Text=岡口 純子 日本IBM
AIを業務に適用するためにデータ分析を日々進化させている企業では、データの重要性が増すとともに、さらなる課題に直面している。
爆発的に増え続け、多種多様な形式で構成されるデータへの対応、散在してサイロ化されたデータへの効率的なアクセス、いざ分析に使ってみると発覚するデータ品質の問題など、その時々のデータに関する課題を解決するために、多様なテクノロジーが生み出され、進化を続けている。
時にはテクノロジーだけでは解決できず、組織、人材の育成、プロセスの改善などへの対応も必要になる。本稿ではそれらの課題解決の一策として、watsonx.dataというオープンなアーキテクチャを備えるレイクハウスソリューションに触れつつ、レイクハウスとオープンなテーブルフォーマットという選択肢について考察する。
データ分析基盤の変遷
図表1にあるとおり、Bill Inmonが1990 年代初頭に「データウェアハウス」の概念を提唱し、90年代後半にはデータを分析するための主要な方法としてデータウェアハウスが登場した。

業務システムに影響を与えることなく正規化された信頼できるデータは分析を容易にし、その後もウェアハウス・テクノロジーは、アプライアンスから列指向、インメモリへと継続的に進化している。
2000年代に入ると(日本では2010年頃から)、ビッグデータというキーワードの下、データの量、速度、種類が大きく拡大するのに伴い、データウェアハウスを補完する新しいテクノロジーとして「データレイク」が登場した。
ビッグデータは生データのまま保管し、構造化データだけでなく非構造化データも保管して活用するため、HadoopやNoSQLなどの新しいテクノロジーが登場し、データレイクに大量データが保管されるようになった。
しかし保管しただけでは、何が入っているか分からず、利用されずにデータが沼化(データスワンプ)していく。そのためデータレイク(狭義のデータストア部分のみ)だけでは維持管理やデータへのアクセスが一般ユーザーには難しく、カタログなどユーザーが利用しやすいような追加のテクノロジーを必要とした。
しかしカタログ整備は手間がかかるので、実装されたケースは少ない。結果的にほとんどのデータレイクプロジェクトは活用が進まず、失敗したと言われている。
その後、クラウドの波が訪れるとともにデータ分析基盤もクラウド化し、大量データをクラウドに保管し、分析用に「クラウド・データウェアハウス」を利用するようになった。クラウド・データウェアハウスの特徴としては、コンピュートとストレージが分離されている、データ量や処理量に合わせて拡張しやすい、利用した分だけ課金するという料金体系を備えるといった点が挙げられる。
