Text=小島 泰一、増田 健(日本アイ・ビー・エム システムズ・エンジニアリング)
近年のIT基盤の変化に伴うIT運用業務への影響と運用課題の改善案として、AIを活用した運用の高度化(AIOps:Artificial Intelligence for IT Operations、またはAlgorithmic IT Operations) について、「AIOpsによる運用高度化の実現 ~Watson AIOpsが実装する運用管理機能の概要」で紹介した。
本稿では既存の運用監視システムに対して、影響をできるだけ少なくしつつAIOps製品の1つである「IBM Cloud Pak for AIOps」(以下、CP4AIOps)を利用して、運用を高度化する方法について紹介したい。
現行システムに対する運用高度化へのアプローチ
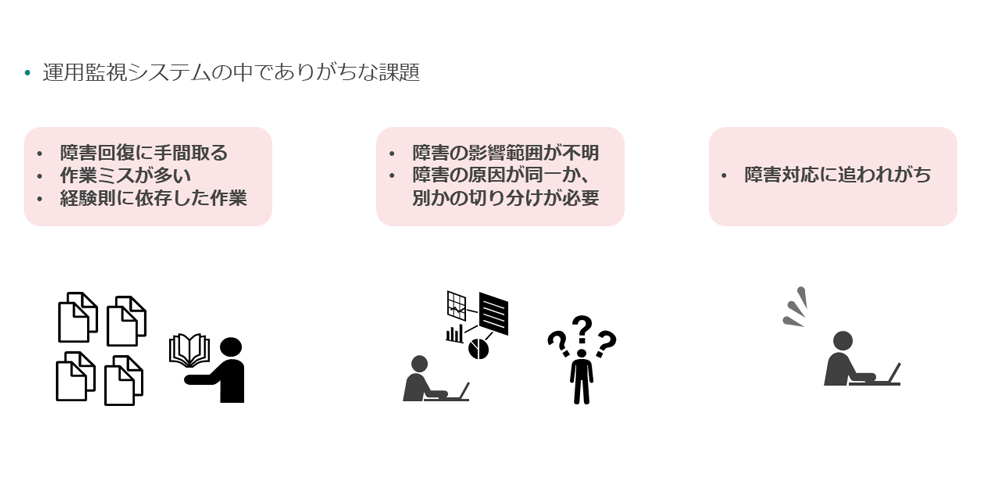
まず、多くのシステム運用部門で聞かれる既存の運用監視システムでの課題を、以下にまとめた(図表1)。
・障害対応が人手のために対応品質にバラツキがある
障害回復に時間を要する。作業ミスが発生する。手順書はあるが、経験値により作業時間に開きがある。
・障害の影響範囲と障害発生原因が同一か否かの判定に時間を要する
障害の検知はできるが、影響範囲(障害が発生したサーバーだけか、他のサーバーにも影響があるか)や、障害が複数発生した場合、その原因が同一であるか否かの判定に時間がかかる。
・事前に障害の発生要素となりうる要因への対応が間に合わない
障害対応に追われがちで、事前にプロアクティブに障害を防ぐ対応にまで手が届かない。
