JBCCの「インフラ最適化クリニック」
JBCCでは、ユーザーのITインフラ環境を改善するための「インフラ最適化クリニック」(以下、クリニック)を提供している。サーバーの仮想化だけにとどまらず、ストレージおよびネットワークの仮想化やパブリッククラウドの活用も視野に入れた、総合的なインフラ環境最適化のための支援サービスである。
クリニックの実施手順は図表1のとおりだが、ユーザーへのアンケートから始まり、ヒアリングと分析を通して隠れた課題と要因までも洗い出し、最適なインフラソリューションを提案するのが特色である。
【図表1 画像をクリックすると拡大します】

以下の2つの改善事例は、クリニックがユーザー環境の診断を踏まえて提案を行い、インフラの移行を実施した例である。ユーザーが抱える課題および要因の整理とその解決方法についての考え方、さらにソリューションの内容をまとめた。
・・・・・・・・
CASE 1
サイロ化したシステム群をDell Nutanixで集約
バックアップの問題を抜本的に解決し、シンプルなインフラを実現
Before:インフラ改築前の状況
このユーザーA社は従業員1000名規模の企業で、グループ各社のシステムも本社システムのなかに収容して運用管理する体制を敷いてきた。特徴的なのは、本社およびグループ各社のシステムが個々別々で、サイロ化していたことである。これは、各社のシステムを収容するたびに、その時点での最適なシステムを選択してきたためで、結果として「統一されていない、つぎはぎだらけのシステム」(JBCCの大島 貴幸氏、プラットフォーム・ソリューション事業部 製品技術部 部長)になっていた。
