Text= 勝木 孝行(日本IBM)
最新のIBM時系列モデルは、点予測および確率的予測においてクラス最高水準の予測性能を持ち、その効率性でもトップに位置している。
時系列データはさまざまな形態を取り、応用の可能性も多岐にわたる。そのため、いかなる単一の予測手法も、常に最良の結果をもたらすわけではない。
翌日の最高気温・最低気温を予測したい場合や、ある企業が来週の売上目標を達成できるかどうかを予測したい場合には、点予測が有力な選択肢となる。
一方、製品をいつ補充すべきかを判断したい場合や、企業のリスクエクスポージャーを評価したい場合には、確率的予測のほうが有用なこともある。また別の場面では、ネットワークの障害や機械の故障を防ぐために、リアルタイムなデータストリームから異常を検知しようとすることもあり、その場合は計算速度が重要となる。
IBM Researchは、これらの各シナリオで力を発揮する時系列基盤モデルのポートフォリオを構築した。公開されたこれらのモデルは、現在Hugging Face上の時系列予測の公開ベンチマークであるGIFT-Evalリーダーボードで上位に立っている。
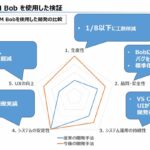
FlowState-r1.1は、非エージェント型・ゼロショット・再現可能で、データリークのないモデルの中で点予測性能(MASE:平均絶対スケール誤差)が首位(執筆時)、PatchTST-FM-r1は同条件で確率的予測が首位(執筆時)の性能を持つ(CRPS:連続値ランク確率スコア)(図表1)。
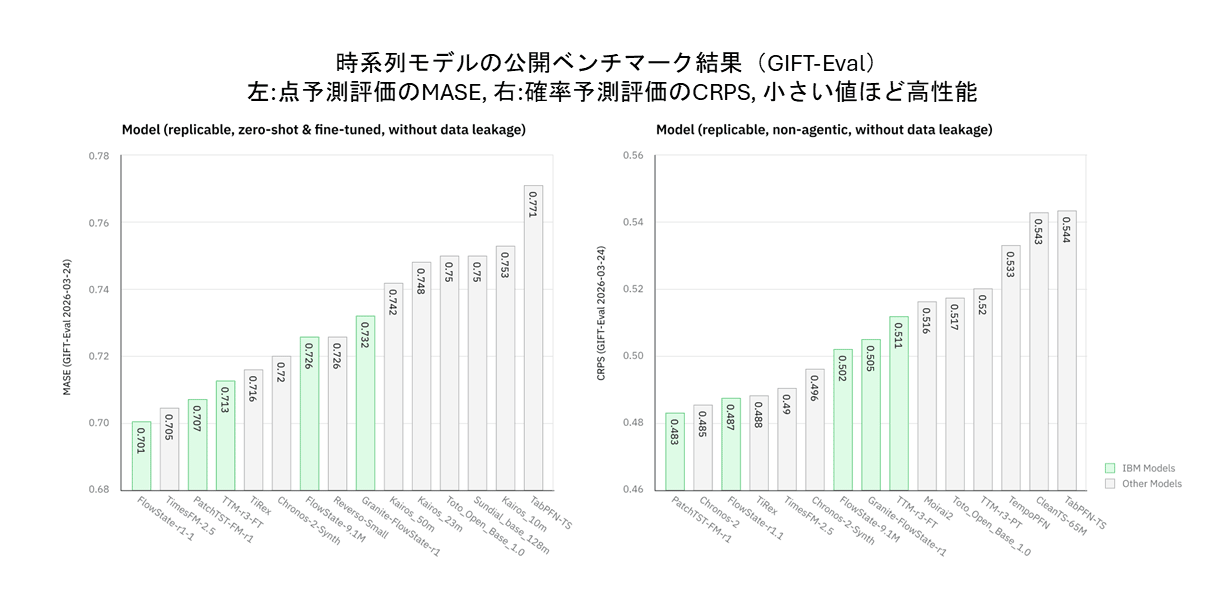
また、効率的な予測・異常検知・分類・検索向けのTTM-r3およびTSPulse-r1は毎秒数千件の推論に対応する。
これらのモデルは、それぞれ固有の強みを持つ異なるアーキテクチャ上に構築されている。本稿では、何が新しいのか、各モデルがどのような種類のタスクに最適なのか、そしてどのようにアクセスして利用できるのかを解説する。
IBMは3つのモデルを発表し
時系列モデルのポートフォリオを拡張
IBMの最新のTransformerベースモデルであるPatchTST-FM-r1は、Rensselaer Polytechnic Institute(レンセラー工科大学、略称RPI)との共同開発によるもので、より高精度かつ効率的な予測のためにチャネル独立性とパッチングを導入した画期的なPatchTSTアーキテクチャを発展させたものである。
PatchTST-FM-r1 モデルは、128から8192 タイムポイントまでのコンテキスト長を柔軟に扱うことができ、短期および長期の双方にわたる予測を可能にし、欠損値に対しても頑健である。