このように監視システムによる障害検知や対応手順は整備されているが、対応手順の実施や影響分析に時間がかかり、事前に障害を回避する方策が十分にできていない、などの課題が挙げられる。
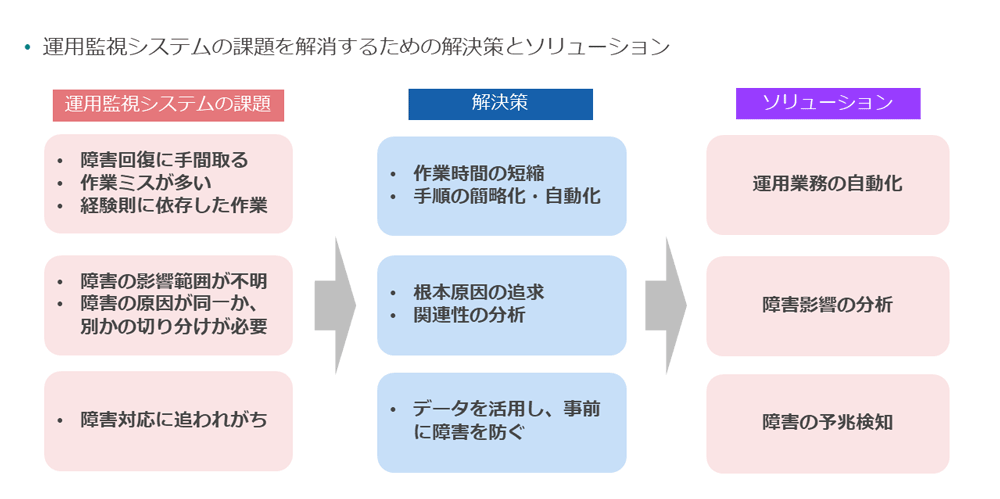
これらの課題に対して解決策を検討し、ソリューションとして以下の3つに整理した(図表2)。
課題: 障害対応が人手のために対応品質にバラツキがある
解決策:手順の簡略化や自動化を行い、作業時間を短縮する
ソリューション:運用業務の自動化
課題:障害の影響範囲と障害発生原因が同一か否かの判定に時間を要する
解決策:複数の障害の関連性や影響を与える業務を分析する、障害の根本原因を追及する
ソリューション:障害影響の分析
課題:事前に障害の発生要素となりそうな要因への対応が間に合わない
解決策:データを活用し、事前に障害を防ぐ
ソリューション:障害の予兆検知
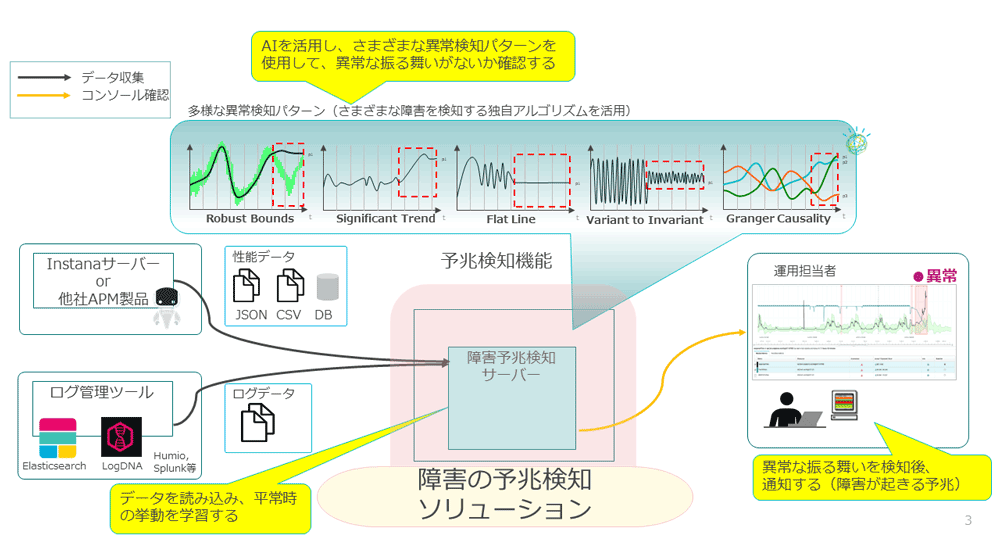
AIOpsは、人工知能(AI)と運用(Ops)を組み合わせたものである。機械学習(ML)、分析、データサイエンスを活用することにより、IT業務で発生したさまざまなデータを元にIT運用の自動化や効率化を図ることを目的とする。
この中で障害の予兆検知は、過去の性能データやログデータを学習材料とし、分析・活用することで障害発生につながる状況(CP4AIOpsでは、この異常な振る舞いを「アノマリー」と表現する)を把握するための仕組みであり、AIOpsを利用したソリューションの1つである。
