[1]Cloud Pak for Data as a Serviceとは何か
Cloud Pak for Dataという名前を始めて聞いたという方もおられるかと思うので、Cloud Pak for Data as a Serviceが何かを説明する前に、Cloud Pak for Dataについて説明したい。
Cloud Pak for Dataは、一言で言えば、企業や組織がAIを活用するために必要な、データの収集から、整備、分析、活用までをトータルにサポートするためのエンド・トゥー・エンドのデータ&AIプラットフォームである。
IBMでは、お客様のAI活用のご支援を通して、企業や組織がビジネスにおいてAIを十二分に活用するためには、Collect、Organize、Analyze、Infuseの4つのステップが必要であることを認識し、それらを総称して「AI Ladder(AIのはしご)」と名付けている。Cloud Pak for Dataはその4つのステップをサポートするための機能を提供するものである。企業はこの4つのステップを経ることで、企業や組織において適正な形でのAI活用を実現することが可能となる。

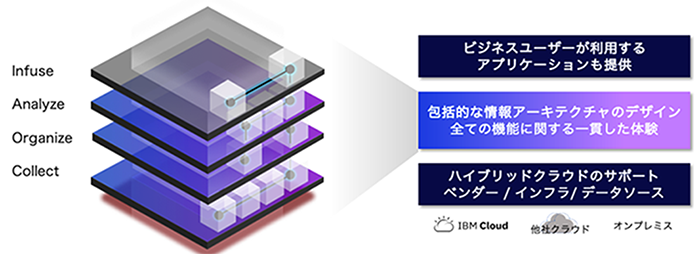
Cloud Pak for Dataは、ソフトウェア、ハイパーコンバーチド・インフラストラクチャ(HCI)、as-a-Serviceの大きく3通りの形態で提供されており、Cloud Pak for Data as a ServiceはCloud Pak for Dataで提供される機能をIBM Cloud上でフルマネージドサービスとして提供している。
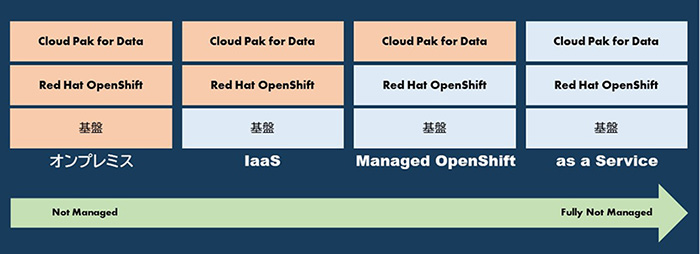
Cloud Pak for Data as a Serviceは現在、Watsonを始めとしてAI Ladderのステップに対応するさまざまなサービスから構成されている。それらはIBM Cloudのカタログ上で提供されている個々のサービスと同じであり、サービス単体での利用も可能である。ユーザーは単一のサービスから利用できるため、スモールスタートで分析プロジェクトを始めることができる。
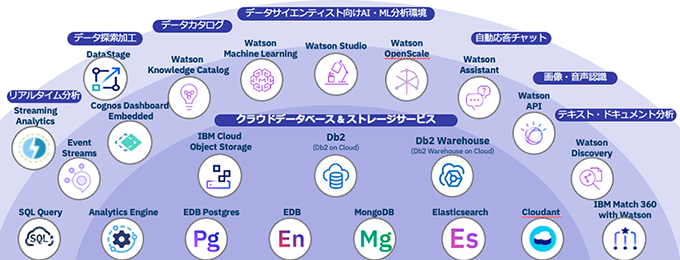
[2]Watson Studioとの連携による拡張、Cloud Pak for Data as a Serviceの詳細
従来より提供されてきたWatson Studioは、Webブラウザ上で多様なツールや言語、ライブラリを活用したカスタム・モデルの開発およびビルドを行えるAI統合開発環境である。
また、AIモデルの実行環境を提供するWatson Machine Learningやデータカタログ機能を提供するWatson Knowledge Catalogなどと連携させることで、データ整備や開発したモデルの展開までを統合的に行う環境を構築することができる。これらのサービスはCloud Pak for Data as a Serviceとして、より統合されたインターフェースの下、関連サービスとともにシームレスに利用可能となった。