現在のGIFT-Evalでの順位は、実データと合成データから成る大規模データセットで学習した場合、Transformerアーキテクチャが柔軟かつ表現力に富み、高い予測性能で機能することを示している。
TTM-r3は、速度と予測性能のバランスを取るよう設計されたTinyTimeMixer モデルの第3世代である。
同リリースでは、予測性能を向上させるとともに、今日の最先端モデルと比べて推論を15~50倍高速化する複数の革新的な機構が導入されている。またTTM-r3はCPUのみの環境でも高い計算速度を発揮するため、実世界の高スループットな応用に適している。
TTM-r3は高速なファインチューニング、複数変数を用いた予測に対応し、さらには制御変数を取り込むこともでき、複雑な産業応用において高い実用性を持つ。IBMのTTMモデルは、Hugging Faceでこれまでに3700万回を超えるダウンロードを記録している。
FlowState-r1.1は、IBMのFlowStateモデルの最新版であり、S5と呼ばれる新規の状態空間アーキテクチャの上に構築されている。S5は、短い入力長と長い入力長、短期および長期の予測期間、さらには多様なサンプリングレートを扱える。
状態空間モデルのエンコーダと関数基底デコーダを組み合わせることで、FlowState-r1.1は、サンプリングレートの異なるデータを調和させて高精度な長期予測を生成する能力を備えている。この新バージョンでは、追加の合成学習データを取り込み、入力長を拡張することで、性能をさらに向上させている。
これら3つのモデルのリリースは、IBMの時系列モデルのポートフォリオを拡張するとともに、TSPulseを補完するものである。TSPulseは、時系列異常検知・検索・分類・補完の各タスクに優れた、軽量な時系列埋め込みの基盤モデルである。
エンタープライズ展開に向けた設計
これらのモデルは、実世界のエンタープライズ要件の広範な領域をカバーする。応用先として、製造業における予測や監視、ITインシデントや電力グリッドの障害の検知などが含まれる。これらのモデルは、公開ドメインから取得した、あるいは合成生成された1000億を超えるデータ点で学習されている。
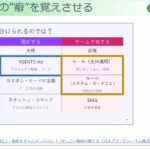
図表2は、各モデルの主要な強みを応用先別に示したものである。
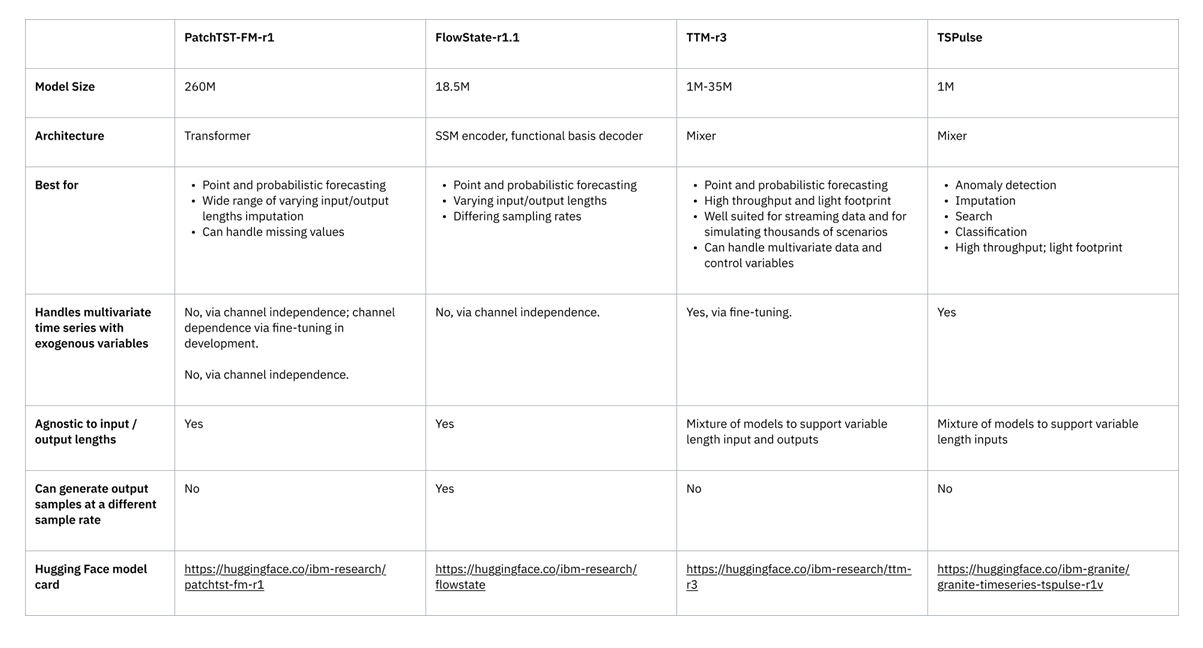
CPUマシンでの高スループットと低レイテンシを求めるならTTM-r3を、高精度な点予測および確率的予測を求めるならそれぞれFlowState-r1.1とPatchTST-FM-r1を、そして時系列の異常検知・分類やその他の非予測タスクにはTSPulseを試してほしい。
ここに至るまでの経緯
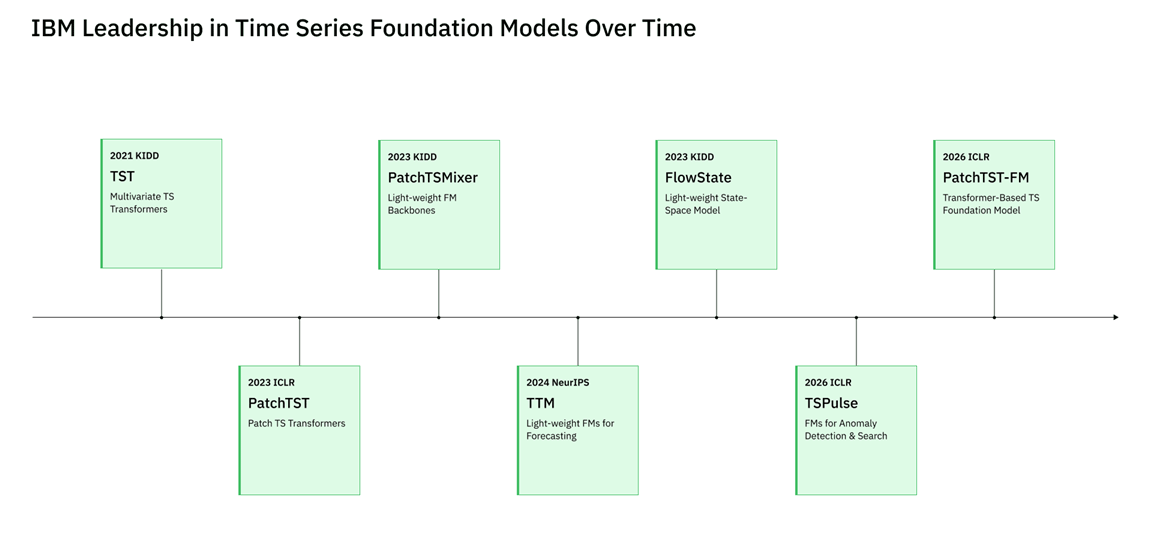
