IBM i のデフォルトな日本語環境
IBM i には、使用する言語や文字コードに関するシステム値やオブジェクトの指定があり、これらの設定によって使用される文字が決定する。実際にIBM i を使用する際に、文字コードがどのように設定されるのかを考えてみよう。
IBM i の日本語環境は現在、日本語2962と日本語2930ユニバーサルの2つが提供されている。AS/400の登場以来、提供されている日本語環境は2962で、現在でも多くのユーザーで2962が使用されていることから、ここでは2962が導入されている環境について考えてみる。
一次言語を2962で導入する場合の言語に関するシステム値のデフォルトは、グローバリゼーションのマニュアルに記載されている(図表5)。
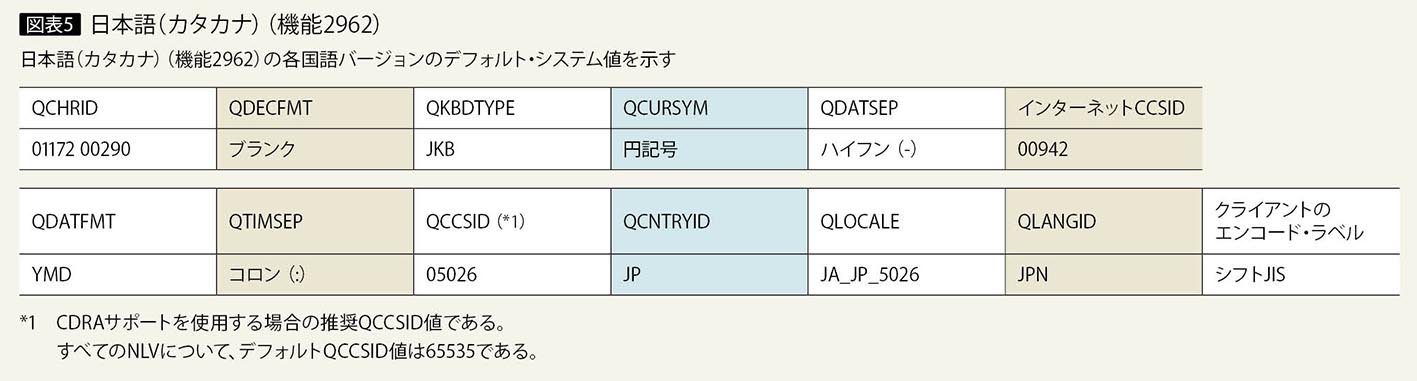
QCCSIDは5026が推奨値であるが、デフォルトのまま変更しない場合について考えてみたいので、QCCSIDは65535とする。
IBM i のジョブで使用される言語環境に関する以下の値は、サイン・オンするユーザー・プロファイルの値を参照する。
・言語ID (LANGID)
・国別または地域ID (CNTRYID)
・コード化文字セットID (CCSID)
・文字識別コードの制御 (CHRIDCTL)
・ロケール・ジョブ属性 (SETJOBATR)
・ロケール (LOCALE)
ユーザー・プロファイルを作成する際に、上記の値について何も設定しない場合は、すべて*SYSVAL(システム値を参照)となる。
・言語ID (LANGID)=JPN
・国別または地域ID =JP
・コード化文字セットID =65535
・文字識別コードの制御 (システム値QCHRIDCTL)= *DEVD
・ロケール・ジョブ属性 (システム値QSETJOBATR)= *NONE
・ロケール=/QSYS.LIB/JA_JP_5026.LOCALE
文字識別コードの制御は*DEVDとなっているので、使用するデバイスの文字IDの値となるこの値は、5250エミュレータのホスト・コード・ページによって決定される。
一次言語5026のデフォルトでの使用を前提としているので、5250エミュレータのホスト・コード・ページは日本語930(カタカナ)が指定されるとすると、デバイスの文字IDの値は1172 290となる。
5250エミュレータのホスト・コード・ページに、日本語939(拡張ローマ字)が指定された場合には、デバイスの文字IDの値は1172 1027となる。
このユーザー・プロファイルでサイン・オンしたジョブの属性を確認すると、図表6のようになる。