Watson Knowledge Catalog、Watson Studio、Watson Machine Learningの3サービスは、Cloud Pak for Data as a Serviceにおいて、データの管理、データの分析、モデルの実行およびモデルのデプロイを行うためのコア・サービスと位置づけられている。
関連サービスとしては、ツールまたは計算能力を追加することで コア・サービスを補足するサービス(例:ダッシュボード機能を提供するCognos Dashboard Embedded)や、データを保管するためのIBM Cloudデータベース・サービス、事前構築済みのモデルを提供するWatsonの各種APIサービスが含まれる。
従来通り、Watson Studioや Watson Knowledge Catalogは単体での利用も可能だが、コア・サービスや関連サービスと組み合わることで、end-to-end のフルマネージドなデータ&AI活用基盤として利用可能となる。
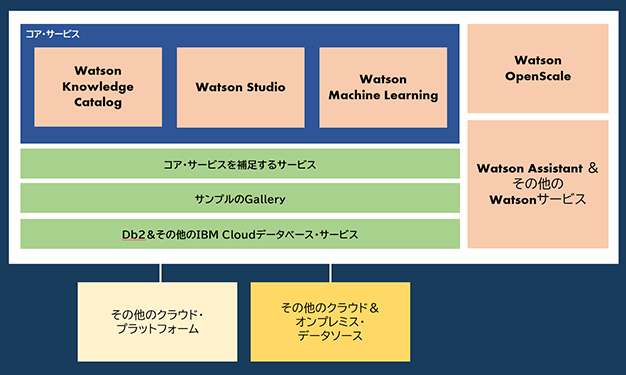
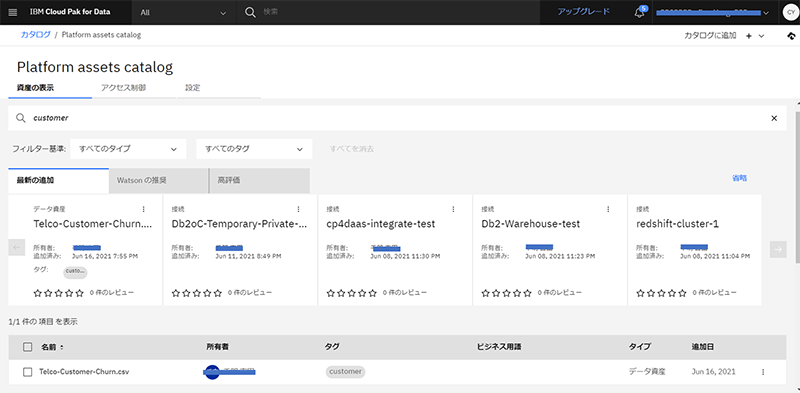
また、Cloud Pak for Data as a Serviceでは統合されたインターフェースの提供に加えて、組織全体でデータ活用を支援する機能が強化されている。多くの場合、企業では多様なデータソースを保有している。そのため、データ活用に際して、それらのデータソースへ安全かつ効率的にアクセスすることが重要となる。
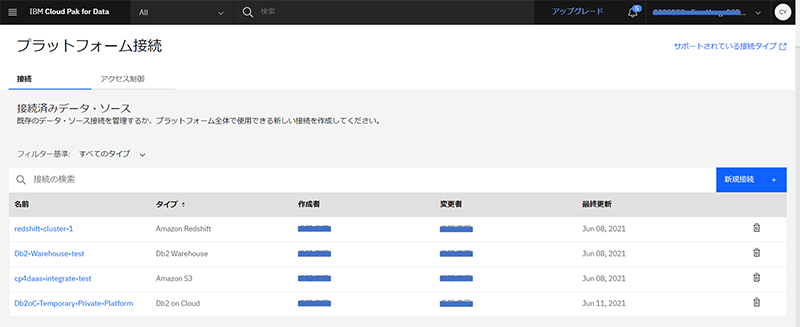
Cloud Pak for Data as a Serviceでは、組織全体でデータソースへの接続を共有するための機能であるプラットフォーム接続を利用できる。従来より、Watson Knowledge Catalogの機能を用いて、目的に応じたカタログを作成し、データを管理できたが、このカタログとは別に、組織全体で共有したい接続を管理するための包括的なカタログとしてプラットフォーム資産カタログを作成し、このカタログで接続を管理可能となった。
また、ガバナンス成果物を定義することで、保護ルールの適用による機密データのマスク、ビジネスの目的に応じたデータの検索性の向上など、組織における効率的なデータ管理を支援する。
[3]IBM Cloud Satelliteとの連携によって実現できること
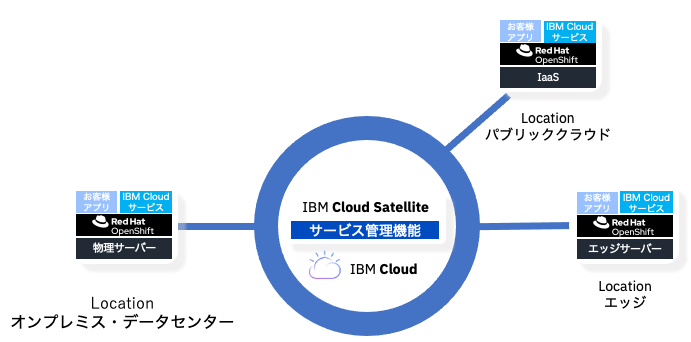
2021年3月にサービス開始されたIBM Cloud Satelliteは、IBM Cloud経由でRed Hat OpenShiftをマネージドサービスとしてさまざまなデータセンター環境に提供可能な分散クラウド環境を実現するサービスである。
クラウドの大きなメリットとして、ミドルウェアの運用マネージドサービスがあるが、クラウドベンダーが提供しているデータセンターに限定されてしまう課題があり、IBM Cloud Satelliteによってデータセンターの制約が大きくなくなったと言える。また、5Gの開始によって注目されるエッジ・コンピューティングのデータセンターにもRed Hat OpenShiftのマネージドサービスを展開できるメリットがある。