インフラ最適化の動きが始まったのは、5年リースの更新時期を迎える製品があったことが発端である(図表2)。それに加えて、従来からストレージ障害によるパフォーマンスの劣化とバックアップの失敗の多発という問題を抱えていたので、その抜本的な解決とインフラのレベルアップも併せて実施することにした。
【図表2 画像をクリックすると拡大します】
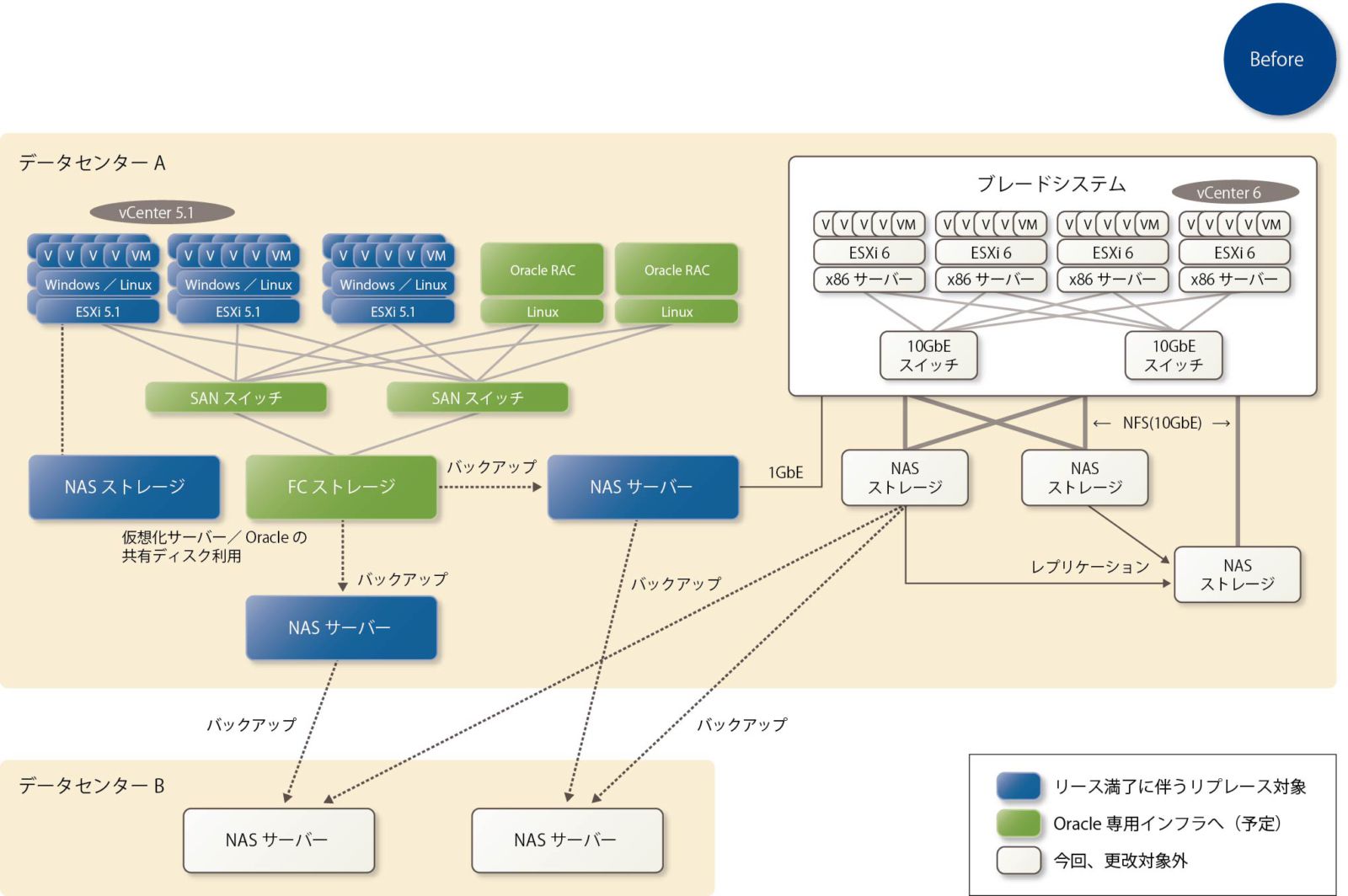
バックアップの失敗は、1日に1〜2台の割合で発生していた。A社のインフラ移行を担当した井戸誠士氏(プラットフォーム・ソリューション事業部 製品技術部 中部グループ)は、「更改対象となった環境には仮想サーバーが100台以上あり、そのバックアップをvSphereのAPIを使って取っていました。こうした環境では、スナップショットの多重処理によって失敗が起きることがあり、それがバックアップの失敗につながることもありました。つまり、バックアップの失敗はバックアップ製品自体の問題ではなく、仮想化環境への依存による問題もあるということです」と説明する。
また、ストレージ障害によるパフォーマンスの劣化については、「冗長化されている2台のコントローラのうち1台で障害が発生すると、データ保護優先のためにキャッシュメモリ機能がオフにされます。製品デザインによる処理性能の低下でした」と、井戸氏は話す。
インフラ改築の方針とソリューション
調査と分析の結果、JBCCではA社のインフラ改築について次のような方針を立てた。
「更改対象のシステムがつぎはぎだらけで統制されていないことが運用負荷を増大させているので、シンプルなインフラを追求することと、運用担当者が2名しかいないことを考慮して、機器の数を減らすことによって管理対象を減らし、障害の発生を最小化することを方針としました。さらに、お客様のニーズに合致する最適なストレージの選択も方針に加えました」(大島氏)