これは従来のデータウェアハウスで指摘される拡張性の課題、すなわちデータの再配分を不要にした点が画期的であった。
しかし管理は容易であるものの、本格的に利用した場合、ユーザー数やデータ量が増えるに従って、従来よりもコストが高額になるケースも見られた。従来のオンプレミスのデータウェアハウスでは処理量が増え、性能に影響が出ても、購入して5年間の償却期間の料金が固定または予測可能であったのに対し、クラウドでは柔軟な構成変更が可能で、利用した分だけ課金される。そのため、請求書が届いて初めて想定以上に利用しているとわかるケースが出てくるわけだ。
現在では生データ、非構造化データ、半構造化データ、アーカイブデータなどの置き場としてのデータレイクと、ユーザーが活用するデータウェアハウスという2 層アーキテクチャを採用する企業が多くなった。
そのため、データはデータレイクからデータウェアハウスへと移動・複製し、主要なデータへのアクセス・レイヤーはデータウェアハウスのままである。ユーザーが必要になった時にデータウェアハウスへ移動させないとアクセスできなかったり、時間とコストがかかったりで、活用を諦めるケースもある。データレイクにあるデータの活用はなかなか難しい。
第1世代レイクハウスの登場
このデータ移動の時間とコストを低減し、データレイク上のデータ活用を促進していくために、「データレイクハウス」というデータウェアハウスとデータレイク双方の利点を組み合わせたソリューションが登場した。
図表2で示すとおり、これは低額なデータレイクのストレージに、使い勝手のよいデータウェアハウスのエンジンを組み合わせたものだ。
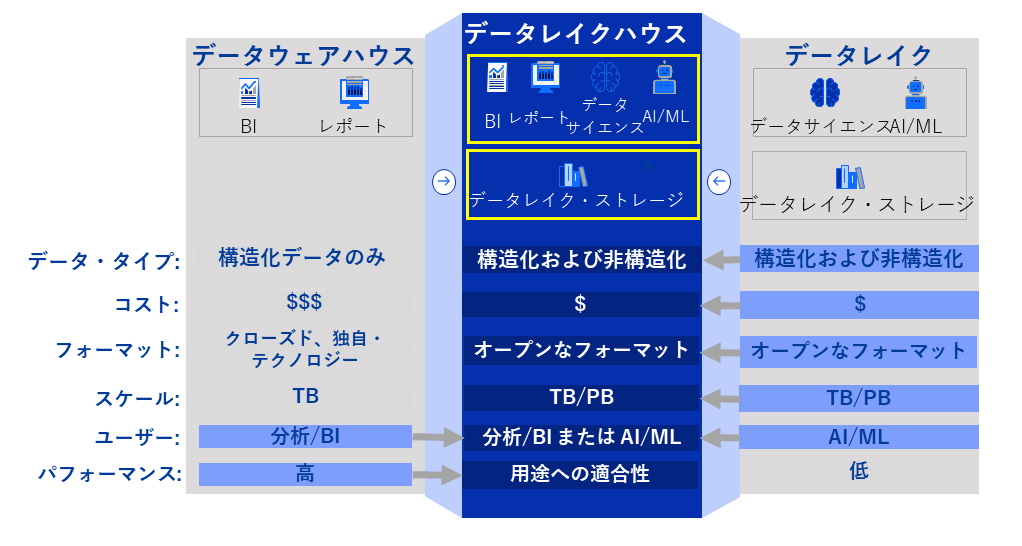
とは言え、新しいテクノロジーはそれぞれの課題を解決するために独自に開発されていく。データレイクハウスも、ML(機械学習)やBIといったワークロードに特化して発展している。
またクラウドのみのサービスであったり、当初は機能実装を優先させたためデータガバナンス機能は最小限といったように、すべてのデータを1つのテクノロジーで解決できないという課題がある。
オープンなレイクハウスアーキテクチャであるwatsonx.data
IBMでは第1世代レイクハウスで指摘される課題への解決策として、watsonx.dataというオープンなアーキテクチャを備えるレイクハウスソリューションの提供を開始した。
