
text:福島 清果、皆川 正浩 日本アイ・ビー・エム システムズ・エンジニアリング
最近Kubernetesやコンテナを採用したシステム開発が増えている。CNCFの2020年のレポートでは本番環境での採用も伸びているという報告がある。
コンテナ環境の構築形態も、仮想サーバー上での構築やマネージド・サービスの利用など多様な選択肢から利用者に適したものを選べる状況にあるが、事例が増えるに従い、システム構築時の課題も明らかになりつつある。
「CNCF Survey Report 2020」では、コンテナの利用/デプロイに関する課題の調査結果も公開されている。半数近くが「該当する」と回答したのは、「複雑さ」や「開発文化の変革」に関する課題である。コンテナは仮想化技術の一種ではあるものの、Kubernetesのように高度に自動化された仕組みもあり、既存システムとの挙動の違いを把握する必要がある。また、これまでの基盤担当者やアプリケーション担当者の役割の境界が変わり、開発の進め方が変わる可能性もある。
本稿では、既存のWebシステムをマネージド・サービス型のコンテナ基盤(Red Hat OpenShift on IBM Cloud)で稼働するコンテナ・アプリケーションへ更改した事例を踏まえ、開発の現場で起こり得る課題と対応のポイントを紹介していく。
コンテナ・アプリケーション開発スキルをどのように習得するか
多くの企業では物理サーバーや仮想サーバー上で稼働するアプリケーションが多く、コンテナ上で稼働するアプリケーションの開発には慣れていない企業も多いだろう。コンテナで稼働するアプリケーションの開発には、コンテナ特有の作業項目がある(図表1)。
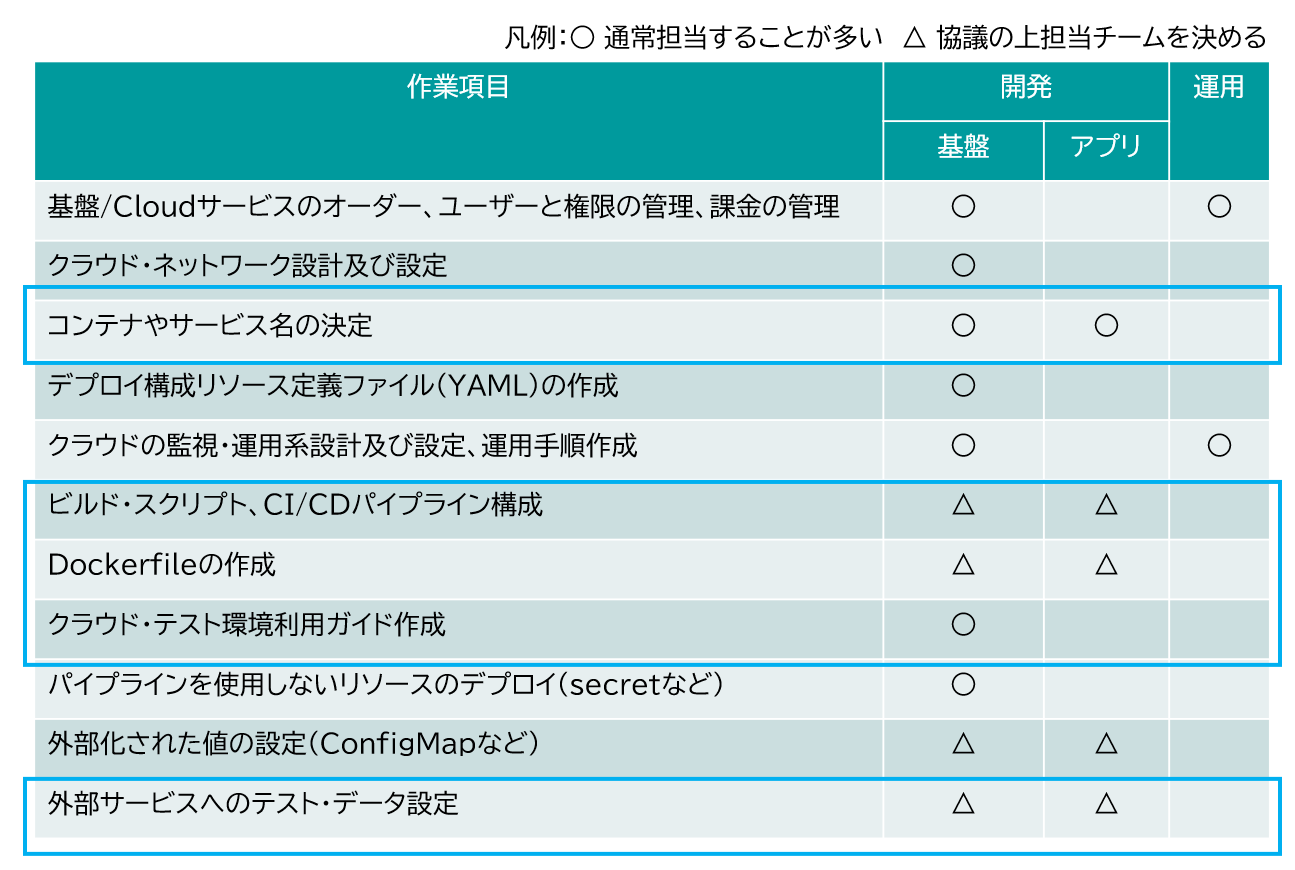
コンテナ特有の作業項目には基盤担当者だけではなく、アプリケーションの担当者が実施する作業もある。たとえば、ビルドやデプロイの自動化のためのビルド・スクリプトやCI/CDパイプライン、コンテナ・イメージのビルドに使用するDockerfileの作成は、基盤担当者とアプリケーション担当者のいずれかが担当するかは開発プロジェクトによって異なることが多い。後述する「環境依存の設定の外部化」も、動的なクラウド環境で稼働するアプリケーションでは必要となるが、外部化された値の設定はアプリケーション担当者が実施する可能性がある。