省略時のコード化文字セットIDは、ジョブのCCSIDに65535以外が指定されている場合は、ジョブのCCSIDとなる。ジョブのCCSIDが65535の場合には、ジョブの言語IDに基づいて設定される。言語IDがJPNの場合は、5026に設定される。
ジョブのCCSIDは、CHGJOBコマンドで変更できる。CCSIDの変更は、直ちにジョブに反映される。ジョブのデフォルトCCSIDは、変更できない。
データベースのフィールドには、数値フィールドを除いてCCSIDのサポートがある。ファイルを作成する際に、明示的にCCSIDを指定しなかった場合は、ジョブのデフォルトCCSIDを参照してフィールドのCCSIDが決定する。
ジョブのCCSIDが65535、デフォルトCCSIDが5026の環境でソース物理ファイルを作成すると、CCSIDはデフォルトでジョブのデフォルトCCSIDを参照するので、5026で作成される。
次に、このジョブで物理ファイルを作成する。物理ファイルのレコード・レベルやフィールド・レベルでCCSIDを指定しない場合、ジョブのデフォルトCCSIDが参照され、このCCSIDをもとにしてフィールドのCCSIDが決定される。
フィールド・タイプが文字列の場合、CCSIDには、ジョブのデフォルトCCSIDに対応するSBCSのCCSIDが割り当てられる。デフォルトCCSIDが5026 の場合は、対応するSBCSのCCSID 290となる。
DBCS混用、DBCS 専用、およびDBCS択一の場合は、混合バイトのCCSIDが割り当てられる。ジョブのデフォルトCCSIDが5026の場合は、5026で作成される。
フィールド・タイプがグラフィックスの場合には、ジョブのデフォルトCCSID 5026に対応するCCSID 4396が割り当てられる(図表6)。フィールドのCCSIDは、ファイル・フィールド記述表示(DSPFFD)コマンドで参照できる(図表7)。

データベースへのデータの読み書きの際は、ジョブのCCSIDとデータベースのCCSIDを参照して、データ変換が行われる。
データを読み込む際にジョブとデータベースのCCSIDが異なる場合は、ジョブCCSIDに変換される。データを書き込む際にジョブとデータベースのCCSIDが異なる場合は、データベースのCCSIDに変換される。
日本語2930を導入した場合
次に、日本語2930を導入した場合について確認する。
一次言語を2930で導入する場合の言語に関するシステム値のデフォルトは、図表8のようになる。
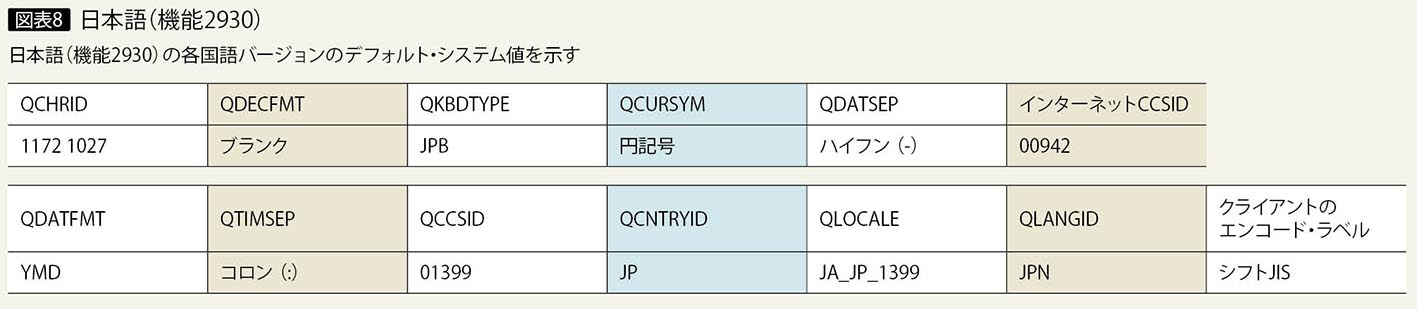