watsonx.dataは、以下のような特徴を備えている。
1) マルチクエリーエンジン
2) オープンテーブルフォーマットの採用
3)カタログの分離
4)データガバナンス
5)GUIの充実
watsonx.dataは、図表3で示すようにオープンソースのPresto、Sparkが選択可能で、Apache Iceberg形式(Apache 2.0 ライセンスの 100%オープンソースデータテーブル形式。以下、Iceberg)でのオープンなテーブルフォーマットを採用している。
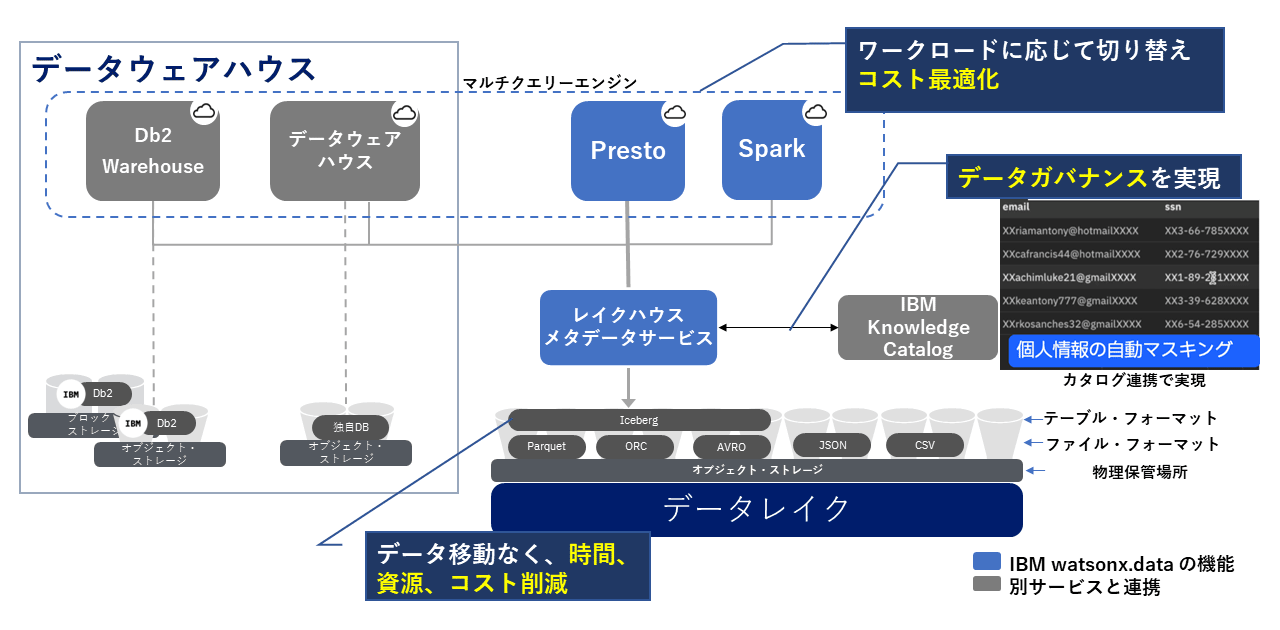
さらにIcebergをサポートするDb2、Netezzaへのクエリーエンジンへも切り替えられるマルチクエリーエンジンのアーキテクチャを備える。これにより、シングルクエリーエンジンでは対応が難しかった複数のワークロードに対応できるようになる。
Meta社が大規模データのリアルタイム処理に向けて開発し、オープンソース化したPrestoは分散SQLエンジンであり、各種データソースへアクセスするコネクターを幅広く提供している。そのためデータを移動・複製することなく、既存データにアクセスすることも可能である。
オープンテーブルフォーマットの採用
マルチクエリーエンジンと並ぶwatsonx.dataの大きな特徴が、オープンテーブルフォーマットの採用である。ここでは、なぜオープンテーブルフォーマットなのかを考えてみよう。
データウェアハウスは、それぞれが最適のフォーマットで格納されている。そのため、他のデータベースから直接アクセスすることはできない。他のシステムでもデータが必要な場合は、データをエクスポートし、インポート/ロードする必要がある。
データレイクに保管されるデータフォーマットは、構造化データの場合、CSVなどの形式が多かった。しかし大量データ処理ではレコード、ファイル単位で扱うと性能的に遅いので、ParquetやORCといった列指向のデータフォーマットが利用され始めている。
列指向は圧縮率が高く、IoTのセンサーデータなどの大量データはいったんデータレイクに格納され、必要に応じてクレンジング、整形、抽出したデータをデータウェアハウスに格納する。そしてユーザーは、そのデータウェアハウスにアクセスするという使い方が一般的である。
データレイクに直接アクセスするには、複雑であったり、性能的に課題となるケースもあり、一部のデータサイエンティストかIT部門のみが扱い、一般のユーザーには開放されていなかった。