図表3の左列と中央列が、クリニックがまとめたA社の課題とその解決方法である。大島氏は、「これを整理したことで、ハイパーコンバージド・システムを選択する道筋がはっきりしました」と述べる。
【図表3 画像をクリックすると拡大します】
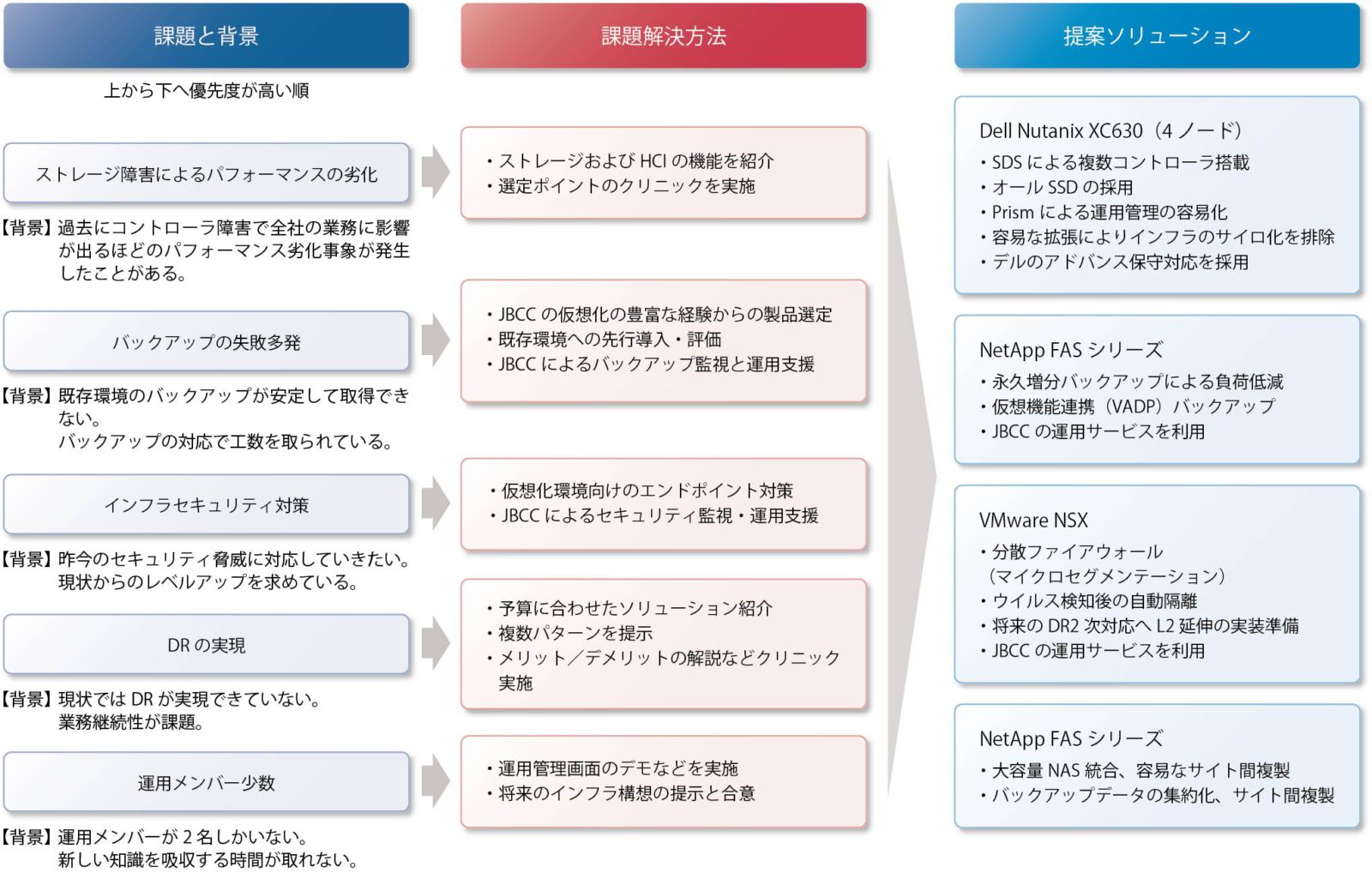
たとえばストレージについては、「一般的なミラーリングでは、障害時に切り替えが発生しますが、ハイパーコンバージド・システムは内蔵ディスクへのレプリケーションなので、障害が起きても切り替えの必要がなく、スムーズに継続運用できます。さらに、小さな筐体にSSDを混在、またはすべてをSDDにできるので、処理性能が格段に優れています。ハイパーコンバージド・システムが導入可能なら外付けディスクの必要がなく、システムをよりシンプルに設計できます」と解説するのは、小松健氏(プラットフォーム・ソリューション事業部 製品技術部)である。
クリニックでは、ハイパーコンバージド・システムとして、Dell Nutanix XC630を選択した。コンパクトな1Uサイズであるのと、スロットが10口あり多数のディスクを積めるのがその理由で、そのほか、「ハイパーバイザーの保守・メンテナンスを24時間/365日提供しているのはデルのみで、ハイパーバイザーが壊れたときのスピーディな対応をメーカーが保証してくれる点は、大きな安心材料です」と、井戸氏は話す。システム構成は最小の3ノードではなく、推奨の4ノードを導入した。1ノードに障害が起きても、4ノードならば自動リカバリモードが作動するからだ。
またバックアップソフトウェアには、Arcserve UDPシリーズを選択した。A社が、VM単位ではなくファイル単位のリストアを要望していたからで、Arcserve UDPはVM単位でバックアップし、VM単位またはファイル単位で非常に簡単にリストアできる。