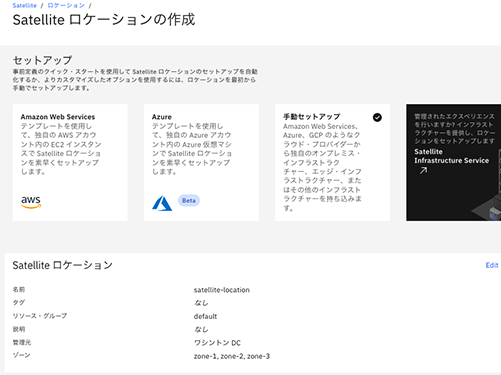
IBM Cloud Satelliteのロケーション指定により、対応している実行環境が指定できる。AWSやAzureのようなパブリック環境に対しては認証情報を入力するだけでRed Hat OpenShiftをデプロイできる。
IBM Cloud Satelliteでは、OpenShiftのマネージドサービスだけではなく、そのコンテナプラットフォーム上に提供されるサービスも一部マネージドサービスとして含めることができる。その中で、Cloud Pak for Dataは、IBM Cloud Satelliteで提供されるサービスの中核を構成している。
分散クラウドにおいて、実現が一番難しいのはデータベースとAIで、その両機能を包含するCloud Pak for DataをIBM Cloud Satellite経由で提供することによって、分散環境にデータベースとAIがマネージドに配置可能になる。

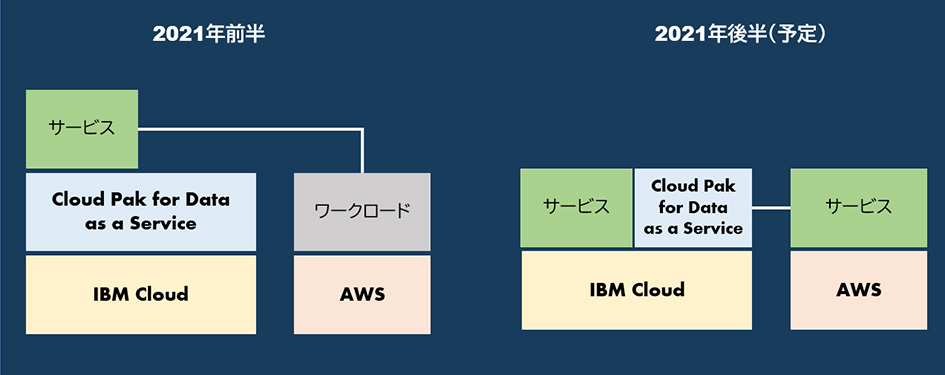
Cloud Pak for Dataは、サービスと実行環境で提供される。2021年前半の第1段でSatellite環境に実装されるのは、実行環境にのみになる。この実行環境とはNotebookで定義される処理で、PythonとRの実行環境である。具体的にSatelliteローケーションにAWSを指定する例で考えてみよう。
Cloud Pak for Data as a ServiceのWatson StudioでJupyter Notebookにより定義された機械学習ロジックを実行する場合、サービスであるWatson StudioはIBM Cloud側にあり、Pythonの実行環境はAWS側にある。これは、分析用のデータがAWSにある場合に、Cloud Pak for Dataのサービスを使いつつも、データに近い場所で機械学習の処理をしたい場合などに有効である。
2021年後半の第2段では、Cloud Pak for Dataで提供されているサービス群もSatellite側で展開できるようになる予定で、アーキテクチャの選択肢が増える。今後、エッジ・コンピューティングのアーキテクチャがより注目を集めていく中で、Cloud Pak for Data as a Service on IBM Cloud Satelliteは有効な選択肢になっていくと考えられる。
[4]AWS、Azure、GCPとの連携によって実現できること
Cloud Pak for Data as a ServiceをSatellite環境に適用せずにIBM Cloudのままで、パブリッククラウドのAWS、Azure、GCP上のデータストアにあるデータを取得したいケースもあるだろう。そのようなケースには、「クラウド統合」機能を使うといいだろう。パブリッククラウドの認証情報を入力するだけで相互接続が可能になり、クラウド間のファイアウォールを構成して、セキュアな接続も可能になる。
[5]Cloud Pak for Data as a Serviceの価値、エッジ時代の実行基盤
Cloud Pak for Dataはソフトウェア版の提供もあるので、さまざまな環境にデプロイできる。IBM Cloud Pak for Data as a Serviceを利用するメリットをまとめてみた。
