IBM iでのUnicodeのサポート
IBM i はEBCDICを基本とするシステムであるが、Unicodeデータもサポートしている。データベースに対してUnicodeのCCSIDを指定することで、Unicodeデータを扱えるようになる。また、EBCDICとUnicodeの間のデータ変換もサポートしている。ここではその方法を解説しよう。
Unicodeエンコード方式のUTF-8にはCCSID 1208、UTF-16にはCCSID 1200を指定する。また、USC-2にはCCSID 13488を指定する。システムでは、CCSID 1200とCCSID 13488の両方を、UTF-16エンコードとして処理する。
IBM iのUnicodeサポートでは、バイト・オーダーはビッグ・エンディアンのみに対応している(図表12)。
なお、以下のCCSIDに対してはUnicodeを指定できない。
・システム値QCCSID
・ユーザー・プロファイルのCCSID
・ジョブのCCSID
IBM i V5R3以降、データベースでUnicodeのCCSIDがサポートされている。UnicodeのCCSIDは、データ・タイプがSBCS文字フィールド(A)とグラフィック(G)のフィールドに対してサポートされる。
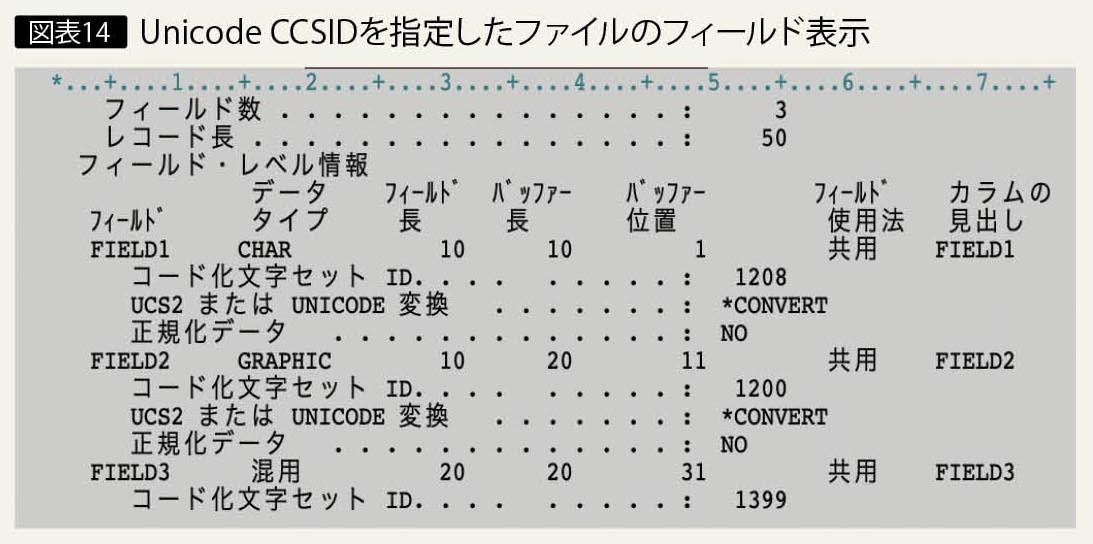
SBCS文字フィールドに対しては、UTF-8のCCSID 1208を指定する。グラフィック・フィールドに対しては、UTF-16のCCSID 1200あるいはUCS-2のCCSID 13488を指定できる。図表13に、物理ファイルのフィールドに対してUnicodeのCCSIDを指定した例を示す。

図表14は、CCSID 1208、1200を指定したファイルを、ファイル・フィールド記述表示(DSPFFD)コマンドで参照した画面である。
論理ファイルでUnicode CCSIDを指定する場合は、SBCS文字フィールド(A)に対しては、UTF-8のCCSID 1208を指定する。グラフィック・フィールド(G)に対しては、UTF-16のCCSID
