Watson Analyticsの利用から、RESTサービスによる連携まで
IBM iのデータ活用を巡る
2つの動き
データを活用することが、ビジネスを拡大する有効な策となるのは言うまでもない。ビッグデータやアナリティクスといった言葉を持ち出すまでもなく、データは企業にとって最も重要な経営資源の1つである。
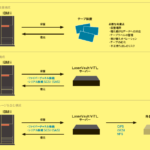
基幹システムのプラットフォームとして運用されてきたIBM iには、貴重な企業データが蓄積されている。このデータを基幹システム以外でも活用すべく、IBM iではこれまで、さまざまなBIソリューションやデータ活用ツールが提供されてきた。今、そこに新たな動きが見える。1つは使いやすいクエリーツールの登場、そしてもう1つはWatsonに代表されるコグニティブコンピューティングがもたらす新たなデータ活用の手法である(図表1)。
【図表1】広がる基幹データ活用
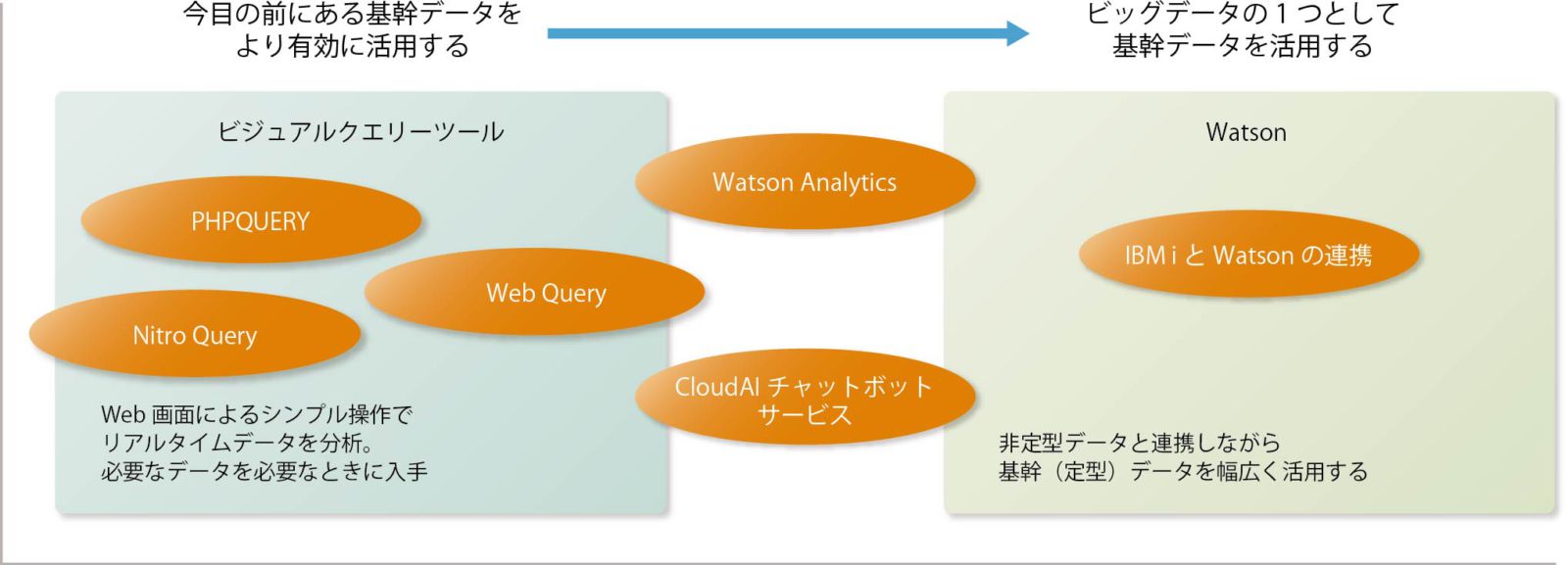
クエリーツールとWatson、ローエンドとハイエンドとも言うべきこの2つの軸に視点を据えて、データ活用基盤としてのIBM iの動きを見てみよう。
ビジュアルクエリーツール
Query/400よりも使いやすく
Query/400は、IBM iユーザーにとって最も身近な照会ツールである。多くのシステム部門で長く使われてきた優秀なツールである一方、最近では5250をベースとした画面のわかりづらさ、データ抽出の煩雑さや不便さに、若手を中心にした技術者が少なからず不満を感じているのも事実であろう。
そこでブラウザベースのGUI画面によるシンプルな操作で、リアルタイムデータを多彩なグラフ形式で可視化し、いつでもどこでも利用可能にするビジュアルクエリーツールが登場している。
たとえば本特集で紹介するミガロ.の「Nitro Query」、オムニサイエンスの「PHPQUERY」、そして日本IBMの「Web Query」などである。