これらの作業項目をすべて実施できるアプリケーション担当者がいるのが理想だが、コンテナ基盤の選択肢も多様化する中で、すべてをこなせる技術者はまだ少ないのが現実である。そのため、コンテナ特有の作業項目については、開発プロジェクト内でスキルアップが必要になることが多いだろう。
実践的なコンテナ・アプリケーション開発スキルを、より多くのメンバーに効率的に習得してもらうために、筆者らが検討したのは以下の3つのポイントである。
1.コンテナ・アプリケーションの開発で必要となる作業の手順を文書化した「ガイド」を共有する。
2.ガイドによる知識だけでなく、コンテナの環境に触れて慣れることも大切であるため、自由に触れる「練習環境」を用意する。
3.有識者が概要と手順を説明する「研修」の機会を設け、スキル習得の第一歩を踏み出しやすくする。
1つ目の「ガイド」については、最低限、図表2のような内容が必要だろう。

ロギング・ソリューション
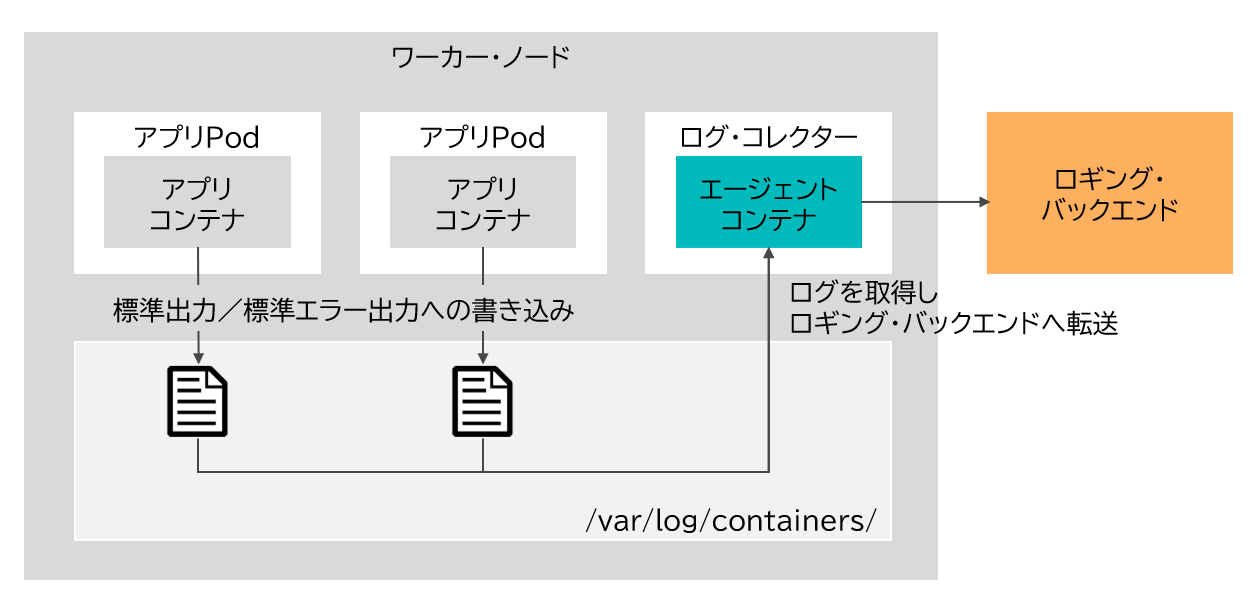
ロギング・ソリューションと呼ばれるものは、コンテナが稼働するワーカーノード上のログを収集して外部に転送する「ログ・コレクター」および、ログを永続化して検索を可能にする「ロギング・バックエンド」の組み合わせとして成り立っている(図表3)。
代表的なものとして、「EFKスタック」(Elasticsearch, Fluentd, Kibana)、「ELKスタック」(Elasticsearch, Logstash, Kibana)と呼ばれる一式が存在する。OpenShift Container Platformには「クラスター・ロギング」と呼ばれる形でEFKスタックをクラスター上に構築する機能が搭載されている。ただし、利用に際してある程度のリソースが消費される点に留意する必要がある。なお、マネージド・サービスであるOpenShift on IBM Cloudには「IBM Log Analysis with LogDNA」(通称LogDNA)というサービスを利用する選択肢もある。
ロギングの考慮点
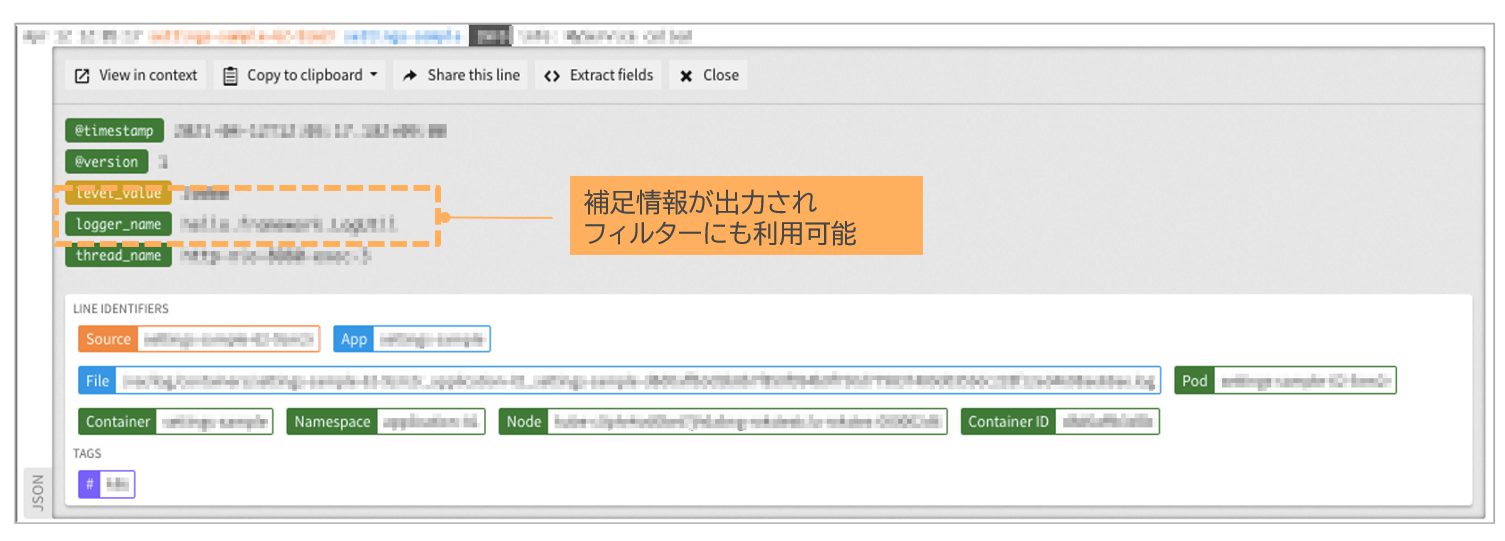
先に述べたように、コンテナ環境においてはログが標準出力・標準エラー出力の一個所に集約される。したがって、ログの監視や分析に際してログの種類(アクセスログや監視ログなど)を識別できるようにするために、種類の情報をログに埋め込む必要がある。たとえばJavaアプリケーションでは、LogbackのJSON encoderを使ってJSON形式でログを出力すると、ロガー名が補足情報として埋め込まれる(図表4)。ログの種類に応じてロガーを分けることで、ロギング・ソリューションのフィルタリング機能を通じてログが種類別に確認できるようになる。