今後、予兆検知は発展が見込まれる分野であり、既存の性能監視とも馴染みやすい機能であるため、本稿でAIOps実装への取り組みとして紹介する。
従来の固定の閾値監視は、特定の値(閾値)を設定し、メトリックが閾値を超過した(あるいは下回った)時に障害として通知する。しかし、これでは対応できない異常ケースがある。
たとえば、月、曜日、時間帯によりパフォーマンスデータに変動が発生するにも関わらず、特定の閾値で監視していると、周期的に発生するパターンと異なる事象が発生してもエラーは通知されない。そのため、本来あるべきパフォーマンスでシステムが稼働しているのかどうかを判断できない。
予兆検知では、APM(アプリケーションパフォーマンス管理)製品やログ管理ツールなどから、性能データやログデータを学習データとして周期的に発生するパフォーマンスのパターンを分析し、平常時の挙動を学習する。
学習以降に読み込まれたデータに対して、現在のパフォーマンス状態がこのパターンに合っているかどうかを判断する。パターンに対しては、その変化に応じた閾値(動的閾値)が設定され、この閾値から外れている場合には、通常と異なる「異常な振る舞い」として検知し、障害が発生する予兆としてアラートを通知する(図表3)。
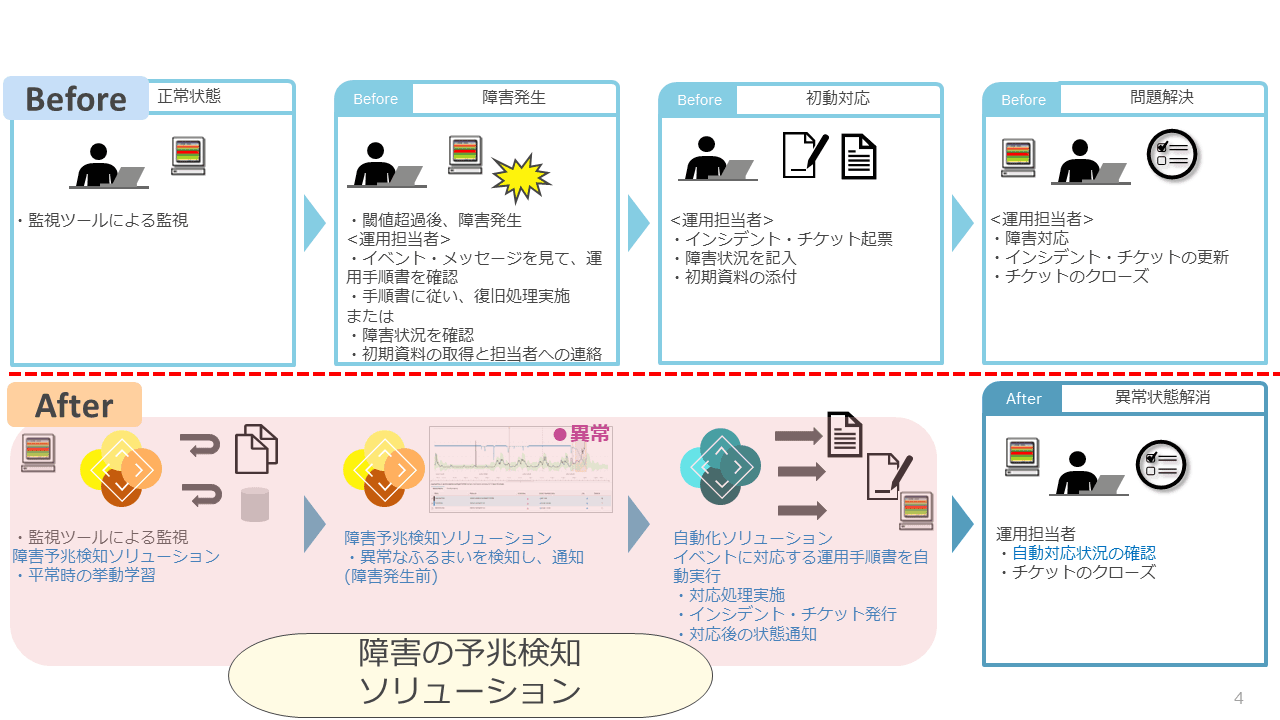
このような障害予兆検知を行うことで、運用担当者は障害発生前に異常状態を把握・対応できる。その結果、システム利用者への影響を回避し、運用担当者に発生する作業負担を軽減することにつながる。
たとえば障害予兆検知の適用前には、運用担当者は障害発生後に以下の作業が必要であった。
障害内容の確認
手順書に基づいた復旧作業の実施