2017年からNetflixによってIcebergが開発され、オープンなテーブルフォーマットとして公開された。オープンなテーブルフォーマットであるIcebergをサポートするのは、同じオープソースであるApache Spark、Apache Flink、Apache Hive、および Prestoなどに加え、対応するベンダーのデータウェアハウスも登場している。
IBMではDb2 Warehouse、Netezzaがサポートを開始し、SnowflakeやAWS AthenaもIcebergをサポートしている。つまり、いったんIceberg形式でデータを格納すれば、データへアクセスするためのクエリーエンジンの切り替えが可能だということだ。
データウェアハウスの場合、データベースエンジンの切り替えはデータ移行とSQL非互換によるアプリケーション改修を伴うので、ベンダーロックインしやすい傾向にある。
オープンテーブルフォーマットを各種データベースエンジンがサポートするようになれば、データのシステム間連携の際、図表4の例のように、一度オープンなテーブルフォーマットで格納し、公開することで、他のシステムのデータベースはローカルにロードし直すことなく、そのデータにアクセスできるようになる。
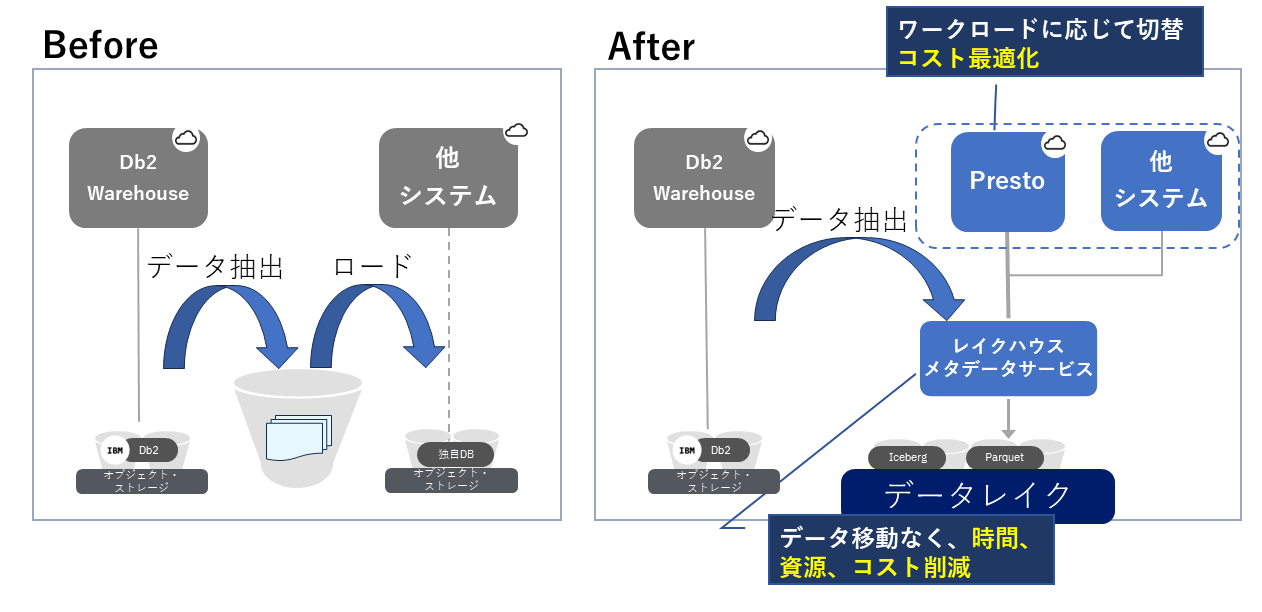
もちろん、最適なパフォーマンスのためにロードし直すデータも出てくるだろうが、すべてを内包することなく、そのままデータにアクセスすることで、複数システムでのデータの複製・保管を抑制し、タイムラグを軽減、かつ移動に伴う時間・資源・コストを削減できる。
前述したように、それぞれのクエリーエンジンは、バッチ処理が得意であったり、リアルタイム検索が得意であったりと、その目的に合わせて開発されてきた特徴を備える。
オープンテーブルフォーマットを採用し、クエリーエンジンを切り替えるというマルチクエリーエンジンのアーキテクチャは、さまざまなワークロードに応じてクエリーエンジンを切り替えることにより、最適な性能とコストのバランスを取ることが可能になる。
カタログ分離の価値
watsonx.dataは、カタログをコンピュートとストレージから分離した。DBはどれも独自のシステムカタログを持ち、表やカラム、属性情報などメタデータを管理している。
外部のファイルや表にアクセスする場合は、外部表定義やニックネームとして、その表の表名、スキーマ、列定義などを独自のシステムカタログに登録することでアクセスが可能となる。