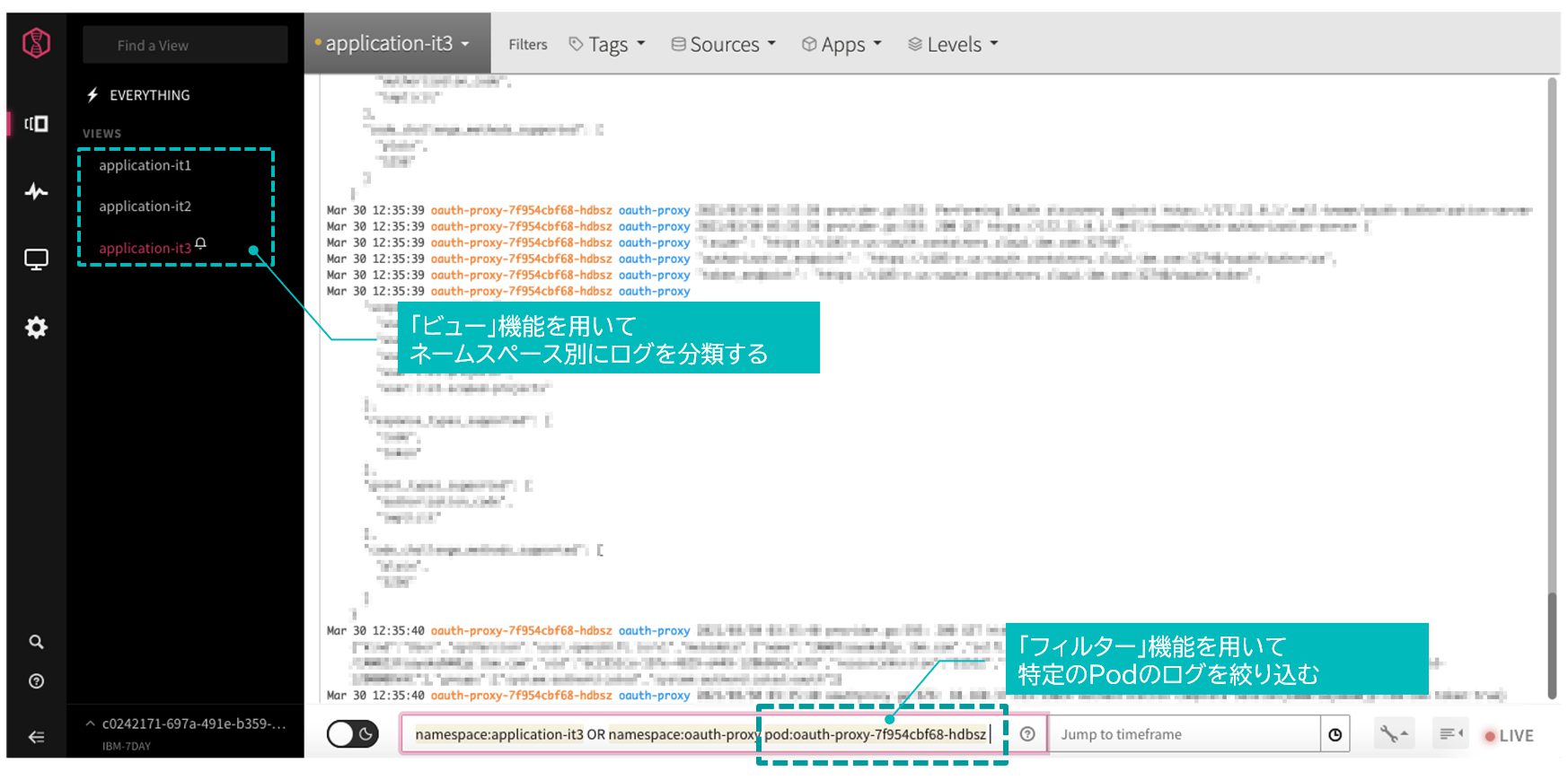
ロギング・ソリューションには通常、フィルタに基づくビューを作成する機能が備わっている。確認すべきログの種類が予めわかっている場合には、ビューを保存しておいてチーム内で周知すると分析時に便利だろう。またアプリケーションの問題判別の場面では、必要なログの種類が状況に応じて変わってくるため、フィルタ機能やアラート通知機能の手順や権限を予め整備しておくことが勧められる。とりわけ開発環境ではアプリケーション開発メンバーがフィルタ機能を使いこなせる状態が望ましい。
LogDNAのWeb UI例を図表5に示す。LogDNAのWeb UIで、はビューの切り替えや検索条件を入力してログが絞り込める。検索条件には AND や OR といった論理演算も使用できる。
アプリケーションをコンテナ環境に対応させるファーストステップを知る
新たにコンテナ環境に対応するアプリケーションを開発することになった開発者としては、はじめの一歩として何をすべきか気になるところだろう。結論を先に述べると、アプリケーションと設定情報を切り出すことが第一歩である。なぜなら、これらが密に結びついたままではコンテナの恩恵が十分に得られないからだ。まずはここで、コンテナ化によって得られるメリットについて確認しておきたい。
コンテナ化のメリット
アプリケーションをコンテナ化することで、複数の環境で実行できる可搬性がアプリケーションにもたらされる。アプリケーションの本体とアプリケーションの実行に必要なファイルが1つのコンテナイメージとしてまとめられるからだ。これにより、たとえば開発環境で動作が確認できたアプリケーションがステージング環境や本番環境で動作しないという事態が避けられる。
ところがコンテナ化の方法を誤ると、「可搬性」というメリットが損なわれてしまう。たとえば、環境固有の設定情報をコンテナイメージに含めることは、環境ごとに個別のイメージを作ることにつながるため好ましくない。作られるイメージが相異なる実体であるため、どれか1つのイメージの動作が確認できても、そのことは他のイメージの動作を必ずしも保証しない。また、作られるイメージの個数が増える分、それだけイメージのビルド、レジストリへのプッシュ、レジストリからのプルといったオーバーヘッドが増えるだろう。こうして、コンテナのメリットが弱められてしまうのだ。
