汎用的な大規模言語モデル(LLM)は非常に強力だが、そのままでは自社の専門用語や業務知識、社内規定など、特定の分野に関する質問には正確に答えられない。こうした課題を解決し、LLMを特定の目的に特化させる代表的な手法が、ファインチューニングとRAG(Retrieval-Augmented Generation)である。
この2つの手法は、AIの知識と応答をカスタマイズするという共通の目的を持つが、そのアプローチは大きく異なる。どちらを選択するかは、目的、コスト、そして利用するデータの性質によって決まる。
ファインチューニング
ファインチューニングとは、既存の学習済みLLMに対して、特定の分野に特化した小規模なデータセット(例:自社の過去の問い合わせ履歴、専門分野の文献など)を追加で学習させる手法である(図表1)。
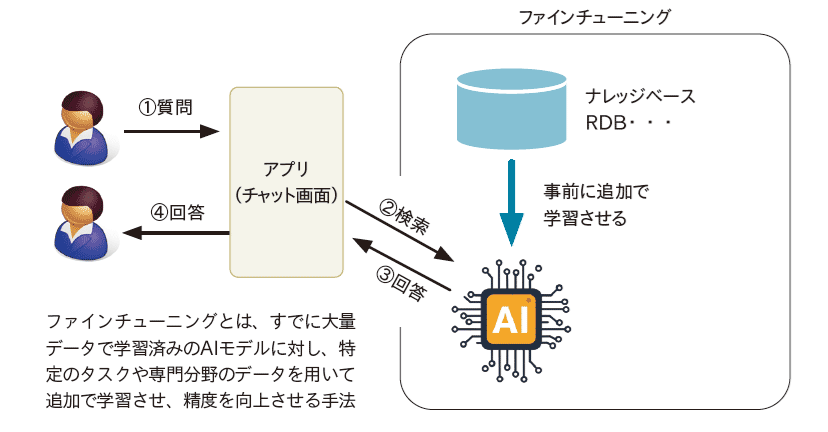
このプロセスは、あたかも広範な知識を持つ新入社員に、自社独自の業務マニュアルを読み込ませて専門家として再教育するようなものだ。ファインチューニングを行うことで、モデルは特定の文体、専門用語、思考の癖などを学習し、その分野に最適化された応答を生成できるようになる。
長所:モデルの根幹の振る舞いを調整するため、非常に高い専門性と応答品質を期待できる。
短所:追加学習に高品質な教師データを大量に用意する必要があり、計算コストも高い。また一度ファインチューニングしたモデルの知識を更新するには、再度学習プロセスが必要となる。一度学習させた内容は静的なので、日々その情報を更新するには相当のコストが必要となる。
ファインチューニングは、モデルの振る舞いやスタイルを根本的に変えたい場合、あるいは小型モデルで効率的にその分野に特化させたい場合に有効である。ただし、各社が提供する生成AIモデルの汎用能力の向上により、「まず試すべき手法」から「他の手法で不十分だった場合の選択肢」へと位置づけが変化している。
RAG
RAGは、LLMが応答を生成する際に、リアルタイムで外部のナレッジベース(データベース、ドキュメント、Webサイトなど)から関連情報を検索し、その内容をコンテキストとしてプロンプトに埋め込んで応答を生成する仕組みである(図表2)。
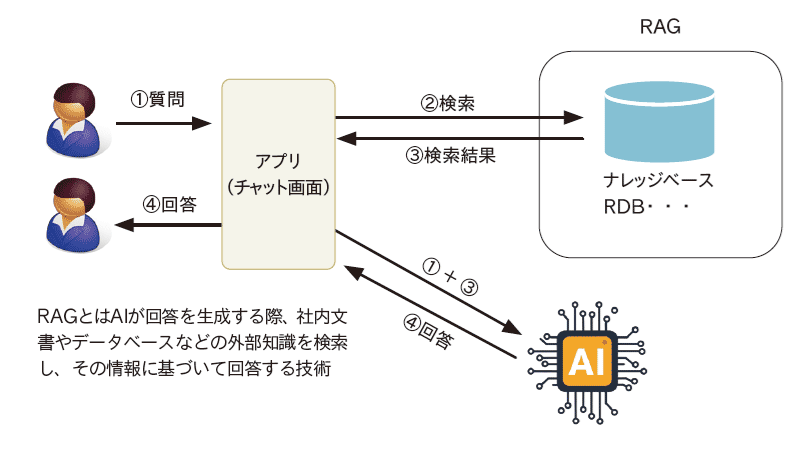
これは人間が質問に答える際に、手元の資料や専門書を参照するプロセスに似ている。LLM自体は追加学習を行わず、あくまでその場で与えられた「参照情報」に基づいて回答を組み立てる。
長所:最新かつ正確な情報に基づいた応答が可能となり、前項で述べたハルシネーションを大幅に抑制できる。ナレッジベースの情報を更新するだけで、AIの応答に反映できるため、ファインチューニングに比べてメンテナンス性も高い。
短所:応答の品質が、ナレッジベースの質と検索システムの精度に大きく依存する。またその検索部分の作成には、高度な設計および実装が必要になる。