さらに、Arcserve UDPが、初回以降はフルバックアップを必要としない「永久増分」に対応している点も高く評価した。「この機能があると、バックアップ時間の短縮に加えて、仮想化基盤のバックアップ負荷を大幅に軽減できます。ハイパーコンバージドとも相性がよく、ノードごとにバックアップ処理が行えるので、負荷分散効果も期待できます」と、井戸氏は説明する。
大島氏は、「バックアップにおいて処理時間を短縮することは、障害最少化の重要な要件です。今回のインフラ改築では大量のVM環境であってもバックアップ時間を削減する、使い勝手のよいストレージ製品を選択できたと考えています」と言う。
After:移行後の新しいインフラ環境
新しいインフラ環境は、サーバーや機器類が削減され、シンプルな構成となった(図表4)。
【図表4 画像をクリックすると拡大します】
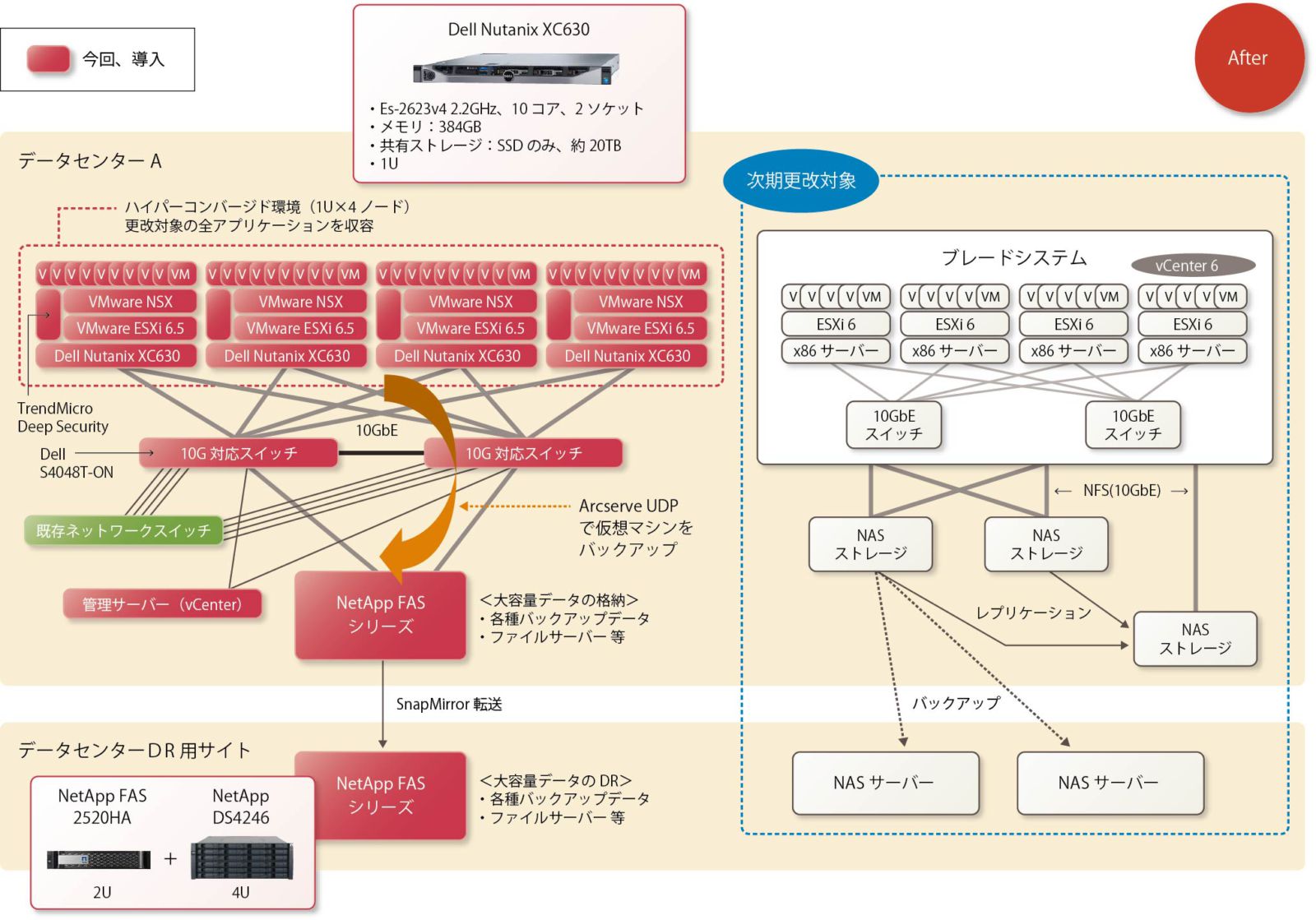
従来2ラックにまたがっていたシステムは1ラックに集約され、更改対象のすべてのアプリケーションが収容された。データはハイパーコンバージド・システム内でレプリケーションされるとともに、10G対応スイッチを経由してNetApp FASシリーズへバックアップデータが送られ、さらに別データセンターのNetApp FASシリーズへミラーリングされDRが実現するという構成である。
インフラセキュリティの強化では、VMware NSXとトレンドマイクロのDeep Securityの組み合わせにより、サーバーがマルウェアやウイルスに感染したら自動的にネットワークから切り離す機能を導入した。また万一、マルウェアやウイルスがすり抜けた場合に飛散が起こらないように、マイクロセグメンテーション技術を適用して、サーバーごとにファイアウォールを設置した。「これにより、セキュリティの強度は大幅に向上しました」と、井戸氏は話す。