「Web Query」が高機能なハイエンドツールであるのに対し、PHPで開発された「PHPQUERY」は高レスポンスでシンプルな操作、かつ月額料金制をベースに低価格で導入できるのが特徴。また「Nitro Query」は、運用管理の便利機能を集めた「Nitroユーティリティ」の1ツールとして提供される一方、開発ツールとしての側面も重視する。
いずれもQuery/400で作成したクエリー定義を再利用でき、Query/400を使い慣れたユーザーに配慮した操作環境を実現している。
システム担当者がさまざまな部門から依頼されるデータ出力作業に追われるなか、こうしたクエリーツールは「必要なときに必要なデータを、簡単な操作で自由に入手できるように」というコンセプトで開発された。
ビッグデータの活用よりも、まずは「今、目の前にあるデータ」「今、手元にあるデータ」を、今まで以上にうまく活用することを重視している。
Watson で
データ活用をレベルアップする
データ活用をレベルアップするもう1つの動きが、Watsonを筆頭とするコグニティブコンピューティングである。
Watsonが活用する情報資源は、多様なテキストデータや文書ファイル、ソーシャル情報をはじめ画像、動画、音声など非定型データであるとのイメージが強い。しかしIBM iが蓄積する基幹データ、たとえばマスタファイルやトランザクションデータなどの定型データも、Watsonが活用するデータソースの重要な一角を形成する。基幹データに裏打ちされてこそ、さまざまな非定型データから意味や予測、ルールやパターンが見えてくる。
本特集では、IBM iとWatsonの連携例の1つとして、IBM iの基幹データにLINEとWatsonを組み合わせた「CloudAIチャットボットサービス」(JBCC)を紹介している。多くのユーザーが日常よく使用するLINEの画面から、納期や価格、在庫などを照会するもの。Watsonがその質問の意味を理解し、クラウド型のBIツールである「SmartBI」を経由して基幹データベースを検索し、その結果をLINEで返すという仕組みだ(WatsonはIBM iの基幹DB以外にもFAQやストレージサービスであるBox、CRM/SFAなどを検索可能)。