設定情報の外部化
環境固有の設定情報をコンテナイメージに含めないようにするためには、第一歩としてどの設定項目が環境固有であるかを洗い出す必要がある。たとえば、アプリケーションが連携する外部システムの接続情報や、ログレベルなどは環境固有のものになるだろう。これらの設定項目が開発環境と本番環境とで異なってくることは想像に難くない。
続いて、洗い出した項目に該当する設定情報をアプリケーションから切り出すことになる。切り出した設定情報は、環境変数や設定サーバーなどのコンテナ外部に格納し、アプリケーションはそれらの設定ストアから設定値を取得するように実装する。なお、既存のアプリケーションをコンテナ化するプロジェクトであれば、設定ファイルそのものをコンテナの外部で管理し、実行環境のボリュームとして設定ファイルをマウントする方法が相応しいかもしれない。こうすることで、実装の変更箇所を少なく抑えられる。
設定を取得する実装
環境変数から設定値を取得する実装の方法には複数の選択肢がある。本稿ではJava + Spring Bootでの例を紹介する。
まず、プログラムそのものはapplication.properties (application.yml)ファイルから設定値を取得するように実装しておく。そうすると、Spring BootのRelaxed Binding機能を経て環境変数の値が取得できるようになる。なお、application.propertiesファイルに記述した値よりも環境変数の値が優先されるため、このファイル自体はデフォルト値の設定に利用できる。さらに、設定項目がこのファイルに集約されるため見通しが良くなるメリットがある。設定項目の見通しの良さは後の設定漏れを防ぐために役立つだろう(図表6)。
以上でJava + Spring Bootの例を紹介したが、PythonやJavaScript (Node.js)の場合は.envファイルが今回のapplication.propertiesファイルと類似の役割を果たすと思われる。

環境変数の設定
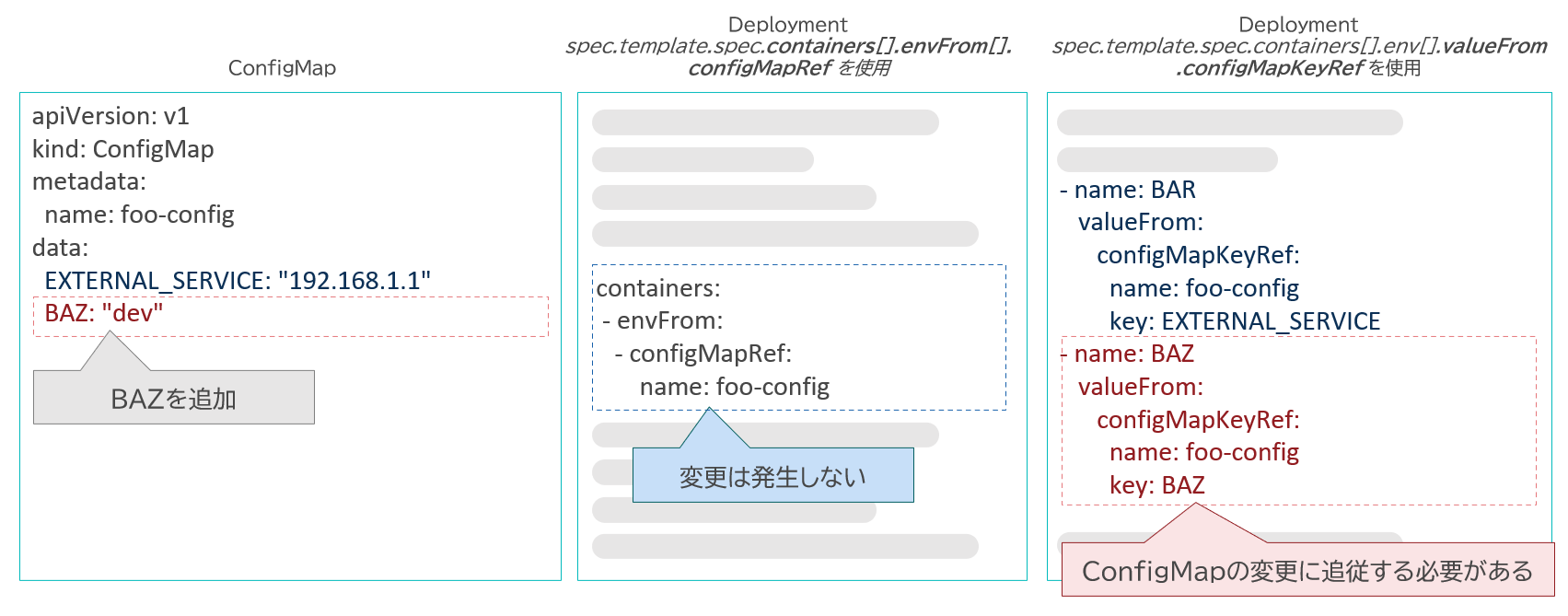
OpenShiftやKubernetesを利用するコンテナ環境では、環境変数の設定値をConfigMapと呼ばれるリソース上で定義し、Deployment等のワークロード定義リソース(以下、Deploymentで代表する)からConfigMap上の設定項目を参照していく。参照方法には2通りある(図表7)。
