MinskyとPowerAIを組み合わせ、強力な画像解析基盤を迅速に構築 ~日本アイ・ビー・エム株式会社
*本稿で紹介している画面はいずれも、「鳥の判別!」のデモサイトで使用されたものである。デモは 「OpenPOWER Developer Congress」で公開されたハンズオンデモに基づいて作成されている。
ディープラーニングに最適化された
システム基盤
ディープラーニングを活用した画像認識は現在、CTやレントゲン、MRIといった医療画像の診断や自動運転、製造現場での異常検知、品質検査、故障予知など、多彩な領域で活用が進んでいる。
Part 1で詳しく解説しているように、ディープラーニングとは、事前学習した画像データをもとに、そこに写っている対象を理解し、分類していくことである。画像を見分ける鍵になるのは「特徴量」、すなわち画像を見分けるための規則性である。
従来の機械学習の手法を使って、「どのような特徴で画像を見分けるか」という特徴量を発見するには、業務に通じた専門家による手動での設計が必要であった。しかしディープラーニングでは、大量の画像を処理し、最適な特徴量を自動的に検出できるので、従来手法よりはるかに高精度の分類が可能になっている。
とはいえ、ディープラーニングの利用にまったく課題がないわけではない。実際に画像解析を実行するには、訓練データを用いた学習済みモデルをプログラミングして作成する必要がある。
たとえばディープラーニングでは、判別したいデータを「学習データセット」として、モデルに事前に学習させる必要がある。しかし判別精度を高めるには、学習のためのデータをモデルが正確に読めるように整える、つまり数千枚に及ぶような大量の学習データに対してピクセルサイズや色調を調整するなどの事前作業が必要になり、大変な労力を要する。