またIBM iとクラウド型データ分析ツールである「IBM Watson Analytics」(以下、Watson Analytics)の連携も興味深い。ここではオンプレミスにあるIBM iの基幹データ(およびIBM i以外のデータソースも利用可能)をクラウドにアップロードし、「Watson Analytics」が分析して、どういった角度での分析が最も有効か、グラフやダッシュボードの作成を含めた知見を提示する(図表2)。
【図表2】IBM iとWatson Analytics
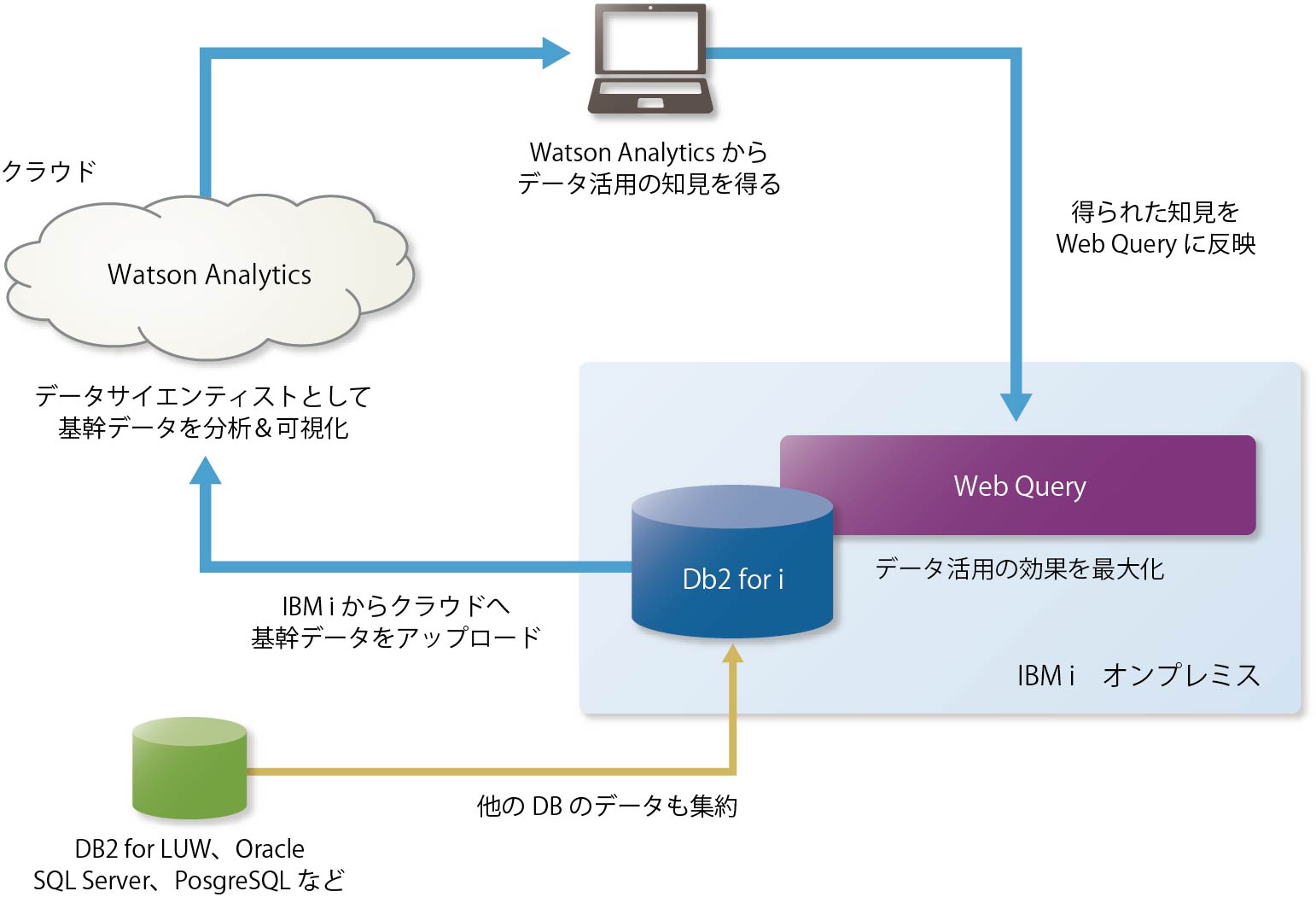
そこで得られた知見を、IBM i側の「Web Query」に反映し、クエリー定義や分析、可視化を実行しながら業務で活用する。「Watson Analytics」はいわば、多彩な分析パターンを提案してくれる、その企業専属のデータサイエンティストとしての役割を果たすことになる。
「Watson Analytics」はSaaS提供のため、導入・開発作業が不要となるので、IBM iで手軽にWatsonを活用する最初の一歩となりそうだ。
IBM iとWatson APIを
RESTサービスで連携する
IBM iの基幹データと、動画や画像、GPSやソーシャル情報など多彩な非定型データとの連携は、大胆な業務改革や新たなビジネスモデル創出への大きな可能性を秘めている。
動画や画像データを利用する例としては、監視カメラで倉庫や商品棚を確認し、必要な在庫数を割ったら警告を発して基幹システムに発注を促す。あるいはショッピングモールでGPSによる位置情報と天気データ、購買履歴を活用し、個々人の好みと天候・季節に基づくパーソナライズされた店舗限定クーポンをスマートデバイスに発行する。今後業務の特性に応じて、さまざまな利用モデルが登場するだろう。
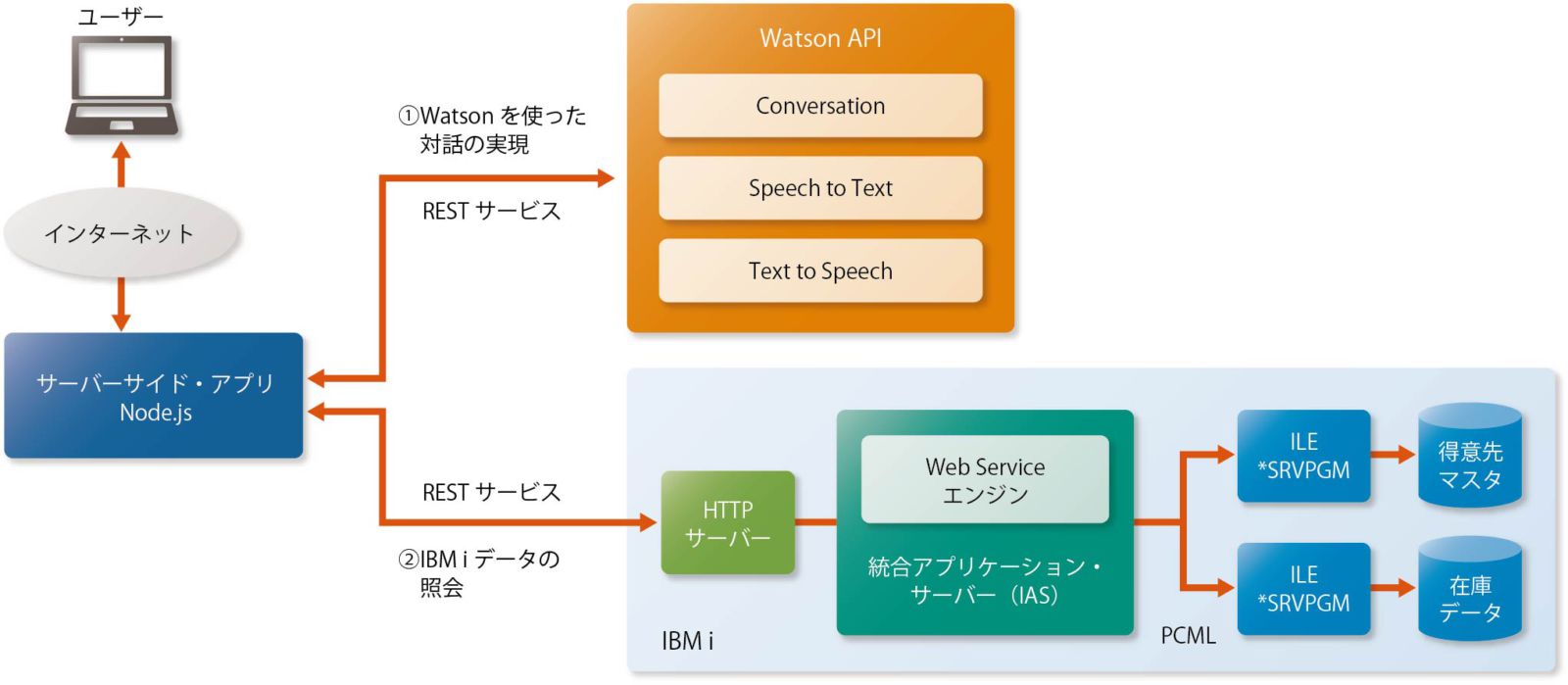
IBM iとWatsonの連携手法には、大きく2つある。1つはRESTサービスを経由してILE RPGとWatson APIを連携する手法、もう1つはILE RPGからダイレクトにWatson APIへアクセスする手法である。前者はWatson API以外の外部APIや外部データを組み合わせたアプリケーションに適しており、後者はRPG技術者にとって、使い慣れた言語を使ってシンプルに連携するアプリケーションを書ける点でメリットがあるだろう。