障害発生元システム担当者への連絡
インシデント・チケット起票
サポートへの問い合わせ(必要に応じて)
これが、障害予兆検知の導入後は自動的に障害の予兆を検知し、障害発生前に対応できる。さらに自動化ソリューションを組み合わせると、予兆検知後の自動対応も可能になる。運用担当者は、対応状況の確認とチケットのクローズだけを実行すればよい(図表4)。
既存システムへの適用例-Zabbixのケース―
ここからは、運用されている既存の監視システムに対して、CP4AIOpsを利用してどのように運用高度化を実現するかを紹介する。
今回は、既存の監視システムの例としてZabbixを取り上げる。Zabbixは、Zabbix社がオープンソースソフトウェア(OSS)として提供している統合監視ソフトウェアである。サーバー、ネットワーク、アプリケーションを一元的に監視できるので、システム監視に利用している企業も多い。
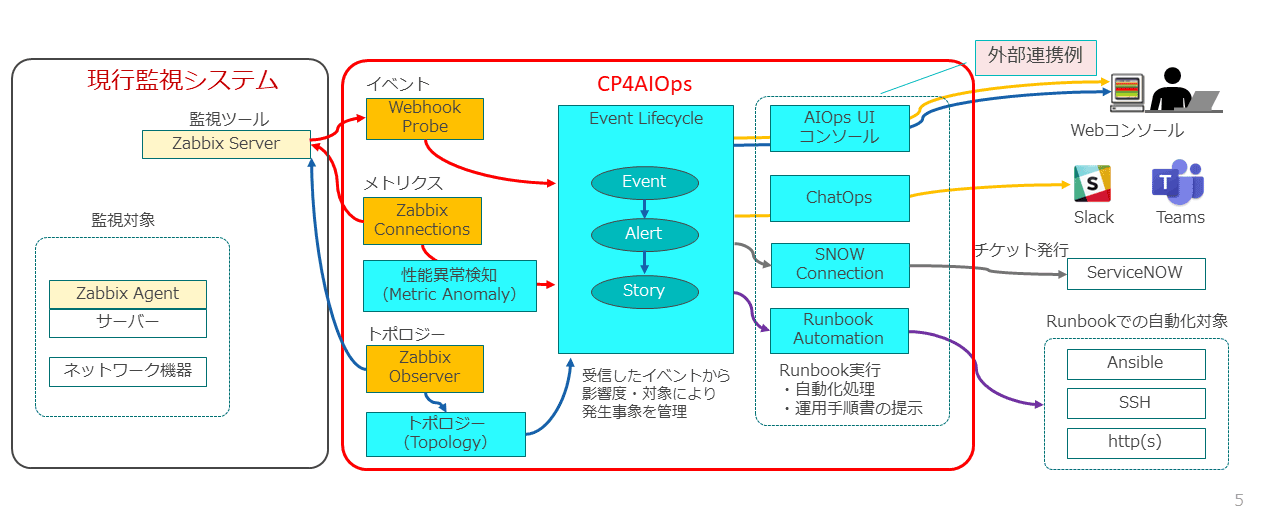
CP4AIOpsは、Zabbixと連携するために以下の機能を提供している(図表5)。
◎イベント連携
Zabbixで検知した障害をWebhookイベントとして受信
◎メトリクス連携
Zabbixが収集した性能データをメトリクスとして取得
◎トポロジー連携
Zabbixのサーバー・エージェント情報をトポロジーとして収集
これらの機能を利用してイベント、メトリクス、トポロジー情報をCP4QIOps内へ収集し、AIによる分析やイベントのグルーピング、メトリクスの異常検知を実行できる。また検知したイベントは、外部連携機能によりSlack、Teams、ServiceNowなどと連携できる。
