text=前田 幸一郎、野村 幸平 日本IBM
前編で概略を説明したユースケース①の「データ分析基盤」、およびユースケース②の「企業内データ利活用基盤」について、以下にその詳細を説明していこう。
データファブリックのユースケース①
データ分析基盤
ここでは、データファブリックの適用として最もよく見られるデータ分析基盤のユースケースを見ていきたい。
前編で延べたように、これまでのデータ分析基盤はデータレイクやデータウェアハウスを中心に、場合によってはデータマートを含めた3層構造のデータ基盤が活用されてきた(図表3)。
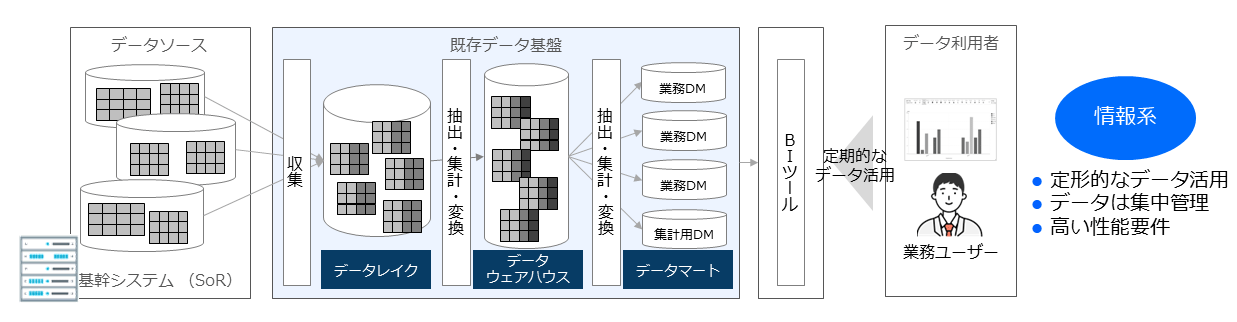
これらのデータ基盤の最も大きな特徴は、データを1カ所で集中管理すること、また大量のデータであっても翌日にはデータ利用者側で活用できるよう、データパイプラインに対して一定の性能要件が求められることにある。
そしてデータパイプライン自体に高い非機能要件が求められることからも、データ基盤設計時には、「どのようなデータをどのように加工して、ユーザーに提供するか」といった要件がある程度定まっている必要があった。
別の言い方をするならば、既存データ基盤はデータ活用の目的、およびデータパイプラインの構造が定型的なユースケースで有効に働く基盤だと言える。
一方で、昨今多くの企業はDXの名の下に、多種多様なデータ分析のニーズが事業部門側、データ分析チーム側から求められている。
これはDXの本質が、これまで以上に顧客理解の解像度を上げることにあるためだ。各企業はデータから顧客の嗜好を分析し、顧客1人1人に対して最適な商品やサービスを提供していくことで、さらなるビジネス優位性を創出することを目指している。
まさに個客志向サービスの実現である。この個客志向サービスを実現するには、これまでの定型的なデータ分析や可視化だけでは入手が困難な「新たな顧客に関連する洞察」を見出すことが求められる。
そのためには多種多様なビジネス仮説を立てながら、その仮説の妥当性についてデータを通して検証することが必要となる。
このような分析を一般的には、「アドホック分析」と言う。このアドホック分析に求められるデータ基盤は、これまでのような大規模な投資が必要な従来のデータ基盤の構築とは大局的な位置付けにあると言える。
なぜなら、新たに立てたビジネス仮説からは必ずしもビジネスに直結するような価値ある洞察が得られるとは限らないからだ。まさにアドホックの名のとおり、探索的アプローチであり、ROIを計算しづらいこのアプローチでは、通常はスモールデータを活用したアジャイルな分析ステップを踏むことが適切と言える。