RESTとはRepresentational State Transferの略で、個々の Web サービスをリソースと見なし、Web サービスをURL によって一意に識別するアーキテクチャのこと。REST 原則に従った (つまりRESTful な)Web サービスには、それぞれに異なる操作の呼び出しを意味する HTTP メソッドを明示的に使用するという特徴がある。つまり各リソースに対してGET、POST、PUT、DELETEでリクエストを送信し、そのレスポンスをXMLやJSONなどで受け取る。
IBM iでは、7.1以降でDb2 for iのHTTPメソッド機能と、統合アプリケーション・サーバー(IAS)の「Web Serviceエンジン」をサポートしており、ウィザード形式によるRESTfulサービスを定義できるようになっている。REST によって定義された一連のアーキテクチャ原則に従って設計すれば、IBM iのアプリケーション(たとえばILE RPGなど)をWebサービス化することが可能なのである。
Watson APIと連携させる場合は、図表3のように、RESTサービスを使ってGETリクエストし、「Web Serviceエンジン」を経由して、ILE*SRVPGM(サービス・プログラム)を呼び出す。そしてその結果をXMLやJSONで受け取る(詳しい連携手法については、次号のi Magazineで詳しく紹介する予定だ)。
【図表3】RESTサービスによるWatsonとIBM iの連携
クエリーツールにより、今目の前にある基幹データを活用する。あるいは「Watson Analytics」でデータ活用の知見を得る。そしてIBM iとWatsonを連携して、定型・非定型の各データを効果的に分析して新たな活用モデルを創出する。
IBM iのデータ活用には、新たな世界が広がっている。
・・・・・・・・
i Magazine 2017 Autum(8月)掲載