一次言語を日本語2962とした場合と同様に、システム値やユーザー・プロファイルの言語に関する指定をすべてデフォルトのままで構成する場合について考える。一次言語を日本語2930とした場合は、システム値QCCSIDは1399に設定される。
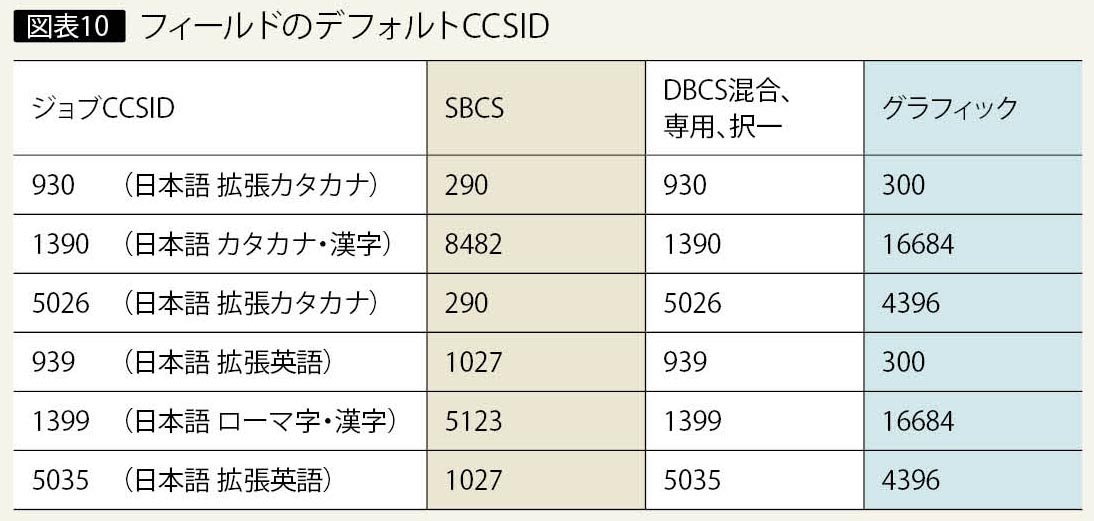
ユーザー・プロファイルでとくに設定しなければ、ジョブのCCSIDは1399になる。このジョブで物理ファイルを作成すると、レコードやフィールドのレベルでCCSIDを指定しない場合のフィールドのデフォルトCCSID は、以下のようになる(図表9)。

・SBCSフィールド:CCSID 5123
・DBCS混合、専用、択一フィールド:CCSID 1399
・DBCSグラフィック・フィールド:CCSID 16684
物理ファイルを作成したときのジョブのCCSIDと、フィールドのタイプごとのデフォルトCCSIDの関係は、図表10のようになる。
IBM i の日本語環境として導入されている言語は、日本語2962が主である。
日本語2962をデフォルトの環境(システム値QCCSIDを65535)のまま使用している場合は、ジョブのデフォルトCCSIDは 5026で使用されることになる。この環境でCCSIDの指定を行わずにファイルを作成すると、SBCSフィールドのCCSIDは290となる。
CCSID 290のコード・ページは290(日本語 拡張カタカナ)で、他の言語圏のコード・ページが英小文字のコード・ポイントとして割り当てている部分にカタカナを割り当て、英小文字は異なるコード・ポイントに割り当てられている。
そのため、英小文字とカタカナの文字化けが発生することになる。文字化けのほかにも、英大文字・小文字を区別するプログラムが動作しないといった問題が発生する。
日本語2962の環境であっても、システム値QCCSIDを5035あるいは1399で設定すれば、CCSIDを明示的に指定しないで作成されるファイルのSBCSフィールドはCCSID 1027、5123で作成されるので、英小文字のコード・ページは英語圏と同じコード・ポイントに割り当てられたものになる。
日本語の環境として2962の代わりに2930を導入すると、システム値QCCSIDは1399に設定されるので、ファイルのSBCSフィールドは、CCSID 5123で作成される。英小文字のコード・ポイントが他の英語圏と同じで、文字化けを起こさずに正しく扱えるので、Db2 Web Query for i やWebアプリケーションなどを実行する環境として、今後の日本語の言語環境としては、日本語2930を導入することが推奨される。