・spec.template.spec.containers[].envFrom[].configMapRef を利用する方法
・spec.template.spec.containers[].env[].valueFrom.configMapKeyRef を利用する方法
前者の方法では、ConfigMapの設定項目すべてが環境変数として利用されることになるため、設定項目の増減に際して必要な変更箇所はConfigMap定義のみであり、Deployment定義には変更が発生しない。その半面、ConfigMapにボリュームマウント対象のファイルを含めている場合、そのファイルの中身までもが「環境変数」として扱われてしまう点に注意が必要である。
後者の方法では、個々の環境変数ごとに参照を記述することになるため、設定項目の増減に際してConfigMap定義とDeployment定義の両方の変更が必要になる。また、設定すべき環境変数の個数が多い場合にはDeploymentの記述量が多くなるため、定義ファイルの見通しが悪くなることに注意が必要である。一方で、環境変数用の項目とボリュームマウント用の項目を1つのConfigMap定義にまとめられるメリットもある。
利用するケースに適う方法を選択したいところだ。
環境変数を利用しない実装
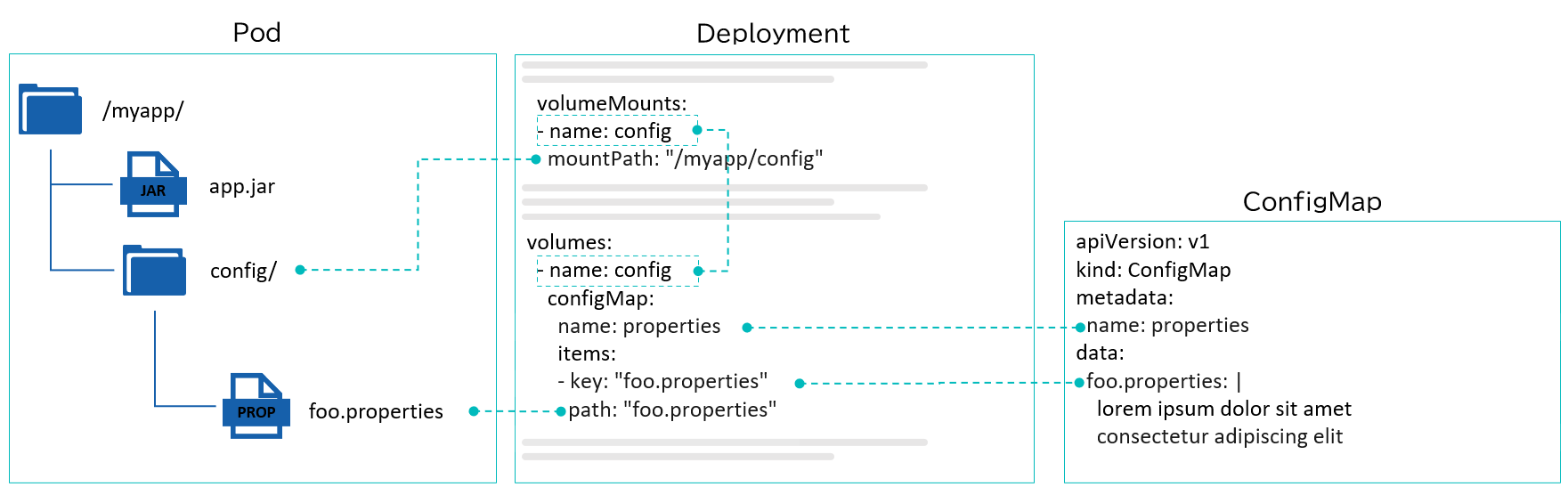
既存のアプリケーションをコンテナ化するプロジェクトなどで、設定値を取得する箇所のソースコードを大きく変える余裕がない場合があるかもしれない。既存のアプリケーションが設定ファイルを読み込むように実装されているのであれば、ConfigMapに設定ファイルを埋め込んでおき、そのConfigMapをボリュームとしてコンテナ内のディレクトリにマウントする方法が設定の外部化に有効だ(図表8)。
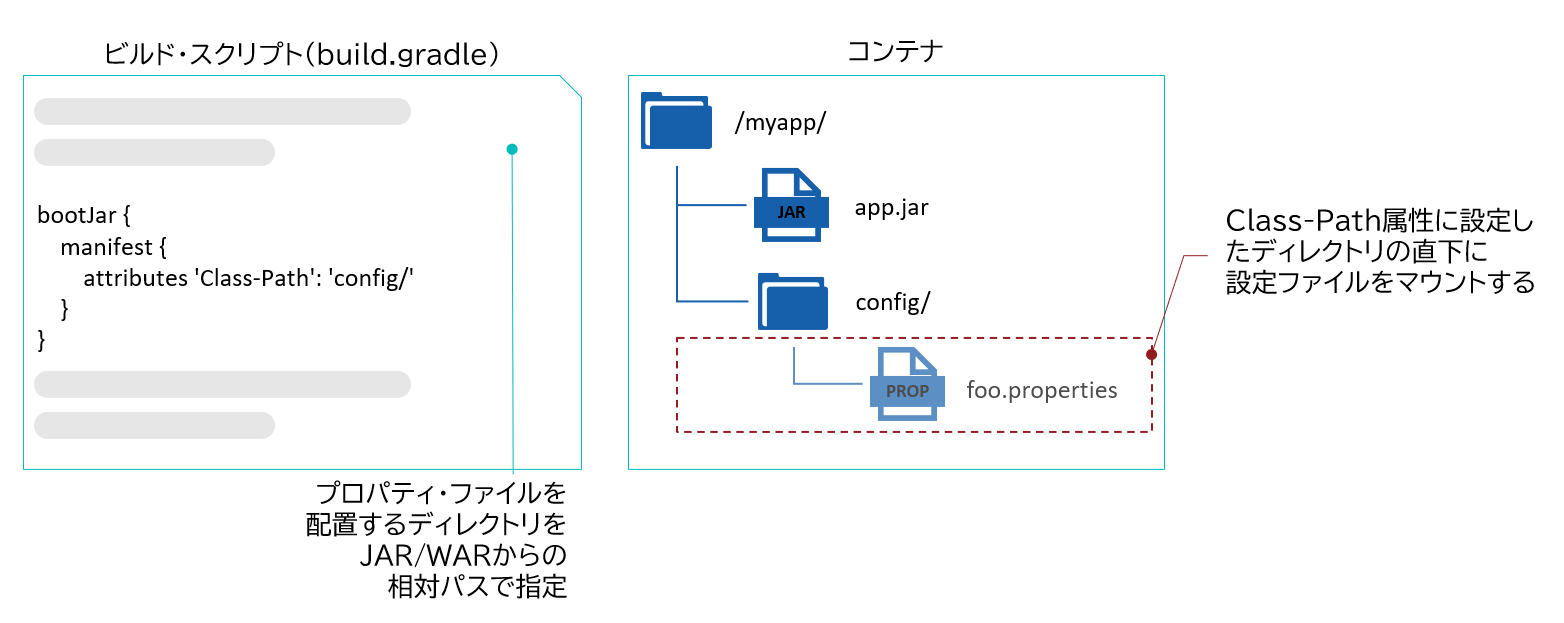
なお、Javaアプリケーションの設定ファイルがJARなどのアーカイブに格納される場合には、設定ファイルをマウントする手法が使えないように見えるかもしれない。その場合には、JARのマニフェストにおけるクラスパスの設定を利用して、特定のディレクトリから設定ファイルを読み込めばよい(図表9)。
