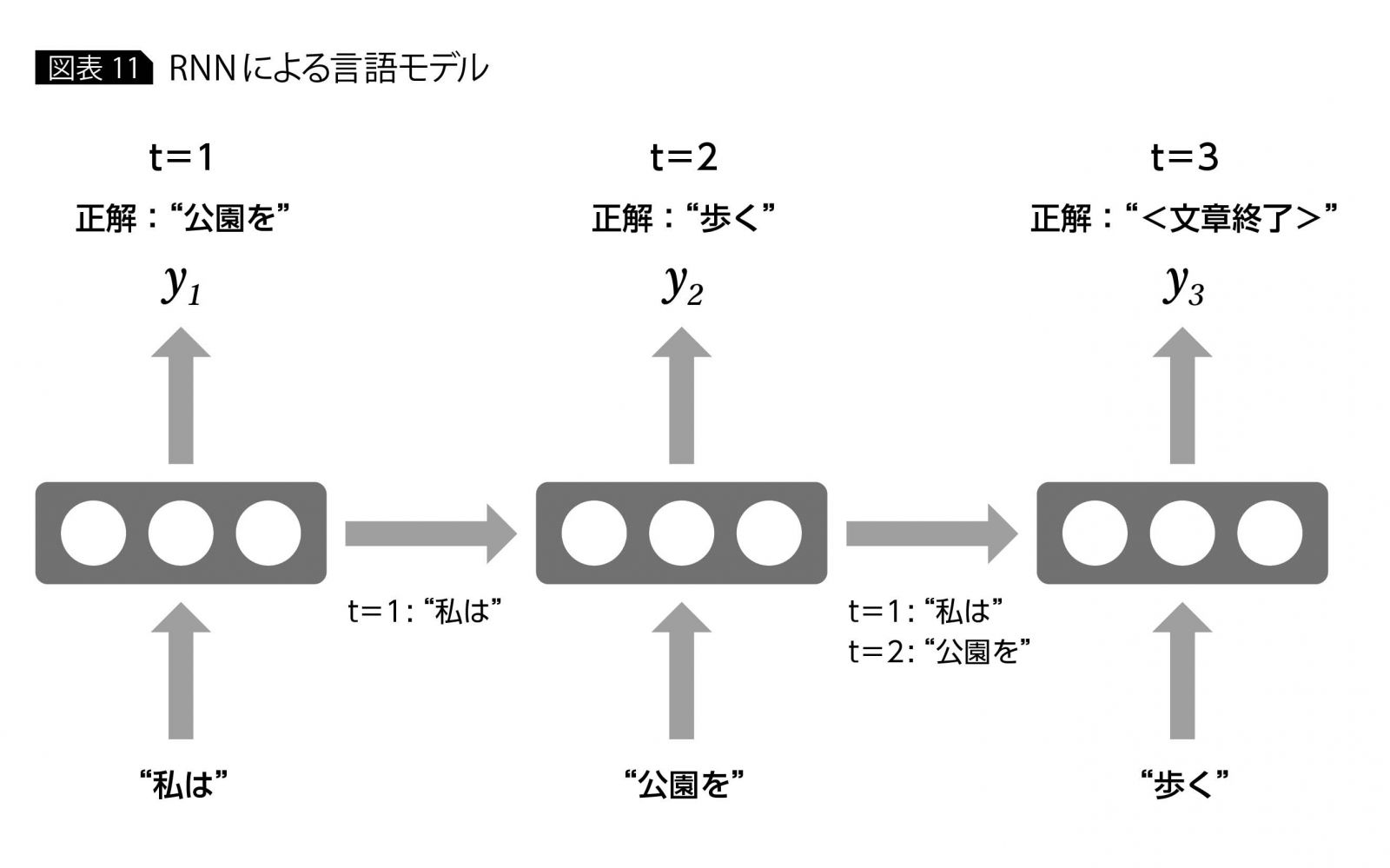
このアイデアから、言語モデルでは文章内の各ワードが発生した状態で、次にどのようなワードがくるかをモデル化する。「私は 公園を 歩く」という文章を生成する例では、「私は」の時点で「公園を」というワードを、「私は 公園を」の時点で「歩く」というワードを予測する。
これをRNNに適用すると、 入力はx1=“私は”、x2=“公園を”、x3=“歩く”となり(実際には各ワードはbag-of-wordsなどで数値ベクトル表現されている)、ラベル(正解)t1=“公園を”、t2=“歩く”、t3=“<文章終了>”で、x1、x2、x3のRNNからの出力がt1、t2、t3に近くなるようにRNNの重み学習を行う(図表11)。
現在では、上記で述べた言語モデルと類似の発想でRNNによる機械翻訳や文章要約などさまざまな形での応用が進められている。また、RNNは基本的に時系列データであれば、どのようなデータでも扱うことが可能である。
たとえば、経済・ファイナンスの分野への適用も可能で、すでに株価のボラティリティ予測などの研究例などもある(https://arxiv.org/abs/1512.04916)。とくにさまざまな機器から出されるセンサ出力なども時系列データの形で捉えられるため、IoT分野への応用に対しても大きな可能性を秘めていると考えられる。
*
本連載では、これまでディープラーニングの理論的な側面に触れてきたが、次回は実務への応用という観点からライブラリを使ったプログラム実装を取り上げる予定である。言語はpythonを使い、畳み込みネットワークによる画像認識プログラムの実装を題材に解説を行いたい。
・・・・・・・・
著者|植田 佳明 氏
日本アイ・ビー・エム システムズ・エンジニアリング株式会社
アナリティクス・ソリューション
アドバイザリーITスペシャリスト

2001年、日本IBM入社。2005年に日本アイ・ビー・エム システムズ・エンジニアリングに出向し、当初はIAサーバー基盤、WebSphere Application Server関連のプロジェクトや技術サポートを担当。2012年よりSPSSを中心としたアナリティクス製品のサポートやデータ分析プロジェクトに従事し、近年ではWatson・ディープラーニングといった人工知能、コグニティブ関連の活動にも携わっている。
[IS magazine No.14(2017年4月)掲載]
・・・・・・・・
連載 ディープラーニング入門 全4回 CONTENTS
第3回 再帰型ニューラルネットワークの「基礎の基礎」を理解する
・・・・・・・・