ファイルのコード・ページの変更
これまでの日本語2962のデフォルト環境で作成された、CCSID 290のフィールドを含むファイルをCCSID 1027や5123に変更する方法を説明する。
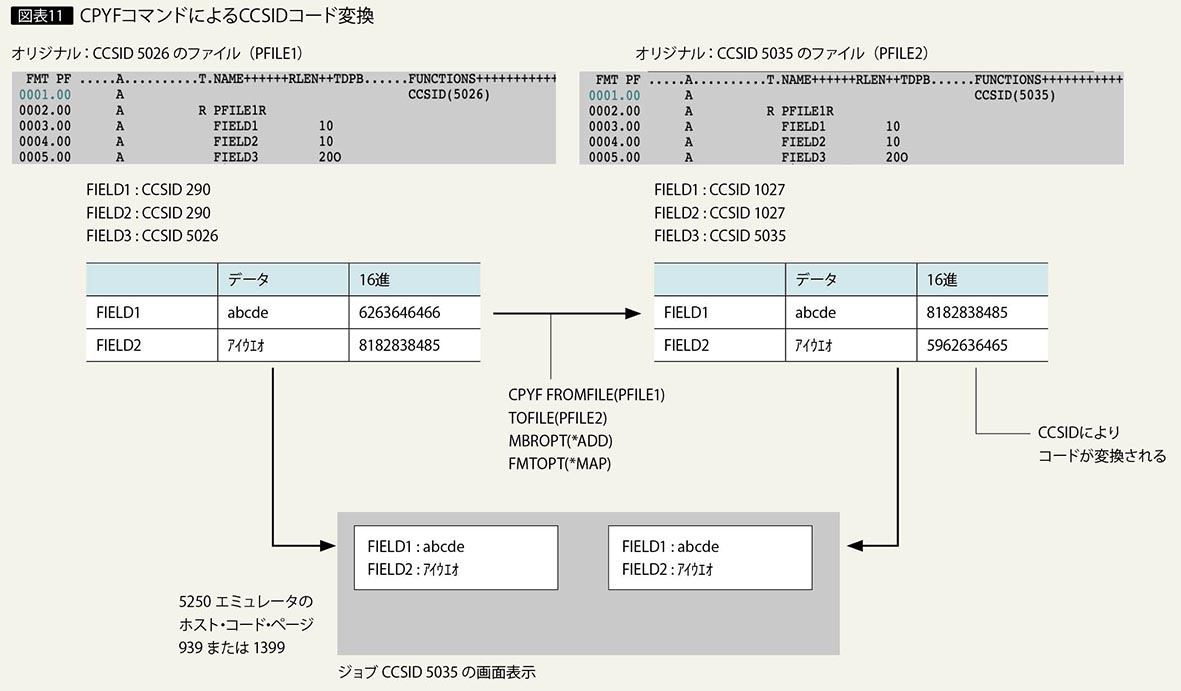
ファイル・コピー(CPYF)コマンドはCCSIDをサポートしており、コピー元とコピー先ファイルのフィールドの属性が同じで、CCSIDが異なる場合に、CCSIDによるコード変換が行われる。このコード変換の機能を使用することで、CCSID 290からCCSID 1027や5123のデータへ変更することが可能になる。
まずコピー元のCCSID 290のファイルと、同じレコード構造のファイルを作成する。フィールド名や属性は、コピー元ファイルとまったく同じ構成にする。コピー先のファイルは、フィールドのCCSIDを1027あるいは5123とするために、該当するフィールドにCCSIDキーワードを指定するか、レコード・レベルでCCSID 5035あるいは1399を指定する。
次にCPYFコマンドで、コピー元CCSID 290フィールドのファイルから、CCSID 1027、5123のフィールドのファイルへコピーを実行する。このとき、CPYFコマンドのレコード様式フィールドのマップ(FMTOPT)パラメータは*MAPを指定する。FMTOPT(*MAP)を指定すると、該当フィールドの間でCCSIDによるコード変換が行われる(図表11)。
なお、CPYFコマンドのFMTOPTパラメータに*NOCHKを指定して実行した場合には、CCSIDによるコード変換は実行されずに、同じコードのままでコピーが実行される。
CCSID 65535を指定した場合には、コードは無変換となる。変換したくないコードを含むフィールドに対しては、CCSID 65535を指定する。
短期連載
第1回 文字コードについて ~その歴史と役割
第2回 IBM iの日本語環境 ~EBCDIC編
第3回 IBM iの日本語環境 ~Unicode編(完結)
著者
三神 雅弘氏
日本アイ・ビー・エム株式会社
システム事業本部 サーバー・システム事業部
コグニティブ・システムズ事業統括
シニアITスペシャリスト
1989年、日本IBM入社。AS/ 400のテクニカル・サポートを担当。日本IBM システムズ・エンジニアリングへの出向を経て、2004年よりテックライン、2016年よりビジネス・パートナー向けテクニカル・サポート、2018年よりIBM iブランド業務を兼任している。

[i Magazine 2020 Autumn(2020年10月)掲載]