1200あるいはUCS-2のCCSID 13488を指定できる。対応する物理ファイルのフィールド・タイプは、文字(A)、グラフィック(G)またはDBCS混合(O)であることが必要である。
物理ファイルと論理ファイルの該当するフィールドの間でCCSIDが異なる場合には、データ変換が実行される。CCSIDによるコード変換は、EBCDICとUnicodeの間でも実行される。
図表13の物理ファイルを参照する論理ファイルは、図表15のように作成する。ここでは論理ファイルのフィールドFIELD2は、CCSID 1208のUTF-8が指定されている。物理ファイルの該当するフィールドFIELD2は、CCSID 1200のUTF-16で作成されているので、UTF-16とUTF-8の間でデータ変換が行われる。

論理ファイルのフィールドFIELD3は、CCSID 1200のUTF-16が指定されている。物理ファイルの該当するFIELD3はCCSID 1399で作成されているので、EBCDIC 1399とUTF-16との間でデータ変換が行われる。
SQLでのUnicode
SQLでテーブルを作成する場合は、カラムに対してUnicodeのCCSIDを指定できる。GRAPHICおよびVARGRAPHICのデータ・タイプのカラムに対しては、UTF-16の1200あるいはUCS2の13488をCCSIDで指定することで、Unicode対応のカラムとなる。
CHARおよびVARCHARのデータ・タイプのカラムに対しては、UTF-8の1208をCCSIDで指定することで、Unicode対応のカラムとなる。
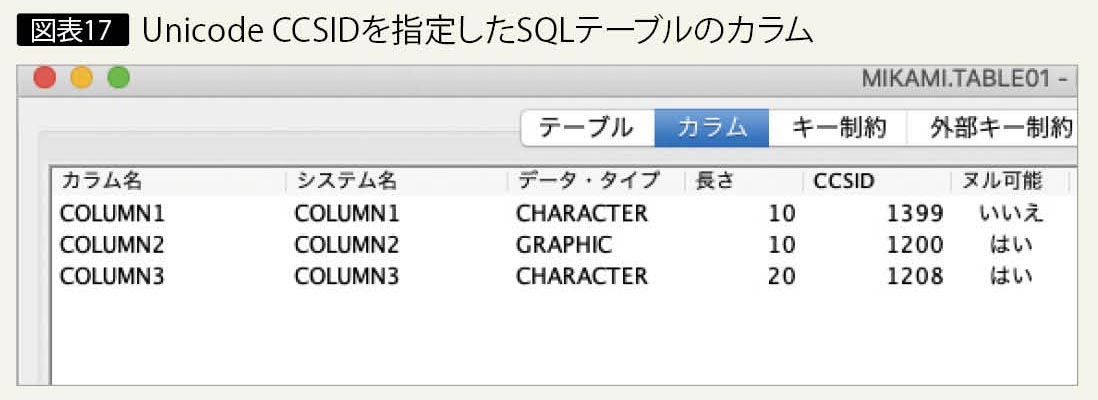
次に、Unicodeに対応したSQLテーブルの作成例を示す(図表16)。

COLUMN2はCCSID 1200でUTF-16、COLUMN3は CCSID 1208でUTF-8が指定される(図表17)。
表示装置ファイルのUnicodeサポート