CP4AIOpsで予兆検知を行う場合は、提供されているメトリクス連携機能を利用する。ここで予兆検知に必要な設定について解説する。
メトリクス取得を行うため、ZabbixとCP4AIOpsに対して以下のように設定する。
・ZabbixとCP4AIOps間の通信経路の確保
・Zabbixサーバー側の作業
APIキーの発行
・CP4AIOps側の作業
Zabbix Connectionの設定
図表5のように、Zabbix APIを利用してCP4AIOps側からメトリックを取得するため、Zabbix上の既存の監視設定に対する変更は発生しない。
Zabbixでは、複数のメトリックがテンプレート(=グループ)にまとまっている(図表6)。
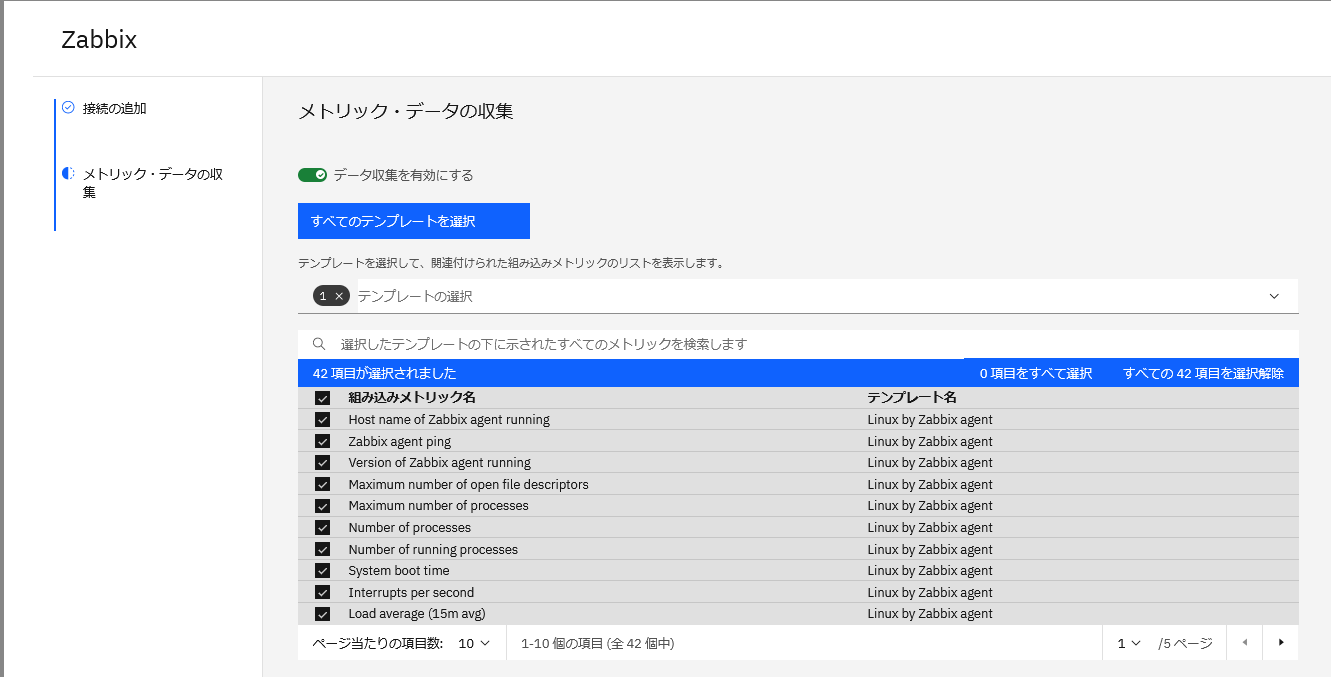
メトリック・データ収集の際は、Zabbix Connectionの設定で、このテンプレートを指定できる。ただしテンプレートでは通常監視に使用していないメトリックも多く含まれているため、すべてのメトリック・データを取得すると過剰なアラートが発生する。
そのため、たとえばトリガー(障害検知のための閾値)が設定されている項目の値を取得するなどの絞り込みが必要である。これにより、Zabbixでの推奨(標準)と同じものが参照可能で、通常の閾値監視対象をアノマリー検知の対象とすることで、既存環境では監視できていなかった変化・異常を検知することが可能である。
メトリック・データ収集を開始すると、CP4AIOpsは平時の挙動時の値としてパターン学習を行う。パターン学習の終了後に連携されたメトリック・データに対して、異常がどうかを判定する。予兆検知の結果、挙動が異常と判定された場合は、アラートとして通知する(図表7)。