また畳み込みニューラルネットワークもしくは再帰型ネットワークの選択、その後のネットワーク構造の設計など、学習モデルを構築するには、専門のスキルと知識が必要になる。
さらにモデルを学習させる際のパラメータ指定にも、職人的な専門スキルが必要だ。学習係数や学習の繰り返し回数、重み減衰、モメンタムなど学習の最適化には適切なパラメータ設定が必要だが、これにも一定の経験が求められる。
そこで登場したのが、「IBM PowerAI Vision」(以下、AI Vision)である。これは、ディープラーニングによる画像解析に特化したGUIベースのアプリケーションである(図表1)。
【図表1】既存の機械学習とAI Vision の比較
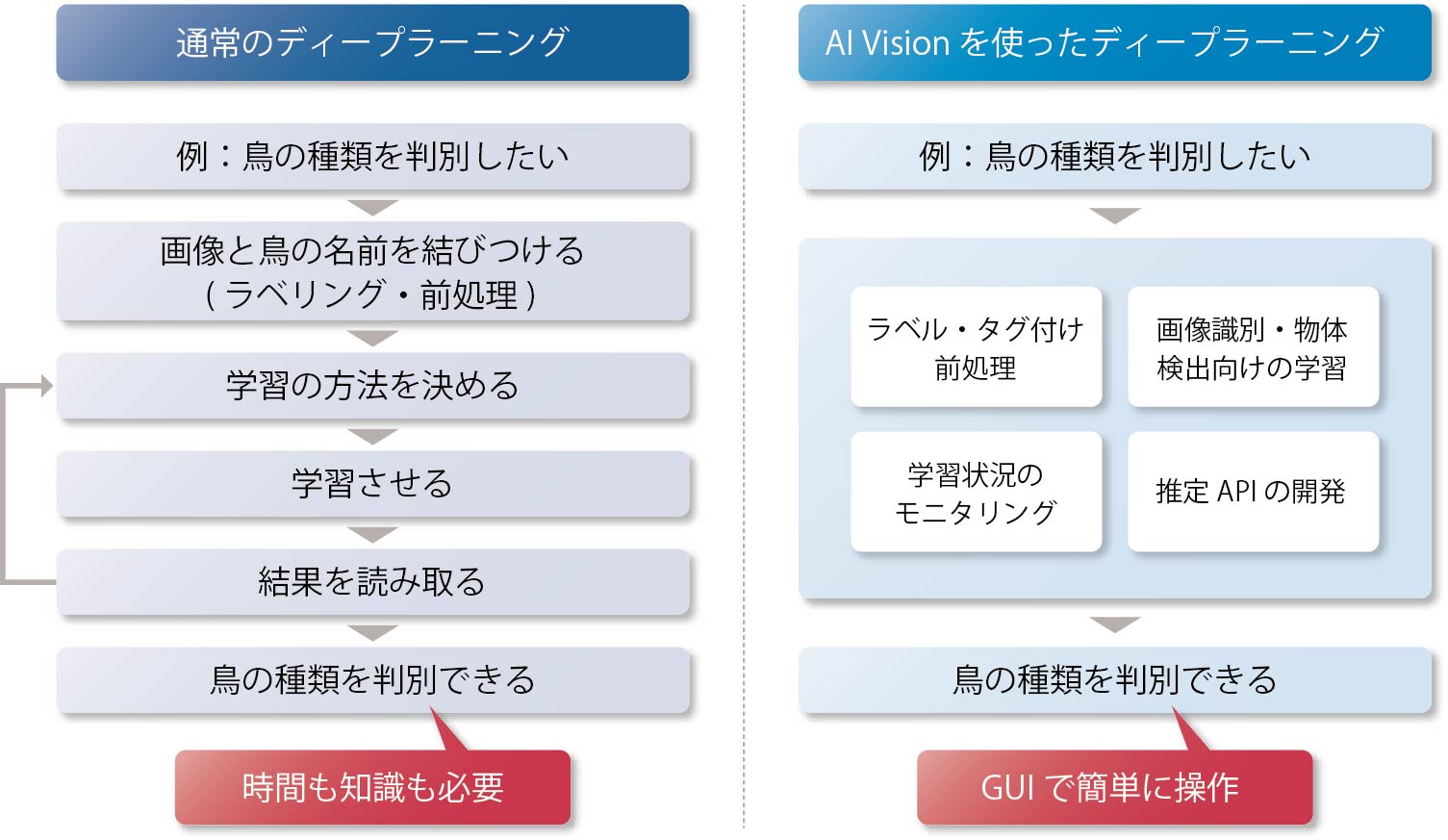
「AI Visionではプログラミング作業を一切必要とせず、GUI操作のみで、手持ちの画像データから学習済みモデルを簡単に作成できます。モデルのアーキテクチャ設計や組み合わせの調整、開発環境の構築といった煩わしさも解消し、ディープラーニングにあまり詳しくないユーザーでも、手軽に画像解析を実現できるのが大きな特徴です」と語るのは、日本IBMの中島康裕氏(IBMシステムズ・ハードウェア事業本部 ソリューション事業 OSSソリューション ITスペシャリスト)である。
AI Visionによる
画像解析の仕組みと流れ