Infrastructure as Codeと複雑な開発環境の管理をどう両立するか
Kubernetesでは基盤の構成をリソース定義ファイル(YAML形式)に記述することが可能なため、基盤情報のコード化(Infrastructure as Code)を実現しやすい。Infrastructure as Codeは動的なクラウド環境の構成管理に非常に有効な手段であるが、開発テスト環境は複数の論理的区画に分割されていたり、複数の案件の開発を並行で実施しているなど、管理すべき構成情報のバリエーションが多く、管理に悩むことがある。
たとえば複数の案件で並行開発をしているケースで、1つの案件ではリソース定義ファイルへの新たなコンテナの追加が必要だが、別の案件では追加をしない状態でリリースしたいということがある。それぞれ案件の開発が重なる期間がある場合、このように相容れない要求をどのように管理していくのか考えてみる。
基盤のリソース定義ファイルは、バージョン管理ツールのGitなどで管理できるが、アプリケーションのソースコードとは別のリポジトリで格納されることが一般的だ。それは、パイプライン実行の効率性の考慮(リソース定義ファイルの変更時にアプリケーションのビルドが実行されてしまうのを避ける)や、アプリケーションと基盤の責務の分解といった目的がある。「GitOps」という基盤構成の自動化においても、アプリケーションと基盤のリポジトリの分離が前提である。
バージョン管理ツールでは、作業の枝分かれを管理するブランチ機能があり、アプリケーション・リポジトリでは、案件やリリース・タイミングの違いなど、並行作業を行いたい場合はブランチを分けるのが一般的である。一方、インフラ構成ファイルについてはバージョン管理自体が比較的新しい考え方であり、ブランチが活用されていないケースも多い。しかし開発環境で複数の案件を並行で開発する場合、単一ブランチの方が管理が煩雑になることもあり、ブランチの活用によるメリットがある(図表10)。
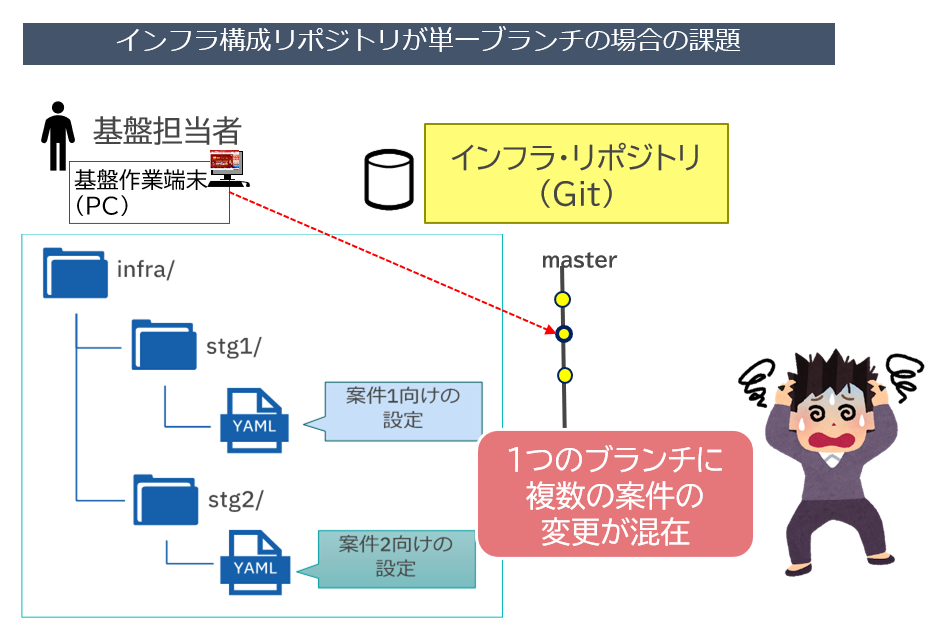
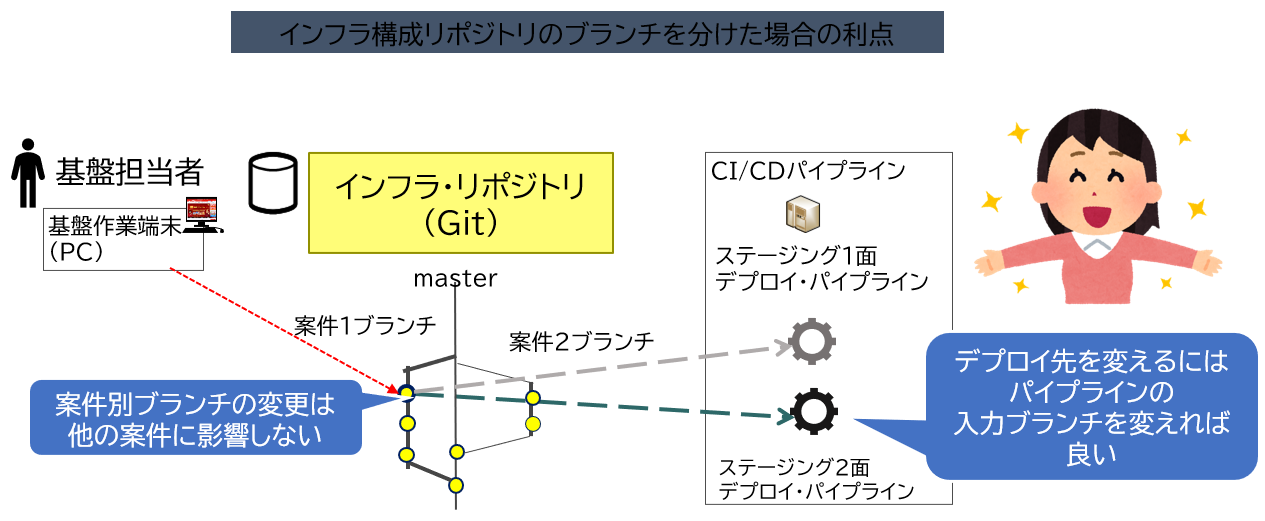
図表10のように、単一ブランチの場合、個別に管理したいリソース定義ファイルはディレクトリーなどを分けて管理することになる。その場合どのディレクトリにどの案件のリソース定義ファイルを格納しているのかを管理しておく必要がある。また複数の作業の変更が混在しているため、間違いやすくミスにも気づきにくい。