このカタログを独立させることで、表定義をそれぞれのDB側で一度登録すれば、それぞれのクエリーエンジン(DB)は再度登録し直すことなく、該当の表にアクセスできるようになる。
具体的にSQLを見てみると、通常のSQLでは表名またはスキーマ名.表名として表を特定するが、カタログが独立しているwatsonx.dataでは下記のように3パートネームとして、“カタログ名.スキーマ名.表名”として表にアクセスする。
SELECT * FROM カタログ名.スキーマ名.表名
これにより、どのクエリーエンジンからも同一のSQLにより、どこに保管されている異種DBの表であったとしても表や列を特定してアクセスが可能になる。
データガバナンス
生データも保管されるデータレイク上のデータを分析業務で活用するには、データガバナンスを考えねばならない。
データへのアクセス制御は今までデータソース側が担ってきたが、個別の表や列、ユーザーに合わせたアクセス制御設定はかなり煩雑であり、設計と運用が大変であった。
また、利用するかどうかわからないデータをすべてマスキングなどのデータ加工をしてから保管するのは、データが大量である場合、コストと時間が嵩むことになる。
watsonx.dataでは、カタログにデータ保護ルールというポリシーをあらかじめ設定しておき、実データにアクセスする際にリアルタイムにデータマスキングやアクセスブロックを行うという既存のテクノロジーと連携することで、設定漏れをなくし、データガバナンスを実現している。
具体的には、図表3にあるIBM Knowledge Catalogのデータ保護ルールの機能と連携し、個別のテーブル設定だけではなく、データをプロファイリングした結果のデータクラス(メールアドレスやIDなどを自動認識)やtagなどより、抜け漏れなくポリシーに従ったアクセス制御をリアルタイムに実現する。
GUIの充実
データ分析基盤を構築、運用、利用するユーザーのスキルも企業によりさまざまである。そのため簡単に活用したいのっであれば、コマンドやAPIだけの提供ではなく、GUIツールによる設定や一元管理を実現することもソリューション利用の裾野を広げる意味でも有効である。
watsonx.dataは散在しているデータソースとカタログの登録、複数利用可能なクエリーエンジンの登録・管理をサポートし、現在の設定とステータスを視覚的に把握するインフラストラクチャー・マネージャーや、複数のデータソースを一元管理するデータマネージャー、SQLの実行と簡単なSQL自動生成を行うSQL照会ワークスペースなどのGUIを用意している。
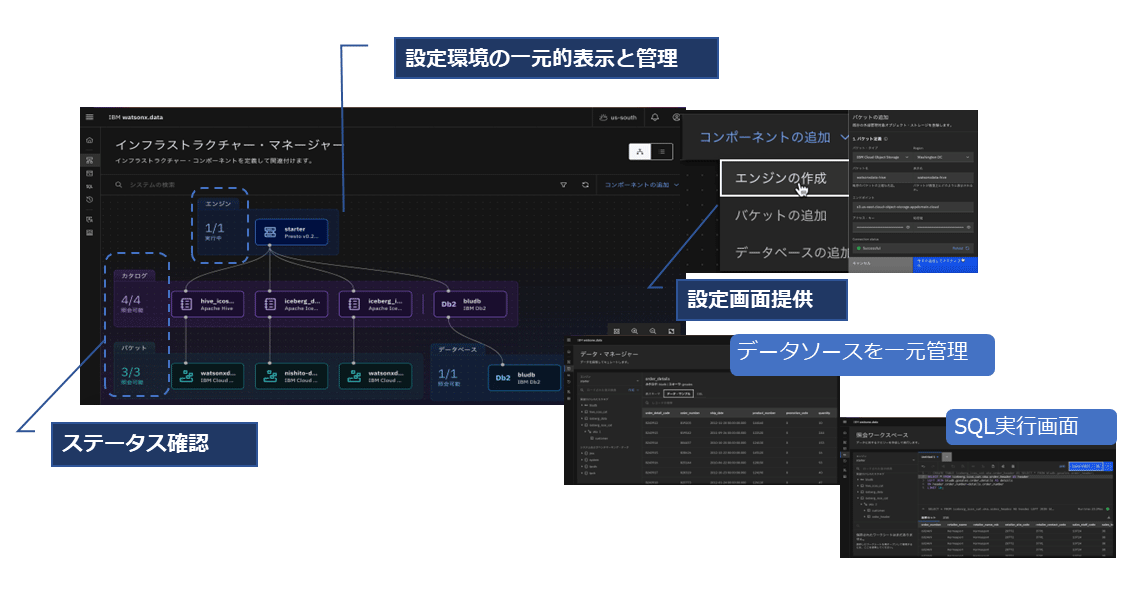