表示装置ファイルのフィールドは、Unicodeをサポートする。レコード・レベルまたはフィールド・レベルでCCSIDキーワードを使用して、UnicodeのCCSIDを指定する。
表示装置ファイルでサポートされるUnicodeのエンコードは、UTF-16またはUCSである。Unicode CCSIDが指定できるのは、グラフィック(G)タイプのフィールドである。
図表18に、表示装置ファイルのフィールドに対してUnicodeのCCSIDを指定した例を示す。この例では、グラフィック・フィールドFLD2Dに対して、UTF-16のCCSIDを指定している。

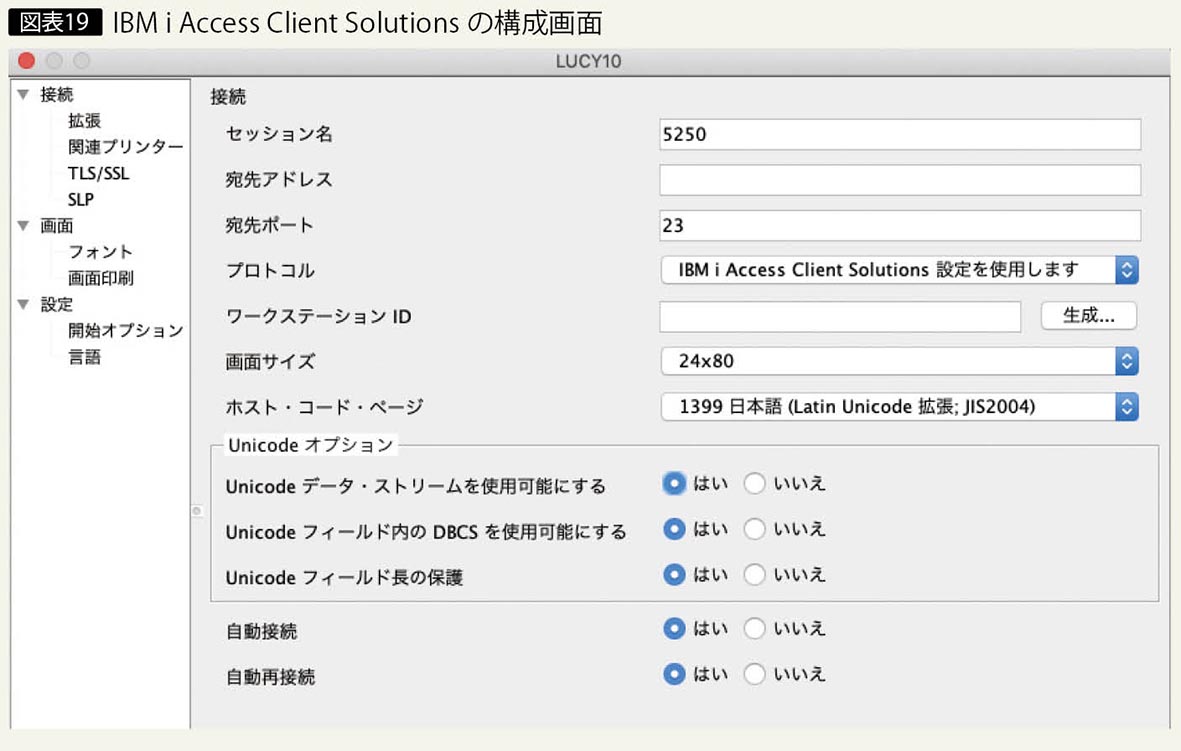
5250エミュレータは、IBM i Access Client Solutions (以下、ACS)で、Unicodeがサポートされている。ACSの構成画面のUnicodeオプションにより設定する(図表19)。
Unicodeを使用したアプリケーション
Unicodeを使用するメリット
ここまで、IBM i のUnicode対応について見てきた。Unicodeデータベースを使用することは、複数言語環境に対応するアプリケーションやWebアプリケーションでの利用時にメリットが得られる。
複数言語に対応するためのアプリケーションを用意する場合には、各国語の文字データを正しく扱うために、それぞれの言語に合わせたファイルあるいはフィールドを用意する必要があった。
このようなアプリケーション環境では、同じ目的のデータが各国語ごとに別々に処理されることになる。Unicodeフィールドにすることで、各国の言語の文字に対して固有の文字コードがサポートされるので、1つのフィールドに各国語のデータを含めることが可能になる。
またWebアプリケーションでは、Unicodeデータを扱うのが普通である。EBCDICのデータベースをWebアプリケーションで使用する場合は、JDBCドライバでコード変換する必要がある。Unicodeのデータベースを用意すれば、Webアプリケーションからデータベースへアクセスする際に、コード変換の必要はなくなる。