①構築不要で機能を簡単に試せるため、スモールスタートが可能
②マネージドサービスであり、どの環境への配置でも運用管理が不要
③エッジ・コンピューティングなど分散環境に配置しても、同じバージョンで統合管理が可能
従来のAIは、その多くがクラウドベンダーによって提供されていたため、AIの実行環境がクラウド業者提供のデータセンターに限定されていた。Cloud Pak for Data as a Serviceは、クラウドのマネージドサービスの恩恵を受けつつ、データセンターの制約を受けないエッジ・コンピューティング時代の実行基盤とも言えるだろう。
◎参考
・IBM Cloud Pak for Data as a Service製品資料
・IBM Cloud Pak for Data as a Service Getting Start
・IBM Cloud Pak for Data as a ServiceのSatelliteロケーションの概要
・IBM Cloud Pak for Data as a ServiceのSatelliteロケーションの環境
・IBM Cloud Pak for Data as a Serviceのその他のクラウド・プラットフォームとの統合
プレスリリース
・IBM Cloud Satellite 提供開始によりエッジを含むあらゆる環境でお客様のセキュアなクラウドを実現
著者|
岸代 憲一氏
日本アイ・ビー・エム株式会社
テクノロジー事業本部 データ・A I・オートメーション事業部
Data & AI 第3テクニカル・セールス
2000年4月、日本IBM入社。情報系ソフトウェアの製品開発、システム構築の提案・実装、ソフトウェアやクラウド製品の提案などに従事。社外では2018年から2021年3月まで一般社団法人データサイエンティスト協会の理事として活動。2020年7月から現職で、データ&AI関連ソリューションのビジネス開発を担当。本稿では[1]を執筆。

・・・・・・・・
吉田 千明氏
日本アイ・ビー・エム システムズ・エンジニアリング株式会社
Advanced AI
アドバイザリーITスペシャリスト
2014年4月、日本アイ・ビー・エム システムズ・エンジニアリング入社。以来、データベースおよび分析系ソフトウェア製品の技術支援や、データ分析を担当。本稿では[2]を執筆。

・・・・・・・・
平山 毅氏
日本アイ・ビー・エム株式会社
テクノロジー事業本部 データ・A I・オートメーション事業部
World Wide Hybrid Cloud Build Team & Data Science Team
Data AI アーキテクト、データサイエンティスト
東京証券取引所、野村総合研究所、アマゾンウェブサービスを経て、2016年2月、日本IBM入社。IBMクラウド事業本部、デジタルイノベーション事業開発部を経て、2021年1月から現職。著書『絵で見てわかるクラウドインフラとAPIの仕組み』ほか6冊。IBM Technical Experts Council of Japan Steering Committee Member。本稿では[3][4][5]を執筆。

[i Magazine・IS magazine]