次期更改予定のシステムは、今回のインフラをベースに改築していく計画。「サーバーの増設はDell Nutanix XC630に接続するだけで済むので、非常にすばやく安全に移行を終えられます。これもハイパーコンバージドであるがゆえの大きなメリットです」と、大島氏は指摘する。
・・・・・・・・
CASE 2
Oracleサーバーを分離、将来を見据えた基盤改築
3層構造に最適なストレージとスイッチを選択、バックアップを効率化
Before:インフラ改築前の状況
このユーザーB社は、ある企業の情報システム子会社で、親会社のシステムを運用・保守するとともに、グループ各社のシステムについても運用・保守を担当している。
今回、インフラ改築の対象となったのはグループ各社の基幹システムが稼働するブレードシステム(IBM BladeCenter H)とIBM Storwize V7000で構成されるシステム、およびテープ・バックアップ環境である(図表5)。
【図表5 画像をクリックすると拡大します】
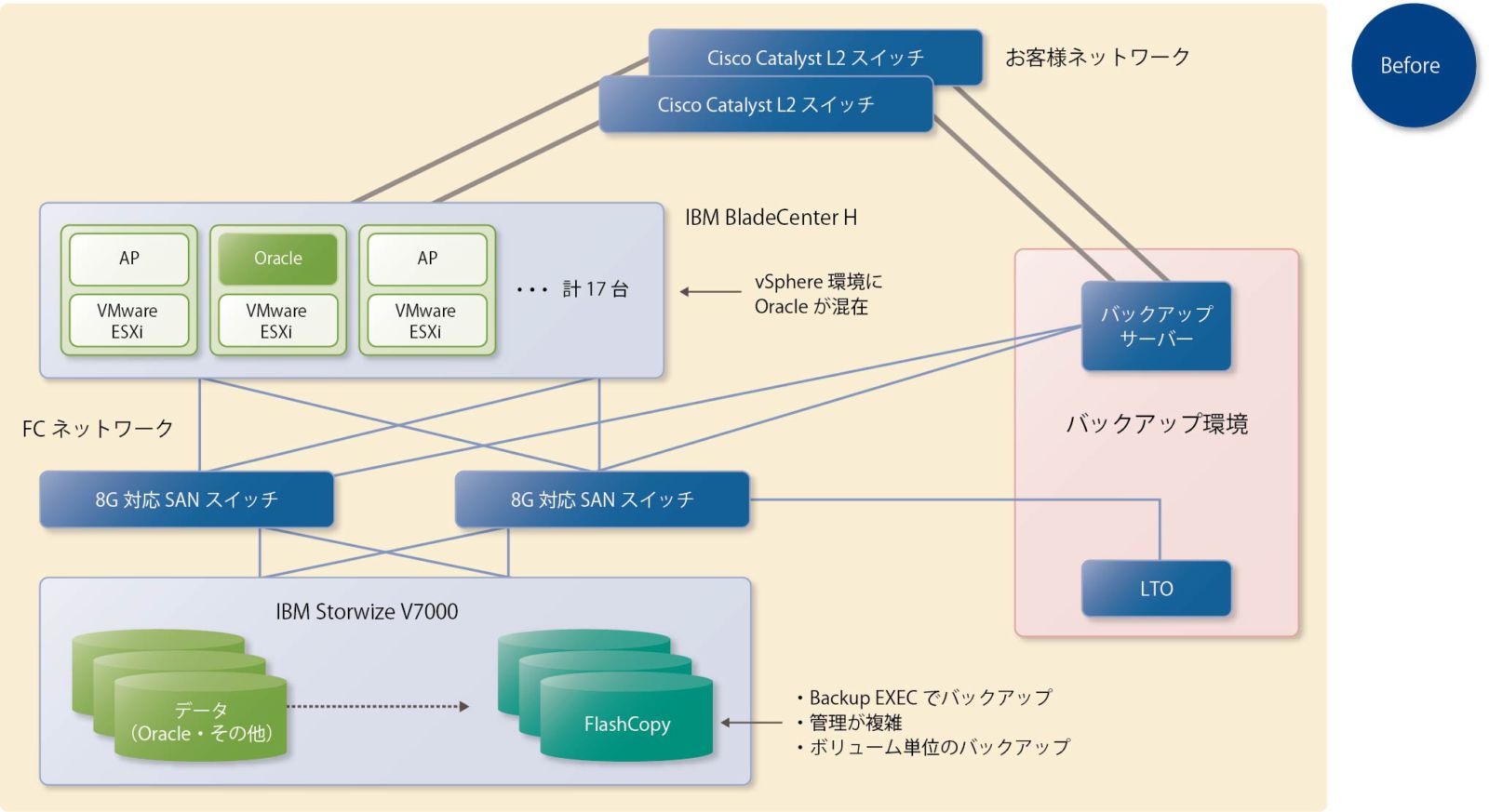
ブレードサーバー上の17台のホストでは、各種アプリケーションとOracleが混在して利用されている。データのバックアップはV7000のFlashCopy機能を使って筐体内でコピーされているが、その管理はBackup EXECで行われており、運用管理の複雑さがユーザーから指摘されていた。また、リストアはボリューム単位ではなくファイル単位で行いたい要望をユーザーは挙げていた。