またDXの文脈におけるアドホック分析では、これまでの基幹系にあるトランザションの結果としての断面的なデータだけではなく、その結果に至った過程のデータも顧客の嗜好を分析するためには必要となる。
このような顧客データを取得可能にするのがDXの要でもあり、また新たな顧客接点部分となる、いわゆるSoE(System of Engagement)と呼ばれるアプリケーションになる。
なお、SoEアプリケーションは収集した大量の顧客データからの洞察もしくは市場の反応に応じて、アプリケーションを絶えず、より魅力的にしていくことが求められるため、一般的には俊敏性の高いクラウド基盤で構築する。
このようにDXの世界を見ると、ユーザーのこれまでの競争力の源泉たるオンプレミス上の既存基幹系システムを軸としながらも、その周りには多くのSoEアプリケーションがクラウド上で構築されていくことになる。
そして、これらの各種システムが生成する多様なデータをいかに効率的に活用していけるかがDX時代に求められるデータ基盤の要件となる。
上記をまとめると、次の3つに集約できる。そしてデータファブリックを活用することで、下記要件を満たすことが可能となる。
(1) 基幹系システム(System of Records)のデータに加え、増え続けるSoEアプリケーションのデータも併せて活用する必要がある(「データにまつわるビジネス課題」で述べた課題❶「各所に散在するデータの可視化と統合的・一元的なビューの提供」と、課題❹「データのサイロ化を助長する組織文化の改革」に関連)
(2) 既存データ基盤のような定型的なデータ活用とは異なり、都度、仮説ベースのアドホック分析を実現する必要性がある(「データにまつわるビジネス課題」で述べた課題❷「膨大なデータからより迅速に、より正確な洞察を得るためのAIの活用」に関連)
(3) 企業の組織間を跨って各システムが生成するデータへのアクセスを可能にするため、利用者や国によってはアクセスポリシーを適用する必要がある(「データにまつわるビジネス課題」で述べた課題❸「各種規約、法規制に対応するためのデータガバナンス」に関連)。
図表4は、既存データ基盤とSoEアプリケーションが存在する世界でのデータファブリックの位置づけを表している。
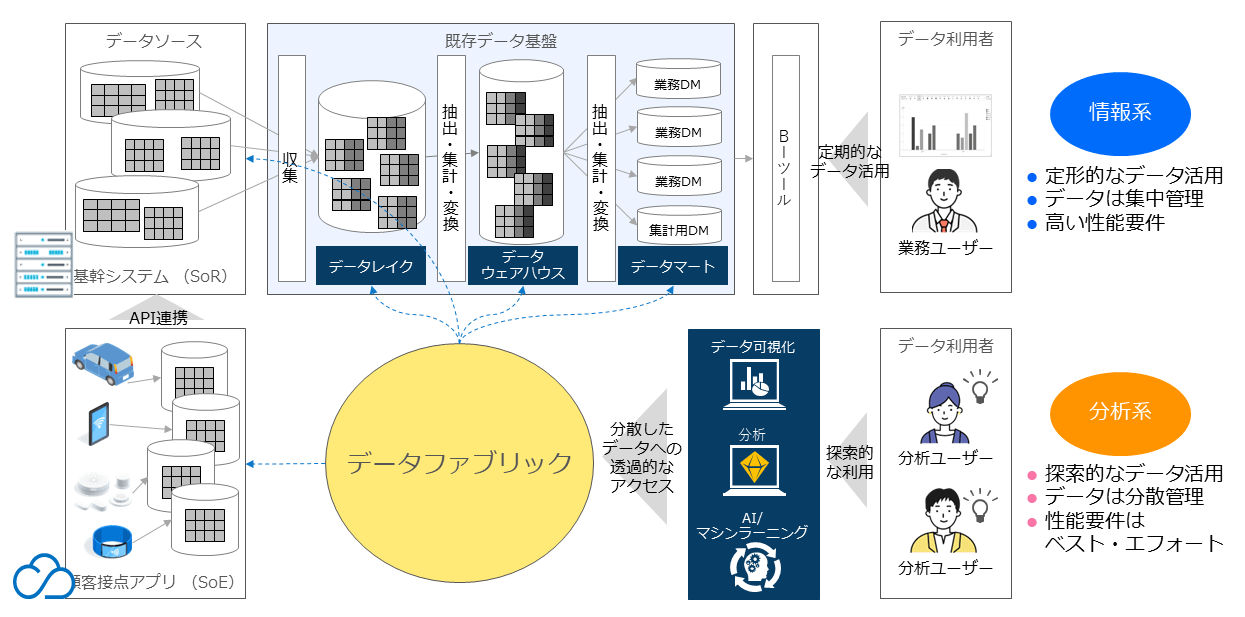
データファブリックの特徴は、データを1カ所に集めることなく、データ利用者に対して、散在するデータへのアクセスを可能にすることだ。
特に増え続けるSoEアプリケーションが生成するデータを既存データ基盤側へ持っていくには、新たなデータパイプラインを構築するワークロードや、そもそもそのデータから価値を見い出せるかといった不確実性の高さから、トータルコストの増大を招く可能性がある。
