Text=堤 富登、北爪 裕紀、濱田 敬弘 (日本IBM)
前回の記事ではデータウェアハウスやデータレイク、Hadoopのようなデータ管理技術の進化と、データレイクハウスの必要性およびそのメリットを紹介した。また、watsonx.dataが準構造化ファイルをクエリーできることによるデータ利活用の可能性を、デモを通じてご覧いただいた。
今回はwatsonx.dataの“イイね”のポイントの2回目として、データとAIのための統合プラットフォームである「Cloud Pak for Data」(以下、CP4D)との連携により、準構造化ファイルにデータの意味付けを行い、CP4Dのデータセマンティックレイヤーがビジネスとシステムの架け橋となることをお伝えしたい。
今回のアジェンダは、以下のとおり。
-CP4Dのデータセマンティックレイヤーとは
-IBM Knowledge Catalogの役割
-watsonx.dataとCP4Dの連携の利点
-デモ動画の紹介
-まとめ
CP4Dのデータセマンティックレイヤーとは
セマンティックレイヤーとは、データの意味づけをすることでデータ提供者側とデータ利用者の間に入り、両者のやり取りを円滑にするデータの論理層としての存在である。
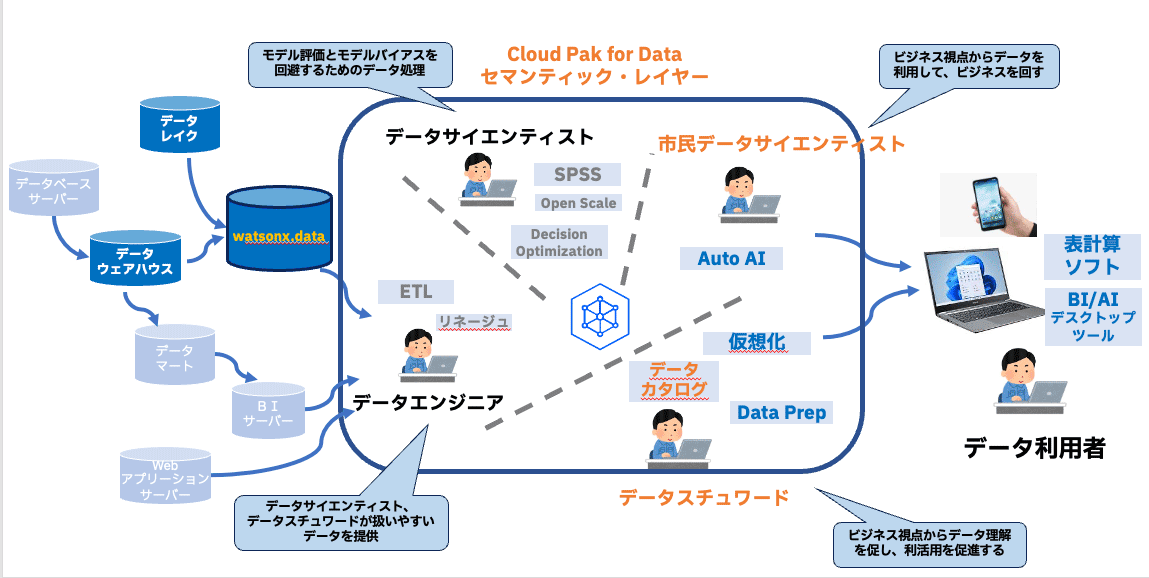
ユーザーとデータの間に立ち、統一された定義を元にデータを活用できる。
近年ではAI普及によるデータ重要性の向上やSaaSツールの台頭により、増大し、かつ分散したデータソースを効率的に利活用するために、「データの意味づけがどうあるべきか」に関心が集まっている。
冒頭で触れたCP4Dは、データとAIのための統合プラットフォームであり、そのコンポーネントの1つであるIBM Knowledge Catalogはデータの意味づけを提供する。
IBM Knowledge Catalogの役割
前稿にてデータレイクが普及してきたことを述べた。これによりガバナンス問題を提起するケースがかなり多い。
この問題としては、データ検索・アクセス・データ品質の担保、システム用語が理解しにくくデータ利用者の生産性が下がることなどが挙げられる。それを解決するための1つの概念として、「データカタログ」が存在する。データカタログを取り入れることで、保有しているデータがどのようなものか簡単に理解できるようになる。
たとえば、データに対してビジネス用語の“タグ付け”をすることで、データ利用者が直感的に理解できる。このようにデータカタログを利用することでデータガバナンスを担保し、ビジネスに大きなメリットを与える。
watsonx.dataとCP4Dの連携の利点
watsonx.dataとCP4Dを連携することで、以下のようなメリットが得られる。
・IBM Knowledge Catalogとの連携でアクセス制御やビジネス用語化、タグ付け、データの隠蔽(マスキング)ができる。
・構造化データだけではなく準構造化データに対しても意味付けができ、データ利用者が簡単にデータを活用できるようになる。
watsonx.dataとCP4Dの連携は、企業でのデータの民主化を大きく発展させる。つまり、誰もが信頼性を保ったデータを自由に利用できるようになり、データドリブンな意思決定を行える。その結果、データ利用者にとっての生産性向上が加速し、ビジネスイノベーションを起こす。
デモ動画の紹介
watsonx.dataとCloud Pak for Data/IBM Knowledge Catalogの実際の連携をデモ動画で紹介する。
データカタログでビジネス用語を定義することで、従来データカタログ化が手つかずになっていた準構造化データに対してデータ利用者が直感的かつ効率的に発見、活用することが可能になる。
・デモ動画
「watsonx.dataデモ:CP4D連携でビジネスユーザーに付加価値を(データカタログ/マスキング)」 (16分)
まとめ
セマンティックレイヤー、データカタログ、そしてwatsonx.dataとCP4Dの連携がもたらすメリットを述べてきた。データを民主化することによって誰もがデータを利用し、新しい価値創造が可能になるだろう。
次回はデータ利用者からの視点にフォーカスして、watsonx.dataを通じて取得した準構造化データを、構造化データと変わらない使い勝手で分析アプリケーションで利用できる様子を説明する。
◎セミナー動画アーカイブでもwatsonx.dataご紹介をご覧になれます。
「IBMのレイクハウスwatsonx.dataデモ連発」登壇者:堤富登
30分のクイックなセミナー。アーカイブ動画のため、好みの倍速で参照可能。



*本記事は筆者個人の見解であり、IBMおよびキンドリルジャパン、キンドリルジャパン ・テクノロジーサービスの立場、戦略、意見を代表するものではありません。
当サイトでは、TEC-Jメンバーによる技術解説・コラムなどを掲載しています。
TEC-J技術記事:https://www.imagazine.co.jp/tec-j/
![]()
[i Magazine・IS magazine]