今回のインフラ改築は、Oracleのライセンス制度の変更が引き金である。Oracleでは従来、CPUのコア数を課金対象としていたが、新制度ではOracleが稼働していないサーバーであってもネットワークでつながっているVMはすべて課金対象になりライセンス費用が発生するので、その適正化を図るのが目的の1つであった。
インフラ改築の方針とソリューション
クリニックが最初に立てた方針は、Oracleが稼働するハイパーバイザーをVMwareとは別にするという、ハイパーバイザーの分離である(図表6)。
【図表6 画像をクリックすると拡大します】
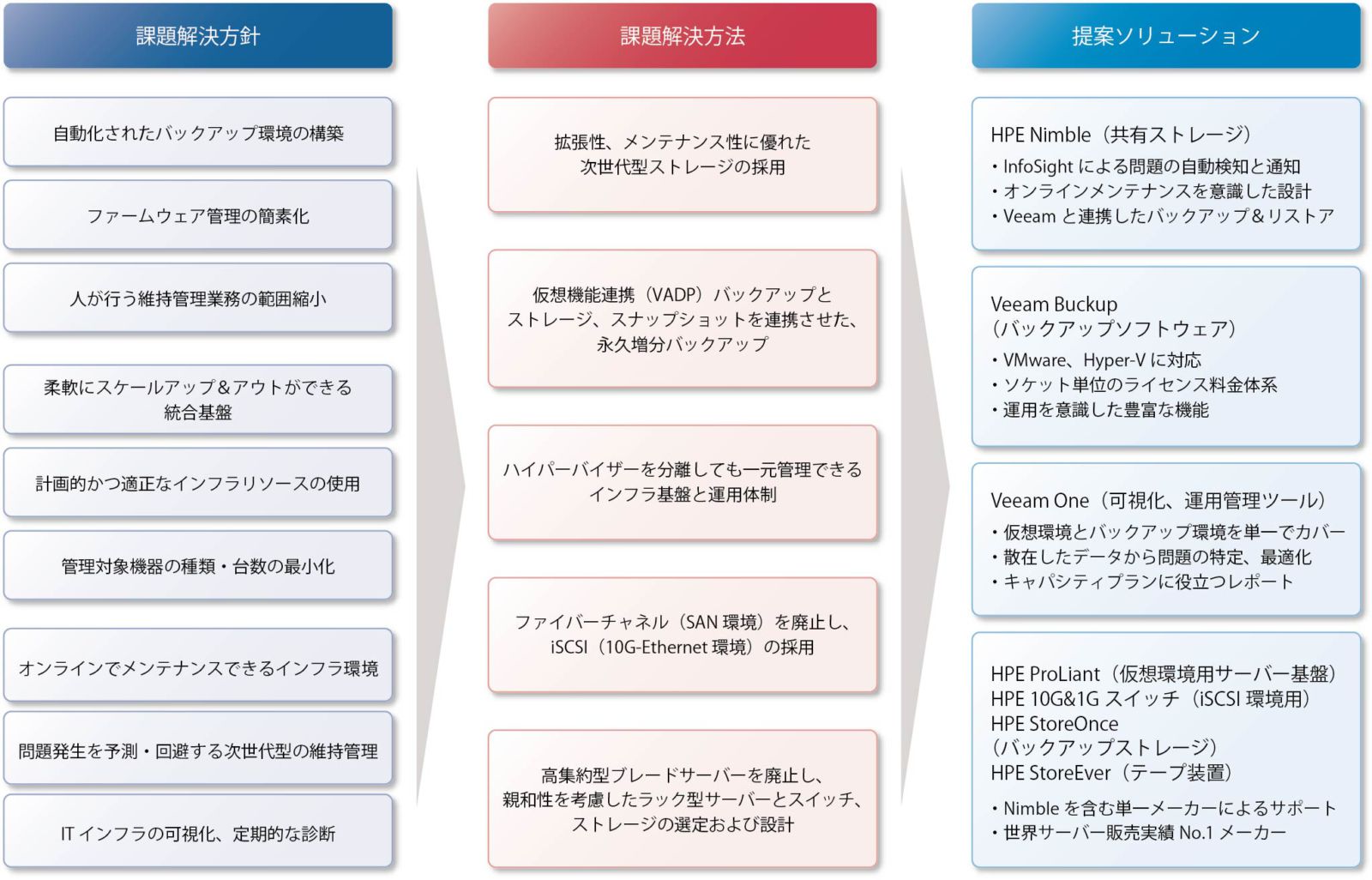
「クラスタが別でもネットワークでつながるVMがすべて課金対象になると、その回避方法はOracleで使用するハイパーバイザーをKVMかHyper-Vにするしかありません。システムを2つに分けることを前提に検討を進めました」(小松氏)
そのなかでクリニックでは、Nutanixの採用も一時期検討の俎上にのせた。NutanixならばVMware、Hyper-V、AHVに対応しているので、Oracleとそのほかとでハイパーバイザーが違っても管理を統一できるというメリットがあるからだ。
「しかし、Nutanixの資料をよく見ると、将来構想として異なるハイパーバイザー間でも仮想サーバーの移動が可能になると明記されてあり、そうなれば別のハイパーバイザーでシステムを組んだとしても将来的にOracleの課金対象となる可能性が出てきます。今後5年間に利用するシステム基盤の設計でそうした冒険はできないので、Nutanixを見送ることにしました」と、大島氏は振り返る。
また、その検討と並行して、Nutanixを導入した場合のコスト試算も行った。今回はシステムを2つに分けるので、Nutanixは2システムで計8ノードが必要になる。これに対して、一般的なVM環境で組めば3ノードで済む。「トータルのコストで試算すると、Nutanixのほうが1.5〜2倍コスト高になることがわかりました」と、小松氏は言う。