EBCDICを使用するアプリケーション
既存の5250アプリケーションを複数言語に対応するアプリケーションに変更したり、Webアプリケーションを追加したりする場合を考えてみよう。
5250アプリケーションの利用が大半で、既存のプログラムを変更したくない場合は、EBCDICファイルにデータを保管し、Unicode用の論理ファイルを作成する方法が考えられる(図表20)。
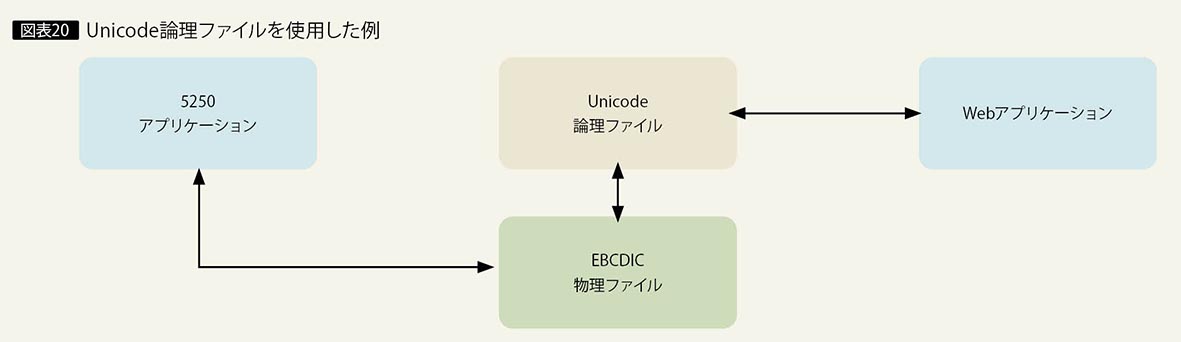
EBCDICのデータは、論理ファイルによってUnicodeデータへ変換され、Unicode用のWebアプリケーションからアクセスすることが可能になる。ただし、EBCDICはUnicodeより扱う文字コードが少ないため、EBCDICファイルに保管される際に文字が失われる可能性がある。
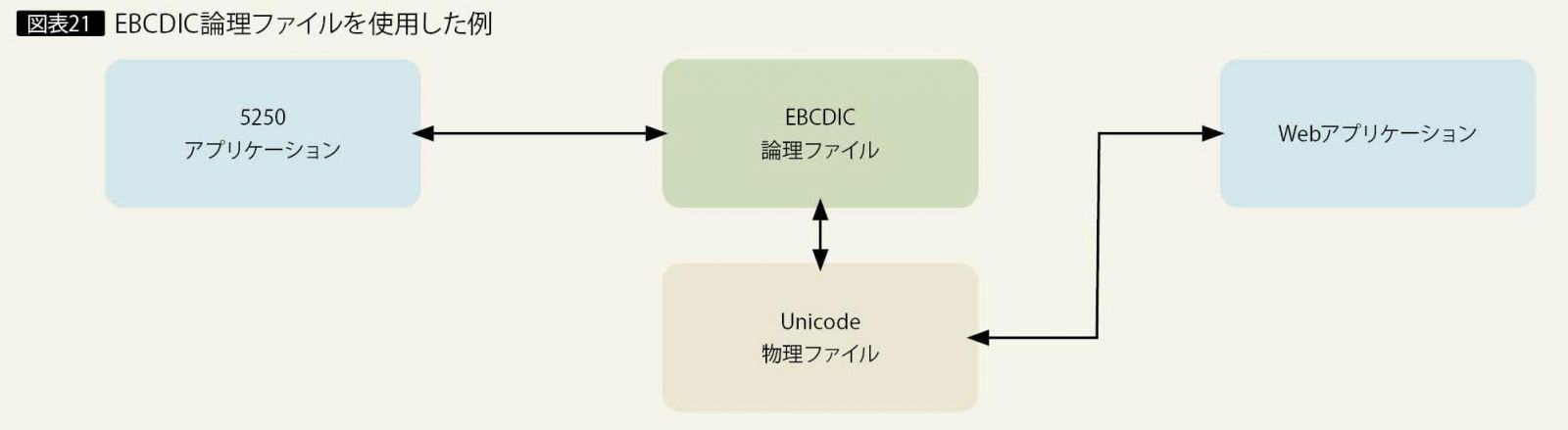
一方、Unicodeアプリケーションの利用が大半である場合は、Unicodeファイルにデータを保管し、5250アプリケーション向けにEBCDIC用の論理ファイルを作成する方法が考えられる(図表21)。Unicodeデータは、論理ファイルによってEBCDICへ変換され、EBCDIC用の5250アプリケーションからアクセスすることが可能になる。
短期連載
第1回 文字コードについて ~その歴史と役割
第2回 IBM iの日本語環境 ~EBCDIC編
第3回 IBM iの日本語環境 ~Unicode編(完結)
著者
三神 雅弘氏
日本アイ・ビー・エム株式会社
システム事業本部 サーバー・システム事業部
コグニティブ・システムズ事業統括
シニアITスペシャリスト
1989年、日本IBM入社。AS/ 400のテクニカル・サポートを担当。日本IBM システムズ・エンジニアリングへの出向を経て、2004年よりテックライン、2016年よりビジネス・パートナー向けテクニカル・サポート、2018年よりIBM iブランド業務を兼任している。

[i Magazine 2020 Autumn(2020年10月)掲載]