IBMは、時系列データに適用された最初期のTransformerベースモデルの1つであるTSTを2021年に公開して以来、時系列基盤モデルの研究開発をリードしてきた。
2023年には、PatchTSTがパッチングとチャネル独立性の概念を時系列データに導入し、Transformerが長い時系列を効率的かつ効果的に処理することに成功した。
同じく2023年には、TSMixerが、パッチ情報とチャネル横断的な情報を統合するために多層パーセプトロンを用いることで、さらなる速度と効率への道を切り拓いた。
これらのMixerを基盤として、2024年に公開されたTinyTimeMixer(TTM)は、多くの領域・タスクに対応する初の軽量時系列モデルを世に送り出した。
2025年には、状態空間モデル(SSM)を基盤として、FlowState時系列モデルを発表した。その革新部分には、並列学習、関数基底デコーディング、サンプリングレート不変性が含まれていた。
TTMとFlowStateの旧バージョンは、2024年と2025年のGIFT-Evalの予測ベンチマークにおいて首位の性能を示した。
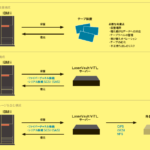
今年、IBMはPatchTST-FM-r1、TTM-r3、FlowState-r1.1 のリリースをもって、ポートフォリオを完成させた(図表3)。これらは、GIFT-Evalの予測タスクにおいて再び首位の性能を示している。さらに、異常検知と分類に特化したTSPulseがこれらを補完する。これらのモデルは、全体として、実世界の広いユースケースをカバーする。
IBMの時系列モデルを試す
IBMのすべての時系列モデルはオープンソースであり、Hugging Faceからダウンロードできる。
◎研究版(research versions)は、非商用ライセンスの下で提供されている。
◎Granite 時系列モデルに含まれるモデル群は、厳選されたデータセットで学習されており、Apache 2.0ライセンスの下で提供されている。
ユーザーがIBMの時系列モデルを使い始める際に役立つ、いくつかのノートブックも用意されている。これらのノートブックは、各モデルの能力と最適なユースケースを示しており、当社のオープンソースリポジトリにあるモデルアーキテクチャおよび補助コードの上に構築されている。
FlowState
TTM
PatchTST-FM
TSPulse-異常検知および分類

*本記事は筆者個人の見解であり、日本IBMの立場、戦略、意見を代表するものではありません。
当サイトでは、TEC-Jメンバーによる技術解説・コラムなどを掲載しています。
TEC-J技術記事:https://www.imagazine.co.jp/tec-j/
![]()
[i Magazine・IS magazine]