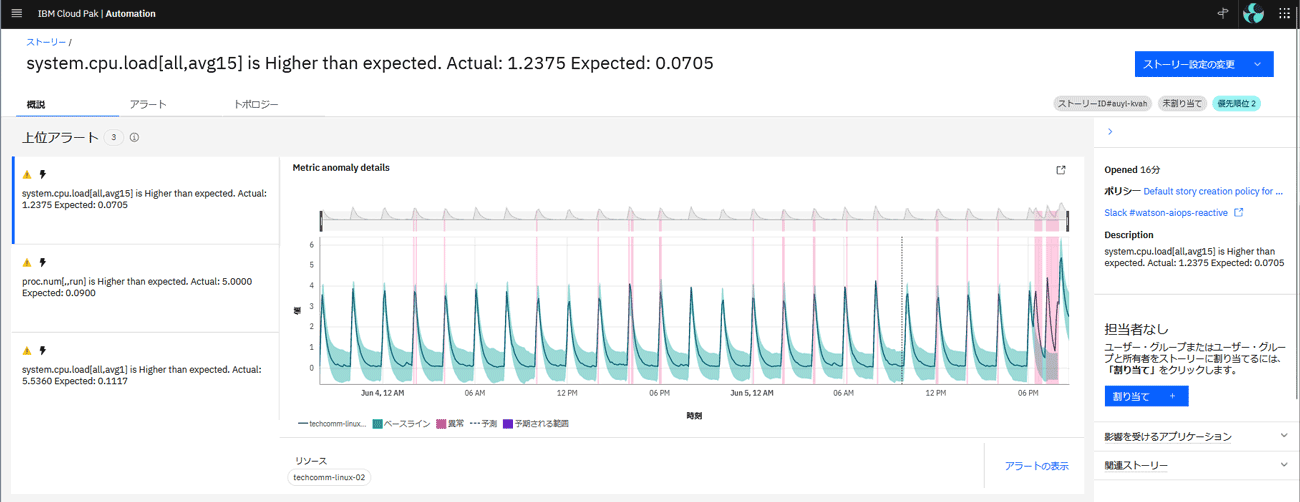
さらに発生したアラートは、イベントやトポロジー・データを組み合わせ、関連する障害としてグループ化して表示することも可能になる。
以上、既存の運用監視システム(Zabbix)に対して、CP4AIOpsを利用して運用を自動化・高度化する方法(予兆検知)について紹介した。
CP4AIOpsでは、分析対象とするテンプレートのアイテムを選択して、トレーニング・スケジュールを設定するだけで済むので、簡単にアノマリー検知を始めることが可能である。
またZabbix以外にも、各社から提供されるAPM製品、たとえばAWS CloudWatch、IBM Instana、Dynatrace、Splunkなどとも連携して、同様にアノマリー検知が可能となる。
このように、既存の運用監視システムの設定を大幅に変更しなくても、従来の閾値監視では不可能であった性能情報の異常発生を早期に検知でき、調査・対応できるようになる。
なお運用高度化を実施する際には、監視ツールを実装するだけでなく、実運用も変更することでより高い効果が得られる。たとえば運用体制を変更し、監視の状況をインフラチームだけでなくアプリチームも確認することで、より迅速に対応できるようになる。
今まで障害対応は事後対応が中心であった。しかしこれからは、予兆検知機能を活用して事前対応を実施することが運用の効率化、高度化のために必要であると筆者は考えている。本稿が運用高度化推進の一助となれば幸いである。