アドホック分析を主軸にしたDXの世界では、データの生成元からデータを移動させないこのデータファブリックのアプローチが適切と言える。
以上をまとめると、データ分析プラットフォームにデータファブリックを適用する価値は次のように考えられる。
・データ分析で必要となるデータは、必要となったタイミングで必要な分を移動させるため、事前に既存データ基盤側へのデータ移動や新規データパイプライを構築しなくともデータ活用が可能となる
・クラウド、オンプレミス上のシステムがどのようなデータを持ち、またそれがどのようなビジネス上の意味を持つのかを明瞭化し、全社に向けて公開できるようになる
・データは分散管理する一方で、データガバナンスに関するポリシーおよびルールは一元管理するため、データ漏洩や個人情報保護法などへの違反リスクを低減できる
・データの発見から活用までをセルフサービスで実現することにより、企業のデータ活用を促進できる
データファブリックのユースケース②
企業内データ利活用基盤
データファブリックを企業内データ利活用基盤として活用するユースケースを、小売業のビジネスを例に取って説明する。
ある小売企業が、一般消費者向けのオンライン販売用Webアプリケーションとスマホ用ネイティブアプリケーションを展開しており、図表5に示すような典型的なマイクロサービス・アーキテクチャをベースとしたアプリケーション・アーキテクチャを採用しているものとする。
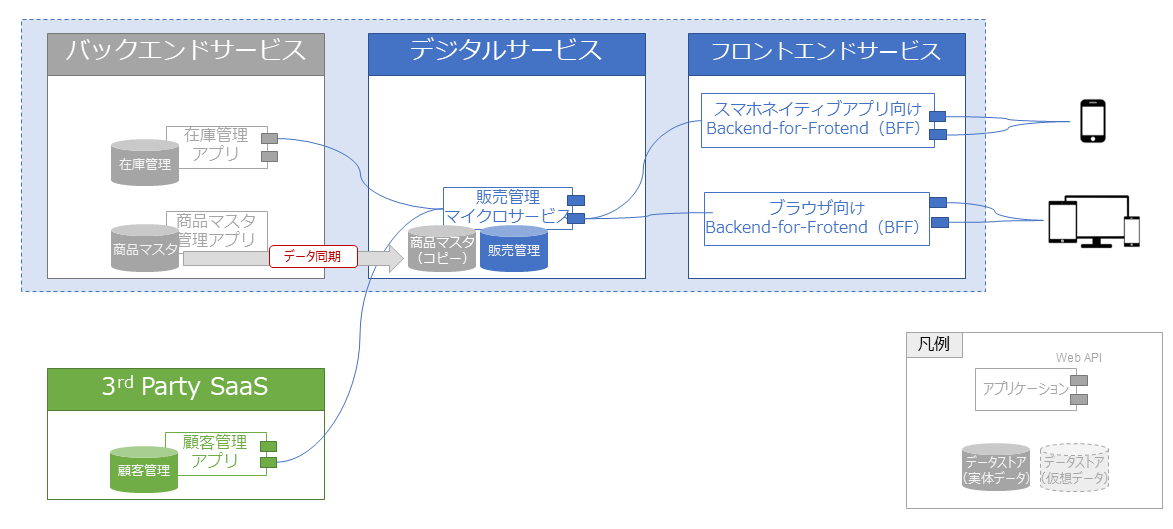
また既存の在庫管理アプリケーション、およびSaaSとして提供されるCRMパッケージとはWeb APIで連携しつつ、Web API化されていない商品マスタは日次のデータコピーで対応している。
このオンライン販売用アプリケーションに対して、販促・マーケティング事業部がユーザー個人の過去の購買履歴やユーザーが属するセグメントの購買傾向などのデータを活用して、クロスセル・アップセルのためのダイナミック広告機能の追加を計画し、その実現方法について検討することになったと仮定してみよう。
従来のアーキテクチャをそのまま拡張すると、図表6のように、新機能を実現するマイクロサービスを追加し、関連するアプリケーションとWeb APIまたはデータコピーを通じて連携することになる。
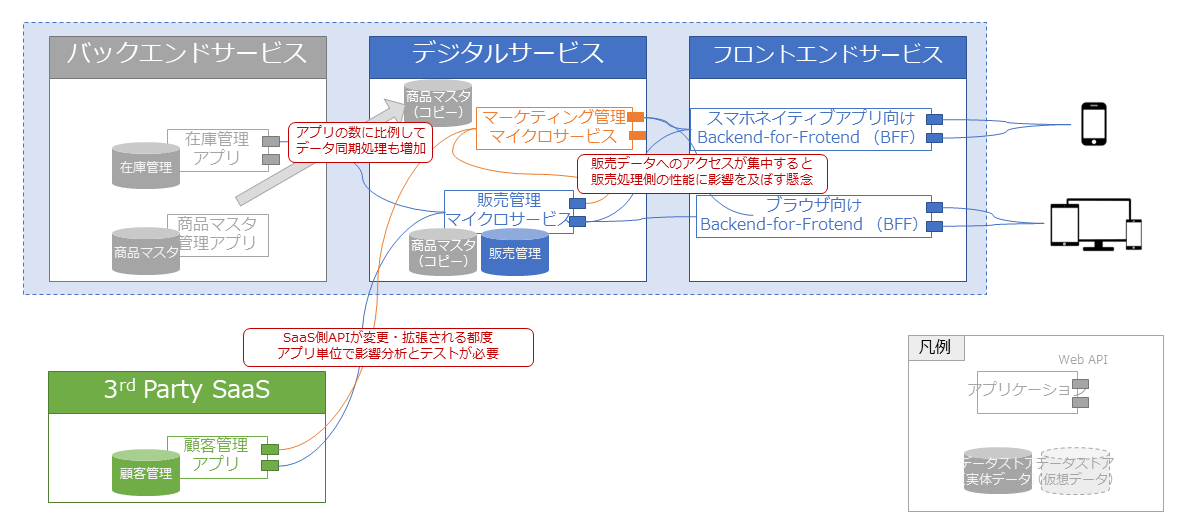
しかしこのアプローチには、以下のようにいくつかの技術的懸念や組織的な課題が存在する。