これに対し、インフラ構成リポジトリでも独立した作業単位、たとえば案件別、でブランチを作成すれば、1つの作業用のリソース定義ファイルの変更は別の作業に影響しない。ブランチの内容は1つの作業の変更のみが含まれるため、変更点の確認などもしやすくなる。また、検証のためのデプロイ先の面を変更したい場合にも、デプロイ用のCI/CDパイプラインで利用する作業ブランチを切り替えるだけで済む。
実際の事例においては、アプリケーションと合わせた案件ブランチを作る方法へ切り替えることで、案件別の並行開発が多い状況における構成の管理にも柔軟に対応できている。
KubernetesやOpenShiftのデプロイ時の挙動の複雑さへの対応
KubernetesやOpenShiftといった高度に管理が自動化されたコンテナ基盤では、ロールアウト(デプロイ)の管理機能が備わっており、リソース定義ファイルに定義された状態になるようにアプリケーションをロールアウトする。つまり、デプロイ後にリソース定義ファイルに定義された状態を満たせないと新しいPod(コンテナ)の起動は停止されるため、常に最新のアプリケーションが稼働しているとは限らない。この挙動は既存システムの開発に慣れている技術者にとっては馴染みがないことが多く、十分に理解してデプロイを行わないと想定どおりの環境で検証が行えないことになる。
デプロイに失敗する原因には、ワーカー・ノードのリソース不足、参照している他のリソースとの不整合、アプリケーション起動直後のプロセスの終了、ヘルスチェックの失敗などがある。
デプロイ・パイプラインにおけるデプロイ後のチェックとログ出力
CI/CDパイプラインによるビルドやデプロイの自動化は、リリース作業の負荷軽減や開発の高速化という意味において大きなメリットがある。デプロイには新たなコードを稼働させる目的があるため、デプロイ後に重要なのは最新のコードが確実に稼働していることである。そのため、KubernetesやOpenShiftの環境におけるデプロイ・パイプラインではデプロイを自動化するだけでは十分でなく、最新のデプロイ結果の確認が不可欠となる。具体的にはkubectlまたはocのrollout statusというコマンドで最新のデプロイ結果を確認することができるため、これらの処理もパイプラインに含めるように留意したい。
rollout statusコマンドについて詳しく知りたい場合は以下のリンク先をご覧いただきたい。
2.デプロイに失敗したPodのEventを確認する。