既存のファイバーチャネル(以下、FC)接続をそのまま残すかどうかも、検討を重ねた項目だった。
大島氏は、「今後5年間のデータ容量の増加と高速処理を念頭に置けば、FCの選択も十分にあり得ました。しかし、運用担当者が2名という少人数体制を考えると、FCの利用にかかるファームウェアのバージョンアップやバージョン合わせなどの重い作業負荷を看過できません。従来は、その作業のために土日や深夜の時間をあてていたそうです。そこで今回は、FC-SANからの脱却をテーマに検討を進め、iSCSIを提案しました」と、経緯を語る。
「iSCSIやNASでも利用のための工数はそれなりにかかりますが、FCと比べたら、はるかに軽いものです。“FCの縛りからの解放”が、ソリューション設計時のキーワードでした」(大島氏)
ストレージは、3層構造のシステムに適合するNimbleを採用した。SSDとディスクの両方を搭載できるハイブリッド型の製品で、今回は960GBのSSDを3台と2TBのSATAディスクを21台搭載した。処理性能と大容量データとのバランスを柔軟に設計できるストレージである。
また、Nimbleへのバックアップ/レプリケーションツールとしては、仮想環境に特化したVeeamを採用した。
「VeeamとNimbleの組み合わせによって、VMのスナップショットを取った瞬間にストレージのスナップショットを取得でき、VMのスナップショットを削除できるので、VMの負荷の大幅な軽減が可能です。しかも永久増分でバックアップできるので、短時間で処理を完了できます。ストレージコストとバックアップ/リストアを最適化するシステムを実現できました」(大島氏)