AI Visionは、「分類(classification)」と「物体検出(Object Detection)」の2つの画像解析に対応し、(1)データの準備、(2)モデルの作成、(3)学習状況のモニタリング、(4)推定結果の表示の4つのプロセスを実行できる。
以下に、IBMのサイトで公開されている「鳥の判別!」というデモ映像(*1)を参考に、AI Visionによる画像解析の仕組みと流れを見てみよう。
ここでは約20種類の鳥の画像を用いてディープラーニングを実行し、鳥の種類を判定する。
(1)データの準備
まずは分類した鳥の画像を、データセットとしてアップロードする。
データセットの名前に「Bird」と付けたフォルダを作る。ここに鳥の画像をアップロードしていくわけだ。
そして「Bird」フォルダのなかに、さらに鳥の種類ごとにフォルダを作っていく。たとえば「タイヨウチョウ」(Aethopyga)というフォルダを作成し、ここにタイヨウチョウの画像データをまとめてアップロードする(図表2)。事前にデータセットをZIPでまとめておき、一括でアップロードすることも可能である。
【図表2】画像データをまとめてアップロード
アップロードが完了すると、タイヨウチョウの画像が一覧で表示される(図表3)。ほかの種類の鳥についても、同じようにフォルダを作り、そこにアップロードしていく。
【図表3】アップロードした鳥の画像一覧を表示
この作業を繰り返すことで、20種類の鳥の画像から構成されるデータセットが完成する。
(2)モデルの作成
次に、学習データを作成する。ここでは、画像分類(classification)を選択する。パラメータとしては、「速度優先」か「精度優先」があるので、どちらかを選ぶ(図表4)。