コンテナが起動する前に発生した問題はコンテナのログではなく、PodのEventに出力される。先に説明したワーカー・ノードのリソース不足、参照している他のリソースとの不整合、ヘルスチェックの失敗などはすべてPodのEventに出力される。そのため、コンテナのログを確認する前に、まずはPodのEventを確認する必要がある。
3.PodのEventには問題がないが、アプリケーションのコンテナがすぐに落ちて再起動してしまう場合は、ロギング・ソリューションでログを確認する。
先に説明したように、デプロイした面や再起動してしまうPodの名前でフィルタリングして、ログにエラーが出力されてないかを確認すればよい。
実際の事例においても、この問題発生時の原因分析の流れを押さえることで、開発テスト環境のデプロイ時に発生した問題に、これまでコンテナ・アプリケーションの開発を行っていなかったメンバーでも落ち着いて対応できるようになっている。
今回は、コンテナの利用時の課題とその対応ポイントを、実際の経験をもとに紹介した。
コンテナ基盤は、新しいテクノロジーを利用するアプリケーションを迅速に稼働させるという意味において大きなメリットとなる。そのため、ITによりビジネス価値を向上させようとする企業では、今後ますますコンテナ基盤を活用できることが求められるだろう。
読者の皆様がコンテナを利用する案件に関わる際に、今回の内容を活用していただけると幸いである。
福島 清果 氏
日本アイ・ビー・エム システムズ・エンジニアリング株式会社
クラウド・アプリケーション
アドバイザリーITスペシャリスト
入社以来、金融業や製造業などさまざまなシステムのテスト自動化に携わり、近年はOpenShiftなどコンテナ環境におけるCI/CDや開発ツールチェーンの提案から構築で活動中。バリバリの理系ではないため、先進的なテクノロジーを苦労して噛み砕いて、より多くの人にわかりやすく届けることを自身の役割としている。

皆川 正浩 氏
日本アイ・ビー・エム システムズ・エンジニアリング株式会社
クラウド・アプリケーション
ITスペシャリスト
新卒入社以来、クラウド周辺のサービスおよび製品の技術支援に従事してきた。2021年6月より日本IBMのテクノロジー・ガレージ部門に出向し、プラットフォームとアプリケーションの両方を担う「二刀流」の技術者として、お客様と価値の共創を目指している。

[i Magazine・IS magazine]