今後の拡張の方向性
watsonx.dataはまず、構造化データ、半構造化データの取り扱いを容易にするためのSQLインターフェースから提供を開始したが、すでに今後の機能拡張も発表している。ベクトルDBと生成AIによるユーザーインターフェースの拡張である。
ベクトルDBはテキストや動画など主に非構造化データをベクトル化して格納し、類似検索などを容易にするテクノロジーである。
生成AIの大規模言語モデル(LLM)の回答精度を上げるために社内データなどを検索し、その結果をLLMでより自然な回答にするRAG(Retrieval Augment Generation)という手法がある。その社内データを格納し、類似検索する際にはベクトルDBに格納するのが一般的である。
マルチクエリーエンジンの仲間としてベクトルDBを追加し、オブジェクトストレージ上にあるテキストや動画、音声など非構造化データをベクトル化することで、データ活用がより進化すると期待される。
また、watsonx.data上に保管される大量データの中から、目的のデータを見つけやすくするインターフェースとして、チャットでやり取りし、どのようなデータが入っているのかというメタデータを生成AIによって自動作成する。それによりカタログ登録の負荷を軽減するとともに、ユーザーがSQLを使わなくてもデータを発見し、目的のデータを入手可能にする機能などが提供される予定である。
レイクハウスは、どの企業にもすぐに選択肢となるようなテクノロジーではない。データ容量が数TBまでで、BIツールで参照する構造化データのみを扱いたい場合は、従来どおりデータウェアハウスだけを利用したほうが管理、運用、性能、コストの面でメリットが大きい。
しかしすでにデータレイクを構築しているものの、そのデータレイクを十分に活用できていない、あるいは今後急激に増え続けるデータの取り扱い、システム間連携でのデータの2重管理、その時間とコスト、データガバナンスなどに課題を抱えている場合もあるだろう。本稿が今後の分析基盤のアーキテクチャを検討する際の一助となれば幸いである。

*本記事は筆者個人の見解であり、IBMおよびキンドリルジャパン、キンドリルジャパン ・テクノロジーサービスの立場、戦略、意見を代表するものではありません。
当サイトでは、TEC-Jメンバーによる技術解説・コラムなどを掲載しています。
TEC-J技術記事:https://www.imagazine.co.jp/tec-j/
![]()
[i Magazine・IS magazine]