一方、テープバックアップのほうは、「20TBのバックアップを効率化するために」(小松氏)、仮想テープ装置のHPE StoreOnce3540とテープライブラリのHPE StoreEver MSL2024を採用した。サーバーからテープ装置へのダイレクト接続ではなく仮想テープ装置を介在させたのは、永久増分への対応である。この永久増分にはD2Dが前提となるため、StoreOnceはネットワークに直接接続してNASのように利用できる機能を使用している。
After:移行後の新しいインフラ環境
インフラ改築後のシステムでは、Oracle搭載のサーバーとOracleを利用しないアプリケーションサーバーの2つが設置され、10Gスイッチ経由でiSCSIによりNimbleへ転送される構成となった。さらにNimbleのバックアップデータは、バックアップサーバーにCIFSマウントされた仮想テープ装置(HPE StoreOnce3540)に取得されたのち、必要に応じてテープに落とされる仕組みである(図表7)。
【図表7 画像をクリックすると拡大します】
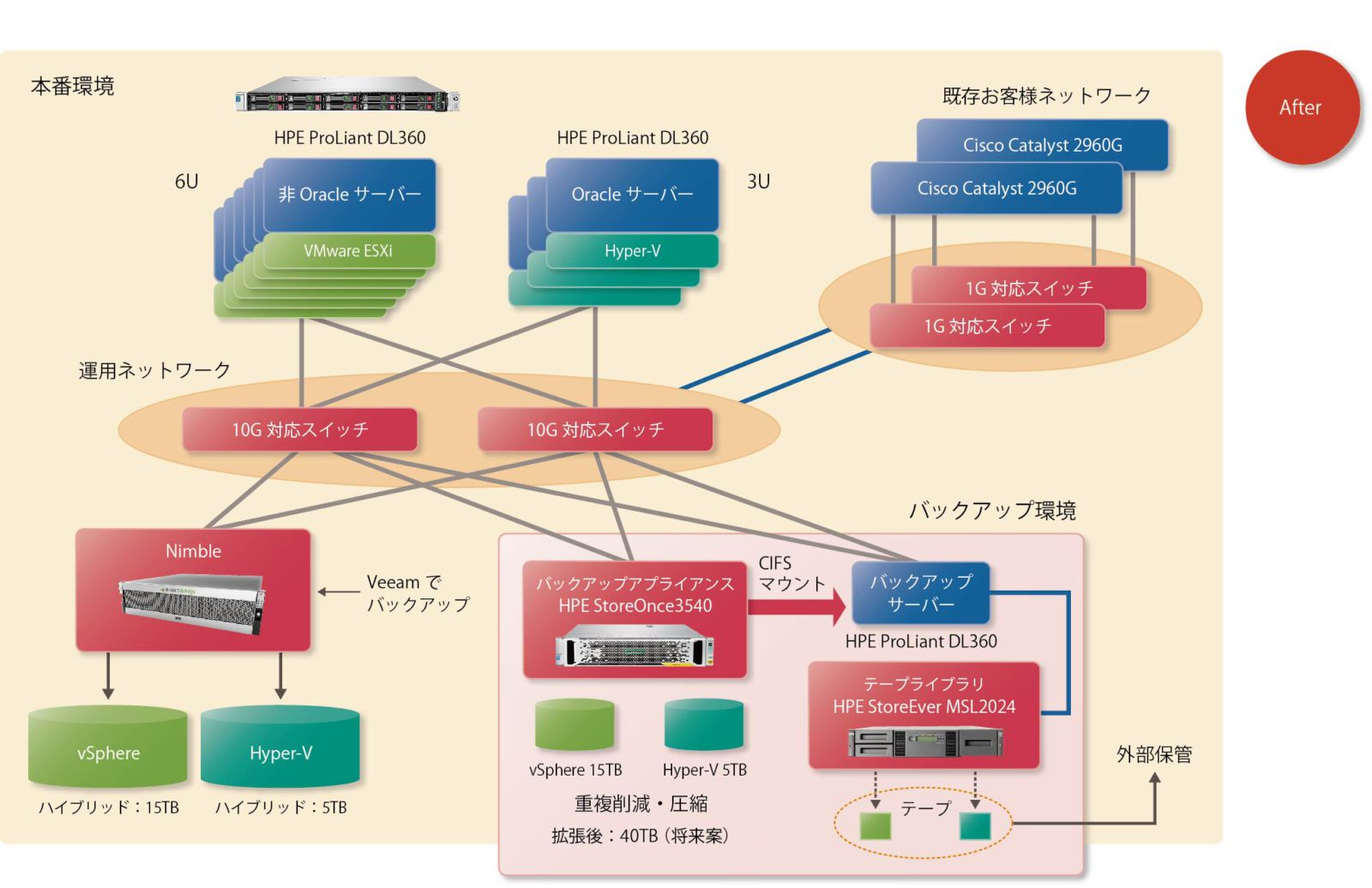
今回の移行により、システムの維持管理にかかる人手作業の範囲を大きく縮小するとともに、バックアップ/リストアを効率化するシステムを実現した。ハードウェア/ソフトウェアの多くをHPE製品で構成したのも「単一メーカーのサポートによる運用管理の負荷軽減」(小松氏)が狙いである。
今後の構想としては、今回の対象外であった親会社のシステム基盤を新しいインフラへ移行させ、クラスタ構成とする計画。「そうなると、システム全体の管理の一元化が図られ、運用が効率化します。5年先を見据えたインフラを導入できたと考えています」(大島氏)[IS magazine No.17 (2017年10月)]