RAGは、大規模なナレッジベースからの検索やコスト効率の面では、いまでも重要な機能である。特に日々更新される情報に関しては、都度ファインチューニングしてLLMに学習させるより圧倒的にコストがかからない。
しかし、前述の短所として述べたように、検索する情報の整理とその仕組みの構築の初期投資は相応の額になる。
ファインチューニングとRAGの現在位置
今日でも、この2つの手法はとても重要である。ファインチューニングは、特定のタスクや業界に特化したモデル作成には欠かせない。たとえば、業界特有のトーンや形式で回答させる、特定のワークフローに沿った出力を生成させるなど、モデルの振る舞いを目的に合わせて調整する手法として、その活躍の場は今でもたくさんある。
一方のRAGは外部の知識ソースを検索し、その結果を基に回答を生成する手法である。回答の根拠を明示できるためハルシネーションの抑制に一定の効果があり、また最新のデータや頻繁に更新される情報にも対応できる。モデル自体を再学習させる必要がないため、運用コストの面でも優れている。
この2つは、どちらが優れているとか、採用すべきとかではなく、お互いの短所を補完する関係にある。ファインチューニングでモデルの振る舞いを整え、RAGで正確な情報を参照させる。つまり両者を組み合わせることで、より信頼性の高い回答を実現できる。
ただし双方を自社で構築・運用するには、それ相応のコストと専門知識が必要になる点も留意すべきである。
IBM i 環境での活用を考える
IBM i環境に蓄積された膨大な資産(設計書、仕様書、RPGやCOBOLのソースコードなど)をAIに活用させる場合、これらの手法は非常に有効である。
自社専用モデルの開発
自社の基幹システムで使われるRPGやCOBOLのコード規約、設計書の記述スタイルなどを学習させ、自社の慣習に沿った応答ができる専用モデルを用意する。このモデルをオンプレミス環境で運用すれば、外部に情報が漏洩するリスクを抑えられる。
RAGの開発
IBM iに蓄積されたデータを必要に応じて検索するRAGシステムを開発すれば、在庫情報や納期回答などを自然言語で問い合わせる仕組みを構築できる。さらに、既存のRPGソースコードから類似ロジックを検索したり、プログラム仕様を参照したりといった開発支援にも活用できる。
しかし、これは現実的だろうか。IBM iユーザーはAIモデルを提供するプラットフォーマーではないし、RAGの開発もかなりの専門的な知識を要する。上記の実現は理想ではあるが、これを実現できる企業は限られる。
前述のとおり、ファインチューニングとRAGの組み合わせが理想であるが、すべてを自社で賄う必要はない。最終目標である正確な情報をユーザーに提供するには、既存のサービスやツールを活用する別のアプローチも検討すべきであり、そういった選択肢は日々増えている。