【図表4】モデルの作成に必要なパラメータを設定
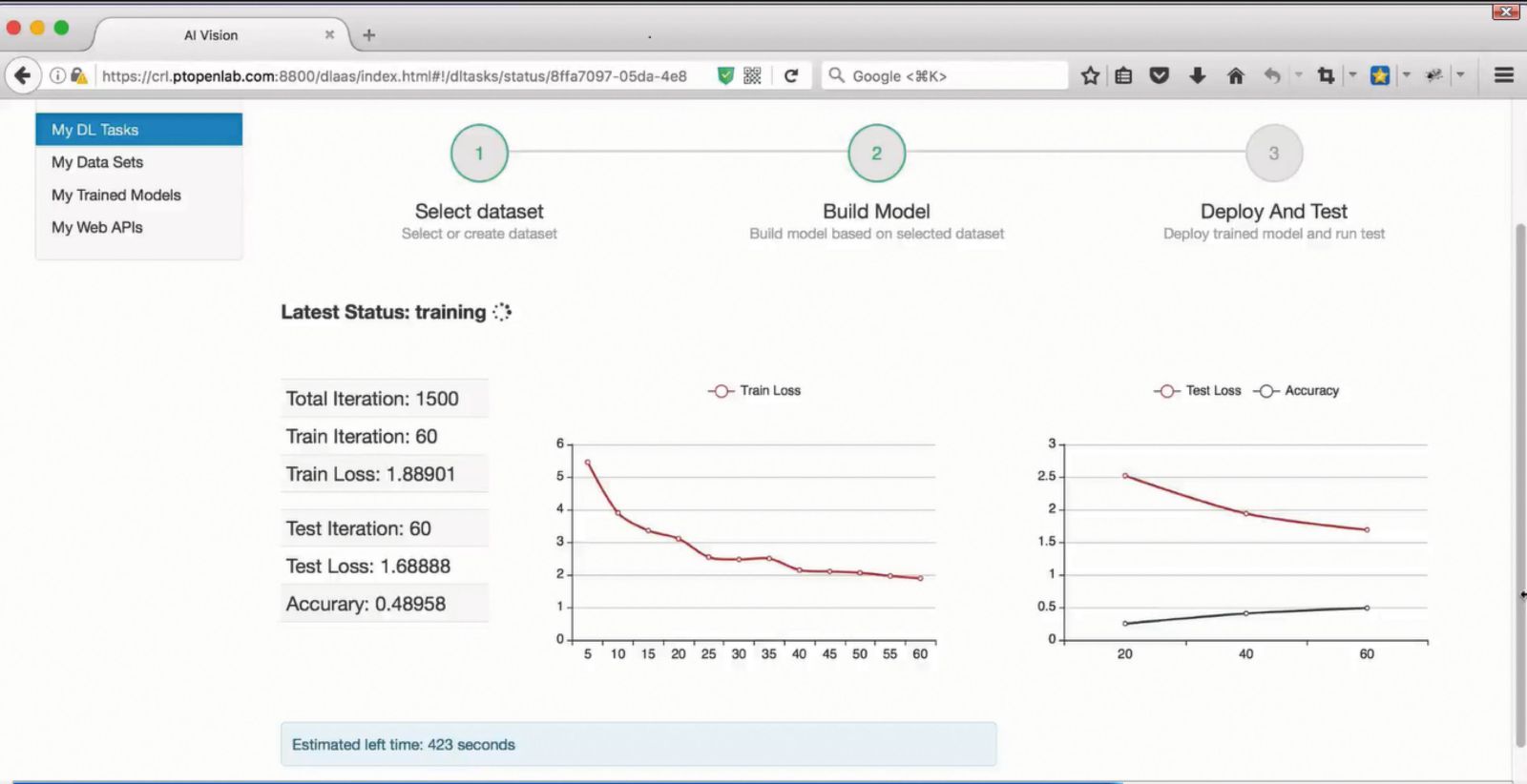
(3)学習状況のモニタリング
学習が始まる。学習の進捗状況は、モニターで確認できる。精度や残り時間も監視できる(図表5)。
【図表5】学習状況をモニタリング
(4)推定結果の表示
学習が完了する。学習結果をもとに、(1)~(3)がうまくいったかを判断する。学習した結果はAPIで呼び出せる。デモでは、AI Vision内のアプリケーションから呼び出している。
画像を1枚入れると、すぐに結果が返ってくる。たとえばキジバト(streptopelia)の画像を入れると、右側に「キジバトである」という予測結果とその確信度合いを表示する(図表6)。ほかの画像を入れても、すぐに結果を返してくる。
【図表6】推定結果を表示
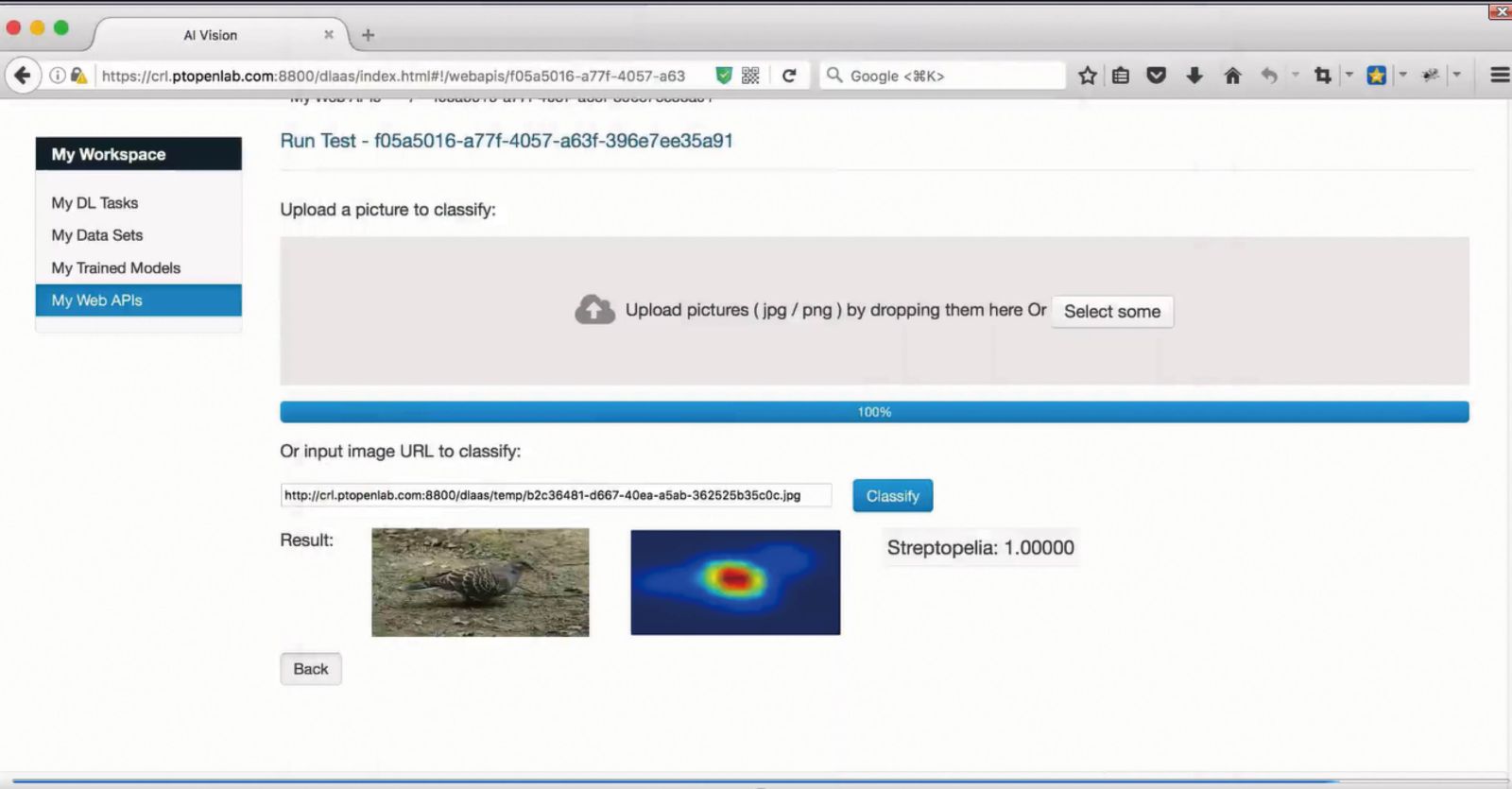
画面の中央には、ヒートマップが表示されている(図表7)。これは画像のどの部分を判断基準にしたかを示すもので、赤色で表示されている部分は特徴量が最も多いことを意味している。
【図表7】ヒートマップで特徴量を表示

こうした作業はすべて、GUIベースで進められていく。
IBMサイトで公開されているデモ映像にはこのほか、画像分類の例として、車を運転中のドライバーの画像から、ドライバーの挙動を判別する「運転中ドライバー画像を分析!」(*2)や、物体検出の例として、作業員の映像を判別し、ヘルメットや安全着の着用状況を検出する「作業員の衣類を検出!」(*3)なども用意されている。