・商品マスタはファイルコピーによる連携にしか対応しておらず、この仕組みを管理する商品企画事業部に連携先追加の設定を依頼する必要があるが、関連事業部との調整には時間を要する
・ダイナミック広告実現のための根幹となる購買データへのアクセスは、販売管理マイクロサービスを経由して行う必要がある。しかし購買データの分析をその都度、大量のデータを用いて実施するのは効率が悪く、特に繁忙期には通常の販売処理の性能に影響を及ぼす懸念がある
・顧客データへのアクセスにはSaaSパッケージへのAPIアクセスが必要になるが、アプリケーションごとのアクセス数に応じたSaaS費用負荷のロジックを考案するのが困難であり、また主管事業部が異なるアプリケーションでそれぞれ同じようなAPI利用テストを実施するのも非効率である
これらの懸念を払拭し、また課題を解決するには、データファブリックの考え方を導入するのが有効な解決策である。そこで、図表7のようなデータ連携基盤を整備する。
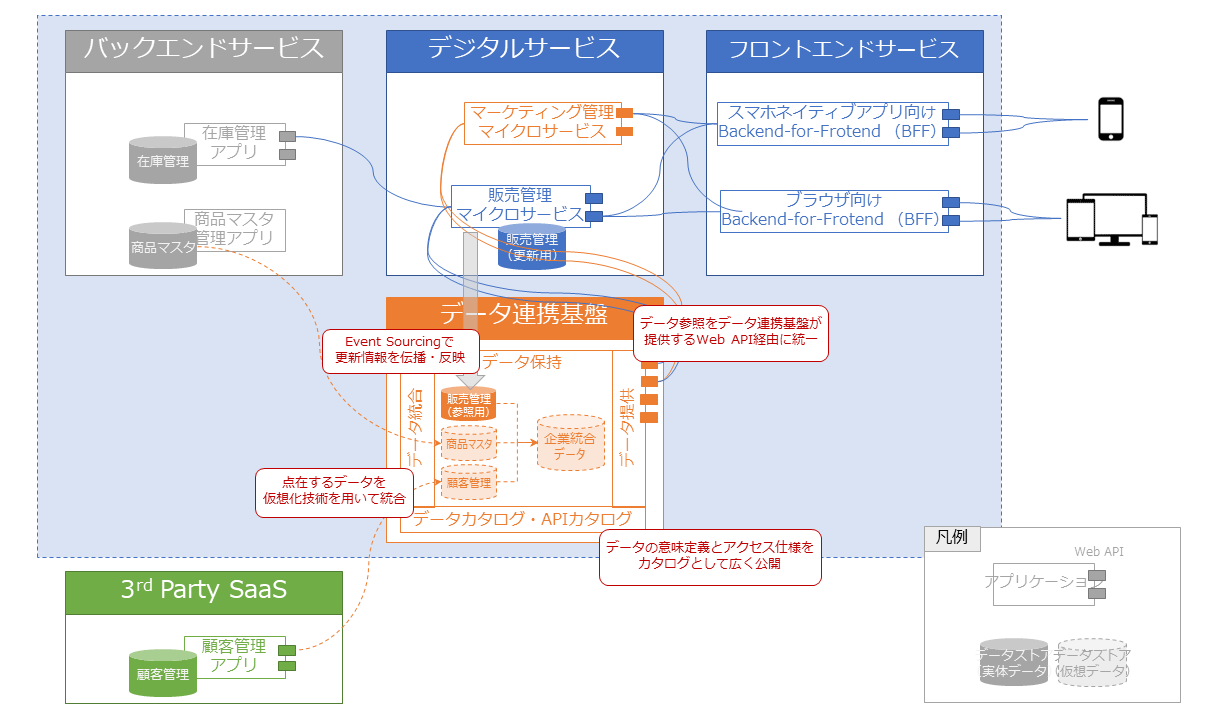
これにより、以下のような効果が得られる。ダイナミック広告機能を追加するという当初の目的を達成できるだけでなく、今後のオンライン販売アプリケーションの拡張やまったく新規のアプリケーション開発でも汎用的に活用できる基盤が整備されることになる。
・バックエンドや他社SaaS上に点在するデータを、データ統合技術を用いて整合性の取れたデータモデルとしてアプリケーション横断で論理的に統合し、標準的なWeb APIを通じて参照可能にできる
・データの意味定義(メタデータ)やアクセス手段についてデータカタログ、APIカタログとして広く社内に公開し、事業部を問わず社内アプリケーション開発者から自由に利用可能にできる
・販売管理データについては、CQRSのデザインパターンを活用して更新用のデータモデルと参照用のデータモデルに分離する。更新情報はEvent Sourcingにより、非同期的に参照用モデルへ伝播させることでアクセス集中による競合を回避すると同時に、伝播の過程にダイナミック広告用の購買データ分析処理を挟むことで、動的な分析モデルの更新と広告表示機能への反映を可能にできる
データファブリックの普及に向けた課題
データガバナンスを主管する組織の設置と維持
データのサイロ化を抑制し、データ駆動経営を可能とする技術的基盤が整ったとしても、その上で実際に企業データを統合し、ユーザーに提供し続けるには、一般的にはビジネスドメインをまたがった全社的なデータガバナンスチームの設置・維持が不可欠とされている。