(*1) (*2)(*3)https://ibm.co/2xjG8hv
ディープラーニングに最適化
MinskyとPowerAI
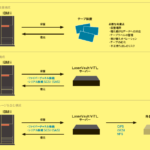
AI Visionは、「Watson Visual Recognition」のようにクラウドサービスとして利用するのではなく、Power Systemsに実装したオンプレミスでの利用が前提となっている。
それを支えるプラットフォームとして、IBMが2016年末にリリースしたのが、ディープラーニングに最適なPOWERプロセッサ搭載サーバー「Minsky(ミンスキー)」(IBM Power System S822LC for HPC)である。
Minskyは、4個の 「NVIDIA Tesla P100 GPU 」を搭載している。GPUはGraphic Processing Unitの略で、もともとは画像処理に特化したプロセッサだが、高い並列計算能力を必要とするHPC(High Performance Computing)用途でも広く活用されている。
NVIDIA Tesla P100は、GPU間を接続するテクノロジーとして「NVLink」を使用できるが、MinskyではCPUとGPU間の接続にもNVLinkを採用しており、x86プロセッサ・ベースのシステムと比較して、CPUとGPU間を2.5倍のバンド幅で接続できる。
ディープラーニングが必要とするディープニューラルネットワークは巨大かつ複雑化されてきており、GPUメモリに必要なデータをすべて格納するのはむずかしい。しかしCPUとGPU間のNVLink接続を実装しているMinskyでは、CPUとGPU間のデータ転送を効率化できるので、大容量のデータ転送が求められる画像解析のワークロードでも高速レスポンスを実現できる。
Minskyでは、x86プロセッサ・ベースのサーバーと比較して、時間当たりの学習可能イメージ量が多いため、学習時間が進むにつれ、学習済みイメージ数の差は、さらに拡大していくことになる。
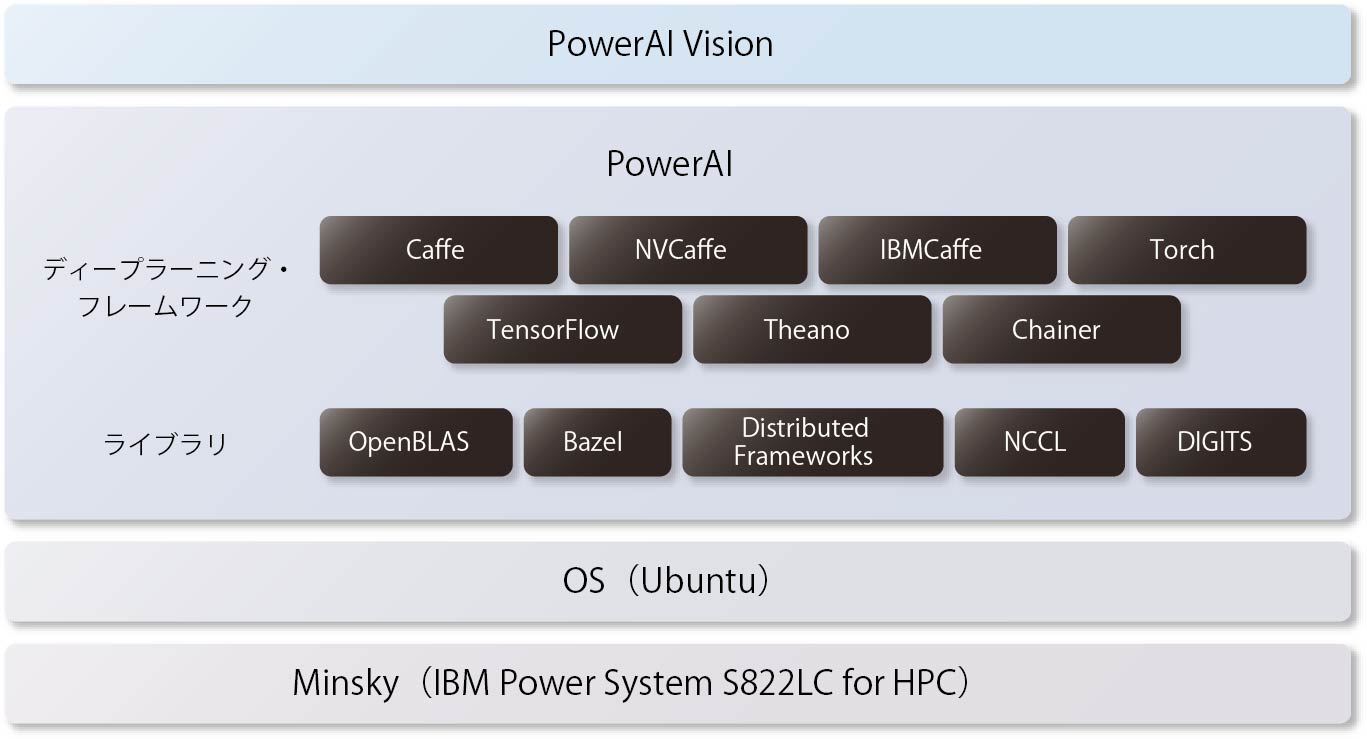
またTensorFlow、Caffe、Chainerなど主要なディープラーニング・フレームワークがMinsky向けに最適化、コンパイル済み状態で、PowerAIとして提供されている。これを活用することで、Minsky上にディープラーニング環境を簡単に構築し、使い始めることが可能である。(図表8)。
【図表8】PowerAIを利用するためのシステム構成
AI Visionは、このPowerAI の拡張機能として提供されており、現在はベータ版を無償で使用できる。近日中に、有償の正式バージョンがリリースされる予定である。
ディープラーニングに最適化された基盤であるMinskyとPowerAI、そして画像解析アプリケーションであるAI Visionの組み合わせは、高度な処理能力が必要な画像解析システムをすばやく構築したいケースや、機密保護の観点から外部のクラウドサービスへ自社データを送れないといったニーズで、とくにその効果を発揮しそうである。
・・・・・・・・
IS magazine No.17(2017年9月)掲載