データの品質を維持しつつ、データ統合を果たすには、各ビジネスドメインのエキスパートが必要となる。しかしそのようなエキスパートをデータガバナンスチームで抱え続けるには、相応の投資が必要となることから、投資の縮小とともにチームが縮小・解散し、せっかく構築したデータ利活用の仕組みがビジネスの変化に追従できなくなったケースも見受けられる。
データファブリックがもたらすビジネス価値を経営層に正しく訴求し、このような組織を維持し続けることが重要になる。
データスチュワードの育成
前編でも触れたとおり、データガバナンスチームの中で最も重要なロールがデータスチュワードである。データスチュワードはユーザーが求めるデータの利活用要件を正しく把握し、データの生成元であるデータオーナーからカタログ生成に必要なメタデータや実際のデータそのものを収集・統合して、ユーザーが利用可能な状態にする責任を担う。
データガバナンスに関する技術的なスキルはもちろんのこと、データの統合に際して各ビジネスドメインのエキスパートと協業するために一定程度のドメイン知識も求められることから、育成するのは容易ではないとされている。
データスチュワードは、データ駆動経営をソフト面で支える最重要ロールと言っても過言ではなく、戦略的に育成に取り組む必要がある。
性能に関する課題
最後に技術面での課題を挙げたい。データファブリックでは、散在するデータを移動させることなく、論理的に統合管理する。したがってデータ利用者側がデータを要求したタイミングで、必要な分のデータがデータソース側から利用者側に移動される。
そのためデータ量によっては、求められる時間内にレスポンスが返せない可能性が十分に発生しうる。そこで、データファブリックの実装技術に依存することにはなるが、たとえば大量データをフェッチする機能にはスケールアウト性を持たせる、またリクエストを予測してデータをキャッシュしておく、などの対応が必要となる。
以上、データ駆動型経営が求められる背景とともに、データファブリックの概要、データファブリックを活用するユースケース、そして今後の普及と発展に向けた課題について概観した。
データファブリックに対しては、IBMを含む多くのベンダーがそれぞれの立場で用語を定義し、製品やサービスを提供しているが、それは裏を返せばデータファブリックという概念・技術に対する市場の高い期待値の証左でもある。
本稿が、データファブリックについての理解を深める際の一助となれば幸いである。課題


*本記事は筆者個人の見解であり、IBMの立場、戦略、意見を代表するものではありません。
当サイトでは、TEC-Jメンバーによる技術解説・コラムなどを掲載しています。
TEC-J技術記事:https://www.imagazine.co.jp/tec-j/
![]()
[i Magazine・IS magazine]